
Van Vu and I have just uploaded to the arXiv our new paper, “Random matrices: Universality of ESDs and the circular law“, with an appendix by Manjunath Krishnapur (and some numerical data and graphs by Philip Wood). One of the things we do in this paper (which was our original motivation for this project) was to finally establish the endpoint case of the circular law (in both strong and weak forms) for random iid matrices 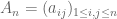

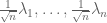
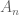
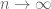
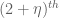
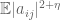

As it turned out, though, in the course of this project we found a more general universality principle (or invariance principle) which implied our results about the circular law, but is perhaps more interesting in its own right. Observe that the statement of the circular law can be split into two sub-statements:
- (Universality for iid ensembles) In the asymptotic limit
with the same mean and variance.
- (Circular law for gaussian matrices) In the asymptotic limit
The reason we single out the gaussian matrix ensemble
These highly algebraic techniques completely break down for more general iid ensembles, such as the Bernoulli ensemble of matrices whose entries are +1 or -1 with an equal probability of each. Nevertheless, it is a remarkable phenomenon – which has been referred to as universality in the literature, for instance in this survey by Deift – that the spectral properties of random matrices for non-algebraic ensembles are in many cases asymptotically indistinguishable in the limit
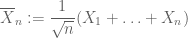
of an iid sequence depends only on the mean and variance of the elements of that sequence (assuming of course that these quantities are finite), and not on the underlying distribution. (The Hermitian non-commutative analogue of the CLT is known as Wigner’s semicircular law.)
Previous approaches to the circular law did not build upon the gaussian case, but instead proceeded directly, in particular controlling the ESD of a random matrix
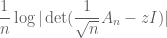
of that matrix for complex numbers z. This method required a combination of delicate analysis (in particular, a bound on the least singular values of 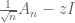
What we discovered while working on our paper was that the algebra and analysis could be largely decoupled from each other: that one could establish a universality principle (Statement 1 above) by relying primarily on tools from analysis (most notably the bound on least singular values mentioned earlier, but also Talagrand’s concentration of measure inequality, and a universality principle for the singular value distribution of random matrices due to Dozier and Silverstein), so that the algebraic heavy lifting only needs to be done in the gaussian case (Statement 2 above) where the task is greatly simplified by all the additional algebraic structure available in that setting. This suggests a possible strategy to proving other conjectures in random matrices (for instance concerning the eigenvalue spacing distribution of random iid matrices), by first establishing universality to swap the general random matrix ensemble with an algebraic ensemble (without fully understanding the limiting behaviour of either), and then using highly algebraic tools to understand the latter ensemble. (There is now a sophisticated theory in place to deal with the latter task, but the former task – understanding universality – is still only poorly understood in many cases.)
To oversimplify a little bit, the universality principle we actually establish is the following:
Theorem 1. (Universality principle) Let
such that the normalised coefficients
are iid. Then in the limit
, and on the variance of the coefficients.
The universality for the circular law (Statement 1) corresponds to the special case 
In the case of the central limit theorem, or for limit theorems for the (necessarily real) eigenvalues of Hermitian or symmetric random matrices, this sort of universality can be obtained via the moment method, and is well understood (and known as the “Lindeberg principle”). Consider for instance the situation in the central limit theorem, and more precisely the task of understanding the distribution of the averages 



If one expands out the expected moment 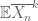

for various indices 

Note that this purely analytical approach did not attempt to actually compute what the limiting moments 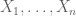


A similar argument allows one to establish Wigner’s semicircular law by first reducing it to the case of the gaussian ensemble; see this paper of Chatterjee for a discussion and extensive generalisations. (In this particular case, this route is not all that much simpler than the traditional method of using the enumerative combinatorics of Catalan numbers to compute the moments directly, or by using the slick machinery of free probability to clean up the computations, but it still illustrates the basic point that one can establish universality by primarily analytic means before having to understand what the limit actually is.)
