
I am posting here four more of my Mahler lectures, each of which is based on earlier talks of mine:
- Compressed sensing. This is an updated and reformatted version of my ANZIAM talk on this topic.
- Discrete random matrices. This talk is a survey on recent developments on the universality phenomenon in random matrices, including work of myself and Van Vu. It covers similar material to my Netanyahu lecture, which has not previously appeared in electronic form.
- Recent progress in additive prime number theory. This is an updated and reformatted version of my AMS lecture on this topic.
- Recent progress on the Kakeya conjecture. This is an updated and reformatted version of my Fefferman conference lecture.
As always, comments, corrections, and other feedback are welcome.

24 comments
Comments feed for this article
31 August, 2009 at 7:39 pm
Phi. Isett
On page 16 of the Random matrices talk there’s a sentence fragment
“Many, many further refinements and
proofs.”
And another on page 18 (but it’s the same, so I’m now a bit unsure it’s unintentional…)
Slightly related and maybe the wrong entry to ask: a long time ago on one of your blog posts you mentioned (paraphrasing) that there’s a connection between the law of large numbers (or maybe it was the central limit theorem) and intuition from information theory (presumably something to do with entropy?). I’m not sure if you’ve elaborated that point since then (it sounded interesting). Maybe you would like to talk more about it in connection to this new work?
31 August, 2009 at 9:50 pm
Lachlan Andrew
That may have been a reference to the relation between the central limit theorem and the information theoretic result that a Gaussian has maximum entropy of any distribution of a given variance.
The connection is discussed in
A. R. Barron.
Entropy and the central limit theorem.
Ann. Probab., 14:336-342, 1986.
and refined in
“Solution of Shannon’s problem on the monotonicity of entropy”
Author(s): Shiri Artstein; Keith M. Ball; Franck Barthe; Assaf Naor
Journal: J. Amer. Math. Soc. 17 (2004), 975-982.
The latter shows that the entropy of $\sum_{i=1}^{n}/\sqrt{n}$ increases monotonically.
I’ve been looking for other senses in which convergence to the CLT is “monotonic” in the number of terms, and would be grateful for any pointers.
31 August, 2009 at 9:02 pm
AK
typo: “Recent progress in additive prime number theory”
page 15: To put … no structure beyong [beyond] the obvious ones …
1 September, 2009 at 12:33 am
Anonymous
Typo in Kakeya slide; needs more verb:
“use linear algebra to a non-trivial polynomial”
1 September, 2009 at 2:18 am
KKK
In the prime number theory slide, the last sentence is not shown clearly on p.9, at the bottom.
1 September, 2009 at 1:58 pm
Terence Tao
Thanks for the corrections! I’ve updated the compressed sensing and prime number theory slides to address some significant issues (missing slides, etc.). I’ll hold off on the other updates until other significant changes need to be made.
2 September, 2009 at 8:19 pm
Ragib Morshed
Dear Prof. Tao,
I have always been intrigued by compressive sensing. Both my undergraduate thesis in computer science and mathematics were on compressive sensing. Even though I am starting my graduate studies in machine learning, I am still very interested in compressive sensing ideas. I was first introduced to compressive sensing at a talk by Emmanuel Candes, and decided to do my undergraduate theses based on it. My cs and math advisors are not specialized in this field, but they took great interest in guiding me after I proposed working on this topic.
Anyways, I took a quick look through your slides on compressed sensing, and it looks like a really good introductory talk. However, I think it might be more interesting if you include, as an example, application of compressive sensing ideas to face recognition. Here’s the link:
http://perception.csl.illinois.edu/recognition/Home.html
There are also a number of other interesting applications, like human action classifier, for example, that might serve as interesting examples in your talk.
Thank you.
3 September, 2009 at 5:05 am
Michael Peake
In the additive primes, page 27, the common difference is one more than a prime, rather than one less than a prime.
In the cosmic ladder talk, on page 80, you hint that you will say why Aristarchus’ ideas were rejected by the ancients; was it because
the measurements were inaccurate, as on page 83, or another reason?
3 September, 2009 at 6:53 pm
Terence Tao
Thanks for the corrections! I forgot to tell the story hinted at on page 80, which was that the Greeks objected to the heliocentric model on the grounds that it would caused observable parallax in the fixed stars, unless those stars were an unimaginably large distance away – which, of course, they are. I’ve amended the slides to reflect this.
3 September, 2009 at 10:41 am
Mathematical Research and the Internet « Euclidean Ramsey Theory
[…] https://terrytao.wordpress.com/2009/08/31/more-mahler-lectures/ Possibly related posts: (automatically generated)Mathematical research and the internet […]
3 September, 2009 at 2:24 pm
Anonymous
My brother encouraged me to skip school so I could see Don Zagier give the Mahler lectures at Melbourne University. His talks were absolutely inspiring — and Zagier paced, of course! It was my first exposure to many beautiful ideas in mathematics, from Hecke eigenforms and the BSD conjecture to the relationship between hyberbolic volume, special values of dilogarithms, and the Bloch group. Together with a two hour conversation with Matthew Emerton (on that same day) this pinpoints the very moment I decided to study algebraic number theory instead of analytic number theory. I hope your lectures will be similarly inspiring.
