This is the sixth thread for the Polymath8b project to obtain new bounds for the quantity
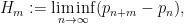
either for small values of  (in particular
(in particular 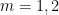 ) or asymptotically as
) or asymptotically as 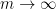 . The previous thread may be found here. The currently best known bounds on
. The previous thread may be found here. The currently best known bounds on 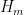 can be found at the wiki page (which has recently returned to full functionality, after a partial outage).
can be found at the wiki page (which has recently returned to full functionality, after a partial outage).
The current focus is on improving the upper bound on 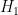 under the assumption of the generalised Elliott-Halberstam conjecture (GEH) from
under the assumption of the generalised Elliott-Halberstam conjecture (GEH) from 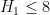 to
to 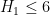 , which looks to be the limit of the method (see this previous comment for a semi-rigorous reason as to why
, which looks to be the limit of the method (see this previous comment for a semi-rigorous reason as to why 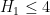 is not possible with this method). With the most general Selberg sieve available, the problem reduces to the following three-dimensional variational one:
is not possible with this method). With the most general Selberg sieve available, the problem reduces to the following three-dimensional variational one:
Problem 1 Does there exist a (not necessarily convex) polytope ![{R \subset [0,1]^3}](https://s0.wp.com/latex.php?latex=%7BR+%5Csubset+%5B0%2C1%5D%5E3%7D&bg=ffffff&fg=000000&s=0&c=20201002) with quantities
with quantities 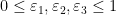 , and a non-trivial square-integrable function
, and a non-trivial square-integrable function  supported on
supported on  such that
such that
and such that we have the inequality
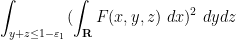
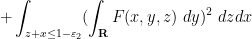
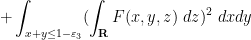

(Initially it was assumed that was convex, but we have now realised that this is not necessary.)
An affirmative answer to this question will imply on GEH. We are “within almost two percent” of this claim; we cannot quite reach  yet, but have got as far as
yet, but have got as far as  . However, we have not yet fully optimised
. However, we have not yet fully optimised  in the above problem.
in the above problem.
The most promising route so far is to take the symmetric polytope
![\displaystyle R = \{ (x,y,z) \in [0,1]^3: x+y+z \leq 3/2 \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R+%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5B0%2C1%5D%5E3%3A+x%2By%2Bz+%5Cleq+3%2F2+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
with symmetric as well, and  (we suspect that the optimal
(we suspect that the optimal  will be roughly
will be roughly  ). (However, it is certainly worth also taking a look at easier model problems, such as the polytope
). (However, it is certainly worth also taking a look at easier model problems, such as the polytope ![{{\cal R}'_3 := \{ (x,y,z) \in [0,1]^3: x+y,y+z,z+x \leq 1\}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Ccal+R%7D%27_3+%3A%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5B0%2C1%5D%5E3%3A+x%2By%2Cy%2Bz%2Cz%2Bx+%5Cleq+1%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which has no vanishing marginal conditions to contend with; more recently we have been looking at the non-convex polytope
, which has no vanishing marginal conditions to contend with; more recently we have been looking at the non-convex polytope 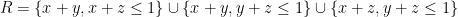 .) Some further details of this particular case are given below the fold.
.) Some further details of this particular case are given below the fold.
There should still be some progress to be made in the other regimes of interest – the unconditional bound on (currently at  ), and on any further progress in asymptotic bounds for for larger – but the current focus is certainly on the bound on on GEH, as we seem to be tantalisingly close to an optimal result here.
), and on any further progress in asymptotic bounds for for larger – but the current focus is certainly on the bound on on GEH, as we seem to be tantalisingly close to an optimal result here.
— 1. Analysis of the symmetric polytope —
In the symmetric situation described above, we have a single vanishing marginal condition
and the inequality we wish to prove is that

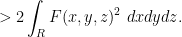
A routine calculus of variations computation, using Lagrange multipliers, tells us that the extremal should take the form

where  is symmetric and supported the disconnected set
is symmetric and supported the disconnected set 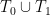 , where
, where  is the triangle
is the triangle
![\displaystyle T_0 := \{ (x,y) \in [0,1]^2: x+y \leq 1-\varepsilon\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++T_0+%3A%3D+%5C%7B+%28x%2Cy%29+%5Cin+%5B0%2C1%5D%5E2%3A+x%2By+%5Cleq+1-%5Cvarepsilon%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
and 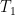 is the trapezoid
is the trapezoid
![\displaystyle T_1 := \{ (x,y) \in [0,1]^2: 1+\varepsilon \leq x+y \leq 3/2 \}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++T_1+%3A%3D+%5C%7B+%28x%2Cy%29+%5Cin+%5B0%2C1%5D%5E2%3A+1%2B%5Cvarepsilon+%5Cleq+x%2By+%5Cleq+3%2F2+%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
(Strictly speaking, we have not established that an extremiser actually exists, but for the purposes of numerics it seems to be reasonable to proceed as if an extremiser does exist.) One also has the eigenfunction equation

