
As in previous posts, we use the following asymptotic notation: 
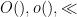



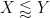

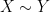
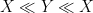
The purpose of this post is to collect together all the various refinements to the second half of Zhang’s paper that have been obtained as part of the polymath8 project and present them as a coherent argument. In order to state the main result, we need to recall some definitions. If 

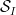



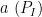
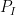

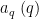
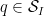

for all coprime 


If 



![{[y^{-1} R, R]}](https://s0.wp.com/latex.php?latex=%7B%5By%5E%7B-1%7D+R%2C+R%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

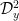
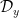
Given any finitely supported sequence 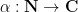
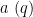

For any fixed 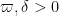
![{MPZ''[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BMPZ%27%27%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \sum_{q \in {\mathcal S}_I \cap {\mathcal D}_{x^\delta}^2: q \leq x^{1/2+2\varpi}} |\Delta(\Lambda 1_{[x,2x]}; a\ (q))| \ll x \log^{-A} x \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bq+%5Cin+%7B%5Cmathcal+S%7D_I+%5Ccap+%7B%5Cmathcal+D%7D_%7Bx%5E%5Cdelta%7D%5E2%3A+q+%5Cleq+x%5E%7B1%2F2%2B2%5Cvarpi%7D%7D+%7C%5CDelta%28%5CLambda+1_%7B%5Bx%2C2x%5D%7D%3B+a%5C+%28q%29%29%7C+%5Cll+x+%5Clog%5E%7B-A%7D+x+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
for any fixed 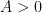


This improves upon the previous constraint of 
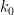

This estimate is deduced from three sub-estimates, which require a bit more notation to state. We need a fixed quantity 
Definition 2 A coefficient sequence is a finitely supported sequence
that obeys the bounds
for all
is the divisor function.
- (i) A coefficient sequence
is said to be at scale
for some
if it is supported on an interval of the form
.
- (ii) A coefficient sequence
for any
, any fixed
, and any primitive residue class
.
- (iii) A coefficient sequence
) is said to be smooth if it takes the form
for some smooth function
supported on
obeying the derivative bounds
for all fixed
(note that the implied constant in the
notation may depend on
).

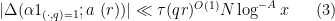
Definition 3 (Type I, Type II, Type III estimates) Let
,
, and
be fixed quantities. We let
- (i) We say that
holds if, whenever
are quantities with
and
for some fixed
, and
are coefficient sequences at scales
respectively, with
obeying a Siegel-Walfisz theorem, we have
- (ii) We say that
holds if the conclusion (7) of
for some sufficiently small fixed
- (iii) We say that
holds if, whenever
are quantities with
and
are coefficient sequences at scales
respectively, with
smooth, we have

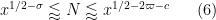



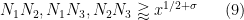


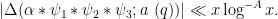
Theorem 1 is then a consequence of the following four statements.
Theorem 4 (Type I estimate)
are fixed quantities such that
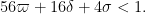
Theorem 5 (Type II estimate)
are fixed quantities such that

Theorem 6 (Type III estimate)
are fixed quantities such that
In particular, if
then all values of
that are sufficiently close to
are admissible.

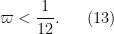

Lemma 7 (Combinatorial lemma) Let
be such that
Indeed, if 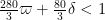
The proofs of Theorems 4, 5, 6 will be given below the fold, while the proof of Lemma 7 follows from the arguments in this previous post. We remark that in our current arguments, the double dense divisibility is only fully used in the Type I estimates; the Type II and Type III estimates are also valid just with single dense divisibility.
Remark 1 Theorem 6 is vacuously true for
, as the condition (10) cannot be satisfied in this case. If we use this trivial case of Theorem 6, while keeping the full strength of Theorems 4 and 5, we obtain Theorem 1 in the regime
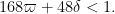
— 1. Exponential sum estimates —
It will be convenient to introduce a little bit of formal algebraic notation. Define an integral rational function to be a formal rational function 

![{P,Q \in {\bf Z}[t]}](https://s0.wp.com/latex.php?latex=%7BP%2CQ+%5Cin+%7B%5Cbf+Z%7D%5Bt%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{P(t) \in {\bf Z}[t]}](https://s0.wp.com/latex.php?latex=%7BP%28t%29+%5Cin+%7B%5Cbf+Z%7D%5Bt%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
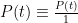
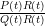


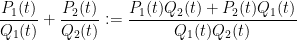
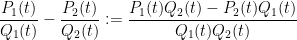

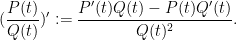
Note that the denominator always remains monic with respect to these operations. This is not quite a ring with a derivation (the subtraction operation does not quite cancel the addition operation due to the inability to cancel) but this will not bother us in practice. (On the other hand, addition and multiplication remain associative, and the latter continues to distribute over the former, and differentiation obeys the usual sum and product rules.) Note that if 

![{({\bf Z}/q{\bf Z})[t]}](https://s0.wp.com/latex.php?latex=%7B%28%7B%5Cbf+Z%7D%2Fq%7B%5Cbf+Z%7D%29%5Bt%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

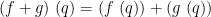


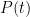
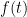
If 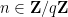

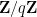


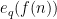
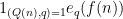


Note that if 

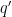
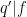
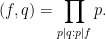
Note with these conventions that 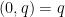
We recall the following Chinese remainder theorem:
Lemma 8 (Chinese remainder theorem) Let
with
coprime positive integers. If
for all integers
is the inverse of
in
and similarly for
.

When there is no chance of confusion we will write 

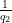
Proof: See Lemma 7 of this previous post.

Now we give an estimate for complete exponential sums, which combines both Ramanujan sum bounds with Weil conjecture bounds.
Proposition 9 (Ramanujan-Weil bounds) Let
of bounded degree. Then we have
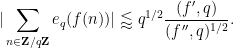
Proof: See Proposition 4 of this previous post.
Proposition 10 (Incomplete sums) Let
. Let
be a fixed integer, and suppose that we have a factorisation
. Then for any
, and any coefficient sequence
at scale
where
and
.


Proof: Let 

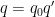
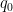

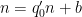

By dividing 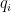
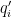
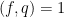
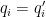
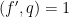

We induct on 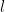
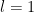

By Proposition 9, we have

so we may delete the condition 
By completion of sums (see Lemma 6 of this previous post), the left-hand side is
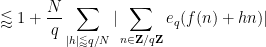
so it will suffice to show that

By Proposition 9 again, the left-hand side is

Since 
Now suppose that 
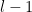
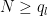

and the claim then follows by the induction hypothesis (concatenating 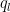
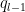


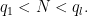
Let 

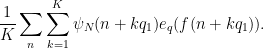
By Lemma 8 we have 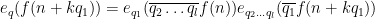
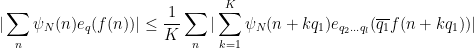

since the summand is only non-zero when 
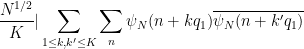
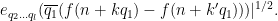
The diagonal contribution 


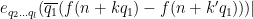

We observe that 
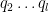
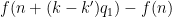
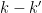
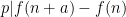


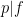
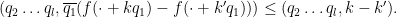
Applying the induction hypothesis and Proposition 9, we may thus bound
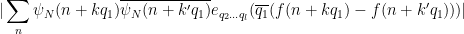
by

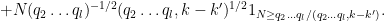
The contribution of the first two terms to (14) is acceptable, so the only contribution remaining to control is
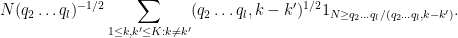
If we bound 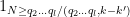
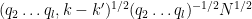

which by Lemma 5 of this previous post and the bound 
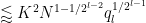
which is acceptable.
We record a special case of the above proposition:
Corollary 11 Let
be square-free numbers (not necessarily coprime) of polynomial size, let
be integers, let
is
be a residue class with
. Then
where
for
. We also have the variant bound
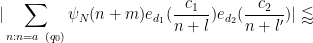
![\displaystyle q_0^{-1/2} N^{1/2} [d_1,d_2]^{1/6} y^{1/6} + q_0^{-1} \frac{(c_1,d'_1)}{d'_1} \frac{(c_2,d'_2)}{d'_2} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++q_0%5E%7B-1%2F2%7D+N%5E%7B1%2F2%7D+%5Bd_1%2Cd_2%5D%5E%7B1%2F6%7D+y%5E%7B1%2F6%7D+%2B+q_0%5E%7B-1%7D+%5Cfrac%7B%28c_1%2Cd%27_1%29%7D%7Bd%27_1%7D+%5Cfrac%7B%28c_2%2Cd%27_2%29%7D%7Bd%27_2%7D+N+&bg=ffffff&fg=000000&s=0&c=20201002)
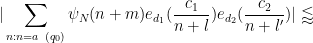
![\displaystyle q_0^{-1/2} [d_1,d_2]^{1/2} + q_0^{-1} \frac{(c_1,d'_1)}{d'_1} \frac{(c_2,d'_2)}{d'_2} N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++q_0%5E%7B-1%2F2%7D+%5Bd_1%2Cd_2%5D%5E%7B1%2F2%7D+%2B+q_0%5E%7B-1%7D+%5Cfrac%7B%28c_1%2Cd%27_1%29%7D%7Bd%27_1%7D+%5Cfrac%7B%28c_2%2Cd%27_2%29%7D%7Bd%27_2%7D+N.+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We first consider the case 
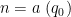
![{[d_1,d_2] = q_1 q_2}](https://s0.wp.com/latex.php?latex=%7B%5Bd_1%2Cd_2%5D+%3D+q_1+q_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle y^{-2/3}[d_1,d_2]^{1/3} \leq q_1 \leq y^{1/3} [d_1,d_2]^{1/3}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++y%5E%7B-2%2F3%7D%5Bd_1%2Cd_2%5D%5E%7B1%2F3%7D+%5Cleq+q_1+%5Cleq+y%5E%7B1%2F3%7D+%5Bd_1%2Cd_2%5D%5E%7B1%2F3%7D&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle y^{-1/3}[d_1,d_2]^{2/3} \leq q_2 \leq y^{2/3} [d_1,d_2]^{2/3}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++y%5E%7B-1%2F3%7D%5Bd_1%2Cd_2%5D%5E%7B2%2F3%7D+%5Cleq+q_2+%5Cleq+y%5E%7B2%2F3%7D+%5Bd_1%2Cd_2%5D%5E%7B2%2F3%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
The first bound then follows from the 
![\displaystyle |\sum_{n \in {\bf Z}/[d_1,d_2]{\bf Z}} e_{d_1}( \frac{c_1}{n+l} ) e_{d_2}( \frac{c_2}{n+l'} )| \lessapprox (c_1,d'_1) (c_2,d'_2) (d_1,d_2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Csum_%7Bn+%5Cin+%7B%5Cbf+Z%7D%2F%5Bd_1%2Cd_2%5D%7B%5Cbf+Z%7D%7D+e_%7Bd_1%7D%28+%5Cfrac%7Bc_1%7D%7Bn%2Bl%7D+%29+e_%7Bd_2%7D%28+%5Cfrac%7Bc_2%7D%7Bn%2Bl%27%7D+%29%7C+%5Clessapprox+%28c_1%2Cd%27_1%29+%28c_2%2Cd%27_2%29+%28d_1%2Cd_2%29&bg=ffffff&fg=000000&s=0&c=20201002)
that is proven as part of Proposition 5 of this previous post. The second bound similarly follows from the
Now we consider the case when 
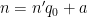


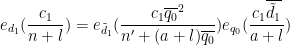
and similarly
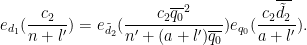
If we then apply the previous results with 
![{[\tilde d_1,\tilde d_2] = [d_1,d_2]/q_0}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctilde+d_1%2C%5Ctilde+d_2%5D+%3D+%5Bd_1%2Cd_2%5D%2Fq_0%7D&bg=ffffff&fg=000000&s=0&c=20201002)

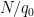

For the Type III estimate we will also need a deeper exponential sum estimate, involving the hyper-Kloosterman sums
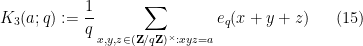
for square-free 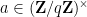
Lemma 12 (Correlation of hyper-Kloosterman sums) Let
be square-free numbers of polynomial size with
. Let
,
, and
. Then
where
.
![\displaystyle |\sum_{h \in ({\bf Z}/[r_1, r_2]s {\bf Z})^\times} K_3(a_1 h; r_1 s) \overline{K_3(a_2 h; r_2 s)} e_{[r_1,r_2] s}( nh )|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Csum_%7Bh+%5Cin+%28%7B%5Cbf+Z%7D%2F%5Br_1%2C+r_2%5Ds+%7B%5Cbf+Z%7D%29%5E%5Ctimes%7D+K_3%28a_1+h%3B+r_1+s%29+%5Coverline%7BK_3%28a_2+h%3B+r_2+s%29%7D+e_%7B%5Br_1%2Cr_2%5D+s%7D%28+nh+%29%7C+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lessapprox d^{1/2} s^{1/2} [r_1,r_2]^{1/2} (r_1,r_2,a_2-a_1,n)^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clessapprox+d%5E%7B1%2F2%7D+s%5E%7B1%2F2%7D+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28r_1%2Cr_2%2Ca_2-a_1%2Cn%29%5E%7B1%2F2%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: From Lemma 8 we have

and so it suffices to prove the estimates
![\displaystyle |\sum_{h \in ({\bf Z}/[r_1, r_2] {\bf Z})^\times} K_3(a_1 \bar{s}^3 h; r_1) \overline{K_3(a_2 \bar{s}^3 h; r_2)} e_{[r_1,r_2]}( \bar{s} nh )|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Csum_%7Bh+%5Cin+%28%7B%5Cbf+Z%7D%2F%5Br_1%2C+r_2%5D+%7B%5Cbf+Z%7D%29%5E%5Ctimes%7D+K_3%28a_1+%5Cbar%7Bs%7D%5E3+h%3B+r_1%29+%5Coverline%7BK_3%28a_2+%5Cbar%7Bs%7D%5E3+h%3B+r_2%29%7D+e_%7B%5Br_1%2Cr_2%5D%7D%28+%5Cbar%7Bs%7D+nh+%29%7C&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lessapprox [r_1,r_2]^{1/2} (r_1,r_2,a_2-a_1,n)^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clessapprox+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28r_1%2Cr_2%2Ca_2-a_1%2Cn%29%5E%7B1%2F2%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle |\sum_{h \in ({\bf Z}/s {\bf Z})^\times} K_3(a_1 \overline{r_1}^3 h; s) \overline{K_3(a_2 \overline{r_2}^3 h; s)} e_{s}( \overline{[r_1,r_2]} nh )| \lessapprox d^{1/2} s^{1/2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Csum_%7Bh+%5Cin+%28%7B%5Cbf+Z%7D%2Fs+%7B%5Cbf+Z%7D%29%5E%5Ctimes%7D+K_3%28a_1+%5Coverline%7Br_1%7D%5E3+h%3B+s%29+%5Coverline%7BK_3%28a_2+%5Coverline%7Br_2%7D%5E3+h%3B+s%29%7D+e_%7Bs%7D%28+%5Coverline%7B%5Br_1%2Cr_2%5D%7D+nh+%29%7C+%5Clessapprox+d%5E%7B1%2F2%7D+s%5E%7B1%2F2%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
By further application of Lemma 8, together with the divisor bound, it suffices to show that

whenever ![{[d_1,d_2] = p}](https://s0.wp.com/latex.php?latex=%7B%5Bd_1%2Cd_2%5D+%3D+p%7D&bg=ffffff&fg=000000&s=0&c=20201002)
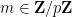
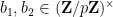
Suppose first that 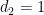
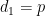

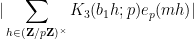
which can be expanded as
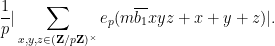
Performing the Fourier summation in 

and
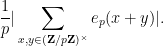
The first term either vanishes or is a Kloosterman sum, and is 

Now suppose that 

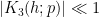
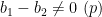

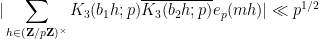
in this case. A proof of this claim (which uses the full strength of Deligne’s work) can be found in this paper of Michel (see also Proposition 6 of this recent expository note of Fouvry, Kowalski, and Michel).
From this and completion and sums we have
Lemma 13 (Correlation of hyper-Kloosterman sums, II) Let
be a smooth function adapted to the interval
which equals one on
. Then
where
, and the sum runs over those
coprime to
.
![\displaystyle |\sum_h \Psi(h) K_3(a_1 h; r_1 s) \overline{K_3(a_2 h; r_2 s)} e_{[r_1,r_2] s}( nh )|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Csum_h+%5CPsi%28h%29+K_3%28a_1+h%3B+r_1+s%29+%5Coverline%7BK_3%28a_2+h%3B+r_2+s%29%7D+e_%7B%5Br_1%2Cr_2%5D+s%7D%28+nh+%29%7C+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lessapprox (\frac{H}{[r_1,r_2]s} + 1) d^{1/2} s^{1/2} [r_1,r_2]^{1/2} (a_2-a_1,r_1,r_2)^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clessapprox+%28%5Cfrac%7BH%7D%7B%5Br_1%2Cr_2%5Ds%7D+%2B+1%29+d%5E%7B1%2F2%7D+s%5E%7B1%2F2%7D+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28a_2-a_1%2Cr_1%2Cr_2%29%5E%7B1%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
— 2. Type I estimate —
We begin the proof of Theorem 4, closely following the arguments from Section 5 of this previous post. Let 

for some sufficiently slowly decaying 

for any fixed 


be a sufficiently small fixed exponent.
By Lemma 11 of this previous post, we know that for all 
![{[D,2D]}](https://s0.wp.com/latex.php?latex=%7B%5BD%2C2D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
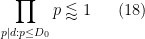

Specifically, the number of exceptions in the interval 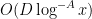

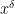

with 

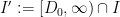

and
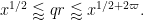
Here we use the easily verified fact that 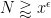
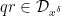
By dyadic decomposition, it thus sufices to show that

for any fixed 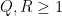
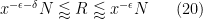
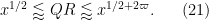
Fix 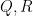
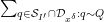