In the case of non-Hermitian random matrix ensembles, such as iid ensembles, the eigenvalues are now complex instead of real, and the moment method no longer gives enough information on the ESD to settle the problem. (For instance, in the case of the circular law, all normalised moments 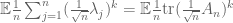
Nevertheless, Girko observed that the (normalised) ESD of a matrix
So the remaining task is to show a universal property for the magnitude of the determinant of random matrices such as
In previous work on the circular law, starting from the breakthrough paper of Girko, this determinant was tackled by expressing it as a product of the singular values of
A recent paper of Dozier and Silverstein shows that the limiting distribution of
To resolve this, we took a slightly different tack, expressing the magnitude of the determinant as the volume of the parallelopiped generated by its rows, which by the high-school “base times height” formula is then the product of various distances from one row to the subspace spanned by previous rows. The first few terms in this product are easy to understand, but things become difficult for the very last few rows, as the subspace now has very high dimension. Nevertheless, thanks to existing work on the least singular value problem (and in particular, the bounds on this problem contained in our previous circular law paper), one can show that the contribution of the last few rows is in fact negligible. For the bulk of the rows, one can use a classical singular value interlacing inequality going back to Cauchy to control the bulk contribution by the distribution of the singular values, for which the Dozier-Silverstein approach applies. It remains to control the contribution of the intermediate rows which are close, but not too close, to the bottom. Previously, these rows needed a good rate of convergence on the singular values in order to be controlled; but, borrowing a trick from one of our previous papers, we applied a very useful concentration-of-measure inequality of Talagrand instead to show that the contribution of these rows is negligible also.
In the appendix by Manjunath Krishnapur, a variant of the Dozier-Silverstein result, which establishes universality (in the weak sense of convergence in probability) without computing the limit for a wider class of random matrices, is established by exploiting an invariance principle of Chatterjee that generalises the Lindeberg trick.

34 comments
Comments feed for this article
6 August, 2008 at 11:35 am
Mark Meckes
This is a very nice approach, and beautiful results.
A typo (or missing detail?) in the post: you write
“in the case of the circular law, all normalised moments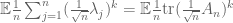 in fact vanish identically”.
in fact vanish identically”.
They do vanish in the limit as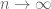 , but not necessarily for finite
, but not necessarily for finite  .
.
6 August, 2008 at 5:53 pm
Terence Tao
Dear Mark: Thanks for the correction!
7 August, 2008 at 1:43 am
R.A.
Dear Prof. Tao,
when writing about moments determining the measure , you probably meant “bounded” and not “finite”. I think that for instance the log-normal distribution is not determined by its moments (or maybe I am just confusing something?).
7 August, 2008 at 9:19 am
Terence Tao
Dear R.A.: Hmm, good point, I oversimplified that part a bit. I don’t want to get bogged down in technical issues at that point, though, so I’ll just put in a vague disclaimer that one needs to assume the probability distribution “has sufficient decay at infinity” (e.g. subgaussian is certainly OK, and one can probably relax this quite a bit.)
7 August, 2008 at 6:36 pm
Mark Meckes
Regarding R.A.’s point: I don’t recall what the necessary and sufficient decay condition is, although it’s known and in standard references. One easy-to-state sufficient condition is that the moment generating function (i.e. Laplace transform) converges in some neighborhood of 0. Thus exponential decay is already enough.
15 October, 2008 at 2:19 am
weiyu
I am reading and trying to understand and learn from this paper. I just have a few minor questions. Can you explain a little more here?
In equation (16), why do we have “some smooth, rapidly decreasing function \hat(f)” and why the measure “du=\hat(f)du dv” is finite?
Should the A_n in the second integral be B_n?
Are the brackets in equation (8) (or in Theorem 1.22) put in the right way?
In equation (19), the denominator in the integral may be “|s+it-w|^2”
15 October, 2008 at 10:58 am
Terence Tao
Dear Weiyu,
Thanks for the corrections! In (8), there should be additional parentheses around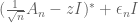 .
.
In (16),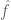 is basically the Fourier transform of f (we are using Parseval’s identity here). The Fourier transform of a smooth compactly supported function is smooth and rapidly decreasing (indeed, both f and
is basically the Fourier transform of f (we are using Parseval’s identity here). The Fourier transform of a smooth compactly supported function is smooth and rapidly decreasing (indeed, both f and 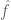 are Schwartz functions).
are Schwartz functions).