whenever ![{(x,y) \in [0,1]^2}](https://s0.wp.com/latex.php?latex=%7B%28x%2Cy%29+%5Cin+%5B0%2C1%5D%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002) is such that
is such that 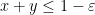 , where
, where  is the quantity that we are trying to push above . It seems that this eigenfunction equation should indicate where exactly we expect the singularities of and to lie, and how bad they will be (our best guess right now is that the extremiser is continuous but not differentiable at certain points), but this has not yet been fully analysed.
is the quantity that we are trying to push above . It seems that this eigenfunction equation should indicate where exactly we expect the singularities of and to lie, and how bad they will be (our best guess right now is that the extremiser is continuous but not differentiable at certain points), but this has not yet been fully analysed.
If we use the ansatz (1), we arrive at a moderately complicated variational problem involving one unknown symmetric function 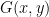 , which is constrained to be supported in and obeys the vanishing marginal condition
, which is constrained to be supported in and obeys the vanishing marginal condition
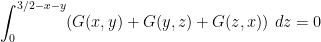
whenever 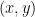 lies in . If we let
lies in . If we let  be the restrictions of to
be the restrictions of to 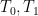 respectively (so that
respectively (so that  ), this constraint becomes
), this constraint becomes
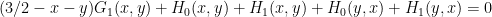
where
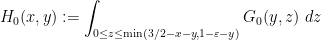
and

This equation can be used to solve for  in terms of
in terms of  , thus reducing to a variational problem for an unconstrained function on the triangle . In the hexagonal region
, thus reducing to a variational problem for an unconstrained function on the triangle . In the hexagonal region

the functions 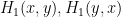 vanish, and we simply have
vanish, and we simply have
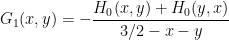
(note that  vanishes at the boundary
vanishes at the boundary 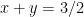 , so there is no singularity here). If
, so there is no singularity here). If 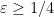 , this covers all of , and completes the reduction to a variational problem for . We do not believe this range to be the optimal value for , but might be worth considering as a warmup.
, this covers all of , and completes the reduction to a variational problem for . We do not believe this range to be the optimal value for , but might be worth considering as a warmup.
Now suppose 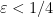 . In the triangular region
. In the triangular region
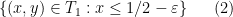
(bounded by the vertices 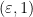 ,
, 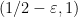 ,
,  ) we have vanishing of
) we have vanishing of  but not
but not 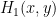 , leading to the equation
, leading to the equation
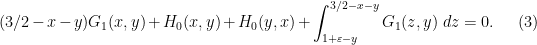
To solve this equation, we first differentiate it in  to obtain
to obtain
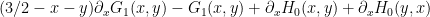
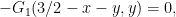
so if we define
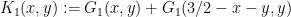
and
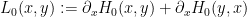
then

and thus by the substitution 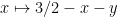 (which preserves the triangle (2), as well as
(which preserves the triangle (2), as well as  )
)

and so on subtracting

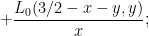
multiplying by  and rearranging, this becomes
and rearranging, this becomes


so we have
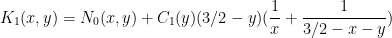
for some function  , where
, where
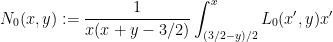
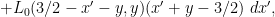
where we are using the signed integral, thus  when
when 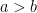 . Note that when
. Note that when  ,
, 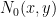 vanishes and
vanishes and  , and so
, and so

Meanwhile, from (4) we have

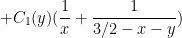
and so
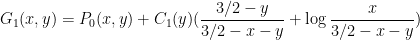
where
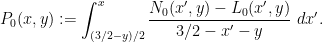
On the other hand, from (3) with  one has
one has
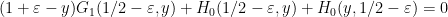
and so we may solve for 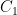 as
as

which gives an explicit (but messy) formula for in terms of in the triangle (2); by symmetry one also describes in the triangle
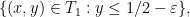
and this completes the description of in terms of . (The exact description is, however, rather messy, in particular requiring a certain amount of integration; it is not clear whether we should actually use it for the purposes of efficient numerics.)

![{R + R \subset \{ (x,y,z) \in [0,2]^3: \min(x+y,y+z,z+x) \leq 2 \},}](https://s0.wp.com/latex.php?latex=%7BR+%2B+R+%5Csubset+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5B0%2C2%5D%5E3%3A+%5Cmin%28x%2By%2Cy%2Bz%2Cz%2Bx%29+%5Cleq+2+%5C%7D%2C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
when
;
when
;
when
;
when
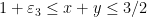