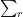
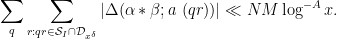
We now split the discrepancy
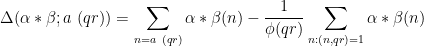
as the sum of the subdiscrepancies
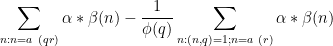
and

In Section 5 of this previous post, it was established (using the Bombieri-Vinogradov theorem) that


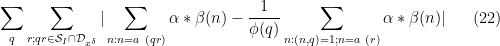

As in the previous notes, we will not take advantage of the 


for each individual 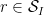

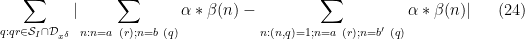
for all 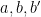
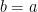

We use the dispersion method. We write the left-hand side of (24) as
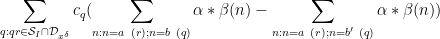
for some bounded sequence 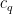

so from the Cauchy-Schwarz inequality and crude estimates it suffices to show that

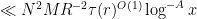
for any fixed 



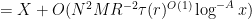
where 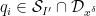



Observe that 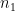

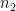


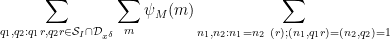
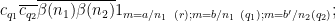
note that these inverses in the various rings 

We may write 





for some 

At this stage in previous posts we isolated the coprime case 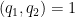

Applying completion of sums (Section 2 from this previous post), we can express the left-hand side of (28) as a main term
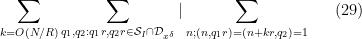
![\displaystyle c_{q_1} \overline{c_{q_2}} \beta(n) \overline{\beta(n+kr)} (\sum_{m} \psi_M(m)) \frac{1}{r[q_1,q_2]} 1_{b/n = b'/(n+kr)\ ((q_1,q_2))}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++c_%7Bq_1%7D+%5Coverline%7Bc_%7Bq_2%7D%7D+%5Cbeta%28n%29+%5Coverline%7B%5Cbeta%28n%2Bkr%29%7D+%28%5Csum_%7Bm%7D+%5Cpsi_M%28m%29%29+%5Cfrac%7B1%7D%7Br%5Bq_1%2Cq_2%5D%7D+1_%7Bb%2Fn+%3D+b%27%2F%28n%2Bkr%29%5C+%28%28q_1%2Cq_2%29%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
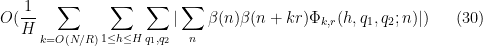
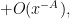

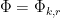 is the phase
is the phase 
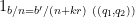
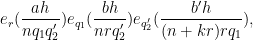
where 
Let us first deal with the main term (29). The contribution of the coprime case 
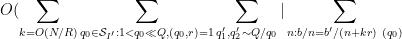
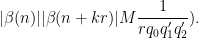
We may estimate 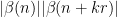
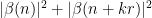


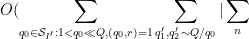

The 



Since 
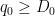
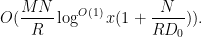
By (20) and (19), this is 
It remains to control (30). We may assume that 
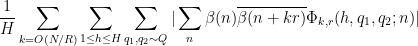
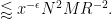
Using (31), it will suffice to show that
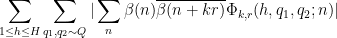
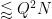
for each
We now work with a single 
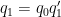
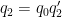

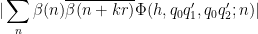
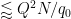
for each 
Henceforth we work with a single choice of

From (31) and (21), this follows from the assertion that

but this follows from (5), (6) if 

As 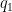

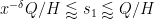
and thus
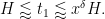
Factoring out 

and
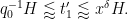
By dyadic decomposition, it thus suffices to show that

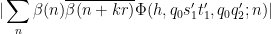
whenever 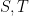
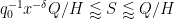
and

and
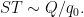
We rearrange this estimate as
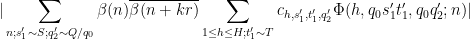

for some bounded sequence 

By Cauchy-Schwarz and crude estimates, it then suffices to show that

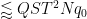
where
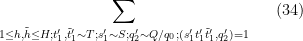

The contribution of the diagonal case 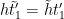
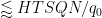




![\displaystyle 1_{b/n=b'/(n+kr)\ (q_0)} e_{r q_0 s'_1 [t'_1, \tilde t'_1]}(\frac{c_1}{n} ) e_{q_0 q'_2}(\frac{c_2}{n+kr} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++1_%7Bb%2Fn%3Db%27%2F%28n%2Bkr%29%5C+%28q_0%29%7D+e_%7Br+q_0+s%27_1+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D%7D%28%5Cfrac%7Bc_1%7D%7Bn%7D+%29+e_%7Bq_0+q%27_2%7D%28%5Cfrac%7Bc_2%7D%7Bn%2Bkr%7D+%29+&bg=ffffff&fg=000000&s=0&c=20201002)
for some quantities 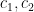

Also, by construction, 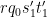
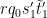

![{[rq_0 s'_1 t'_1 \tilde t'_1,q_0 q'_2]}](https://s0.wp.com/latex.php?latex=%7B%5Brq_0+s%27_1+t%27_1+%5Ctilde+t%27_1%2Cq_0+q%27_2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



by
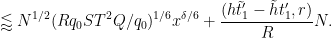
Bounding 

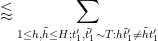
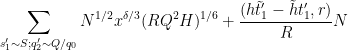
which sums (using Lemma 5 of this previous post and the divisor bound) to
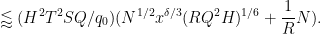
Discarding some factors of

From (31), (21), (5) we have 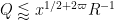


From (20), this will be implied by
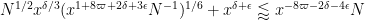
or equivalently that

and
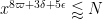
which by (6) is obeyed whenever

and
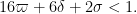
The second condition is implied by the first and may be deleted. The proof of Theorem 4 is now complete.
— 3. Type II estimate —
Now we prove Theorem 5. We repeat the Type I arguments through to (33) (noting that the hypothesis (6) is never used until that point, other than to ensure that
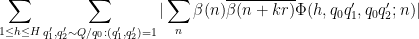
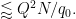
This time, however, we do not have 
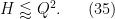
Indeed by (31) this is equivalent to
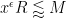
and this follows from (20) and (5), (8).
With this weaker bound (35) we have to perform Cauchy-Schwarz differently. We rearrange the left-hand side as

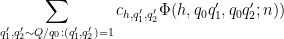
for some bounded coefficients 
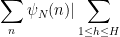
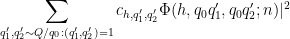

The left-hand side may be bounded by

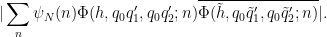
We isolate the diagonal case 

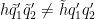

![\displaystyle 1_{b/n=b'/(n+kr)\ (q_0)} e_{r q_0 [q'_1, \tilde q'_1]}(\frac{c_1}{n} ) e_{q_0 [q'_2, \tilde q'_2]}(\frac{c_2}{n+kr} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++1_%7Bb%2Fn%3Db%27%2F%28n%2Bkr%29%5C+%28q_0%29%7D+e_%7Br+q_0+%5Bq%27_1%2C+%5Ctilde+q%27_1%5D%7D%28%5Cfrac%7Bc_1%7D%7Bn%7D+%29+e_%7Bq_0+%5Bq%27_2%2C+%5Ctilde+q%27_2%5D%7D%28%5Cfrac%7Bc_2%7D%7Bn%2Bkr%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
for some 

By the divisor bound and Lemma 5 of this previous post, this sums to
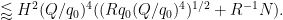
Discarding some factors of
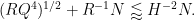
From (31), (21), (5) we have

From (20), this will be implied by

or equivalently that
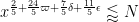
and
which by (8) is obeyed whenever
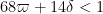
and
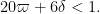
The second condition is implied by the first and may be deleted. The proof of Theorem 5 is now complete.
— 4. Type III estimate —
We now prove Theorem 6. Let 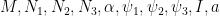

for some sufficiently small fixed 

where 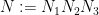
Henceforth we work with a single choice of
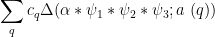
for some bounded sequence

for some
The left-hand side may be rewritten as

Note that for 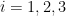

By Fourier inversion we have
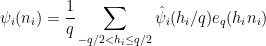
for all 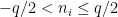


From the smoothness of 

for any fixed 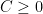
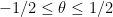
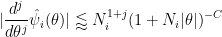
for any fixed 

(say) when 

Furthermore, for 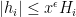


for some fixed 


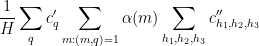

for some bounded sequences 

and
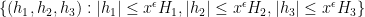
respectively, and where

If we then introduce the modified hyper-Kloosterman sum


defined for 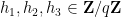

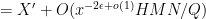
for some 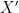
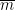

We may rewrite 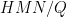


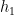

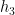



At this point we need to account for a technical problem that the 
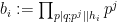
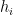





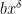
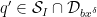
Now we factor 

For the second term, we observe that 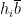
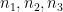

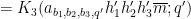
where 

and we recall that 

As for the first term, we have the following estimate:
Lemma 14 We have
where
(thus for instance
).

Proof: By further applications of Lemma 8 it suffices to show that
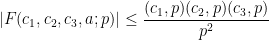
whenever 

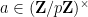
Without loss of generality we may assume that 
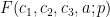
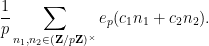
But this factors as the product of two Ramanujan sums divided by
For brevity we write 
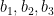



where the

Writing 

and recalling that 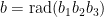
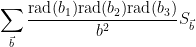
where 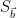
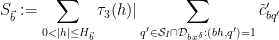

where 


We now focus on estimating
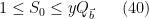
be a quantity to optimise in later, where
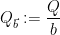
and
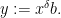

Observe that every 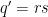


with 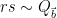
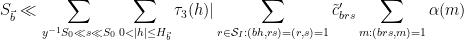
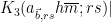
where
From crude estimates we have
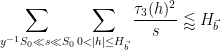
so from the Cauchy-Schwarz inequality we have

where
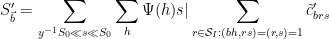
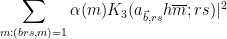
and 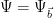
![{[-2H_{\vec b},2H_{\vec b}]}](https://s0.wp.com/latex.php?latex=%7B%5B-2H_%7B%5Cvec+b%7D%2C2H_%7B%5Cvec+b%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-H_{\vec b},H_{\vec b}]}](https://s0.wp.com/latex.php?latex=%7B%5B-H_%7B%5Cvec+b%7D%2CH_%7B%5Cvec+b%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now we estimate 
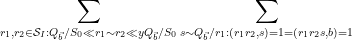

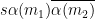
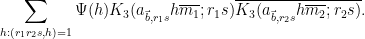
We first dispose of the diagonal case 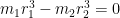


By the divisor bound, for each 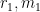
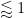


which sums to 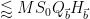
Applying Lemma 13 for the off-diagonal case 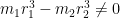

![\displaystyle (\frac{ H_{\vec b}}{[r_1,r_2] s} + 1) d^{1/2} s^{1/2} [r_1,r_2]^{1/2} (r_1,r_2,m_2-m_1)^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28%5Cfrac%7B+H_%7B%5Cvec+b%7D%7D%7B%5Br_1%2Cr_2%5D+s%7D+%2B+1%29+d%5E%7B1%2F2%7D+s%5E%7B1%2F2%7D+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28r_1%2Cr_2%2Cm_2-m_1%29%5E%7B1%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where

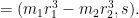
Using the bound 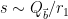
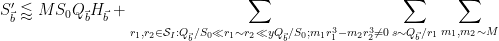
![\displaystyle (Q_{\vec b}/r_1) (\frac{ H_{\vec b}}{[r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2}} + [r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28Q_%7B%5Cvec+b%7D%2Fr_1%29+%28%5Cfrac%7B+H_%7B%5Cvec+b%7D%7D%7B%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%7D+%2B+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%29+&bg=ffffff&fg=000000&s=0&c=20201002)

By Lemma 5 from this previous post we have
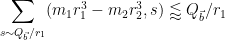
and hence also
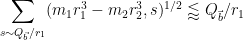
and thus

![\displaystyle (\frac{ H_{\vec b}}{[r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2}} + [r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2}) (r_1,r_2,m_2-m_1)^{1/2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28%5Cfrac%7B+H_%7B%5Cvec+b%7D%7D%7B%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%7D+%2B+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%29+%28r_1%2Cr_2%2Cm_2-m_1%29%5E%7B1%2F2%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Similarly, we have

for all 
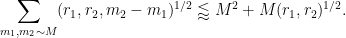
We thus have
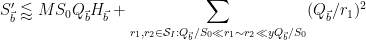
![\displaystyle (\frac{ H_{\vec b}}{[r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2}} + [r_1,r_2]^{1/2} (Q_{\vec b}/r_1)^{1/2}) (M^2 + M (r_1,r_2)^{1/2}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28%5Cfrac%7B+H_%7B%5Cvec+b%7D%7D%7B%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%7D+%2B+%5Br_1%2Cr_2%5D%5E%7B1%2F2%7D+%28Q_%7B%5Cvec+b%7D%2Fr_1%29%5E%7B1%2F2%7D%29+%28M%5E2+%2B+M+%28r_1%2Cr_2%29%5E%7B1%2F2%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
Writing 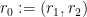

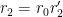

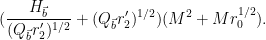
Performing the 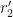
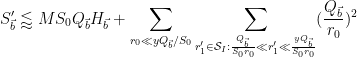
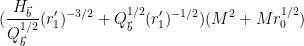
and then performing the 


The net power of 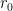



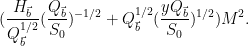
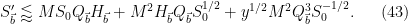
To optimise this in 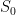
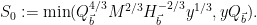
(The quantity 


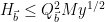
which would follow if

But from (41) one has 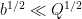
Inserting this value of 

One should view the first term here as the main term. By (42), we conclude that
Since 


From Euler products we see that
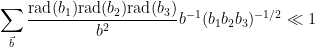
and so to prove (39) it will suffice to show that

We can rewrite these conditions as upper bounds on 
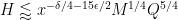


As 
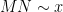

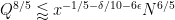

Since 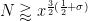
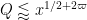
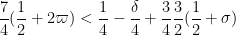
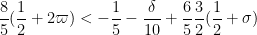
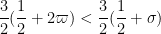
which we may rearrange as

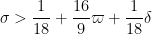

but these follow from (12). The proof of Theorem 6 is complete.