18 October, 2008 at 12:14 pm
From the Littlewood-Offord problem to the Circular Law: universality of the spectral distribution of random matrices « What’s new
[…] to the circular law for the ESDs for iid random matrices with zero mean and unit variance (see my previous blog post on this topic, or my Lewis lectures). We conclude by mentioning a few open problems in the […]
25 October, 2008 at 12:43 am
weiyu
Dear Professor Tao,
I guess in Proposition 5.1, $d$ should be [1, n-n^0.99], instead of [1,n-n^0.9] . The exponent 0.9 certainly implies the result for the exponent 0.99, but in the proof, when we do the projection from C^n->C^{n’} (the equation 32) and be “adjusting c slightly”, the exponent 0.9 does not seem to go through. From the context, it also seems to be 0.99. Hope I did not get it wrong
In using Talagrand’s inequality, do we implicitly assume that as n grows, the “median” be approaching the square root of the “expected second moments”?
25 October, 2008 at 8:13 am
Terence Tao
Dear Weiyu,
Thanks for the correction! Talagrand’s inequality implies in particular that the root mean square is necessarily close to the median, and so bounding one is equivalent (up to constants) to bounding the other.
4 November, 2008 at 12:10 am
weiyu
Dear Professor Tao,
Thanks for the previous answers and they help a lot.
I have one additional question left. In the proof of Lemma 6.3., can you explain in further details how the interlacing property leads to the euqation right below equation (37)? I am not sure I understand this part or understand correctly.
Thanks.
4 November, 2008 at 7:04 am
Terence Tao
Dear weiyu,
Let’s start with the base case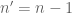 . From the interspersing relation
. From the interspersing relation
we see that for any function f, the difference between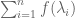 and
and 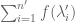 is bounded in magnitude by the total variation of f, plus the maximum value of f. This gives an error term of the form
is bounded in magnitude by the total variation of f, plus the maximum value of f. This gives an error term of the form  in the equation below (37). Iterating this, we see that when
in the equation below (37). Iterating this, we see that when  , the total error is about
, the total error is about  , which is
, which is 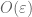 when
when  is small enough.
is small enough.
3 December, 2008 at 4:00 pm
John Jiang
Dear Professor Tao,
I am wondering how the circular law will be different if one restricts to real valued gaussian iid entries. Does the same approach of Girko’s lemma work in that case? Also have you thought about singular values of iid complex Gaussian square matrices? I know their limiting spectral measure obey the quadrant law, which is the first quadrant of the unit disk on the complex plane, but as far as I know there are no rigorous proofs of this result yet.
Thanks,
John
6 December, 2008 at 9:41 pm
Terence Tao
Dear John,
The circular law is valid for all complex iid matrices with zero mean and unit variance, which includes the real-valued gaussian case (for which the circular law was first worked out by Edelman).
For singular values of iid matrices the universality principle is much easier to establish (because in this case the bulk distribution can be worked out from the moment method), and indeed we rely on a paper of Dozier and Silverstein which more or less does exactly this (as does the paper of Chatterjee that we also use). In particular, the distribution of the singular values of an iid matrix will depend only on the mean and variance of the entries.
7 December, 2008 at 8:48 pm
bobo
Dear Prof Tao,
i have x in C^n complex gaussian vector and X=x*x’ form Hermitian
matrix with rank 1. eign distribution of X can be evaluated with
Wishard Distribution.
But i would like to know.. the spacing distribution of two consecutive
eigenvalues. could you pls point me the reference..
thanks,
bobo
1 February, 2009 at 6:29 pm
Anonymous
Dear Prof Tao,
I’m trying to understand and learn form this paper. I have some minor questions during the reading, could you please give a little more details?
In (22), how can I see the inner integrand is bounded by an explicit upper bound of Pi and the “inequality” below (26) should \lamda be the absolute value of \lamda?
I guess it should be n^2 instead of n in (13) and B_n instead of A_n in (16).
Also, in (17) I think we are taking the real part of the summation.
Thanks,
Ricky
1 February, 2009 at 10:26 pm
Terence Tao
Dear Ricky,
Thanks for the corrections!