104 comments
Comments feed for this article
17 January, 2014 at 3:54 pm
Eytan Paldi
In problem 1, should be in
should be in 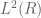 with positive norm, and in the definition of
with positive norm, and in the definition of  the maximum should be
the maximum should be 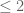 .
.
[Corrected, thanks – although the constraint![R+R \subset [0,2]^3](https://s0.wp.com/latex.php?latex=R%2BR+%5Csubset+%5B0%2C2%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) actually already forces
actually already forces ![R \subset [0,1]^3](https://s0.wp.com/latex.php?latex=R+%5Csubset+%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) . -T.]
. -T.]
17 January, 2014 at 4:27 pm
Eytan Paldi
The maximum (in the def. of ) should be corrected to
) should be corrected to 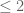 (instead of
(instead of 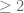 ).
).
And three closing parentheses are missing.
[Corrected, although I don’t see where the three missing closing parentheses are. -T.]
17 January, 2014 at 5:50 pm
Eytan Paldi
I’m sorry (no need for closing parentheses.)
17 January, 2014 at 4:45 pm
Eytan Paldi
It seems that condition (4) in the previous thread is that the minimum is .
.
[Corrected – T.]
17 January, 2014 at 4:02 pm
Anonymous
Just before “1. Analysis of the symmetric polytope”: 272 –> 270.
[Corrected, thanks -T.]
17 January, 2014 at 4:06 pm
Anonymous
The very last word: “numericss” –> “numerics”
[Corrected, thanks -T.]
17 January, 2014 at 6:22 pm
Eytan Paldi
It seems that in the eigenfunction equation above,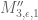 should be on the RHS.
should be on the RHS.
[Corrected, thanks – T.]
18 January, 2014 at 9:23 am
Eytan Paldi
It seems that the LHS should be without the factor 3.
[Corrected, thanks – T.]
17 January, 2014 at 6:38 pm
Aubrey de Grey
Two quick questions relating to loose ends from the previous thread:
1) Can I just clarify: is it still believed that H_1 could be reduced from 8 to 6 on GEH if M”_4 could be pushed to a point that allows “n,n+8 both prime” to be excluded (estimated as 2.35), or is there now a variant of the argument for k=3, H_1=4 which precludes that? I ask only because this avenue for progress is strangely unmentioned in the new post.
2) While the focus remains on k=3 it seems worthwhile to maintain some awareness of the potential for ideas currently in play to translate to the unconditional setting as and when attention returns to it. In particular, the original mention of converting F(x,y,z) to G(x,y) noted the computational efficiency advantage, so it would be valuable to understand whether a corresponding conversion can be performed for larger k. If it can, does it also preserve the ability to avoid partitioning (at the cost of looking at a reduced range of possible F’s) that was mentioned in the thread before last?
17 January, 2014 at 8:19 pm
Terence Tao
I don’t see any strong barrier to the k=4 approach to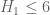 , except for the purely numerical one that we would have to make a much larger improvement in the M_4 statistic to reach this than we would for the M_3 statistic. (Note that 2.35 is only a heuristic computation; in practice, we would probably have to be more efficient still than this.)
, except for the purely numerical one that we would have to make a much larger improvement in the M_4 statistic to reach this than we would for the M_3 statistic. (Note that 2.35 is only a heuristic computation; in practice, we would probably have to be more efficient still than this.)
I’m hoping that by playing around with enough variants of the k=3 problem, we will naturally discover efficient ways to do slightly higher values of k (4 or 5, for instance), and can maybe start extrapolating how much gain one could get from various tricks in higher k. I suspect though that most of these gains decay rather fast in k, though if we become better at optimising on the truncated simplex, then we could finally use some of the Polymath8a results, which so far have only been used for m >= 2.
18 January, 2014 at 7:54 am
Pace Nielsen
Aubrey, as you pointed out in the previous thread, I was being more than a little optimistic that we could reach 2.35. It’s still worthwhile to see what happens (if we can’t make the k=3 case work), but now that I’ve thought about it a bit more, getting to 2.35 seems like a long shot.
18 January, 2014 at 2:38 am
Eytan Paldi
Three lines above (1), the LHS should be multiplied by 3.
[Corrected, thanks – T.]
18 January, 2014 at 4:00 am
Eytan Paldi
The exact expression of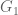 is (at least) useful by providing more detailed information on the possible locations (and types) of its singularities in
is (at least) useful by providing more detailed information on the possible locations (and types) of its singularities in  (assuming certain regularity properties of
(assuming certain regularity properties of  in
in 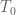 ).
).
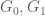 may be approximated by piecewise polynomials (using polygonal partition adapted to the above information on the possible locations of singularities).
may be approximated by piecewise polynomials (using polygonal partition adapted to the above information on the possible locations of singularities).
18 January, 2014 at 8:39 am
Anonymous
I cannot see the last part of the inequality just above (1); maybe “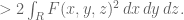 ” should be put on a new line.
” should be put on a new line.
[Corrected, thanks – T.]
18 January, 2014 at 10:09 am
Aubrey de Grey