94 comments
Comments feed for this article
8 July, 2013 at 12:13 am
David Roberts
(empty comment to subscribe to email updates)
8 July, 2013 at 12:37 am
g
Probably-clueless question here, motivated purely by aesthetics:
Clearly 2 is a gratuitously specific number :-). What happens if we replace the notion of “doubly dense divisibility” by, let’s call it, “hereditarily dense divisibility”: x is y-HDD iff either x=1 or in every interval [R/y,R] with 1 <= R <= x there is a factor of x that's also y-HDD. It seems like this is stronger than DDD but weaker than y-smoothness (but maybe intuition is deceptive here?).
8 July, 2013 at 9:21 am
Terence Tao
I think this property is equivalent to y-smoothness, since by setting R slightly less than x we see that every y-HDD number is the product of a number in (1,y] and another number which is y-HDD, and hence by induction is y-smooth. So we have a fairly continuous hierarchy of properties, from y-dense divisibility (the weakest), to double y-dense divisibility, to triple y-dense divisibility, …, all the way to hereditary y-dense divisibility or equivalently y-smoothness (the strongest property).
The sieving step can purchase us double y-dense divisibility for almost the same price as y-dense divisibility, but presumably the price keeps rising as we ask for more and more divisibility. For instance, with our current best values of we can purchase double dense divsibility at
we can purchase double dense divsibility at 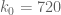 (and single dense divisibility at more or less the same level), whereas smoothness requires
(and single dense divisibility at more or less the same level), whereas smoothness requires  to be 873 or so.
to be 873 or so.
There is a chance that we will need triple or higher dense divisibility if we start iterating the van der Corput process more often than we are doing now, but thus far this seems to have been counterproductive.
8 July, 2013 at 12:55 am
Lior Silberman
Is inequality (12) reversed? Otherwise large values of wouldn’t violate it.
wouldn’t violate it.
8 July, 2013 at 9:28 am
Terence Tao
No, I think the inequalities are the right way for the Type III estimates. The parameter demarcates the border between Type I and Type III; if one increases
demarcates the border between Type I and Type III; if one increases  , then we dump more cases into Type I (which then becomes harder to prove) but take more cases out of Type III (which becomes easier to prove). So the necessary conditions for Type I involve upper bounds on
, then we dump more cases into Type I (which then becomes harder to prove) but take more cases out of Type III (which becomes easier to prove). So the necessary conditions for Type I involve upper bounds on  while the necessary conditions for Type III involve lower bounds, which have to be balanced against each other (and with the combinatorial condition
while the necessary conditions for Type III involve lower bounds, which have to be balanced against each other (and with the combinatorial condition  ) to get the final range of
) to get the final range of  . (Actually, with our current technology, the combinatorial constraint is giving a stronger lower bound than the Type III estimates, so it is not currently a critical priority to try to improve the Type III estimates further.)
. (Actually, with our current technology, the combinatorial constraint is giving a stronger lower bound than the Type III estimates, so it is not currently a critical priority to try to improve the Type III estimates further.)
8 July, 2013 at 4:57 am
Eytan Paldi
Let denotes the number of consecutive prime pairs
denotes the number of consecutive prime pairs
 satisfying
satisfying 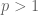 . Since it is known that
. Since it is known that
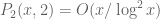 , the next (natural) step is to give an explicit lower bound on the growth of
, the next (natural) step is to give an explicit lower bound on the growth of  for some
for some  , where
, where  is the number of consecutive prime pairs
is the number of consecutive prime pairs 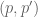 satisfying
satisfying  .
.
(even. should be a great advance!)
should be a great advance!)
8 July, 2013 at 5:14 am
Eytan Paldi
In terms of as defined above, Zhang’s theorem is equivalent to
as defined above, Zhang’s theorem is equivalent to 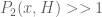 for some
for some  .
.
8 July, 2013 at 6:00 am
Lior Silberman
I haven’t followed all the details, but isn’t the argument producing an H such that, for all x large enough, there is a pair of primes at distance at most H in the interval [x,2x]? That directly gives the bound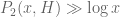 .
.
8 July, 2013 at 6:30 am
Eytan Paldi
You are right of course! (it is interesting that even Bertrand’s postulate shows that Zhang’s theorem implies this seemingly stronger result.)
So perhaps the next step is to find a lower bound on the growth of P_2(x, H) as implied by the best known upper bound on the gap between consecutive primes.
8 July, 2013 at 9:34 am
Terence Tao
Dear Eytan,
You might be interested in this recent paper of Pintz at http://arxiv.org/abs/1305.6289 which discusses what results of this type one can get as consequences of Zhang’s theorem (or variants thereof). In particular, I think the bound of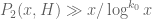 can be obtained from the sieve-theoretic arguments. The arguments of Goldston, Pintz, and Yildirim at http://arxiv.org/abs/1103.5886 should in principle be able to improve this, though I don’t know if we can get the optimal
can be obtained from the sieve-theoretic arguments. The arguments of Goldston, Pintz, and Yildirim at http://arxiv.org/abs/1103.5886 should in principle be able to improve this, though I don’t know if we can get the optimal 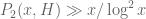 this way. This question is a little outside of the direct scope of the Polymath8 project, but perhaps someone will look into it.
this way. This question is a little outside of the direct scope of the Polymath8 project, but perhaps someone will look into it.
8 July, 2013 at 10:02 am
Eytan Paldi
Dear Terence, Thanks for the information ! (It seems that the conjecture that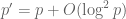 is sufficient to get
is sufficient to get 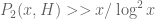 )
)
8 July, 2013 at 11:21 am
Gergely Harcos
@Eytan: Why would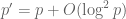 imply
imply  ?
?
8 July, 2013 at 2:08 pm
Eytan Paldi
Assuming the conjecture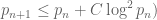 for some absolute constant
for some absolute constant  for each prime
for each prime  . My idea was to define the sequence
. My idea was to define the sequence 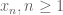 by
by  , starting with sufficiently large
, starting with sufficiently large 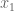 so each interval
so each interval 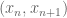 contains a pair of consecutive primes, and the number of such intervals below
contains a pair of consecutive primes, and the number of such intervals below
 is
is  , but (thanks to Gergely question) I realized that the problem is that for each fixed H, the number of H-bounded prime gaps can grow arbitrarily slower than the number of such intervals below
, but (thanks to Gergely question) I realized that the problem is that for each fixed H, the number of H-bounded prime gaps can grow arbitrarily slower than the number of such intervals below  .
.
 .
.
So it is not clear now how to get any explicit lower bound on the growth of
8 July, 2013 at 9:47 am
Eytan Paldi
In my previous comment (8 July, 4:57 am), the definition of should be the number of consecutive prime pairs
should be the number of consecutive prime pairs  satisfying
satisfying
 .
.
8 July, 2013 at 5:30 am
M Flax
In the first formula of definition (2), should log(x) be log(n)?
8 July, 2013 at 12:56 pm
Pace Nielsen
No. By convention, is implicitly a function of
is implicitly a function of  .
.
8 July, 2013 at 8:57 am
Pace Nielsen
Since the current boundary is the the combinatorial bound , it makes sense to see what happens if we replace the approximation
, it makes sense to see what happens if we replace the approximation  in the Type III computations with the weaker
in the Type III computations with the weaker 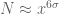 , which avoids the combinatorial obstacles. If we do, the three lower bounds on
, which avoids the combinatorial obstacles. If we do, the three lower bounds on  that we obtain are
that we obtain are
and
and
It appears that there is room to rebalance these inequalities, but only the second one currently surpasses the obstacle.
obstacle.
It would also be interesting to rework the Type III computations but instead of working with three smooth functions use only one or two (with, respectively, ). We would then need to bound formulas involving
). We would then need to bound formulas involving  instead of
instead of  .
.
8 July, 2013 at 2:39 pm
Eytan Paldi
The pages “Dickson -Hardy-Littlewood theorems” and “Distribution of primes in smooth moduli” should be updated according to this post.
[Done, thanks for the suggestion – T.]
9 July, 2013 at 7:13 am
Eytan Paldi
More corrections:
1. In the page “Dickson-Hardy-Littlewood theorems”, in the last title MPZ should be replaced by MPZ”. ),
), 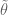 in the last section should be defined (as already suggested by Gergely Harcos) as the minimum between its current expression and 1.
in the last section should be defined (as already suggested by Gergely Harcos) as the minimum between its current expression and 1.
Also (to ensure that
2. In the page “Distribution of primes in smooth moduli”, in the second line MPZ” should also be mentioned. Also the definition of MPZ” should also be added as well as the definitions of and
and 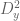 .
.
[Corrected, thanks – T.]
9 July, 2013 at 9:50 am
Gergely Harcos
Let me clarify. Regarding Theorem 5 and its later variant of the earlier thread (https://terrytao.wordpress.com/2013/06/18/a-truncated-elementary-selberg-sieve-of-pintz/) I suggested that there was no need to redefine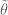 , because
, because  . The wiki page (http://michaelnielsen.org/polymath1/index.php?title=Dickson-Hardy-Littlewood_theorems) is a slightly different issue, because the Maple code there contains an upper bound for
. The wiki page (http://michaelnielsen.org/polymath1/index.php?title=Dickson-Hardy-Littlewood_theorems) is a slightly different issue, because the Maple code there contains an upper bound for  rather than its actual value. On the other hand, this upper bound is increasing in
rather than its actual value. On the other hand, this upper bound is increasing in 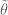 (it is the antiderivative of a nonnegative function), hence if
(it is the antiderivative of a nonnegative function), hence if 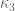 is admissible for some
is admissible for some  , then it is admissible for the redefined
, then it is admissible for the redefined  as well. This means that the Maple code worked fine in its original form (i.e. without taking the minimum of
as well. This means that the Maple code worked fine in its original form (i.e. without taking the minimum of 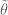 and
and  ), but of course it is more efficient in its current updated form.
), but of course it is more efficient in its current updated form.
9 July, 2013 at 11:08 am
Eytan Paldi
Thank you! (now I understand it better.)
8 July, 2013 at 9:00 pm
Pace Nielsen
I believe that in the Type I estimate bounds should be
in the Type I estimate bounds should be  .
.
[Sorry about this, actually the is I think correct, but in the display deriving it at the bottom of Section 2, I had an
is I think correct, but in the display deriving it at the bottom of Section 2, I had an 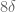 where there should have been a
where there should have been a  instead, which I’ve now corrected. -T.]
instead, which I’ve now corrected. -T.]
8 July, 2013 at 11:32 pm
James Hilferty
Is all this not a little fruitless and over complicated? I have a far simpler sum, namely the Black-Scholes formula. No one has actually disproved it and for a theorem which never worked at anytime just look at all the damage it caused to the financial system. I was just recently looking at JP Morgan’s “Var” formula and they admit that there is no accurate method at predicting the price “volatility” of a future’s option and you all are trying to do something similar with your new (?) probability theorem. What do you all think?
9 July, 2013 at 7:35 am
Anonymous
I admire your imagination but deplore your ignorance.
9 July, 2013 at 9:26 am
Terence Tao
As usual, I am recording the critical numerology, i.e. the endpoint case that we currently can’t treat with our methods. Setting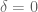 for simplicity, this is
for simplicity, this is  and
and 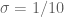 . In the Heath-Brown decomposition, the enemy here is either a “Type IV” expression of the form
. In the Heath-Brown decomposition, the enemy here is either a “Type IV” expression of the form  where
where 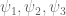 are smooth and supported at scale
are smooth and supported at scale  and
and  is smooth and supported at scale
is smooth and supported at scale  , or a “Type V” sum of the form
, or a “Type V” sum of the form  where all of the
where all of the  are smooth and supported at scale
are smooth and supported at scale 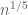 . While it looks like the Type IV sum is treatable from the Type I method by exploiting the additional smoothness of
. While it looks like the Type IV sum is treatable from the Type I method by exploiting the additional smoothness of 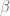 in this case, it does not seem that this is available for the Type V sum, which is also far from being treatable by Type III methods.
in this case, it does not seem that this is available for the Type V sum, which is also far from being treatable by Type III methods.
If we attack the Type V sum by Type I methods, we factor it as where
where 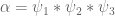 is supported at scale
is supported at scale  , and
, and 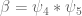 is supported at scale
is supported at scale  . The modulus
. The modulus  has magnitude
has magnitude 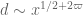 and is factored as
and is factored as 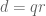 , where
, where 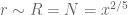 (ignoring epsilons) and so
(ignoring epsilons) and so 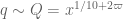 . After various Cauchy-Schwarz type manipulations, our task is then to show that
. After various Cauchy-Schwarz type manipulations, our task is then to show that
where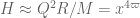 , and we may take
, and we may take  to be coprime as the dominant case (so
to be coprime as the dominant case (so 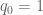 ). Thus we need to gain about
). Thus we need to gain about  over the trivial bound. There is also some additional averaging in the k and r parameters (the k averaging is over a negligible range, but r ranges over scales
over the trivial bound. There is also some additional averaging in the k and r parameters (the k averaging is over a negligible range, but r ranges over scales 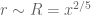 and is potentially useful) but we currently do not know how to exploit this extra averaging. The phase
and is potentially useful) but we currently do not know how to exploit this extra averaging. The phase  is periodic with period
is periodic with period  .
.
The way we are currently treating the Type I sum, we are factoring with
with 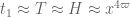 and
and 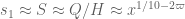 . After Cauchy-Schwarz, we are reduced to showing that
. After Cauchy-Schwarz, we are reduced to showing that
thus we need to save a factor of over the trivial bound. Thus, on average, we need to obtain an exponential sum estimate of the form
over the trivial bound. Thus, on average, we need to obtain an exponential sum estimate of the form
where is an explicit but slightly messy phase of period
is an explicit but slightly messy phase of period  . With the particular choice of
. With the particular choice of  , we have
, we have 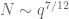 and
and  , so our objective is to prove something like
, so our objective is to prove something like
for an “average” phase of period
of period  (as a zeroth approximation, think of the model case
(as a zeroth approximation, think of the model case 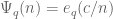 where
where  ranges over a shortish interval, say of length
ranges over a shortish interval, say of length 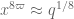 ). This is currently being treated by the van der Corput estimate, which roughly has the shape
). This is currently being treated by the van der Corput estimate, which roughly has the shape
which doesn’t save the epsilon, and is ultimately why we just barely fail to make reach
reach 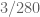 . So the basic challenge is to do better than (*) when
. So the basic challenge is to do better than (*) when 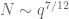 , possibly after exploiting the additional averaging in the
, possibly after exploiting the additional averaging in the 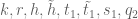 parameters that are available. But these parameters are hard to exploit: the k averaging is negligible, the
parameters that are available. But these parameters are hard to exploit: the k averaging is negligible, the 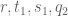 averages are substantial but affect the modulus which is bad, leaving only the
averages are substantial but affect the modulus which is bad, leaving only the  averaging which looks promising but is only over a fairly short range. A model problem would be to obtain a bound of the form
averaging which looks promising but is only over a fairly short range. A model problem would be to obtain a bound of the form
for a “typical” sufficiently smooth modulus , whatever “typical” means. (Here we are implicitly using smooth cutoffs where necessary, and adopting the convention that
, whatever “typical” means. (Here we are implicitly using smooth cutoffs where necessary, and adopting the convention that  vanishes when
vanishes when  is not coprime to
is not coprime to  .)
.)
9 July, 2013 at 10:40 am
Terence Tao
By chance I happened to attend a nice talk by Igor Shparlinski while at Budapest in which he gave a nice summary of the start of the art on how to estimate multidimensional incomplete exponential sums (though he focused primarily on the prime modulus case rather than the smooth modulus case). In addition to the standard technique of completion of sums, he also mentioned Vinogradov-type techniques (which are traditionally used to estimate exponential sums over the integers, e.g. for Waring’s problem or in bounding the zeta function, but can also give non-trivial results in finite fields), as well as the sum-product methods of Bourgain and co-authors (but this requires a lot of multiplicative structure), and also the Burgess type arguments (again this requires some sort of multiplicativity in the phase though).
Another route is to develop the q-van der Corput theory more fully, basically replicating the theory of exponent pairs in the q-setting. There are some exponent pairs that are known that are not obtainable from the standard A- and B- processes (e.g. the work of Huxley and Watt). These may end up being a bit complicated to execute though (if we do too many fancy manipulations, the dependence on is eventually going to hurt us; also, the Deligne-type exponential sum we will need to control at the end gets more and more complicated, though perhaps there is only a finite amount of algebraic geometry verification to be done for each specific application of this machinery).
is eventually going to hurt us; also, the Deligne-type exponential sum we will need to control at the end gets more and more complicated, though perhaps there is only a finite amount of algebraic geometry verification to be done for each specific application of this machinery).
One route that looks moderately promising to me is to try to combine the van der Corput A-process that we are currently using with the additional averaging in auxiliary parameters such as that we are currently unable to exploit (I called this a “Level 5” Type I estimate on the wiki). This should attenuate the diagonal contribution which should allow for some rebalancing of parameters that takes some of the load off of the off-diagonal contribution. (This trick already was used to good effect on the Type III sums.) I’ve tried to do this a few times in the last few days, but the problem has always been that the parameters being averaged over are over a shorter range than the difference
that we are currently unable to exploit (I called this a “Level 5” Type I estimate on the wiki). This should attenuate the diagonal contribution which should allow for some rebalancing of parameters that takes some of the load off of the off-diagonal contribution. (This trick already was used to good effect on the Type III sums.) I’ve tried to do this a few times in the last few days, but the problem has always been that the parameters being averaged over are over a shorter range than the difference  that one is Weyl differencing over so no additional gain could be extracted, but I did not exhaust all the possible permutations of this strategy.
that one is Weyl differencing over so no additional gain could be extracted, but I did not exhaust all the possible permutations of this strategy.
ADDED LATER: I forgot to add automorphic forms techniques (or “Kloostermania”) as a possible further technique which can exploit averaging in the modulus although once one moves away from the model problem and starts considering more realistic sums such as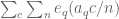 where
where  varies with
varies with  in a manner consistent with the Chinese remainder theorem, my understanding is that these methods become significantly more difficult to deploy.
in a manner consistent with the Chinese remainder theorem, my understanding is that these methods become significantly more difficult to deploy.
9 July, 2013 at 10:52 am
Pace Nielsen
Dear Terry,
Thank you for this analysis. I’ll try to absorb it more fully over the next week. In the meantime I did have a few questions (some perhaps easier to answer than others).
1. I’m a little weak on when it is allowable to use the Linnik decomposition rather than the Heath-Brown decomposition. Assuming that we can use the Linnik decomp., is there any extra information we gain that helps in these analyses? For instance, do we gain any insight into the scales involved in the coefficient sequences?
2. In your computations above, you take . Another option would be to take
. Another option would be to take  and try to take advantage of the smoothness of
and try to take advantage of the smoothness of 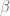 . Does the smoothness (and thus avoidance of an extra Cauchy-Schwarz) make up for the smaller scale size? Or is this just a pipe dream?
. Does the smoothness (and thus avoidance of an extra Cauchy-Schwarz) make up for the smaller scale size? Or is this just a pipe dream?