The upper bound in (22) stems from the classical Poisson integral identity , which can be seen by a trigonometric substitution. (The
, which can be seen by a trigonometric substitution. (The 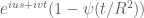 term has magnitude at most 1 and can be discarded.)
term has magnitude at most 1 and can be discarded.)
5 February, 2009 at 7:32 am
Paul
Dear Professor Tao,
When trying to understand the new techniques in your paper, there is a minor point I could not get. To show the strong boundedness of the empirical spectral distribution (Lemma 1.11), the strong law of large numbers is required. It seems to me that we need such a law for triangular arrays of random variables, which does not exit in full generality. How do you circumvent this ?
Thank you,
Paul
5 February, 2009 at 9:11 am
Terence Tao
Dear Paul,
The expression is the average of
is the average of 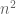 iid copies of a single random variable
iid copies of a single random variable 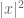 . By a suitable relabeling one can rewrite this expression as
. By a suitable relabeling one can rewrite this expression as  , where
, where 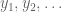 are iid copies of
are iid copies of 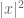 (and such that
(and such that  correspond to the
correspond to the  for
for 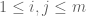 ). From the strong law of large numbers we know that
). From the strong law of large numbers we know that  is a.s. bounded (and even convergent), and so
is a.s. bounded (and even convergent), and so  is also a.s. bounded.
is also a.s. bounded.
5 February, 2009 at 10:32 am
Paul
Dear Professor Tao,
Thank you for your answer. The strong law of large numbers means that
 converges almost surelay, as you say. My impression here was that we need a strong law of large numbers for sums like
converges almost surelay, as you say. My impression here was that we need a strong law of large numbers for sums like  , where the $y^{(N)}_k$’s are iid but all distinct when $N$ changes.
, where the $y^{(N)}_k$’s are iid but all distinct when $N$ changes.
Best,
Paul
5 February, 2009 at 10:49 am
Paul
Sorry, I just realized that the entries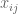 are conserved for all
are conserved for all  , thank you.
, thank you.
8 February, 2009 at 8:40 pm
Anonymous
Dear Professor Tao,
Thanks for your previous answer, it’s very helpful! I’m not quite sure the meaning of the symbol in the equation right below (26) which looks like a inequality sign and I’m also confused about the right hand side of that equation. Could you specify this a little more?
Thank you,
Ricky
9 February, 2009 at 12:22 am
Terence Tao
The equation below (26) should read
below (26) should read  (we changed the notation at some point from
(we changed the notation at some point from 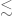 ‘s to O()’s, but I guess this particular equation managed to somehow survive the switch). The estimate is a fairly crude one, basically reflecting the fact that
‘s to O()’s, but I guess this particular equation managed to somehow survive the switch). The estimate is a fairly crude one, basically reflecting the fact that
(The first estimate comes from the local integrability of in the plane.)
in the plane.)
16 February, 2009 at 9:46 am
A sharp inverse Littlewood-Offord theorem « What’s new
[…] 16 February, 2009 in math.CO, math.PR, paper | Tags: generalised arithmetic progressions, Littlewood-Offord theorems, random walks, Van Vu | by Terence Tao Van Vu and I have just uploaded to the arXiv our preprint “A sharp inverse Littlewood-Offord theorem“, which we have submitted to Random Structures and Algorithms. This paper gives a solution to the (inverse) Littlewood-Offord problem of understanding when random walks are concentrated in the case when the concentration is of polynomial size in the length of the walk; our description is sharp up to epsilon powers of . The theory of inverse Littlewood-Offord problems and related topics has been of importance in recent developments in the spectral theory of discrete random matrices (e.g. a “robust” variant of these theorems was crucial in our work on the circular law). […]
2 March, 2009 at 11:39 am
Anonymous
Dear Professor Tao,
Could you please explain more about how you get the equation right before (23), I specially want to know what role did “|w|<=R” play here.