I’ve been reviewing Pace’s data from the past week to see whether there is any anomalous pattern.
First, Pace: I’m uncertain which polytope you were using for the data you reported in https://terrytao.wordpress.com/2014/01/08/polymath8b-v-stretching-the-sieve-support-further/#comment-264511 and https://terrytao.wordpress.com/2014/01/08/polymath8b-v-stretching-the-sieve-support-further/#comment-264615. In each case, was it R’, the prism or the symmetric half-cube? Your description in 264511 looks like the prism, but you referred to it as M’ and then in 264615 as “the symmetric case” so I wanted to check. In particular, it would be good to clarify whether the symmetric half-cube behaves like R’ in gaining 2/3 as much from using epsilon,epsilon,0 as from using eps,eps,eps.
My main focus is the fact (already pointed out, of course) that the best M value we have for the symmetric half-cube (using three equal epsilons) is only 0.007 greater than for R’ (1.9596 versus 1.9527). This is an order of magnitude less than the difference of 0.06 without epsilons (1.9026 versus 1.8429). I think this suggests that the putative inefficiency of partitioning in the presence of epsilons is hurting much more in the non-R’ polytopes within the symmetric half-cube than it is within R’. Is that a reasonable interpretation? If so, then maybe one idea would be to do Terry’s variable-degree trick in reverse, i.e. to look at high degree for a subset of the non-R’ polytopes (just the A’s, or just the B’s, etc) rather than for R’ itself. Worth a try?
18 January, 2014 at 1:55 pm
Pace Nielsen
The polytope was the one exactly described in comment 264511. It is the prism with cut-offs when and
and 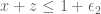 .
.
I’m not sure when I’ll have time to get back to these computations. One of my coauthors sent me a draft of our paper, and I’ll be focused on that for the next few days. If you want to give your variable-degree idea a try, you are welcome to the code. Just email me on Tuesday and I’ll send the mathematica notebook to you.
18 January, 2014 at 8:12 pm
Aubrey de Grey
Many thanks Pace – OK, so it’s definitely R’ with two equal epsilons added, so we don’t yet have data on the symmetric half-cube with two equal epsilons added. Please do send me the code (aubrey@sens.org) – thanks! – though I too am overstretched and don’t promise to have the time, especially since I am an extreme Mathematica novice.
19 January, 2014 at 10:47 am
Aubrey de Grey
OK, a very brief fiddle with Pace’s code (on the prism, which is the code he had to hand at home) makes this idea look unpromising – increasing the degree to 6 for just one category of component polytopes does not raise M” by more than 0.001 in any case. (I may have done it wrongly, however, because sometimes M” actually fell and because I received some alerts about the matrix inversion being “badly conditioned”.) If this is correct and applies also to the symmetric half-cube, perhaps the takeaway is that the partitioning is just losing a lot in all cases examined so far – which concords with Terry’s suggestion that there are loads of singularities in G_0. As a first data point I checked the prism with epsilon set to 0.25 and found that M” falls by only about 0.017 relative to that for the optimal epsilon of 0.157 found earlier by Pace, so it indeed seems useful to explore the “warmup” option Terry mentioned above (in which, if I understand Terry’s earlier comment about the likely locations of singularities, T_0 will need only a not-very-scary four partitions).
19 January, 2014 at 12:45 pm
Eytan Paldi
A more efficient and numerically stable evaluation of any M-value is to represent it as the largest eigenvalue of a linear matrix pencil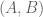 ( see the application section in the wikipedia article on matrix pencil) for which there is an efficient and numerically stable algorithm (without matrix inversion!)
( see the application section in the wikipedia article on matrix pencil) for which there is an efficient and numerically stable algorithm (without matrix inversion!)
20 January, 2014 at 8:03 am
Aubrey de Grey
Interesting! When Pace was working on k=54 or so he mentioned that the inversion step was causing RAM issues, so this could be a valuable new tool. (Then again, he did note at the same time that there were also RAM issues when finding the largest eigenvector of similarly sized matrices, so maybe he’s already doing this when needed.)
20 January, 2014 at 8:51 am
Eytan Paldi
This can be implemented in mathematica, see e.g.
http://reference.wolfram.com/legacy/applications/anm/GeneralizedEigenvalueProblem/9.1.html
20 January, 2014 at 10:41 am
Aubrey de Grey
I’ve now received Pace’s code for the symmetric half-cube and also (thanks to a suggestion from him) eliminated the alerts I mentioned. As with the prism, it turns out that the benefits to M” from increasing the degree for just one category of partition is much less for any of the non-R’ categories than it is for R’ itself (but it is always positive, so I’m pretty sure I did it correctly this time). A new partitioning that respects singularities seems, therefore, to be an absolute requirement for meaningful further progress.
18 January, 2014 at 2:02 pm
Eytan Paldi
Since the explicit (somewhat messy) expression for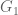 depends linearly on
depends linearly on  , another possible approach is to use a basis of symmetrical polynomials to approximate
, another possible approach is to use a basis of symmetrical polynomials to approximate  on
on  with a corresponding basis of functions (derived by the above explicit expression) for