3. Perhaps a better way to take advantage of the smoothness would instead be to modify the Type III computations from to
to 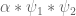 or
or  (with
(with  of scale
of scale 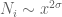 ). This would replace bounds on
). This would replace bounds on  with needing bounds on
with needing bounds on  , which seem to be much more controllable. (Again, this might be a pipe dream.)
, which seem to be much more controllable. (Again, this might be a pipe dream.)
Best wishes,
Pace
9 July, 2013 at 7:54 pm
Terence Tao
Dear Pace,
1. Morally speaking the Linnik decomposition should work in these arguments, but it has infinitely many terms and there is basically no hope of controlling sums involving the divisor function with a really good dependence on k. Note for instance that
with a really good dependence on k. Note for instance that  is (conjecturally on the Mobius pseudorandomness conjecture) believed to be
is (conjecturally on the Mobius pseudorandomness conjecture) believed to be  for any fixed
for any fixed  (with the decay rate being highly non-uniform in
(with the decay rate being highly non-uniform in  ), while
), while  is certainly not
is certainly not  , so one can’t hope to use Linnik to get good estimates for
, so one can’t hope to use Linnik to get good estimates for  from good estimates for
from good estimates for  .
.
2. Let’s do a quick computation. If one halts the Type I argument before the final Cauchy-Schwarz, the objective in the critical case is to obtain an estimate roughly of the form
for some phase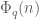 of period
of period  , where
, where  . If
. If 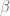 is smooth, one can use the completion of sums bound
is smooth, one can use the completion of sums bound
which suggests the constraint
which rearranges to
If we instead use the van der Corput bound
then we are led to the constraint
which becomes
This is a bit better than the current Type I constraint of , with
, with  , it allows us to take
, it allows us to take  as large as
as large as  when
when 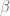 is smooth, so we can basically handle any configuration
is smooth, so we can basically handle any configuration 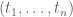 of exponents with
of exponents with 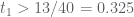 . That’s not bad – it should dispose of most of the “Type IV” type sums we will encounter – but still quite far from dealing with the tuple
. That’s not bad – it should dispose of most of the “Type IV” type sums we will encounter – but still quite far from dealing with the tuple  which would basically require stretching
which would basically require stretching  to be as large as
to be as large as  .
.
If we apply the next iteration of van der Corput, this gives
leading to the constraint
which rearranges as
which, at , gets
, gets  as large as
as large as  , which is actually worse than what we got with just one van der Corput (which is consistent with the other times that we have tried iterated van der Corput, the gain in the
, which is actually worse than what we got with just one van der Corput (which is consistent with the other times that we have tried iterated van der Corput, the gain in the  aspect is generally outweighed by the loss in the
aspect is generally outweighed by the loss in the  aspect). So we’re not making much progress here towards stretching the Type I sums all the way to the
aspect). So we’re not making much progress here towards stretching the Type I sums all the way to the 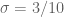 case when
case when 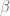 is smooth.
is smooth.
One last numerology check: if we assume the most optimistic exponential sum bound (the Hooley conjecture)
one gets
which clears the bar with room to spare ( can now be as large as
can now be as large as 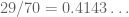 ). So there is hope, but it does require quite strong exponential sum estimates.
). So there is hope, but it does require quite strong exponential sum estimates.
3. I haven’t given this a shot yet, but I’ll take a look at the suggestion.
10 July, 2013 at 10:15 am
Pace Nielsen
Dear Terry,
Thank you for working this out. It appears that I wasn’t conveying myself well, since my question #2 was about a lower bound on , not upper bounds. However, your answer was still extremely helpful for me, and hopefully will help me explain my idea a bit better.
, not upper bounds. However, your answer was still extremely helpful for me, and hopefully will help me explain my idea a bit better.
For simplicity I’m going to ignore all the ‘s and
‘s and  ‘s.
‘s.
As you know, the combinatorial data gives a natural meeting place between the Type I/II and Type III sums, which can be thought of as given, respectively, by upper and lower bounds on . The Type III sums arise from consideration of how many smooth sequences have scales somewhere in the range
. The Type III sums arise from consideration of how many smooth sequences have scales somewhere in the range ![[x^{2\sigma},x^{1/2-\sigma}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B2%5Csigma%7D%2Cx%5E%7B1%2F2-%5Csigma%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) . If there are too few (or too many) such sequences (and
. If there are too few (or too many) such sequences (and 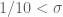 ), then we can reduce to the Type I/II bounds. On the other hand, if there are exactly three sequences in this range, we can then either again reduce to the Type I/II bounds, or we have that the product of the three scales is at least
), then we can reduce to the Type I/II bounds. On the other hand, if there are exactly three sequences in this range, we can then either again reduce to the Type I/II bounds, or we have that the product of the three scales is at least  which we call the Type III case.
which we call the Type III case.
My idea is to forget about some of this information in exchange for weaker combinatorial restrictions. So, for example, when we are in the Type III situation I forget about the fact that there are three smooth sequences in the range![[x^{2\sigma},x^{1/2-\sigma}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B2%5Csigma%7D%2Cx%5E%7B1%2F2-%5Csigma%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) for which the product of the scales is fairly large, and instead only retain the information that there is a single smooth sequence in the range. This is clearly going to lead to inequalities worse than the usual Type III bounds, but as the current restriction occurs between the Type I bounds and
for which the product of the scales is fairly large, and instead only retain the information that there is a single smooth sequence in the range. This is clearly going to lead to inequalities worse than the usual Type III bounds, but as the current restriction occurs between the Type I bounds and 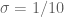 , this might not be too bad.
, this might not be too bad.
So, now let's work through the numerology. We have . Similarly,
. Similarly,  since we are ignoring
since we are ignoring  . We also have
. We also have  , where
, where 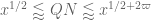 . Finally,
. Finally, 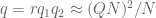 . Now let's consider the four types of bounds from your post.
. Now let's consider the four types of bounds from your post.
————**Completion of sums**—————
We need . This leads to
. This leads to 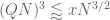 . Hence
. Hence
This, in conjunction with the given Type I bound, yields which is worse than what we normally get.
which is worse than what we normally get.
————–**van der Corput once**—————-
We need . This leads to
. This leads to 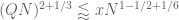 . Hence
. Hence
This, in conjunction with the given Type I bound, yields .
.
—————–**van der Corput twice**—————-
We need . This leads to
. This leads to  . Hence
. Hence
This, in conjunction with the given Type I bound, yields , which is worse than the single van der Corput.
, which is worse than the single van der Corput.
Notice further that in all three cases we never surpass the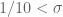 bound.
bound.
—————-**Hooley Conjecture**———————
We need . This leads to
. This leads to  . Hence
. Hence
In this case, it appears that we can actually remove all of the Type I considerations and reduce to the Type II sums!
10 July, 2013 at 11:57 am
Terence Tao
In case you’re interested, the general form of the van der Corput estimate (assuming as much smoothness as needed) is
so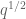 for
for 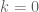 (completion of sums),
(completion of sums), 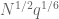 for
for 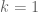 (single van der Corput),
(single van der Corput),  for
for 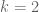 (double van der Corput),
(double van der Corput),  for
for  , and so forth. I believe one would eventually push
, and so forth. I believe one would eventually push  down as low as desired by continually iterating van der Corput, but it becomes exponentially expensive in
down as low as desired by continually iterating van der Corput, but it becomes exponentially expensive in  to do so, so unfortunately it is not a net win. (However if one just wants to prove Zhang’s theorem and don’t care how small
to do so, so unfortunately it is not a net win. (However if one just wants to prove Zhang’s theorem and don’t care how small  (or
(or  ) has to be, I think we now have the technology to do so entirely using the Type II argument, and we could even replace the completion of sums bound
) has to be, I think we now have the technology to do so entirely using the Type II argument, and we could even replace the completion of sums bound 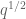 by the weaker, but more elementary, Kloosterman bound of
by the weaker, but more elementary, Kloosterman bound of 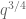 that avoids the Weil conjectures completely.)
that avoids the Weil conjectures completely.)
10 July, 2013 at 3:11 pm
Terence Tao
I played around a little with item 3, i.e. modifying the Type III computations to deal with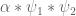 or
or  instead of
instead of  . This is like asking for averaged distribution results for the trivial divisor function
. This is like asking for averaged distribution results for the trivial divisor function  or the classical divisor function
or the classical divisor function  rather than the third order divisor function
rather than the third order divisor function 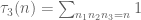 . It turns out that while the distribution results for the former functions are indeed better than the latter, this is more than compensated by the fact that a much smaller portion of the total convolution is actually coming from the divisor function in these cases, so it doesn’t look like a win.
. It turns out that while the distribution results for the former functions are indeed better than the latter, this is more than compensated by the fact that a much smaller portion of the total convolution is actually coming from the divisor function in these cases, so it doesn’t look like a win.
To illustrate what is going on let us revert to “Level 3” Type III estimates that do not exploit the alpha averaging. Fouvry, Kowalski, Michel, and Nelson showed that has a level of distribution of 4/7 for smooth moduli, which roughly speaking means that they have good control on
has a level of distribution of 4/7 for smooth moduli, which roughly speaking means that they have good control on 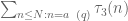 on average for
on average for  . This allows one to get good distribution results for
. This allows one to get good distribution results for  for moduli
for moduli 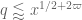 , where each
, where each  is supported at scale
is supported at scale 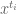 , provided that
, provided that
Now suppose we work instead with . Here the classical result of Linnik and Selberg is that the level of distribution is at least 2/3. (Sketch of proof: one basically needs to estimate
. Here the classical result of Linnik and Selberg is that the level of distribution is at least 2/3. (Sketch of proof: one basically needs to estimate  to accuracy
to accuracy 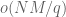 when
when 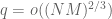 . Assuming
. Assuming  , we can perform Fourier summation and reduce to estimating
, we can perform Fourier summation and reduce to estimating 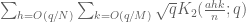 to accuracy
to accuracy  , where
, where  is the normalised Kloosterman sum
is the normalised Kloosterman sum
If one then uses the Weyl bound (ignoring the zero frequency contribution
(ignoring the zero frequency contribution 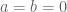 ), we obtain the desired claim.) For smooth moduli, Fouvry and Iwaniec (and Katz) improved the 2/3 slightly to 2/3+1/48, and perhaps with Zhang's new arguments one can push this a bit further, but let's work with the 2/3 number for now. This gives good estimates for
), we obtain the desired claim.) For smooth moduli, Fouvry and Iwaniec (and Katz) improved the 2/3 slightly to 2/3+1/48, and perhaps with Zhang's new arguments one can push this a bit further, but let's work with the 2/3 number for now. This gives good estimates for 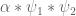 when
when
This constraint is better in that the 4/7 is improved to a 2/3, but worse in that we are only summing two of the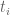 instead of one. In the model case
instead of one. In the model case 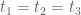 we end up significantly worse off if we try to use this estimate.
we end up significantly worse off if we try to use this estimate.
Finally, if we work with , this trivially has level of distribution 1, so we obtain a good estimate for
, this trivially has level of distribution 1, so we obtain a good estimate for  when
when
This is the Type 0 estimate that we are already using. Again, the 4/7 or 2/3 factor has been improved to 1, but at the cost of now only using one of the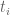 , so this is not a win in the cases we need the most badly.
, so this is not a win in the cases we need the most badly.
Finally, for we do not have level of distribution results better than 1/2 for smooth moduli (though in principle the Type I/II/III estimates we have should give us something which is at least as good as the estimates we have for MPZ, and perhaps a little bit better because the pesky Type V sums don’t appear for
we do not have level of distribution results better than 1/2 for smooth moduli (though in principle the Type I/II/III estimates we have should give us something which is at least as good as the estimates we have for MPZ, and perhaps a little bit better because the pesky Type V sums don’t appear for  – actually, it might be worth having a look to see what numerology we can get for
– actually, it might be worth having a look to see what numerology we can get for  , as this may offer a benchmark as to what to hope to get for
, as this may offer a benchmark as to what to hope to get for  ), so we only get
), so we only get
which is in fact never satisfied for any positive .
.
The numerology changes a bit if we use the latest Type III estimates but I think the general picture is more or less the same.
10 July, 2013 at 4:41 pm
Pace Nielsen
Thanks once again for answering my questions. What seems surprising to me is how badly the constants work out in the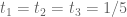 case. Perhaps more surprising to me is that even though the Type III summation techniques have been optimized to improve the lower bound on
case. Perhaps more surprising to me is that even though the Type III summation techniques have been optimized to improve the lower bound on  , we seem to do better using the techniques from the Type I case when we are restricted to two sequences. That is, when trying to deal with sums involving
, we seem to do better using the techniques from the Type I case when we are restricted to two sequences. That is, when trying to deal with sums involving 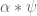 with
with  smooth of scale
smooth of scale  , we get better bounds trivially modifying the Type I techniques rather than using the techniques for Type III. Unfortunately, even if it were the case that some methods from the Type I analysis made the Type III analysis turn out better, that isn’t the current point of conflict.
, we get better bounds trivially modifying the Type I techniques rather than using the techniques for Type III. Unfortunately, even if it were the case that some methods from the Type I analysis made the Type III analysis turn out better, that isn’t the current point of conflict.
Thank you for your very clear analysis. It appears that to make any headway on the Type V sums, we would need to improve the level of distribution for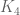 quite a bit (or to get Hooley’s conjecture and skip it all).
quite a bit (or to get Hooley’s conjecture and skip it all).
9 July, 2013 at 11:29 pm
Sniffnoy
Just a question from an interested onlooker: Everything since H=12006 has been marked “?”. What part of H=5414 is still unconfirmed?
10 July, 2013 at 8:26 am
Terence Tao
Basically, these later bounds rely on the Type I, II and III estimates described first in a number of scattered blog comments, and then finally compiled in one place in this blog post. So far, none of the other participants of the project have confirmed these estimates (they are somewhat lengthy, and there are a number of places where an arithmetic error could occur; I myself found a few minor ones when converting the comments to the blog format), but this will presumably happen eventually. (It’s not as if we are racing against time here.)
10 July, 2013 at 5:00 pm
Terence Tao
I think I figured out a way (in principle, at least, subject to the verification of some Deligne-level exponential sum estimates) to improve the van der Corput estimate
for smooth functions at some scale
at some scale 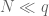 and some reasonable phase
and some reasonable phase 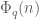 (e.g. the Kloosterman phase
(e.g. the Kloosterman phase 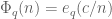 ) periodic with a smooth period
) periodic with a smooth period  , very slightly to
, very slightly to
if one is allowed to do some averaging in the q aspect, and if one ignores the role of . As far as the Type I sums are concerned, this would improve the constraint
. As far as the Type I sums are concerned, this would improve the constraint
(or equivalently, ) to
) to
(or equivalently ). Playing this against
). Playing this against  , this suggests that we can improve
, this suggests that we can improve  from
from 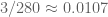 to
to 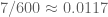 – not much, but better than nothing. (Using xfxie’s table at http://www.cs.cmu.edu/~xfxie/project/admissible/k0table.html , this should correspond to
– not much, but better than nothing. (Using xfxie’s table at http://www.cs.cmu.edu/~xfxie/project/admissible/k0table.html , this should correspond to  somewhere near 630, which by the prime tuples page at http://math.mit.edu/~primegaps/ suggests a value of
somewhere near 630, which by the prime tuples page at http://math.mit.edu/~primegaps/ suggests a value of  somewhere near 4660. But this is an extremely rough back-of-the-envelope calculation.)
somewhere near 4660. But this is an extremely rough back-of-the-envelope calculation.)
To explain the strategy, let me make the general remark that much of the game here is trying to estimate averaged exponential sums such as
where the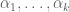 are various weights at various scales
are various weights at various scales  and
and 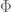 is some explicit algebraic phase depending on
is some explicit algebraic phase depending on  ; also the modulus
; also the modulus  is also allowed to depend on one or more of the
is also allowed to depend on one or more of the  parameters. The various averages
parameters. The various averages  can be informally divided into various types:
can be informally divided into various types:
* “smooth” averages (in which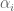 is smooth) and “rough” averages (in which
is smooth) and “rough” averages (in which 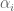 has no smoothness).
has no smoothness).
* “long” averages (in which is large) and “short” averages (in which
is large) and “short” averages (in which  is small).
is small).
* “non-modulus-altering” averages (in which does not depend on
does not depend on 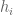 ) and “modulus-altering” averages (in which
) and “modulus-altering” averages (in which  does depend on
does depend on 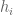 ).
).
Basically, we want to have smooth long non-modulus-altering averages around, because there are a lot of techniques available (e.g. completion of sums) for exploiting such averaging. In contrast, averages that are rough, short, and/or modulus-altering are not easy to exploit directly and so often just have to be discarded through the triangle inequality. However, the Cauchy-Schwarz inequality and its variants (e.g. Weyl differencing, dispersion method, or Holder’s inequality) can often be used to convert a “bad” average to a “good” average, albeit at the cost of “square-rooting” any gain one gets (and often the modulus grows a little bit after one applies Cauchy-Schwarz). So the game is to use Cauchy-Schwarz as sparingly as possible to extract one or more “good” averages that one can then squeeze some cancellation out of (which, in all of our arguments so far, is only obtainable by using completion of sums combined with the Weil conjectures).
grows a little bit after one applies Cauchy-Schwarz). So the game is to use Cauchy-Schwarz as sparingly as possible to extract one or more “good” averages that one can then squeeze some cancellation out of (which, in all of our arguments so far, is only obtainable by using completion of sums combined with the Weil conjectures).
The point is that when one applies the van der Corput method once, there is a moderately long smooth average in a parameter which manages to not alter the modulus. After using Fourier inversion to deal with another long smooth average, we can then deal with the moderately long smooth average by a second van der Corput. (In principle one could keep iterating this procedure, but it is already rather complicated as it is so I won’t try to do so here.)
which manages to not alter the modulus. After using Fourier inversion to deal with another long smooth average, we can then deal with the moderately long smooth average by a second van der Corput. (In principle one could keep iterating this procedure, but it is already rather complicated as it is so I won’t try to do so here.)
OK, to the details. We will study the averaged sum
We factor where
where 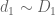 ,
, 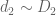 , and
, and  is to be optimised in later, though we assume we are in the regime
is to be optimised in later, though we assume we are in the regime  which is the regime of interest when applying van der Corput. We throw away the
which is the regime of interest when applying van der Corput. We throw away the 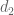 averaging and just average in