Thank you
2 March, 2009 at 1:00 pm
Terence Tao
Dear anonymous,
The assumption ensures (in conjunction with the presence of the cutoff
ensures (in conjunction with the presence of the cutoff 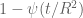 ) that the denominator
) that the denominator  is large (of size at least
is large (of size at least  ). Now we integrate by parts, integrating the
). Now we integrate by parts, integrating the  term many times (four times will suffice) and differentiating all the other terms. When the derivative falls on the cutoff
term many times (four times will suffice) and differentiating all the other terms. When the derivative falls on the cutoff 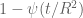 one essentially gains a factor of
one essentially gains a factor of  ; and similarly when the derivative falls on
; and similarly when the derivative falls on 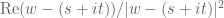 , due to the separation between t and w. (In fact one can continue integrating by parts indefinitely and get a bound of
, due to the separation between t and w. (In fact one can continue integrating by parts indefinitely and get a bound of 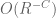 for any C.)
for any C.)
12 April, 2009 at 5:23 am
Anonymous
Dear Professor Tao,
Thanks for your previous answer.
To see equation(24)on page 20: I tried to break the eigenvalues of
A_n (say \lamda_j ) into two cases: i) |\lamda_j \leq R ii) |\lamda_j|>R.
By part ii) of lemma 3.4 and 17), the triangle inequality
we have (24) is O(\epsilon) when i) holds and there’s no question about that.
For case ii), I think we need to get a upper bound of (22) which is
independent of R, because (22) is O(\epsilon)only when R is large enough.
Then one can use (21) and triangle inequality to get (24) is O(\epsilon) in this case too, which implies the claim of (24). But unfortunately I haven’t worked it out so far.
could you please give a little more details about this?
Thank you
12 April, 2009 at 10:01 am
Terence Tao
Dear anonymous,
The bounds (23), (24) are only proven under the assumption that R is sufficiently large depending on epsilon, but as one can choose R to be whatever one pleases, this is all one needs anyway (note that the convergence of (25) is going to be established for every R).
3 June, 2009 at 11:16 am
Random matrices: universality of local eigenvalue statistics « What’s new
[…] are based primarily on the Lindeberg replacement strategy, which Van and I also used to obtain universality for the circular law for iid matrices, and for the least singular value for iid matrices, but also rely on other tools, such as some […]
27 July, 2009 at 3:05 am
Student A
Dear Prof. Tao,
do you have a quick argument, proving that the normalized spectral moments of non-Hermitian randm matrix ensembles converge to zero identically?
Thank you!
27 July, 2009 at 1:05 pm
Terence Tao
Well, for ensembles such as the random complex gaussian matrix A, one can use the invariance of the distribution under the phase rotation to show that all moments
to show that all moments  must have zero expectation.
must have zero expectation.
For more general ensembles (e.g. random Bernoulli), I think one can just work out the moments by hand and see that they are quite small. For instance working out the normalised moments for A Bernoulli and k=1,2,3,4 is quite instructive.
for A Bernoulli and k=1,2,3,4 is quite instructive.
12 August, 2009 at 5:46 am
Giovanni Peccati
Dear Terence,
some joint CLTs for traces of non-Hermitian random matrices, which have a somewhat ”universal” flavour, are contained in a recent paper by I. Nourdin and myself
http://arxiv.org/abs/0908.0391
All the best,
Giovanni
14 March, 2010 at 11:33 am
254A, Notes 8: The circular law « What’s new
[…] This theorem has a long history; it is analogous to the semi-circular law, but the non-Hermitian nature of the matrices makes the spectrum so unstable that key techniques that are used in the semi-circular case, such as truncation and the moment method, no longer work; significant new ideas are required. In the case of random gaussian matrices, this result was established by Mehta (in the complex case) and by Edelman (in the real case), as was sketched out in Notes. In 1984, Girko laid out a general strategy for establishing the result for non-gaussian matrices, which formed the base of all future work on the subject; however, a key ingredient in the argument, namely a bound on the least singular value of shifts , was not fully justified at the time. A rigorous proof of the circular law was then established by Bai, assuming additional moment and boundedness conditions on the individual entries. These additional conditions were then slowly removed in a sequence of papers by Gotze-Tikhimirov, Girko, Pan-Zhou, and Tao-Vu, with the last moment condition being removed in a paper of myself, Van Vu, and Manjunath Krishnapur. […]
17 July, 2013 at 6:22 pm
Local universality of zeroes of random polynomials | What's new
[…] paper (and can be viewed as a local-scale version of the global-scale replacement principle in this earlier paper of ours). Specialising the replacement principle to the elliptic or flat polynomials, and using the […]