3 September, 2009 at 5:38 pm
Andriy
Interesting introduction to compressed sensing, wait to watch it today. Hope that that time all will be OK with connections and we will be able to hear questions and answers:-))
Just a question: You assume that the “right basis” is given, then you solve l_1 minimization problem.
However very often statistical(image analysis,…) point of view is that you have to find a “right basis” and l_1 minimization simultaneously. Indeed in many cases we do not know the “right basis” for huge new data sets in advance. Also the pair l_1 solution+basis might be nonunique. Are there any general theoretical results on simultaneous basis choice and l_1 minimization?
3 September, 2009 at 7:10 pm
Terence Tao
Well, every signal is sparse with respect to some basis, for instance a basis which includes the signal itself as one of the basis elements, so one can’t proceed very far just by knowing sparsity with respect to an unknown basis. But with a library of signals, I think there are tools (e.g. from machine learning) that can discover a common basis that is efficient for the bulk of these signals.
In practice, I would imagine that it would not be effective to learn the basis simultaneously with performing compressed sensing; ideally, one would like to spend more measurements to acquire an initial library of training signals with which to learn the basis before doing the compressed measurements.
Amusingly, if one is receiving a signal with an as-yet unknown basis, one could record it using random gaussian measurements, since such measurements work well with respect to any (orthonormal) basis. If and when the correct basis is discovered, one could perform l^1 minimisation (or other algorithms) to reconstruct the signal; until then, the data has been stored, but cannot be reconstructed.
3 September, 2009 at 8:20 pm
Andriy
Thank you for you comments. Absolutely agree in general case. Of course we are not going to include each signal in the basis :-))
Might be I had to specify my previous question. Suppose that we have different candidate bases from our initial analysis (as you mentioned we learn the basis before, but we might have many candidates, just for simplicity – different families with unknown parameters). I am interested to estimate parameters in the basis to inform my colleagues on my choice of basis (I can send them only parameters instead of all basis functions) and perform l_1 minimisation. Choice of basis parameters might not be l_1 problem (I am not 100% sure, need to check it). Do you think that in this case the following l_1 minimization is appropriate? I am suspicious that 2 stage procedure gives the best result, that’s why I asked about simultaneous one.
It seems knowing you use l_1 norm must force you to use some appropriate corresponding methods to chose the basis. So it supports some simultaneous choice somehow.
Might be more correct question is not about completely unknown basis, but partially unknown (or choice in some class of candidates).
I see that the problem is a little bit far of presentation results. Any way it is interesting to know your opinion. Thanks.
3 September, 2009 at 10:29 pm
Terence Tao
Your questions remind me of work on compressed sensing in redundant dictionaries (e.g. unions of several distinct bases), see e.g.
Click to access 0701131v1.pdf
It seems that much of the compressed sensing machinery extends to this case.
6 September, 2009 at 4:59 pm
Clay-Mahler lecture series « Mathematics in Australia
[…] Here are the slides for the four Access Grid Room talks, “Compressed sensing”, “Discrete random matrices”, “Recent progress in additive prime number theory”, and “Recent progress on the Kakeya problem”. […]
7 September, 2009 at 2:14 pm
Pietro Poggi-Corradini
I’ve enjoyed the talk on random matrices. Any chances it will become an actual survey paper with some details, references, etc…or does a closed substitute already exist?
10 September, 2009 at 8:32 pm
Yuan Lee
Hi Terry,
Really enjoyed the Q&A and your talk on compress sensing at the University of Queensland. Hope you’ll visit Australia soon again :)
Regards,
Yuan
12 September, 2009 at 6:42 pm
Paul Leopardi
On slide 38 of the Kayaka conjecture talk, what is the relationship between n and d?
14 September, 2009 at 2:33 am
Terence Tao
Oops, n is supposed to be d. It will be corrected in the next major update of the slides.
17 September, 2009 at 1:07 am
Indian
Dear Prof Tao,
I would like to ask you a query and it is: Are you attending (or going to attend) the next International Congress of Mathematicians (ICM) ’10 at Hyderabad?
If so, then it would be very nice. Are you attending it next year?
I don’t know for sure whether this is an appropriate place to ask you this query. If it isn’t I apologize.
18 July, 2010 at 6:29 pm
AJ
Professor:
Is there any work of UUP on non-archimedean spaces? Uncertainty has an implicit non-commutative flavor. Is there any study of UUP from anabelian geometry perspective?
Thank you,
AJ
31 March, 2011 at 3:47 pm
Sper
Some minor observations concerning slide 13 of the Compressed sensing slides are as follows:
1. The proof of the Proposition should begin: Then there are two S-sparse signals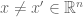 .
.
2. In the general case is at most 2S-sparse, and not always 2S sparse. For the purpose of the proof though, the fact that
is at most 2S-sparse, and not always 2S sparse. For the purpose of the proof though, the fact that  is exactly 2S-sparse is relevant, as written in the slides.
is exactly 2S-sparse is relevant, as written in the slides.
1 April, 2011 at 8:59 am
Sper
Actually, revisiting the definition of S-sparse signals: “A signal is S-sparse if it contains (at most) S nonzero entries”, led me to the conclusion that the second observation in my previous post is unfounded.