with a corresponding basis of functions (derived by the above explicit expression) for  on
on  . If the basis of functions for
. If the basis of functions for 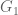 is not “too complicated”, the needed two dimensional integrals representing the elements of the matrices for the unconstrained optimization program may be computed sufficiently accurately.
is not “too complicated”, the needed two dimensional integrals representing the elements of the matrices for the unconstrained optimization program may be computed sufficiently accurately.
19 January, 2014 at 9:10 am
Eytan Paldi
In the representation of the vanishing marginal condition using (1), the integrand should be inside parentheses.
[Edited, thanks – T.]
19 January, 2014 at 2:44 pm
Aubrey de Grey
On another topic: just before Christmas (https://terrytao.wordpress.com/2013/12/20/polymath8b-iv-enlarging-the-sieve-support-more-efficient-numerics-and-explicit-asymptotics/#comment-258871) Terry improved the asymptotic bounds on H_m in the setting of the MPZ estimates, but I don’t think there was any mention that this was taken through into a modification of the Maple code that xfxie was using to identify minimal k’s. Is any such modification needed? If so, and if it wasn’t done yet, maybe it would give xfxie and Drew something to do while the focus is on k=3 :-)
19 January, 2014 at 2:51 pm
Polymath 9 | Euclidean Ramsey Theory
[…] is a post discussing this. Meanwhile Polymath 8 has spawned a new project Polymath 8b. https://terrytao.wordpress.com/2014/01/17/polymath8b-vi-a-low-dimensional-variational-problem/ is the latest post of this […]
20 January, 2014 at 1:37 am
Eytan Paldi
In the simple expression for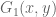 (six lines above (2)), the RHS should be with a minus sign.
(six lines above (2)), the RHS should be with a minus sign.
[Corrected, thanks – T.]
20 January, 2014 at 11:12 am
Eytan Paldi
The exact value of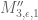 for
for 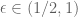 :
:
In this (simplest) case, the set is empty and therefore
is empty and therefore 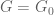 is supported on
is supported on 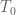 . Since in this case
. Since in this case 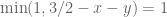 , it follows (assuming the existence of an optimal
, it follows (assuming the existence of an optimal  ) from the eigenvalue equation and the representation (1) that
) from the eigenvalue equation and the representation (1) that
where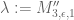 and
and
is a constant supported on![[0, 1 - \epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C+1+-+%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) . We may normalize it as
. We may normalize it as
Remark: This expression seems to hold in the limiting case (since in this case the set
(since in this case the set  still has zero area measure).
still has zero area measure).
20 January, 2014 at 12:10 pm
Aubrey de Grey
Splendid! If this is confirmed, it would be positively cruel if an epsilon slightly less than 1/2 were not a win…
20 January, 2014 at 12:18 pm
Terence Tao
Unfortunately I think the integral![\int_0^{1-\varepsilon} [H(x)+H(z)]\ dz](https://s0.wp.com/latex.php?latex=%5Cint_0%5E%7B1-%5Cvarepsilon%7D+%5BH%28x%29%2BH%28z%29%5D%5C+dz&bg=ffffff&fg=545454&s=0&c=20201002) should in fact be
should in fact be ![\int_0^{1-\varepsilon-x} [H(x)+H(z)]\ dz](https://s0.wp.com/latex.php?latex=%5Cint_0%5E%7B1-%5Cvarepsilon-x%7D+%5BH%28x%29%2BH%28z%29%5D%5C+dz&bg=ffffff&fg=545454&s=0&c=20201002) , as G(x,z) is supported on the region
, as G(x,z) is supported on the region 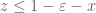 . This equation should still be exactly solvable for H, and hence for G and F (by an analysis similar to that providing the exact solution for M_2, or for solving for G_1 in terms of G_0) but it is going to lead to a messier answer than
. This equation should still be exactly solvable for H, and hence for G and F (by an analysis similar to that providing the exact solution for M_2, or for solving for G_1 in terms of G_0) but it is going to lead to a messier answer than 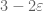 , I’m afraid.
, I’m afraid.
20 January, 2014 at 12:53 pm
Eytan Paldi
I see the problem: The first formula expressing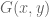 in terms of
in terms of  is known to hold for
is known to hold for 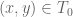 (but not necessarily on
(but not necessarily on ![[0, 1-\epsilon]^2](https://s0.wp.com/latex.php?latex=%5B0%2C+1-%5Cepsilon%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) ).
).
20 January, 2014 at 1:41 pm
Eytan Paldi
Yes. I almost have the solution (H satisfies a very simple second order equation!)
20 January, 2014 at 9:02 pm
Eytan Paldi
The corrected derivation of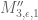 is
is
1. The corrected equation for follows by integrating the representation (on
follows by integrating the representation (on 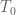 ) of
) of  with respect to
with respect to  over
over ![[0, 1-\epsilon -x]](https://s0.wp.com/latex.php?latex=%5B0%2C+1-%5Cepsilon+-x%5D&bg=ffffff&fg=545454&s=0&c=20201002) (for which the representation holds!). This gives
(for which the representation holds!). This gives
(*)
This is the corrected equation for on
on ![[0, 1-\epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C+1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
2. Assuming to be sufficiently smooth, we have
to be sufficiently smooth, we have
(1)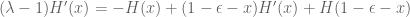
By reflection ( instead of
instead of  ) we have
) we have