averaging and just average in  , thus we need to bound
, thus we need to bound
for a given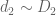 .
.
We perform Weyl differencing in the direction and end up staring at
direction and end up staring at
Pulling out the n summation from the absolute values and then applying Cauchy-Schwarz, we can bound this by
The diagonal term contributes
contributes  . For the off-diagonal terms, we crucially note (as in previous applications of van der Corput) that the
. For the off-diagonal terms, we crucially note (as in previous applications of van der Corput) that the  component of the phases cancel, and the phase
component of the phases cancel, and the phase  collapses to something like
collapses to something like  , so we are now looking at
, so we are now looking at
for the off-diagonal contribution, where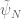 is some smooth cutoff function whose exact form is not too important here. If we estimate this by completion of sums, we get an additional term of
is some smooth cutoff function whose exact form is not too important here. If we estimate this by completion of sums, we get an additional term of  , giving the van der Corput bound of
, giving the van der Corput bound of  which optimises to
which optimises to  as before. To do better than this, we first deal with the n summation by Fourier inversion, rewriting the above as something like
as before. To do better than this, we first deal with the n summation by Fourier inversion, rewriting the above as something like
where is the Kloosterman-type sum
is the Kloosterman-type sum
The point is that the summation is a moderately long smooth average (of length vaguely comparable to
summation is a moderately long smooth average (of length vaguely comparable to  or so) that does not affect the modulus of
or so) that does not affect the modulus of  , and so (assuming certain Deligne-level estimates are OK) we expect a van der Corput bound of the form
, and so (assuming certain Deligne-level estimates are OK) we expect a van der Corput bound of the form
which if one does the arithmetic gives a bound of for the off-diagonal terms. We have thus bounded the original exponential sum by
for the off-diagonal terms. We have thus bounded the original exponential sum by
which optimises to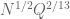 as claimed by setting
as claimed by setting  and
and 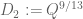 .
.
10 July, 2013 at 5:37 pm
Anonymous
Terry, Let’s do a trade, I go to ucla to learn math from you, you learn Cantonese from me, OK?
10 July, 2013 at 7:38 pm
Pace Nielsen
What prevents one from starting with a rough sequence, and then introducing a smooth sequence at the Cauchy-Schwarz step, as has been done in the past? (I initially thought there might be problems as now depends not only on
depends not only on  but also
but also  . But if that were the issue, wouldn’t it also cause problems in the Fourier inversion step as well? I’m probably just missing something simple here.)
. But if that were the issue, wouldn’t it also cause problems in the Fourier inversion step as well? I’m probably just missing something simple here.)
10 July, 2013 at 8:29 pm
Terence Tao
Yes, one can use Cauchy-Schwarz to convert all sorts of rough sequences to smooth sequences, but it can cause some of the other averages to be duplicated, and more importantly it square roots the gain one gets at the end of the day (or equivalently, it doubles the amount of gain one now has to produce to meet one’s original objectives). For instance, if one had to gain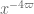 over the trivial bound for an averaged exponential sum involving a rough sequence and then used Cauchy-Schwarz to make the rough sequence smooth, one would now have to gain
over the trivial bound for an averaged exponential sum involving a rough sequence and then used Cauchy-Schwarz to make the rough sequence smooth, one would now have to gain  over the trivial bound (this is how the Type I and Type II arguments eliminate the rough sequence
over the trivial bound (this is how the Type I and Type II arguments eliminate the rough sequence  ).
).
In the van der Corput analysis above, it turns out that all the relevant sequences are already smooth; we need Cauchy-Schwarz to perform Weyl differencing but not to eliminate rough sequences (well actually there is a rough sequence implicit in the summation (which lies outside the absolute values) that is eliminated by the Cauchy-Schwarz that performs the Weyl differencing, so the Cauchy-Schwarz is actually doing double duty here).
summation (which lies outside the absolute values) that is eliminated by the Cauchy-Schwarz that performs the Weyl differencing, so the Cauchy-Schwarz is actually doing double duty here).
16 July, 2013 at 8:19 am
Philippe Michel
I think, the required Deligne type estimates are valid here: the Kloosterman type sum that occurs say (the Fourier transform of a fraction looking like
say (the Fourier transform of a fraction looking like  for
for 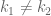 ) is the Frobenius trace function of a sheaf which has a singularity at
) is the Frobenius trace function of a sheaf which has a singularity at 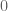 .
.
Now the VdC method amounts to knowing whether some non-trivial additive shift of K can correlate with K times a(ny) additive character (then, in absence of correlation, Deligne bootstraps this to square root cancellation). This is equivalent to deciding whether or not the additive shift of the sheaf underlying is geometrically isomorphic to the tensor product of itself with the trivial or any Artin-Schreier sheaf. In particular these isomorphic sheaves would have the same singularities on the affine line (since additive translation fixes infinity). The Artin-Schreier sheaf has no singularities on the affine line (hence cannot “destroy” any of the affine singularities of
is geometrically isomorphic to the tensor product of itself with the trivial or any Artin-Schreier sheaf. In particular these isomorphic sheaves would have the same singularities on the affine line (since additive translation fixes infinity). The Artin-Schreier sheaf has no singularities on the affine line (hence cannot “destroy” any of the affine singularities of  in the tensor product), that means that the set of affine singularities of
in the tensor product), that means that the set of affine singularities of  (which is non-empty) would have to be invariant under non-trivial additive translation and in particular would cover the whole finite field which is not possible (if
(which is non-empty) would have to be invariant under non-trivial additive translation and in particular would cover the whole finite field which is not possible (if  is large enough). There are probably other arguments possible but that one is fairly general.
is large enough). There are probably other arguments possible but that one is fairly general.
These sort of things will be explained in more details in my lectures tomorrow.
16 July, 2013 at 10:55 am
Terence Tao
Great! Looking forward to your lectures (at Caltech) tomorrow; this sheaf-based perspective to Deligne type estimates does indeed seem to be very well suited for analytic number theory, as all the basic operations on phases or Kloosterman sums on finite fields (e.g. Weyl differencing, pointwise multiplication, Fourier transforms, or computing correlations) seem to have natural geometric counterparts on the associated sheaves. Will definitely be taking notes :)
17 July, 2013 at 6:49 pm
Terence Tao
Dear Philippe,
After your very nice lectures (I now understand the role of l-adic sheaves a lot better now!) I tried to flesh out the Deligne-level estimates needed for the multiple van der Corput, but unfortunately I found that the sheaf Fourier transform of Deligne, Laumon, and Katz isn’t quite appropriate for the correlation sum needed, because I need the sheaf to run over a different variable than the Fourier variable.
Let me explain with the model problem of estimating an averaged incomplete Kloosterman sum
(being vague about smooth cutoffs etc.), and with smooth. We factor
smooth. We factor  for some suitable
for some suitable 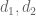 of a certain magnitude
of a certain magnitude  and throw away the
and throw away the 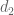 averaging, leaving us with
averaging, leaving us with
For the inner sum we perform the q-van der Corput A-process in the direction, which leaves us with the task of bounding things like
direction, which leaves us with the task of bounding things like
for some non-zero (one could conceivably try to exploit averaging in the
(one could conceivably try to exploit averaging in the  parameter, but I will not attempt this here). As usual, the modulus of the phase collapses from
parameter, but I will not attempt this here). As usual, the modulus of the phase collapses from  to
to 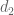 (which is the whole point of the q-van der Corput process):
(which is the whole point of the q-van der Corput process):
Now we perform completion of sums in the n variable and end up with things like
for various (again, we will not attempt to exploit averaging in
(again, we will not attempt to exploit averaging in  , it is quite a short average in practice). So we need to control something like
, it is quite a short average in practice). So we need to control something like
where is the Kloosterman-type sum
is the Kloosterman-type sum
Now, the Deligne-Laumon-Katz theorem lets us express as the trace of a Frobenius of a lisse sheaf in the h variable, but unfortunately that’s the wrong variable; we instead need a sheaf interpretation of
as the trace of a Frobenius of a lisse sheaf in the h variable, but unfortunately that’s the wrong variable; we instead need a sheaf interpretation of  in the b variable. That’s not obviously a Fourier transform, so DLK does not directly apply. It’s still the pushforward of a two-dimensional sheaf, though, so in principle one can still view it as a one-dimensional sheaf (though it may be a bit harder to track the singularities – presumably Laumon’s sheaf-theoretic stationary phase still applies though? Also, it may be trickier to maintain geometric irreducibility in this variable, since we don’t have the Plancherel trick any more).
in the b variable. That’s not obviously a Fourier transform, so DLK does not directly apply. It’s still the pushforward of a two-dimensional sheaf, though, so in principle one can still view it as a one-dimensional sheaf (though it may be a bit harder to track the singularities – presumably Laumon’s sheaf-theoretic stationary phase still applies though? Also, it may be trickier to maintain geometric irreducibility in this variable, since we don’t have the Plancherel trick any more).
17 July, 2013 at 10:29 pm
Philippe Michel
Oh I see; sorry, I took the wrong variable; thanks for correcting. I will look at the right problem now.
18 July, 2013 at 2:54 am
Gergely Harcos
Dear Philippe and Terry, it would be nice and useful to have a brief account of the l-adic techniques and their relation to older techniques (or alternately a transcript/recording/notes of Philippe’s lectures) on this blog.
18 July, 2013 at 8:42 am
Terence Tao
I’ll try to write something over the coming days. Philippe, Emmanuel, and Etienne are planning a monograph on this topic but that will probably take a bit longer :) [But Chapter 11 of Iwaniec-Kowalski already has a pretty good summary.]
18 July, 2013 at 2:15 pm
Philippe Michel
I think that being irreducible may not be too much an issue: given some trace function associated to some sheaf
some trace function associated to some sheaf  the VdC method requires that for all but a bounded number of
the VdC method requires that for all but a bounded number of 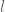 ,
, 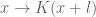 does not correlate with
does not correlate with  for any additive character
for any additive character  . If
. If  is irreducible this would work for all non-zero
is irreducible this would work for all non-zero  (provided
(provided  is large compared to the conductor that
is large compared to the conductor that  satisfy some mild additional condition like having a singularity on the affine line or large enough Swan conductor at
satisfy some mild additional condition like having a singularity on the affine line or large enough Swan conductor at  ,
,  -the later to avoid thing like quadratic phases-).
-the later to avoid thing like quadratic phases-).
If there are more than one irreducible component (each one satisfying the assumptions above) then it seem that the number of bad might increase but by a bounded amount only. That concerns of course the weight 0 part and if the sheaf mixed of weight
might increase but by a bounded amount only. That concerns of course the weight 0 part and if the sheaf mixed of weight  the contribution from the negative weight part can be bounded trivially. So maybe there is a relatively soft proof of this form of VdC for general
the contribution from the negative weight part can be bounded trivially. So maybe there is a relatively soft proof of this form of VdC for general  : of course one needs to know a bit about that specific sheaf and especially its weight 0 part but maybe not as much as one would know if it were a Fourier transforms.
: of course one needs to know a bit about that specific sheaf and especially its weight 0 part but maybe not as much as one would know if it were a Fourier transforms.
That is an interesting question !
18 July, 2013 at 2:43 pm
Terence Tao
I think it may be convenient to decompose into irreducible components before applying the vdC method (this may require some uniformity of the decomposition (e.g. uniform bounds on the conductor of the components) with respect to all the various primes p dividing the modulus q, but perhaps one can appeal to some scheme-theoretic nonsense to justify this), so one doesn’t have to see the interactions between different components, instead simply using the plain old triangle inequality to glue together the contributions of each component. For a single component, I think one can in fact get an “inverse theorem” to the effect that the expected vdC theorem works unless the component is coming from a quadratic phase
into irreducible components before applying the vdC method (this may require some uniformity of the decomposition (e.g. uniform bounds on the conductor of the components) with respect to all the various primes p dividing the modulus q, but perhaps one can appeal to some scheme-theoretic nonsense to justify this), so one doesn’t have to see the interactions between different components, instead simply using the plain old triangle inequality to glue together the contributions of each component. For a single component, I think one can in fact get an “inverse theorem” to the effect that the expected vdC theorem works unless the component is coming from a quadratic phase 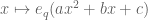 (if one was using iterated vdC, then also higher polynomial phases would appear). So basically one has to show that
(if one was using iterated vdC, then also higher polynomial phases would appear). So basically one has to show that  usually doesn’t correlate with a quadratic phase in the b variable, which looks like a relatively easy thing to verify (but it is, naively at least, still a two-dimensional exponential sum or worse, so one still needs some Deligne-level technology to dispose of it).
usually doesn’t correlate with a quadratic phase in the b variable, which looks like a relatively easy thing to verify (but it is, naively at least, still a two-dimensional exponential sum or worse, so one still needs some Deligne-level technology to dispose of it).
18 July, 2013 at 7:47 pm
Philippe Michel
A simple way to decide whether the sheaf contains geometrically a quadratic phase (or any phase) is to use Hooley’s criterion a rational function with
a rational function with
(On exponential sums and certain of their applications, Exeter) which state that for
numerator and denominator with rational coefficient the sum
if the curve
is geometrically generically irreducible (irreducible over an algebraic closure of ) and
) and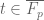 the
the 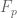 -variety
-variety
if for any
is a curve (possibly reducible). This is a nice and simple application of Parseval together with the invariance of the weights under Galois conjugation!
One can find in (Fouvry-Michel, Sur certaines sommes d’exponentielles sur les nombres premiers) examples where this criterion is applied (and a simple criterion Prop 2.1 to verify Hooley’s criterion). I have not checked it yet on our case.
Of course it will be very interesting to have a general result to apply VdC to general trace weights of composite moduli, but that depend both on the shape of the local trace weights mod and the way the global one factorizes under the CRT. Anyway that criterion should permit to make good progress on this specific case.
and the way the global one factorizes under the CRT. Anyway that criterion should permit to make good progress on this specific case.
20 July, 2013 at 2:43 pm
Terence Tao
I’m recording here the details of Hooley’s argument from http://www.ams.org/mathscinet-getitem?mr=697259 as it is indeed very neat. Deligne’s theorems give an expansion of the form
where is the trace from
is the trace from 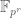 to
to 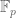 ,
,  and
and  are bounded integers, and
are bounded integers, and 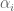 are distinct algebraic integers whose magnitude is a power of
are distinct algebraic integers whose magnitude is a power of 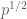 (and all Galois conjugates of
(and all Galois conjugates of 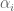 have the same magnitude). The problem here is that some of the
have the same magnitude). The problem here is that some of the 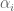 may be of too high weight – of magnitude
may be of too high weight – of magnitude  or
or 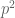 . But we can eliminate this using Galois theory and the Plancherel identity as follows. The left-hand side lives in the cyclotomic integers of order
. But we can eliminate this using Galois theory and the Plancherel identity as follows. The left-hand side lives in the cyclotomic integers of order  , so the weights
, so the weights 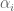 do as well. We then have
do as well. We then have
for all non-zero , where
, where  is the Galois automorphism of the cyclotomic integers that maps
is the Galois automorphism of the cyclotomic integers that maps 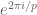 to
to  . If one of the
. If one of the 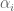 has magnitude
has magnitude  or more, we can then square-sum in
or more, we can then square-sum in  and conclude that
and conclude that
for infinitely many , which certainly implies
, which certainly implies
But by Plancherel, the left-hand side may be rewritten as
where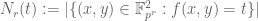 . From the hypotheses on
. From the hypotheses on  and the Weil conjectures for curves we have
and the Weil conjectures for curves we have 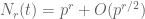 for all but boundedly many
for all but boundedly many  , and
, and 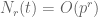 in general, so the previous expression is
in general, so the previous expression is  , leading to a contradiction for
, leading to a contradiction for  large enough.
large enough.
For our specific application, namely showing that the function does not correlate with any quadratic phase, it seems that it boils down to showing that the quartic curve
does not correlate with any quadratic phase, it seems that it boils down to showing that the quartic curve 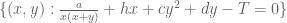 is geometrically generically irreducible for
is geometrically generically irreducible for 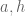 non-zero, which looks like something that can be verified by some ad hoc finite computation.
non-zero, which looks like something that can be verified by some ad hoc finite computation.
18 July, 2013 at 9:16 pm
Terence Tao
OK, so the question of making K not correlate with a quadratic phase doesn’t look too bad then, it will “just” require some classical algebraic geometry (one of Bertini’s theorems, perhaps). (For the actual application to bounded gaps, K will be a little more complicated than advertised above, because we are not summing a Kloosterman phase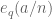 , but rather the more complicated phase in equation (34) of this blog post that arose after two applications of Cauchy-Schwarz to eliminate the
, but rather the more complicated phase in equation (34) of this blog post that arose after two applications of Cauchy-Schwarz to eliminate the 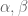 weights, but hopefully the arguments will extend.) So it seems the main thing is to check that K is still coming from some reasonably well-behaved (though not necessarily geometrically irreducible) sheaf in the b variable. (I now think the decomposition of the modulus into individual primes p will not be a problem, the CRT allows one to reduce the treatment of completed exponential sums (even higher-dimensional ones) on composite (squarefree) moduli to prime moduli without much difficulty.)
weights, but hopefully the arguments will extend.) So it seems the main thing is to check that K is still coming from some reasonably well-behaved (though not necessarily geometrically irreducible) sheaf in the b variable. (I now think the decomposition of the modulus into individual primes p will not be a problem, the CRT allows one to reduce the treatment of completed exponential sums (even higher-dimensional ones) on composite (squarefree) moduli to prime moduli without much difficulty.)
18 July, 2013 at 9:47 pm
Philippe Michel
“(I now think the decomposition of the modulus into individual primes p will not be a problem, the CRT allows one to reduce the treatment of completed exponential sums (even higher-dimensional ones) on composite (squarefree) moduli to prime moduli without much difficulty.)”
What I was meaning about the CRT factorization for general trace weights was just the following:
imagine the original trace function were, say , a Kloosterman sum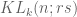 the CRT yields
the CRT yields
so after doing VdC one would get a transform of the shape
(or as you say something a bit more complicated) so one would need to look at the variation in of the correlation of
of the correlation of  with the pair of arguments
with the pair of arguments
so different values of would yield different pairs to study.
would yield different pairs to study.
Similarly, if the trace function were (Paul’s notation)
(which is the problem in present case with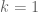 ), the pair would be
), the pair would be
I just mean I don’t see yet a general geometric pattern allowing to treat all possible cases all at once (unlike the case of the general Polya-Vinogradov method or the treatment of type II sums for general trace weights).
Maybe such a pattern will emerge after the present case has been sufficiently understood and digested…
20 July, 2013 at 7:01 pm
Philippe Michel
The generic geometric reducibility of the curve can be checked via the following criterion (Prop. 2.1 of Fouvry-Michel, Sur certaines sommes d’exponentielles sur les nombres premiers):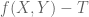 is reducible over
is reducible over  iff
iff  can be written
can be written 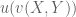 with
with  not a fractional linear transformation (not a ratio of polynomials of degree
not a fractional linear transformation (not a ratio of polynomials of degree  ) and
) and  ; in other terms the morphism
; in other terms the morphism  factors non-trivially through the projective line. Moreover, in the present case (since
factors non-trivially through the projective line. Moreover, in the present case (since  has non-constant denominator) if one allow the fractions to have coefficients in
has non-constant denominator) if one allow the fractions to have coefficients in 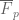 one may assume that
one may assume that  has positive degree (a pole at
has positive degree (a pole at 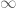 ).
).
20 July, 2013 at 8:47 pm
Terence Tao
Dear Phillippe: thanks for this! Your criterion with Fouvry seems very close to Bertini’s second theorem, see Theorem 5.3 of this survey of Kleiman. In this particular case of trying to show that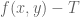 is generically irreducible with
is generically irreducible with 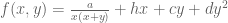 , I think we can combine this criterion (in a somewhat ad hoc fashion) with Eytan’s observation (using the cubic nature of the curve
, I think we can combine this criterion (in a somewhat ad hoc fashion) with Eytan’s observation (using the cubic nature of the curve 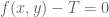 in y) that if this expression was generically reducible, the components would have to be linear of the form
in y) that if this expression was generically reducible, the components would have to be linear of the form  (note that the factors have to be Galois conjugate to each other over
(note that the factors have to be Galois conjugate to each other over  , indeed they are of the form
, indeed they are of the form  ), which I think means that the rational function
), which I think means that the rational function  in the putative factorisation
in the putative factorisation  has to be of the form
has to be of the form 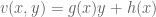 (otherwise the curves
(otherwise the curves 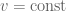 have too much multiplicity in the
have too much multiplicity in the  direction). On the other hand, as
direction). On the other hand, as  is non-zero, this rational function is singular at
is non-zero, this rational function is singular at  , which means that (after shifting
, which means that (after shifting  by a constant) we have
by a constant) we have  for some rational function
for some rational function  . Writing
. Writing 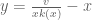 , we thus have
, we thus have
Looking at the behaviour as approaches zero, we see that
approaches zero, we see that  cannot be a function of
cannot be a function of  alone unless
alone unless  is constant, but then by considering the behaviour as
is constant, but then by considering the behaviour as  approaches zero we must have
approaches zero we must have  both vanishing, but then taking
both vanishing, but then taking 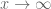 we see that
we see that  must vanish also, which we assumed not to be the case. So I think this proves that
must vanish also, which we assumed not to be the case. So I think this proves that 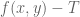 is generically geometrically irreducible. (Probably there is a less ad hoc way to do this though.)
is generically geometrically irreducible. (Probably there is a less ad hoc way to do this though.)
20 July, 2013 at 9:32 pm
Philippe Michel
Dear terry
thanks for the reference to Kleiman which I didn’t t know and is great to read. No geometer pointed it to me before.
Another reference which is relevant to this discussion is this inverse theorem for Gowers norms for l adic sheaves (http://arxiv.org/abs/1211.3282) which unfortunately does not include the decomposition question in its statements. Given this and earlier comment you made: wouldn’t it be interesting to restate VdC and iterations of it systematically in terms of Gowers norms ?
20 July, 2013 at 10:22 pm
Terence Tao
Dear Philippe,
One can use lots of Cauchy-Schwarz (or van der Corput) to control incomplete sums such as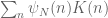 in terms of various Gowers norms of
in terms of various Gowers norms of  , but the process is rather inefficient in the exponents, though if one is only interested in qualitative cancellation (e.g. gaining powers of
, but the process is rather inefficient in the exponents, though if one is only interested in qualitative cancellation (e.g. gaining powers of 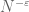 over the trivial bound where one doesn’t care about how small
over the trivial bound where one doesn’t care about how small  is) then one can do everything through Gowers norms. But since in this project we need exponents that are as good as possible, I don’t think it’s worth going through the Gowers norms here.
is) then one can do everything through Gowers norms. But since in this project we need exponents that are as good as possible, I don’t think it’s worth going through the Gowers norms here.
On the other hand, it seems likely that the Hooley argument allows one to deduce the inverse theorem for van der Corput (roughly speaking, that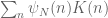 obeys a van der Corput estimate unless
obeys a van der Corput estimate unless  contains or correlates with a polynomial phase at many primes
contains or correlates with a polynomial phase at many primes  dividing the modulus
dividing the modulus  of
of  ) from the inverse theorem for the Gowers norms in your paper with Emmanuel and Etienne you linked to above… though this is sort of a roundabout way to do it, since I think the inverse van der Corput argument can be proven directly using an easier version of the methods in that paper (particularly since in our case we only use the first van der Corput estimate and not any higher iteration, though probably the inverse theorem for the iterated vdC follows by the same methods).
) from the inverse theorem for the Gowers norms in your paper with Emmanuel and Etienne you linked to above… though this is sort of a roundabout way to do it, since I think the inverse van der Corput argument can be proven directly using an easier version of the methods in that paper (particularly since in our case we only use the first van der Corput estimate and not any higher iteration, though probably the inverse theorem for the iterated vdC follows by the same methods).
10 July, 2013 at 5:28 pm
Fan
Prof. Tao,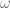 7/600 or 6/700? It’s one way here and the other way on the Polymath wiki.
7/600 or 6/700? It’s one way here and the other way on the Polymath wiki.
Is the new
[Corrected, thanks – T.]
13 July, 2013 at 4:03 pm
Gergely Harcos
Two suggestions and some typos:
1. In the proof of Corollary 11, you refer to Proposition 5 of the previous post (https://terrytao.wordpress.com/2013/06/22/bounding-short-exponential-sums-on-smooth-moduli-via-weyl-differencing/). For the sake of the reader it would be cleaner/simpler to refer to just one important step in the proof of this proposition, namely to
where![q:=[d_1,d_2]](https://s0.wp.com/latex.php?latex=q%3A%3D%5Bd_1%2Cd_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) and
and  . This implies that the last term in Proposition 10 (for this choice of parameters) is
. This implies that the last term in Proposition 10 (for this choice of parameters) is
2. In the proof of Lemma 12, the term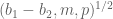 should be
should be  . Moreover, in three consecutive displays of this proof,
. Moreover, in three consecutive displays of this proof,  should be
should be 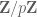 .
.
3. Two lines below (7),![Type_I[\varpi,\delta,\sigma]](https://s0.wp.com/latex.php?latex=Type_I%5B%5Cvarpi%2C%5Cdelta%2C%5Csigma%5D&bg=ffffff&fg=545454&s=0&c=20201002) should be
should be ![Type''_I[\varpi,\delta,\sigma]](https://s0.wp.com/latex.php?latex=Type%27%27_I%5B%5Cvarpi%2C%5Cdelta%2C%5Csigma%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
4.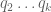 should be
should be  (four occurrences).
(four occurrences).
5. In Corollary 11,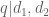 should be
should be 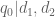 ; perhaps
; perhaps  would be even better. In addition,
would be even better. In addition, 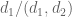 should be
should be  .
.
6. In the proof of Corollary 11, “replaced by ” should be “replaced by
” should be “replaced by  “, and
“, and ![[d'_1,d'_2]](https://s0.wp.com/latex.php?latex=%5Bd%27_1%2Cd%27_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) should be
should be ![[\tilde d_1, \tilde d_2]](https://s0.wp.com/latex.php?latex=%5B%5Ctilde+d_1%2C+%5Ctilde+d_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
7. In Lemma 12,![[r_1 r_2]](https://s0.wp.com/latex.php?latex=%5Br_1+r_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) should be
should be ![[r_1, r_2]](https://s0.wp.com/latex.php?latex=%5Br_1%2C+r_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
8. Three displays above Lemma 13,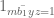 should be
should be 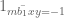 .
.
[Corrected, thanks – T.]
13 July, 2013 at 8:03 pm
Gergely Harcos
9. I think in Proposition 10 all prime factors of should be sufficiently large to make the implication
should be sufficiently large to make the implication
valid. We can remove this restriction on by decomposing
by decomposing
where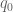 is the product of the small prime factors of
is the product of the small prime factors of  . A similar comment applies to Corollary 11.
. A similar comment applies to Corollary 11.
10. Three displays above Lemma 13,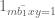 should be
should be 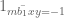 .
.
[Corrected, thanks – T.]
13 July, 2013 at 7:10 pm
Terence Tao
I am recording here a variant of the combinatorial lemma that relaxes the constraint to
to 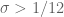 , at the cost of introducing two additional cases, the “Type IV” and “Type V” cases. We have good estimates for the Type IV case, but unfortunately not for the Type V case, so this lemma does not actually give any improvement on
, at the cost of introducing two additional cases, the “Type IV” and “Type V” cases. We have good estimates for the Type IV case, but unfortunately not for the Type V case, so this lemma does not actually give any improvement on  for our application. (However if one is interested in a distribution theorem for
for our application. (However if one is interested in a distribution theorem for  rather than for
rather than for  , then the Type V case is excluded and we can do a little bit better than what we currently have (specifically, if we ignore
, then the Type V case is excluded and we can do a little bit better than what we currently have (specifically, if we ignore  , we improve
, we improve  from
from 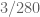 to
to 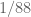 ).
).
Here is the precise lemma:
Combinatorial lemma Let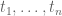 be non-negative quantities adding up to
be non-negative quantities adding up to  , and let
, and let  . Then at least one of the following occurs:
. Then at least one of the following occurs:
* (Type 0 case) We have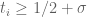 for some
for some  .
.
* (Type I/II case) There exists a partition such that
such that  .
.
* (Type III case) There exist distinct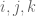 such that
such that  and
and  . (This case only occurs when
. (This case only occurs when 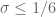 .)
.)
* (Type IV case) There exist distinct such that
such that 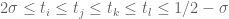 and
and  . In particular we have
. In particular we have 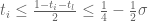 , and hence
, and hence  . (This case only occurs when
. (This case only occurs when  .)
.)
* (Type V case) There exist distinct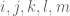 such that
such that 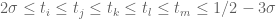 and
and  . (This case only occurs when
. (This case only occurs when 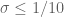 .)
.)
Proof If we have![\sum_{i \in A} t_i \in [1/2-\sigma,1/2+\sigma]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi+%5Cin+A%7D+t_i+%5Cin+%5B1%2F2-%5Csigma%2C1%2F2%2B%5Csigma%5D&bg=ffffff&fg=545454&s=0&c=20201002) for some
for some  then we are in the Type I/II case (possibly after replacing
then we are in the Type I/II case (possibly after replacing  with its complement), so we may assume that this does not occur. Thus every
with its complement), so we may assume that this does not occur. Thus every 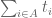 is “small” (less than
is “small” (less than  ) or “large” (greater than
) or “large” (greater than  ).
).
As before, call an element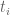 “powerful” if the addition of
“powerful” if the addition of 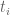 can convert a small sum into a large sum, and “powerless” otherwise. All the powerful elements must be at least
can convert a small sum into a large sum, and “powerless” otherwise. All the powerful elements must be at least  , and have large sum. If any of the powerful elements are large then we are in Type 0, so we may assume that they are all small, which implies that they remain small even if we add in all the powerless elements; in particular, there are at least three powerful elements (since two small quantities cannot sum to 1). On the other hand, since
, and have large sum. If any of the powerful elements are large then we are in Type 0, so we may assume that they are all small, which implies that they remain small even if we add in all the powerless elements; in particular, there are at least three powerful elements (since two small quantities cannot sum to 1). On the other hand, since 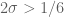 , we see that there are at most five powerful elements.
, we see that there are at most five powerful elements.
We now divide into cases. If there are exactly three powerful elements , then without loss of generality
, then without loss of generality  . Since
. Since 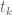 plus all the powerless elements is small, we conclude that
plus all the powerless elements is small, we conclude that  is large, and we are in the Type III case.
is large, and we are in the Type III case.
If there are exactly four powerful elements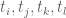 , then without loss of generality
, then without loss of generality 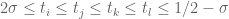 . If
. If  is large then we are in the Type IV case, so suppose instead that
is large then we are in the Type IV case, so suppose instead that  is small. Then
is small. Then  plus all the powerless elements is still small, so
plus all the powerless elements is still small, so  is large. But then
is large. But then  place us in the Type III case, and we are again done.
place us in the Type III case, and we are again done.
Finally suppose that there are exactly five powerful elements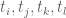 . Without loss of generality we have
. Without loss of generality we have  . Note that
. Note that 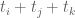 is at least
is at least  , which is greater than
, which is greater than 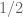 ; thus
; thus 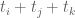 is large. Thus forces
is large. Thus forces 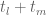 to be small; since
to be small; since 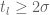 , we conclude that
, we conclude that  as required.
as required. 
We can illustrate this lemma with the estimate when there is no Type V estimate. Ignoring
estimate when there is no Type V estimate. Ignoring  , we can control the Type 0 sums whenever
, we can control the Type 0 sums whenever
the Type I sums whenever
the Type II sums whenever
and the Type III sums whenever
(The Type I condition might be improvable in view of this previous comment https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238186 , but let’s ignore that for
now.)
To handle the Type IV sums, we see that as , we can view these sums as a Type I sum with
, we can view these sums as a Type I sum with  replaced by
replaced by  , and with the “
, and with the “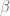 ” factor smooth. In this comment https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238054 it is shown (or at least sketched) that such sums can be controlled if
” factor smooth. In this comment https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238054 it is shown (or at least sketched) that such sums can be controlled if
One can check that these conditions (as well as the combinatorial constraint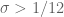 ) are satisfiable in the neighbourhood of
) are satisfiable in the neighbourhood of 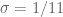 ,
,  ). It’s a pity that we don’t yet have any good way to control Type V sums (other than to treat them to a Type I sum), otherwise we could hope to obtain this sort of improvement for the actual problem, rather than for the
). It’s a pity that we don’t yet have any good way to control Type V sums (other than to treat them to a Type I sum), otherwise we could hope to obtain this sort of improvement for the actual problem, rather than for the  distribution problem.
distribution problem.
13 July, 2013 at 7:30 pm
Brian Rothbach
Shouldn’t you be able to improve 1/12 to 1/14 in the lemma? The sum of three powerful elements just needs to be greater than to be large, not
to be large, not  [probably you mean
[probably you mean 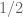 here – T.]; once you have that, you can’t have 6 powerful elements with a sum less than 1 (since both the first three and the last three would sum to at least
here – T.]; once you have that, you can’t have 6 powerful elements with a sum less than 1 (since both the first three and the last three would sum to at least  ).
).
The next obstacle to the combinatorial lemma appears to be a collections of seven 1/7th’s (and other clusterings of 1/7th), and in general collections of 2n+1 1/(2n+1)’s start new cases..
13 July, 2013 at 7:40 pm
Terence Tao
Nice observation! I think you’re right. (At present this doesn’t improve any exponents because the Type I/Type III barrier is currently at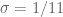 , but in principle this improvement could become relevant in the future.)
, but in principle this improvement could become relevant in the future.)
15 July, 2013 at 8:59 am
Pace Nielsen
Here is something I tried to figure out but couldn’t make it work. Does the Type V decomposition actually occur in the cases we care about? That is, when utilizing the Heath-Brown decomposition, can we have exactly 5 smooth terms, each roughly of scale ?
?
15 July, 2013 at 9:04 am
Terence Tao
I’m recording here an observation which is a bit tricky to formalise properly, but roughly asserts that one cannot hope to do much better than the Heath-Brown identity when decomposing into various Type I, Type II, Type III, etc. convolutions of various coefficient sequences, some smooth and some not, at different scales.
into various Type I, Type II, Type III, etc. convolutions of various coefficient sequences, some smooth and some not, at different scales.
Let me try to explain what I mean by this. Currently, with the Heath-Brown identity, one has decomposed into a finite (or more precisely, a polylogarithmic) number of convolutions
into a finite (or more precisely, a polylogarithmic) number of convolutions 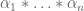 , where each
, where each 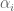 is a coefficient sequence at scale
is a coefficient sequence at scale 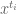 for some non-negative real numbers
for some non-negative real numbers 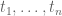 summing to 1. Furthermore, the
summing to 1. Furthermore, the 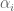 are smooth whenever the
are smooth whenever the 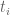 are not absolutely tiny. We then need to find enough Type I, Type II, Type III, etc. estimates to cover all possible values of the tuple
are not absolutely tiny. We then need to find enough Type I, Type II, Type III, etc. estimates to cover all possible values of the tuple 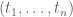 . Each “Type X” estimate covers convolutions of a certain form
. Each “Type X” estimate covers convolutions of a certain form 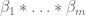 , where each
, where each  is supported at some scale
is supported at some scale 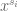 , with some constraints on the
, with some constraints on the 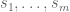 (typically a collection of linear inequalities), and also some requirements that some of the
(typically a collection of linear inequalities), and also some requirements that some of the  are smooth. (There is also a Siegel-Walfisz condition, but this is easily verified in practice and will be ignored here.) Such an estimate can “cover” a certain convolution
are smooth. (There is also a Siegel-Walfisz condition, but this is easily verified in practice and will be ignored here.) Such an estimate can “cover” a certain convolution 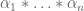 if there is some way to regroup this convolution (e.g. by concatenating
if there is some way to regroup this convolution (e.g. by concatenating 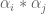 into a single sequence
into a single sequence 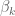 at scale
at scale  ) to place it in a form treatable by the estimate (keeping in mind that convolution destroys smoothness).
) to place it in a form treatable by the estimate (keeping in mind that convolution destroys smoothness).
One could hope that one could repeat this strategy with the Heath-Brown identity replaced by another identity (e.g. Vaughan’s identity) that similarly splits into finitely many pieces, each of which is covered by some “Type X” estimate, but which is superior to Heath-Brown in the sense that not every tuple
into finitely many pieces, each of which is covered by some “Type X” estimate, but which is superior to Heath-Brown in the sense that not every tuple 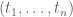 summing to 1 needs to be covered. For instance, our current nemesis is the tuple
summing to 1 needs to be covered. For instance, our current nemesis is the tuple  – wouldn’t it be great if there was an identity that avoided the need to control this tuple? Note that one has to interpret the phrase “avoided the need to control this tuple” carefully. For instance, in the Vaughan identity
– wouldn’t it be great if there was an identity that avoided the need to control this tuple? Note that one has to interpret the phrase “avoided the need to control this tuple” carefully. For instance, in the Vaughan identity
with (say), there is no term that involves the convolution of five factors, and so the tuple
(say), there is no term that involves the convolution of five factors, and so the tuple  does not explicitly appear in this decomposition. However, it appears implicitly, for instance through the component of