(1′)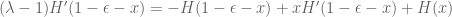
Now we use (1) to express
(2)
So by taking derivatives
(2′)
Substitution of (2) and (2′) in (1′) gives
Implying that the logarithmic derivative of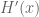 is
is
Giving (the normalized)
(3)![H'(x) = 1/[(x+1-\lambda)(x+\lambda +\epsilon -2)^2]](https://s0.wp.com/latex.php?latex=H%27%28x%29+%3D+1%2F%5B%28x%2B1-%5Clambda%29%28x%2B%5Clambda+%2B%5Cepsilon+-2%29%5E2%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Which gives
(4)![H(x) = K^{-2}[\log |\frac{x-a}{x+b}| + \frac{K}{x+b}] + C](https://s0.wp.com/latex.php?latex=H%28x%29+%3D+K%5E%7B-2%7D%5B%5Clog+%7C%5Cfrac%7Bx-a%7D%7Bx%2Bb%7D%7C+%2B+%5Cfrac%7BK%7D%7Bx%2Bb%7D%5D+%2B+C&bg=ffffff&fg=545454&s=0&c=20201002)
Where and
and  is an integration constant (to be determined with
is an integration constant (to be determined with  ).
).
3. In order to determine and
and  we need two boundary conditions. First, observe that (*) implies
we need two boundary conditions. First, observe that (*) implies
(i)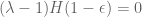
Assuming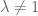 , we have
, we have
(i)’ , implying
, implying
In order to determine , we need another boundary condition.
, we need another boundary condition.
By (2) and (i)’ we have
Therefore by (3)
(ii)’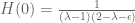
Using this in (4), we see that satisfies
satisfies
(5)
Therefore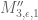 should be the largest positive root of (5).
should be the largest positive root of (5).
Remark:
Note that since the argument of the logarithm in the above expression for should be nonzero and finite, this is equivalent that
should be nonzero and finite, this is equivalent that 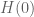 should not vanish. In particular, the assumption
should not vanish. In particular, the assumption 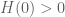 implies the simple inequality
implies the simple inequality
20 January, 2014 at 9:22 pm
Terence Tao
Thanks for this! One could use this exact solution to benchmark the convergence of the numerics (with or without partitioning, using G instead of F, etc.); even in this simple regime in which many of the polytopes have disappeared, it appears that G still has a jump discontinuity at
in which many of the polytopes have disappeared, it appears that G still has a jump discontinuity at 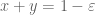 , leading to corresponding discontinuities for F which require some partitioning in order to be able to efficiently work around. (Conversely, one can use the numerics to confirm the correctness of the exact solution.)
, leading to corresponding discontinuities for F which require some partitioning in order to be able to efficiently work around. (Conversely, one can use the numerics to confirm the correctness of the exact solution.)
It also occurs to me that if we work in the two-dimensional G formulation rather than the three-dimensional F formulation, then we can make plots of G that will help strengthen our intuition as to how the singularities are distributed.
20 January, 2014 at 10:05 pm
Pace Nielsen
I think there is something wrong here. Graphically, the largest positive root of (5), in the range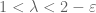 , appears to always be
, appears to always be  . Taking
. Taking  , we are then getting
, we are then getting  (and in that special case, this is indeed the largest root). But numerically I'm getting
(and in that special case, this is indeed the largest root). But numerically I'm getting  . Hopefully I'm not missing something simple.
. Hopefully I'm not missing something simple.
20 January, 2014 at 11:10 pm
Eytan Paldi
Interestingly, it is easy to verify that the root is exactly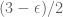 .
.
(In fact all the three terms are zero!) I’ll check again the derivation.
20 January, 2014 at 11:37 pm
Eytan Paldi
For this it follows that
it follows that  vanish identically! (i.e. it is the trivial solution!). If the derivation is correct than something must be wrong with the assumptions (e.g. existence of a smooth optimal solution.)
vanish identically! (i.e. it is the trivial solution!). If the derivation is correct than something must be wrong with the assumptions (e.g. existence of a smooth optimal solution.)
21 January, 2014 at 7:55 am
Eytan Paldi
You are right! In fact, I just found an easy proof that
This connection to the constant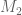 is very interesting!
is very interesting!
Concerning your example, using , we get
, we get
I’ll send the details in my next message.
21 January, 2014 at 8:46 am
Aubrey de Grey
Great work Eytan! Even though 1.69 is a long way from 2, I’m wondering whether this finding could help to indicate which half-cube is really the best. Pace: do you numerically get this same value for both the prism and the symmetric half-cube? (I’m presuming that I can’t check this myself with the code you sent me because a different partitioning is needed for epsilon that large.) If the prism leads to a smaller M” for epsilon=1/2, I think that would constitute a significant strengthening of the evidence that there is no need to consider any half-cube other than the symmetric one from now on.
21 January, 2014 at 11:53 am
Eytan Paldi
Derivation of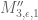 for
for 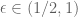
Observe that is supported on
is supported on  .
.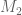 variational problem. Recall (for comparison purpose) that
variational problem. Recall (for comparison purpose) that
Therefore it seems reasonable that there is some (scaling) connection to the