does not explicitly appear in this decomposition. However, it appears implicitly, for instance through the component of 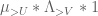 in which the first two terms are at scale
in which the first two terms are at scale  and the last term is at scale
and the last term is at scale  . This is a convolution of two rough sequences at scale
. This is a convolution of two rough sequences at scale  and one smooth sequence at scale
and one smooth sequence at scale  , which is a pattern which can also be attained by a convolution
, which is a pattern which can also be attained by a convolution  of five smooth sequences associated the tuple
of five smooth sequences associated the tuple  by grouping together two pairs of the
by grouping together two pairs of the  together. Hence, if the former convolution can be treated by some “Type X” estimate, then the latter convolution can also be treated by the same estimate, and so we have not actually avoided the need to control the tuple
together. Hence, if the former convolution can be treated by some “Type X” estimate, then the latter convolution can also be treated by the same estimate, and so we have not actually avoided the need to control the tuple  here. In order to do that, the decomposition would have to avoid not only any term which resembled the original convolution
here. In order to do that, the decomposition would have to avoid not only any term which resembled the original convolution  , but also any term that resembles some regrouping of this convolution, e.g.
, but also any term that resembles some regrouping of this convolution, e.g. 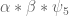 where
where 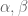 are rough sequences at scale
are rough sequences at scale  . It is an instructive exercise to verify that no matter how one chooses the parameters
. It is an instructive exercise to verify that no matter how one chooses the parameters  for the Vaughan identity, one cannot avoid some recombination of
for the Vaughan identity, one cannot avoid some recombination of  using this identity.
using this identity.
More generally, I now believe that given any tuple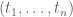 of strictly positive real numbers summing to one, any Heath-Brown or Vaughan-type decomposition of
of strictly positive real numbers summing to one, any Heath-Brown or Vaughan-type decomposition of  must involve at least one component that resembles some recombination of the convolution
must involve at least one component that resembles some recombination of the convolution 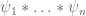 of smooth functions at scales
of smooth functions at scales  respectively, which basically means that one is forced to find enough Type X estimates to cover all such tuples
respectively, which basically means that one is forced to find enough Type X estimates to cover all such tuples 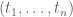 . I’ll illustrate this with the tuple
. I’ll illustrate this with the tuple  for sake of concreteness, although the construction generalises of course to other tuples (after setting up a certain amount of notation).
for sake of concreteness, although the construction generalises of course to other tuples (after setting up a certain amount of notation).
Basically, the idea is to exploit duality, introducing a weight function (which one can think of as a sort of restricted, renormalised Mobius function) that correlates with
(which one can think of as a sort of restricted, renormalised Mobius function) that correlates with  , but does not correlate with any of the convolutions of the type that come out of a Heath-Brown or Vaughan type identity EXCEPT for those which resemble the tuple
, but does not correlate with any of the convolutions of the type that come out of a Heath-Brown or Vaughan type identity EXCEPT for those which resemble the tuple  or a recombination thereof. Specifically, consider the function
or a recombination thereof. Specifically, consider the function 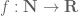 defined by setting
defined by setting
when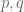 are primes in
are primes in ![[x^{0.4}, (1+\log^{-A_0} x) x^{0.4}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.4%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.4%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) and
and ![[x^{0.6}, (1+\log^{-A_0} x) x^{0.6}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.6%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.6%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) respectively, and
respectively, and
when is a prime in
is a prime in ![[x, (1+\log^{-A_0} x) x]](https://s0.wp.com/latex.php?latex=%5Bx%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5D&bg=ffffff&fg=545454&s=0&c=20201002) , and zero otherwise, where
, and zero otherwise, where 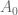 is a large fixed constant. The normalisations here have been set up so that f essentially has mean zero, indeed from the prime number theorem we see that
is a large fixed constant. The normalisations here have been set up so that f essentially has mean zero, indeed from the prime number theorem we see that
for any smooth coefficient sequence at scale
at scale  . So
. So  basically does not correlate with any smooth coefficient sequence. Also, because
basically does not correlate with any smooth coefficient sequence. Also, because  is supported on numbers with at most two prime factors,
is supported on numbers with at most two prime factors,  does not correlate with any convolution of three or more non-trivial sequences (where “non-trivial” means “not supported at 1), and can only correlate with a convolution of two sequences at scale
does not correlate with any convolution of three or more non-trivial sequences (where “non-trivial” means “not supported at 1), and can only correlate with a convolution of two sequences at scale 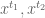 respectively if
respectively if 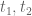 are basically equal to
are basically equal to 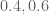 up to permutations. On the other hand,
up to permutations. On the other hand,  has a strong correlation with
has a strong correlation with  :
:
Thus, regardless of how one splits up into convolutions of various coefficient sequences at various scales, at least one of the convolutions thus obtained must either be a rough sequence at scale
into convolutions of various coefficient sequences at various scales, at least one of the convolutions thus obtained must either be a rough sequence at scale  , or else the convolution of two sequences at scale
, or else the convolution of two sequences at scale 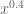 and
and  . Controlling either of these two types of sequences by some Type X estimate would also imply the ability to control a convolution
. Controlling either of these two types of sequences by some Type X estimate would also imply the ability to control a convolution  of two smooth sequences at scales
of two smooth sequences at scales 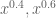 respectively, and so we must somehow be able to cover the tuple
respectively, and so we must somehow be able to cover the tuple  by some Type X estimate.
by some Type X estimate.
There are similar arguments for longer tuples but it gets messy. For instance, for the tuple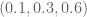 , one would want to choose a function
, one would want to choose a function  with
with
if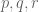 are primes in
are primes in ![[x^{0.1}, (1+\log^{-A_0} x) x^{0.1}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.1%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.1%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![[x^{0.3}, (1+\log^{-A_0} x) x^{0.3}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.3%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.3%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![[x^{0.6}, (1+\log^{-A_0} x) x^{0.6}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.6%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.6%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) respectively,
respectively,
if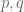 are primes in
are primes in ![[x^{0.1+0.3}, (1+\log^{-A_0} x) x^{0.1+0.3}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.1%2B0.3%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.1%2B0.3%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![[x^{0.6}, (1+\log^{-A_0} x) x^{0.6}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B0.6%7D%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5E%7B0.6%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) respectively, and similarly for two other ways to concatenate the tuple
respectively, and similarly for two other ways to concatenate the tuple 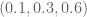 , and finally
, and finally
when is a prime in
is a prime in ![[x, (1+\log^{-A_0} x) x]](https://s0.wp.com/latex.php?latex=%5Bx%2C+%281%2B%5Clog%5E%7B-A_0%7D+x%29+x%5D&bg=ffffff&fg=545454&s=0&c=20201002) . Then one can show that the only sequences coming out of a Heath-Brown type decomposition that can correlate strongly with
. Then one can show that the only sequences coming out of a Heath-Brown type decomposition that can correlate strongly with  are either smooth at scale
are either smooth at scale  , or convolutions
, or convolutions  where
where  is rough at scale
is rough at scale  and
and 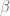 is at scale
is at scale  (or permutations thereof), or convolutions
(or permutations thereof), or convolutions 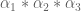 where
where  are at scales
are at scales  (or permutations thereof). If a Type X estimate can handle any of these expressions, it can also handle the convolution
(or permutations thereof). If a Type X estimate can handle any of these expressions, it can also handle the convolution  of smooth sequences at scales
of smooth sequences at scales  respectively, proving that one has to be able to cover the tuple
respectively, proving that one has to be able to cover the tuple 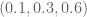 in any argument of this type.
in any argument of this type.
15 July, 2013 at 9:39 pm
Mike Ruxton
In the polymath wiki, the distribution result is listed as
280/3 omega bar + 70/3 delta
while your theorem 1 has 80/3 delta.
[Oops, that was a typo on the wiki; corrected now, thanks – T.]
16 July, 2013 at 8:08 pm
Terence Tao
I’m recording some elementary facts about “multiple dense divisibility”, which I think will be needed in order to flesh out the most recent refinement to the Type I estimates from https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238574 (in particular, a back-of-the-envelope calculation suggests that quadruple dense divisibility is needed here).
First, the definition. Fix . We define the notion of a
. We define the notion of a  -tuply
-tuply  -densely divisible natural number
-densely divisible natural number  recursively as follows: every natural number is
recursively as follows: every natural number is 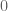 -tuply
-tuply  -densely divisible, and if
-densely divisible, and if 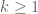 , we call
, we call 
 -tuply
-tuply  -densely divisible if, for every
-densely divisible if, for every  with
with 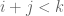 and every
and every  , one can find a factorisation
, one can find a factorisation 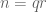 with
with ![q \in [y^{-1} R, R]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5By%5E%7B-1%7D+R%2C+R%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, 
 -tuply
-tuply  -densely divisible, and
-densely divisible, and 
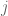 -tuply
-tuply  -densely divisible.
-densely divisible.
Some easy facts:
* -tuply
-tuply  -dense divisibility implies
-dense divisibility implies  -tuply
-tuply  -dense divisibility.
-dense divisibility.
* -smooth numbers are
-smooth numbers are  -tuply
-tuply  -dense divisible for every
-dense divisible for every  (and conversely).
(and conversely).
* More generally, if is square-free and
is square-free and  -smooth for some
-smooth for some 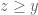 and
and 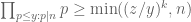 , then
, then  is
is  -tuply
-tuply  -densely divisible.
-densely divisible.
* If is
is  -tuply
-tuply  -densely divisible and
-densely divisible and  is a factor of
is a factor of  , then
, then  is
is  -tuply
-tuply  -densely divisible.
-densely divisible.
I also conjecture that the least common multiple of two -tuply
-tuply  -densely divisible natural numbers is again
-densely divisible natural numbers is again  -tuply
-tuply  -densely divisible (this will be convenient in some arguments). I can prove this for
-densely divisible (this will be convenient in some arguments). I can prove this for 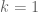 currently. (If this turns out to fail, then we may end up redefining
currently. (If this turns out to fail, then we may end up redefining  -tuple
-tuple  -dense divisibility using the criterion
-dense divisibility using the criterion 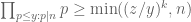 instead, since this is certainly preserved by least common multiple.
instead, since this is certainly preserved by least common multiple.
The sieve machinery that lets us reduce to single or double dense divisibility also lets us reduce to -tuply
-tuply  -dense divisibility as well, the only difference being that the quantity
-dense divisibility as well, the only difference being that the quantity  now needs to be set equal to
now needs to be set equal to 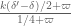 .
.
16 July, 2013 at 10:29 pm
Gergely Harcos
A suggestion and some typos:
1. A few lines below (34) you use your earlier observation that if are both
are both  -densely divisible, then
-densely divisible, then ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=545454&s=0&c=20201002) is also
is also  -densely divisible (https://terrytao.wordpress.com/2013/06/23/the-distribution-of-primes-in-densely-divisible-moduli/#comment-236387). For the sake of the reader I would reproduce the proof here.
-densely divisible (https://terrytao.wordpress.com/2013/06/23/the-distribution-of-primes-in-densely-divisible-moduli/#comment-236387). For the sake of the reader I would reproduce the proof here.
2. In (22), should be
should be  .
.
3. In the display below (24), the condition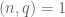 can be deleted.
can be deleted.
4. In (25) and the preceding display, should be
should be  .
.
5. In the display below (26),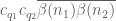 should be
should be 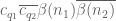 .
.
6. In (32), should be
should be  .
.
7. In the second line below (32), should be
should be  .
.
8. In the fifth display below (32),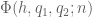 should be
should be 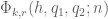 .
.
9. In the seventh display below (33), the condition “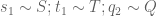 ” should be “
” should be “ “.
“.
10. In the display before (34), should be
should be  .
.
11. In (34), the condition “ ” should be “
” should be “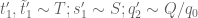 “.
“.
12. In the three lines following (34),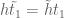 (resp.
(resp.  ) should be
) should be 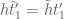 (resp.
(resp. 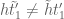 ), and
), and 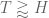 should be
should be 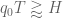 .
.
13. In the second and fourth display below (34), should be
should be  .
.
14. In the fifth display below (34), the condition “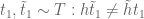 ” should be “
” should be “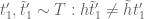 “, the condition “
“, the condition “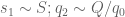 ” should be “
” should be “ “, and
“, and  should be
should be  .
.
15. In the ninth and tenth line below (34), “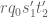 and
and  ” should be “
” should be “ and
and  “, and
“, and ![[rq_0 s'_1 t'_1 \tilde t'_1,q'_0 q'_2]](https://s0.wp.com/latex.php?latex=%5Brq_0+s%27_1+t%27_1+%5Ctilde+t%27_1%2Cq%27_0+q%27_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) should be
should be ![[rq_0 s'_1 t'_1 \tilde t'_1,q_0 q'_2]](https://s0.wp.com/latex.php?latex=%5Brq_0+s%27_1+t%27_1+%5Ctilde+t%27_1%2Cq_0+q%27_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
[Corrected, thanks – T.]
18 July, 2013 at 2:48 am
Gergely Harcos
Dear Terry, a further suggestion and some typos:
16. As we need the condition in (32) for later purposes, we should impose
in (32) for later purposes, we should impose  as a condition on
as a condition on  from the display before (20) up to (22), then as a condition on
from the display before (20) up to (22), then as a condition on  from (23) to (25). Finally, from (26) to (30) we should add the condition
from (23) to (25). Finally, from (26) to (30) we should add the condition  as well.
as well.
17. In the seventh display below (33),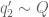 should be
should be 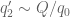 .
.
18. In the second line following (34),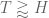 should be
should be 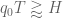 .
.
19. Correction #14 has not been implemented.
20. In the ninth line below (34),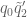 should be
should be  .
.
[Corrected, thanks – T.]
18 July, 2013 at 2:43 pm
Gergely Harcos
Two related suggestions and a typo:
1. I wonder if the case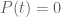 was meant to be included in Proposition 10. Perhaps not, because the degree is usually not defined for the zero polynomial. At any rate, it would be useful to clarify, because while the statement is valid in this case, the proof is not. Specifically, the display following (14) fails when
was meant to be included in Proposition 10. Perhaps not, because the degree is usually not defined for the zero polynomial. At any rate, it would be useful to clarify, because while the statement is valid in this case, the proof is not. Specifically, the display following (14) fails when 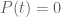 . In fact, already at the beginning, we cannot achieve
. In fact, already at the beginning, we cannot achieve  when
when 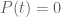 .
.
2. Shortly before (14) we infer that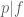 if
if  is sufficiently large. The way I see it, we don’t need to assume here that
is sufficiently large. The way I see it, we don’t need to assume here that  is sufficiently large, because
is sufficiently large, because  is monic. In fact the largeness assumption might cause subtle uniformity issues, because the implied constant in Proposition 10 must not depend on the actual coefficients of
is monic. In fact the largeness assumption might cause subtle uniformity issues, because the implied constant in Proposition 10 must not depend on the actual coefficients of  and
and  . On the other hand,
. On the other hand,  contradicts the initial assumption that
contradicts the initial assumption that  , so everything is fine. In fact this way we obtain the stronger conclusion
, so everything is fine. In fact this way we obtain the stronger conclusion
and I think we need this stronger conclusion.
3. In the fifth display below (34), should be
should be  .
.
18 July, 2013 at 3:01 pm
Terence Tao
1. Actually I think the f=0 case is fine. With the conventions given, (f,q) is equal to q when f vanishes, and the initial reductions in the case land one in the trivial setting q=1.
2. Unfortunately I don’t think we can remove the sufficiently large hypothesis. For instance if then
then 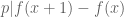 but
but  even though
even though  ostensibly vanishes at infinity. On the other hand, the implied constant in “sufficiently large” depends only on the degree of f and not on the coefficients (it’s the number of poles and zeroes of f that are the problem), so I don’t think the uniformity is an issue. I’ve adjusted the text slightly to emphasise this.
ostensibly vanishes at infinity. On the other hand, the implied constant in “sufficiently large” depends only on the degree of f and not on the coefficients (it’s the number of poles and zeroes of f that are the problem), so I don’t think the uniformity is an issue. I’ve adjusted the text slightly to emphasise this.
3. Corrected, thanks!
18 July, 2013 at 4:22 pm
Gergely Harcos
Thank you! You are absolutely right, I overlooked silly things like: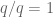 or that a polynomial that is nonzero mod
or that a polynomial that is nonzero mod  can still vanish mod
can still vanish mod  at every integer.
at every integer.
18 July, 2013 at 4:57 pm
Gergely Harcos
Actually the initial reduction that has no prime factor less than
has no prime factor less than  can be used to infer that
can be used to infer that 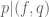 , contradicting
, contradicting  , whence
, whence
This is a very minor point, but it makes the argument more structured and easier to follow.
[Fair enough – I’ve adjusted the text accordingly. -T.]
19 July, 2013 at 9:18 am
Gergely Harcos
Some small suggestions:
1. In (32) I would change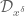 to
to 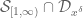 to avoid some necessary restrictions later. For example, without this change we would need further coprimality assumptions in (34) to guarantee the square-freeness of the moduli
to avoid some necessary restrictions later. For example, without this change we would need further coprimality assumptions in (34) to guarantee the square-freeness of the moduli 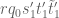 and
and  later (see also item 4 below).
later (see also item 4 below).
2. If the previous suggestion is implemented, in (32)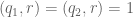 can be deleted. Moreover, in (33)
can be deleted. Moreover, in (33)  and seven displays later
and seven displays later  can be deleted.
can be deleted.
3. In (34) I would add the condition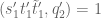 as it seems necessary to ensure the relation
as it seems necessary to ensure the relation 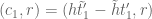 later.
later.
4. In the display below (34), I would change to
to ![[t'_1,\tilde t'_1]](https://s0.wp.com/latex.php?latex=%5Bt%27_1%2C%5Ctilde+t%27_1%5D&bg=ffffff&fg=545454&s=0&c=20201002) to ensure the square-freeness of the moduli necessary for Corollary 11 (see also item 1 above).
to ensure the square-freeness of the moduli necessary for Corollary 11 (see also item 1 above).
5. In the endgame of the proof of Proposition 10,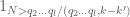 should be
should be 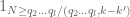 : three occurrences.
: three occurrences.
[Corrected, thanks – T.]
19 July, 2013 at 11:50 am
Gergely Harcos
Further small suggestions and typos:
6. If item 1 is implemented, in the first, fourth, and fifth display of Section 3, can be deleted. Moreover, in the sixth and eight display of Section 3,
can be deleted. Moreover, in the sixth and eight display of Section 3,  can be deleted.
can be deleted.
7. In the fourth display below (35),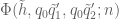 should be conjugated.
should be conjugated.
8. The fifth display below (35) should read
9. In Line 25 of Section 3,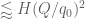 should be
should be 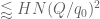 . In the next line,