1. In the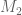 problem, the eigenvalue equation was
problem, the eigenvalue equation was
(1)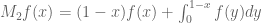 ,
, ![x \in [0, 1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=545454&s=0&c=20201002)
with the solution
(2)
2. For the current problem, the eigenvalue equation is (see previous comment)
(*)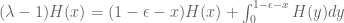
where is now supported on
is now supported on ![[0, 1-\epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C+1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
Let be a solution of (*), than (by a change of variables) we have the equivalent form (with
be a solution of (*), than (by a change of variables) we have the equivalent form (with 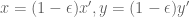 )
)
(*)’![(\lambda -1)\phi(x') = (1-\epsilon)[(1-x')\phi(x')+\int_0^{1-x'} \phi(y')d y']](https://s0.wp.com/latex.php?latex=%28%5Clambda+-1%29%5Cphi%28x%27%29+%3D+%281-%5Cepsilon%29%5B%281-x%27%29%5Cphi%28x%27%29%2B%5Cint_0%5E%7B1-x%27%7D+%5Cphi%28y%27%29d+y%27%5D&bg=ffffff&fg=545454&s=0&c=20201002)
where is supported on
is supported on ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=545454&s=0&c=20201002) .
.
By comparing (*)’ to (1), it follows that
(3)
Remark: From this comparison, it follows that the solution to (*) is given by
to (*) is given by
(4)![H(x) = f(x/(1-\epsilon)) , x \in [0, 1-\epsilon]](https://s0.wp.com/latex.php?latex=H%28x%29+%3D+f%28x%2F%281-%5Cepsilon%29%29+%2C+x+%5Cin+%5B0%2C+1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002)
where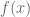 is given by (2).
is given by (2).
20 January, 2014 at 3:47 pm
Eytan Paldi
I found to be an explicit fourth degree polynomial on
to be an explicit fourth degree polynomial on ![[0, 1 - \epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C+1+-+%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) and
and 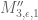 was found to be the largest positive root of an explicit fourth order polynomial. I’ll give the details in my next comment.
was found to be the largest positive root of an explicit fourth order polynomial. I’ll give the details in my next comment.
20 January, 2014 at 9:15 pm
Eytan Paldi
This (wrong) result was corrected in a later comment (the error originated in a wrong sign of the logarithmic derivative of H’ – affecting the later derivation.)
20 January, 2014 at 7:21 pm
arch1
Is it possible to turn Problem 1 into an optimization problem on a region of some finite-dimensional space, then turn a computer loose on it using a stochastic optimization algorithm or some other global optimization heuristic?
20 January, 2014 at 8:54 pm
Pace Nielsen
I took a little break from my other work, and decided to give the extra partitioning a try numerically. So I broke the simplex![\{(x,y,z)\in [0,1]^3\ :\ x+y,y+z,z+x\leq 1+\varepsilon;\ x+y+z\leq 3/2\}](https://s0.wp.com/latex.php?latex=%5C%7B%28x%2Cy%2Cz%29%5Cin+%5B0%2C1%5D%5E3%5C+%3A%5C+x%2By%2Cy%2Bz%2Cz%2Bx%5Cleq+1%2B%5Cvarepsilon%3B%5C+x%2By%2Bz%5Cleq+3%2F2%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002) into a finer decomposition than I had used previously. Namely, I used the the following pieces (intersected with the region above)
into a finer decomposition than I had used previously. Namely, I used the the following pieces (intersected with the region above) 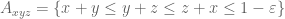
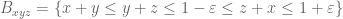
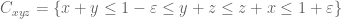
 and their counterparts from permuting x,y,z. I assumed an arbitrary polynomial approximation on each piece, with the obvious symmetries from permuting the variables, and I also assumed that the D-components were irrelevant. [I realize that further restrictions could be made on the other components, but that doesn’t appear necessary.]
and their counterparts from permuting x,y,z. I assumed an arbitrary polynomial approximation on each piece, with the obvious symmetries from permuting the variables, and I also assumed that the D-components were irrelevant. [I realize that further restrictions could be made on the other components, but that doesn’t appear necessary.]
It looks like is quite stable as the optimal choice, and for polynomials of degrees 1-5 we get
is quite stable as the optimal choice, and for polynomials of degrees 1-5 we get 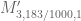 is bounded below by 1.955982…,1.956463…, 1.956638…, 1.956695…, 1.956713…
is bounded below by 1.955982…,1.956463…, 1.956638…, 1.956695…, 1.956713…
Because of the nice convergence of these values, I think that the simplex has been sufficiently decomposed. Unfortunately, the numbers make me doubt that the M” computation will give much better numerics.
20 January, 2014 at 9:10 pm
Terence Tao
Hmm, that’s only a modest improvement over our previous value of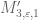 (which was 1.9527), but (a) every little bit helps, I think; (b) it is proof of concept that there was some singularity issue that was helped by improved partitioning; and (c) all the slow convergence issues are coming from the M” problems rather than the M’ problems, suggesting that the singularity problems there are more severe there, and hopefully there is a more serious gain (though we need a tenfold increase in gain over the gain observed here to win, which is a little daunting…). So it’s not yet hopeless (and maybe there’s one last trick to be had in manipulating the Selberg sieve further, though I’m currently out of ideas on that front).