. In the next line, 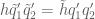 should be negated. In the next line,
should be negated. In the next line, 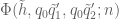 should be conjugated, and “taks” should be “takes”.
should be conjugated, and “taks” should be “takes”.
10. In the seventh display below (33) we may write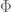 for
for  .
.
[Corrected, thanks -T]
19 July, 2013 at 12:18 pm
Eytan Paldi
In the page “Dickson-Hardy-Littlewood theorems”, all the criteria for conversion to DHL demand (implicitly) the (necessary) condition
 which is not satisfied for
which is not satisfied for 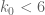 .
.
Perhaps a remark about it should be added to this page.
[I added a remark to this effect. -T]
19 July, 2013 at 3:08 pm
George Lantern
Hello Terence,
What do you think of this conjecture I found when I was reading at viXra.org http://vixra.org/abs/1307.0081
Greetings from US.
19 July, 2013 at 6:06 pm
Mangas & Maths²
very interesting george thanks for sharing ;-)
19 July, 2013 at 4:22 pm
Gergely Harcos
Dear Terry, thanks for the new post on l-adic sheaves! Thanks for implementing my numerous small comments as well. Here is a new list:
1. The notation is a bit ambiguous for me, starting with Lemma 14. The original definition is
is a bit ambiguous for me, starting with Lemma 14. The original definition is  , but this is not emphasized in Lemma 14, and in fact the symbol
, but this is not emphasized in Lemma 14, and in fact the symbol  plays two roles there. Likewise, in the third display below Lemma 14, the relation of
plays two roles there. Likewise, in the third display below Lemma 14, the relation of  to
to  is not explained. More importantly, (41) and the text below it suggest that
is not explained. More importantly, (41) and the text below it suggest that 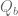 is meant to be
is meant to be  instead of what its definition below (40) says. I think the definition of
instead of what its definition below (40) says. I think the definition of  should be updated in a similar fashion, i.e. it should be
should be updated in a similar fashion, i.e. it should be 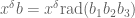 . Finally, the notation
. Finally, the notation 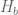 is also a bit confusing, because it does not really depend on
is also a bit confusing, because it does not really depend on  but on
but on  .
.
2. In the first display of Section 4,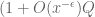 should be
should be 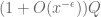 . In the next display, the lower bound should be
. In the next display, the lower bound should be 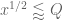 . In the next display,
. In the next display,  should be
should be  .
.
3. Seven lines below (37), I would add “by Poisson summation and integration by parts” for the sake of the reader.
4. In the sixth display below (37), should be
should be  .
.
5. In the display before (38), should be
should be  .
.
6. The display before Lemma 14 is missing the normalisation factor . In fact this quantity was already defined in (15).
. In fact this quantity was already defined in (15).
7. In the display after Lemma 14, the denominator should be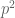 .
.
[Corrected, thanks – T.]
19 July, 2013 at 5:13 pm
Gergely Harcos
1. OK, so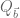 is not
is not  as I thought. But then I don’t understand why
as I thought. But then I don’t understand why 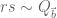 , as stated four lines below (41). I thought that
, as stated four lines below (41). I thought that 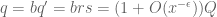 , whence
, whence 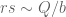 . Also, I don’t understand why we may assume that
. Also, I don’t understand why we may assume that 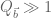 with the current definition of
with the current definition of 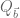 , as stated by (41). Sorry if I am missing the obvious.
, as stated by (41). Sorry if I am missing the obvious.
2. I think the fifth display below (35) is still not right. It should be
3. In the fifth display above (38),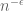 should be
should be  .
.
[Sorry about that – I was in the process of fixing a problem with my previous correction, it should be all right now – T.]
19 July, 2013 at 9:25 pm
Terence Tao
I’m recording some calculations to obtain more precise numerology on what the proposed improvement https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238186 in the exponential sum estimates would give for , assuming quadruple dense divisibility (which means that
, assuming quadruple dense divisibility (which means that  is now taken to be
is now taken to be 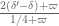 ). I’m going to skip some of the details which I believe will not affect the numerology.
). I’m going to skip some of the details which I believe will not affect the numerology.
We will assume the following Deligne-level estimate: if is a large prime and
is a large prime and  is the Kloosterman-type sum
is the Kloosterman-type sum
then one has
for any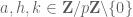 . This is roughly comparable in strength to the Bombieri-Birch estimate, but I was not able to reduce this estimate to known estimates.
. This is roughly comparable in strength to the Bombieri-Birch estimate, but I was not able to reduce this estimate to known estimates.
Anyway, to the numerology. We repeat the argument in the blog post up to equation (34), but retain the averaging in ; for simplicity we work in the case
; for simplicity we work in the case 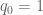 , which should be dominant. Our task is then basically to show that
, which should be dominant. Our task is then basically to show that
If we assume the original moduli to be quadruply -densely divisible, one can assume that
-densely divisible, one can assume that  is doubly densely divisible and the
is doubly densely divisible and the  variables are densely divisible, which was already needed to obtain the factorisation of
variables are densely divisible, which was already needed to obtain the factorisation of  into
into 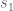 and
and  variables.
variables.
We now split where
where 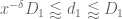 and
and 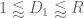 is to be chosen later, and
is to be chosen later, and 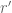 is densely divisible. Throwing away most of the averages, we need to show
is densely divisible. Throwing away most of the averages, we need to show
for typical values of and some
and some 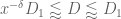 , where
, where
We apply van der Corput and reduce to showing that
The diagonal case contributes
contributes 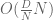 , so we need
, so we need
For the off-diagonal case, we complete sums in the n variable, noting that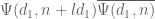 is periodic with period
is periodic with period ![d_2 := r' s_1 [t_1,t'_1] q_2](https://s0.wp.com/latex.php?latex=d_2+%3A%3D+r%27+s_1+%5Bt_1%2Ct%27_1%5D+q_2&bg=ffffff&fg=545454&s=0&c=20201002) , and reduce to showing that
, and reduce to showing that
for arbitrary . By construction,
. By construction, 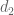 is
is  -densely divisible. Using van der Corput and assuming the Deligne level estimates, the left-hand side may be bounded by
-densely divisible. Using van der Corput and assuming the Deligne level estimates, the left-hand side may be bounded by
so we need
We can bound and
and 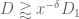 , so we need
, so we need
Combining this with (*) we reduce to
Since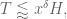 latex ST \sim Q$, we reduce to
latex ST \sim Q$, we reduce to
which we rearrange as
Since is basically
is basically  , and
, and 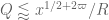 , this becomes
, this becomes
which (since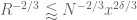 ) becomes
) becomes
since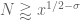 , this becomes (after some algebra)
, this becomes (after some algebra)
setting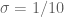 , this becomes
, this becomes
As mentioned previously, this should lead to roughly around 630, keeping in mind that one has to adjust
roughly around 630, keeping in mind that one has to adjust  to ensure quadruple dense divisibility.
to ensure quadruple dense divisibility.
20 July, 2013 at 8:16 am
Aubrey de Grey
Two quick novice-level questions:
1) Is this refinement essentially what is referred to as “Type I level 5” on the wiki, or does that refinement still potentially exist as a next step?
2) Given the exhaustion of options in Type I and the consequent need to focus on somehow reducing sigma, I’m curious at the lack of response to Pace Nielsen’s comment https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-238723 . Is it obviated by Terry’s comment posted just five minutes later? If not, and if there is indeed some mysterious reason why a Type V situation is impossible, is that the lowest-hanging fruit at this point?
20 July, 2013 at 9:26 am
Terence Tao
1) Yes, one could view this as partially realising the idea behind the Level 5 Type I estimate, although the original version of this idea didn’t quite work; it tried to push additional averaging, e.g. over parameters, inside the Cauchy-Schwarz to reduce the diagonal terms, which it does do, but this makes the off-diagonal terms much worse because these the modulus varies with these parameters and one is left with a sum over a much larger modulus, which is undesirable. However the
parameters, inside the Cauchy-Schwarz to reduce the diagonal terms, which it does do, but this makes the off-diagonal terms much worse because these the modulus varies with these parameters and one is left with a sum over a much larger modulus, which is undesirable. However the  averaging can be partially used after applying a van der Corput to modify the modulus to the point where it does not depend on one of the factors
averaging can be partially used after applying a van der Corput to modify the modulus to the point where it does not depend on one of the factors  of
of  , and then one can safely exploit averaging in the
, and then one can safely exploit averaging in the  parameter. (There is a related idea of Fouvry and Iwaniec that was pointed out to me by Philippe.) I’ve updated the wiki to reflect this.
parameter. (There is a related idea of Fouvry and Iwaniec that was pointed out to me by Philippe.) I’ve updated the wiki to reflect this.
2) The stumbling block is having to invent a new type of estimate – a Type V estimate – to deal with the convolution of five smooth but very short sequences. The only way we know how to do this is to combine some of the short sequences into rough sequences and then use the Type I arguments; the Type III arguments (which can control the convolution of three smooth and medium-length sequences) don’t seem to give a favorable numerology in the quintuple convolution setting (even the quadruple convolution case makes this argument only recover the Bombieri-Vinogradov type bound). There’s a more general problem with exponential sum estimates in that very short averages are quite difficult to exploit, even if there are many of them; the main trick to exploit such averages is to combine many of them together into one long average (weighted by some divisor function which is then eliminated by a Cauchy-Schwarz), but one has to perform at least one completion of sums trick before one can do this, and when one is convolving many short sequences together this becomes very expensive. It may be that one will have to wait for a radically new technique for controlling exponential sums to be discovered before one can start making Type V estimates that are competitive with the existing Type I, II, III estimates in the parameter ranges of interest.
20 July, 2013 at 10:42 am
Aubrey de Grey
1) Thanks! 2) Well sure, but what I was referring to was this comment from Pace: “Here is something I tried to figure out but couldn’t make it work. Does the Type V decomposition actually occur in the cases we care about? That is, when utilizing the Heath-Brown decomposition, can we have exactly 5 smooth terms, each roughly of scale x^{1/5}?”. I am far from being able to know in sufficient detail just what are “the cases we care about”, but is there anything in this? Maybe Pace could elaborate?
20 July, 2013 at 1:51 pm
Pace Nielsen
@Aubrey,
Terry’s post five minutes after mine was exactly the type of thing I was asking after. It appears that we cannot simply avoid consideration of the Type V case; it does actually occur in practice.
Thus, as far as I understand it, the only easy/likely way we currently can improve the estimates is by directly improving the numerics in the Type I case.
20 July, 2013 at 2:04 pm
Terence Tao
In the specific case of the Heath-Brown identity
the Type V sum arises as follows. If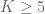 , then the
, then the 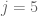 term contains, among other things, a component of the form
term contains, among other things, a component of the form 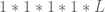 , which on dyadic decomposition gives Type V sums, including the most critical one where all five components are at scale
, which on dyadic decomposition gives Type V sums, including the most critical one where all five components are at scale  . For smaller values of
. For smaller values of  , the Type V sums are more implicit. For instance, when
, the Type V sums are more implicit. For instance, when  , we have a term of the form
, we have a term of the form 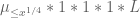 which is actually worse than a Type V sum because one of the factors is rough instead of smooth, and for which all five components can be at scale
which is actually worse than a Type V sum because one of the factors is rough instead of smooth, and for which all five components can be at scale  . Similarly for
. Similarly for  and
and 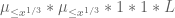 . For
. For 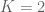 , we have a term of the form
, we have a term of the form  , which among other things contains the convolution of a rough sequence at scale
, which among other things contains the convolution of a rough sequence at scale  , a rough sequence at scale
, a rough sequence at scale  , and two smooth sequences at scale
, and two smooth sequences at scale  which is a worse convolution to deal with than five smooth convolutions at scale
which is a worse convolution to deal with than five smooth convolutions at scale  (since the latter type of convolution is a subcase of the former). Similarly for
(since the latter type of convolution is a subcase of the former). Similarly for  and
and 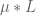 .
.
20 July, 2013 at 2:11 pm
Aubrey de Grey
Thanks! And anyway, I note that reducing sigma has become almost non-beneficial with the latest type I improvement (I’m getting 123/1318 or about 1/10.7 for the optimal sigma, with varpi at 8/659 if that sigma were permitted), pending any Type III improvements.
20 July, 2013 at 2:55 pm
Gergely Harcos
Dear Terry, congratulations to this amazing post. I have verified everything carefully, so all the question marks at the relevant Wiki pages can be deleted.
Here is a list of minor suggestions and corrections:
1. In Lemma 13 we should make clear that runs through integers coprime with
runs through integers coprime with  .
.
2. In the second display below (42), the conditions and
and 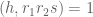 are missing. More importantly, the factor
are missing. More importantly, the factor 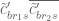 is missing.
is missing.
3. In the fifth display below (42), I would add the condition for clarity, although formally speaking this is not necessary.
for clarity, although formally speaking this is not necessary.
4. In the seventh display below (42), the condition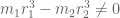 is missing.
is missing.
5. In the sixth display above (43), should be
should be  , and the condition
, and the condition 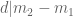 should be deleted.
should be deleted.
6. In the third and fourth display above (43),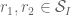 should be
should be  .
.
7. In the display below (43), should be
should be 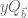 .
.
8. I think that (13) needs to be strengthened to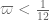 in order to yield the third display below (43).
in order to yield the third display below (43).
9. In the fourth display below (43), the factor can be deleted (cf. item 7). Accordingly, in the next display the factor
can be deleted (cf. item 7). Accordingly, in the next display the factor 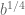 can be deleted.
can be deleted.
10. In the ninth and twelfth display below (43), should be
should be  .
.
[Corrected, thanks, and many thanks for the careful reading of all the blog posts! – T.]
21 July, 2013 at 12:36 am
Gergely Harcos
1. In the second display below (42), the condition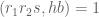 appears too early as
appears too early as  does not exist at that point. This is why I suggested the separate conditions
does not exist at that point. This is why I suggested the separate conditions  and
and 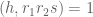 .
.
2. In the third display above (43),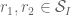 should be
should be  .
.
3. In the twelfth display below (43),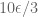 should be
should be  .
.
[Corrected, thanks – T.]
20 July, 2013 at 5:10 pm
Eytan Paldi
It seems that if the above quartic curve is reducible, then its factors should be of first degree with respect to y. So y should be a rational function of x for both factors.
Therefore this factorization is generic in the above parameters only if the discriminant of the resulting quadratic equation of y is a square of a polynomial in x for each choise of the above parameters.
27 July, 2013 at 9:34 am
Terence Tao
I managed to get a value of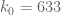 from the constraint
from the constraint 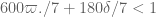 from https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-239189 and quadruple dense divisibility (which means that the quatity
from https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-239189 and quadruple dense divisibility (which means that the quatity  is set equal to
is set equal to 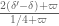 instead of
instead of 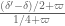 (for dense divisibility) or
(for dense divisibility) or 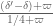 (for double dense divisibility). It is likely that one can shave
(for double dense divisibility). It is likely that one can shave  a little bit more by optimising the free parameters
a little bit more by optimising the free parameters  further. From the tables at http://math.mit.edu/~primegaps/ , this gives bounded gaps between primes with
further. From the tables at http://math.mit.edu/~primegaps/ , this gives bounded gaps between primes with 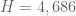 .
.
I’m in the process of writing the details of the Type I estimate leading to this improvement in a blog post which should be ready within a day or two.
k0 := 633;
delta := 1/8000;
varpi := (1 - 180*delta/7) * 7 / 600;
deltap := 1/130;
A := 500;
theta := deltap / (1/4 + varpi);
thetat := min( (2*(deltap - delta) + varpi) / (1/4 + varpi), 1);
deltat := delta / (1/4 + varpi);
j := BesselJZeros(k0-2,1);
eps := 1 - j^2 / (k0 * (k0-1) * (1+ 4*varpi));
kappa1 := int( (1-t)^((k0-1)/2)/t, t = theta..1, numeric);
kappa2 := (k0-1) * int( (1-t)^(k0-1)/t, t=theta..1, numeric);
alpha := j^2 / (4 * (k0-1));
e := exp( A + (k0-1) * int( exp(-(A+2*alpha)*t)/t, t=deltat..theta, numeric ) );
gd := (j^2/2) * BesselJ(k0-3,j)^2;
tn := sqrt(thetat)*j;
gn := (tn^2/2) * (BesselJ(k0-2,tn)^2 - BesselJ(k0-3,tn)*BesselJ(k0-1,tn));
kappa3 := (gn/gd) * e;
eps2 := 2*(kappa1+kappa2+kappa3);
# we win if eps2 < eps
27 July, 2013 at 2:02 pm
Gergely Harcos
Sounds great! I think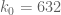 is admissible, yielding prime gaps of size
is admissible, yielding prime gaps of size 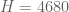 (http://math.mit.edu/~primegaps/tuples/admissible_632_4680.txt). Using
(http://math.mit.edu/~primegaps/tuples/admissible_632_4680.txt). Using  ,
, 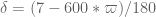 ,
,  ,
, 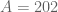 , I am getting
, I am getting  ,
,  ,
, 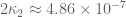 ,
,  . Please check as I am writing this in a rush.
. Please check as I am writing this in a rush.
[This seems to check out – T.]
27 July, 2013 at 4:53 pm
Terence Tao
Oops, I encountered a problem while writing up the argument… it turns out that in order for a -smooth number
-smooth number  to be
to be  -tuply densely divisible, it is not enough for
-tuply densely divisible, it is not enough for 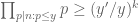 as I had thought… instead one needs the slightly stronger condition
as I had thought… instead one needs the slightly stronger condition 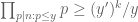 . This has the effect of increasing
. This has the effect of increasing  slightly from
slightly from 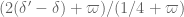 to
to 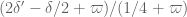 . I can recover
. I can recover 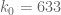 with this weaker criterion (using
with this weaker criterion (using  ,
, 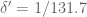 , and
, and 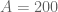 ) but just barely fail recovering
) but just barely fail recovering 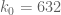 (keeping those same values of
(keeping those same values of 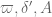 one is only off by about 5% or so). But perhaps a more careful optimisation can recover this.
one is only off by about 5% or so). But perhaps a more careful optimisation can recover this.
In any event, even without delta issues,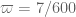 gives
gives  at best, so there isn’t terribly much room for further optimisation without improving
at best, so there isn’t terribly much room for further optimisation without improving  .
.
27 July, 2013 at 6:32 pm
Gergely Harcos
[Confirmed, thanks! – T.]
27 July, 2013 at 6:57 pm
Gergely Harcos
30 July, 2013 at 1:08 pm
Eytan Paldi
Since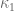 is (significantly) dominant over
is (significantly) dominant over
 , it seems that its reduction may lead to a further (small) reduction in
, it seems that its reduction may lead to a further (small) reduction in  . One possibility is by trying to increase
. One possibility is by trying to increase
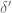 (and thereby
(and thereby  ). Another possibility is to improve the upper bound on
). Another possibility is to improve the upper bound on 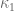 (by improving the current bound on
(by improving the current bound on
 – I just found a simple improved bound – I’m preparing the details.)
– I just found a simple improved bound – I’m preparing the details.)
27 July, 2013 at 6:55 pm
An improved Type I estimate | What's new
[…] purpose of this (rather technical) post is both to roll over the polymath8 research thread from this previous post, and also to record the details of the latest improvement to the Type I estimates (based on […]