(which was 1.9527), but (a) every little bit helps, I think; (b) it is proof of concept that there was some singularity issue that was helped by improved partitioning; and (c) all the slow convergence issues are coming from the M” problems rather than the M’ problems, suggesting that the singularity problems there are more severe there, and hopefully there is a more serious gain (though we need a tenfold increase in gain over the gain observed here to win, which is a little daunting…). So it’s not yet hopeless (and maybe there’s one last trick to be had in manipulating the Selberg sieve further, though I’m currently out of ideas on that front).
22 January, 2014 at 9:44 am
Pace Nielsen
Motivated by Terry’s optimism,I worked out a similar decomposition as above, over the entire symmetric half-cube. Again I only got modest improvements. The optimal epsilon appears to be around 174/1000, and using that value we get the following lower bounds for . As the degree goes from 1 to 4 we have 1.960128, 1.960845, 1.962407, 1.962998.
. As the degree goes from 1 to 4 we have 1.960128, 1.960845, 1.962407, 1.962998.
When I tried to use additional information about the structure of an optimal solution to speed up the computation, the marginal conditions forced all approximations to be zero (assuming I implemented everything correctly). So it is possible that the marginal conditions are holding the computation back, and don’t work well with polynomial approximation.
22 January, 2014 at 11:52 am
Terence Tao
Well, it’s another 10% or so shaved off of the distance to 2, which is something at least (still feels like Zeno’s paradox, though)… but it does look like we are not using the full power of the extra regions where the vanishing conditions are in effect, so that gives some hope.
In principle, we don’t have to deal with the vanishing marginals at all, because of the explicit formulae for everything in the extra polytopes given in the blog post above. These are rather messy though, and the probability of an error (either in my calculations, or in a numerical implementation of these calculations) is high, also one has to do some numerical integration of some non-polynomial functions (involving some logarithms). So we can hope to just blast through with polynomials, perhaps working in the G(x,y) formulation where we might be able to use graphs of G to suggest more efficient bases to use.
How high of a degree do you think you can feasibly compute? We talked earlier about staggering the degree so that R” gets a lot more degree than the other polytopes; one could also arrange matters so that polytopes that have to face two marginal conditions have lower degree than those that face just one marginal condition.
23 January, 2014 at 10:34 am
Pace Nielsen
It took about 10 hours to compute with degree 6, and the ram requirement was getting large. So probably only another degree or two would be possible.
I tried playing around with limiting some of the degrees, but that didn’t give good numerics (which it shouldn’t since we expect the G0 and G1 components of G to interact).
Since the new polytope you gave is so close to the symmetric half-cube, I should be able to get the computations out of that later today (hopefully).
22 January, 2014 at 5:58 pm
Eytan Paldi
A possible reason to the enforcement of the approximations to zero on the polytopes for which the marginal constraints apply, is that the number of marginal constraints is larger than the number of degrees of freedom in these approximations (which may happen if the approximating polynomials degrees are “too low”) – leaving no remaining degrees of freedom for improvement.
23 January, 2014 at 5:12 am
Terence Tao
I just realised that there is a bit more flexibility to the region R that the function F needs to be supported on. Namely, it is not actually necessary that R is convex (this is not used anywhere in the Selberg sieve computations), so long as it obeys the inclusion
as stated in the blog post. After playing around with some non-convex examples, I think that in addition to the prism and the symmetric polytope we’ve been playing with, another potentially good choice for R would be the non-convex region
which obeys (1) (basically because of the pigeonhole principle). Like our other candidates, R has exactly half of the volume of the cube [0,1]^3 (it and its reflection around (1/2,1/2,1/2) cover the cube). The advantage of this R is that each region only deals with at most one vanishing marginal condition, so numerically we shouldn’t be taking as big a hit with the linear constraints on these polytopes. I also suspect that when we reduce to the G-function, the equations are simpler than they are for![\{(x,y,z) \in [0,1]^3: x+y+z \leq 3/2 \}](https://s0.wp.com/latex.php?latex=%5C%7B%28x%2Cy%2Cz%29+%5Cin+%5B0%2C1%5D%5E3%3A+x%2By%2Bz+%5Cleq+3%2F2+%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002) as computed in the main blog post, although I haven’t done this yet.
as computed in the main blog post, although I haven’t done this yet.
23 January, 2014 at 11:31 am
arch1
It seems the 1st component of the union is a pyramid whose altitude is the unit segment [0,1] on the x axis and whose base is the unit square [0,1]x[0,1] in the y-z plane. And analogously for the other two components. Is that right?
23 January, 2014 at 11:57 am
Terence Tao
Yes, that is how a single piece of R looks. The full non-convex polytope R is a bit strange-looking, though. Here’s how it looks from a “top down” view. The unit square can be divided into four right-angled isosceles triangles,
can be divided into four right-angled isosceles triangles,  ,
,  ,
, 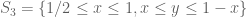 , and
, and  . For (x,y) in the two opposing triangles S_1, S_3, z can range from 0 to 1-x; but for (x,y) in the other two triangles S_2, S_4, z can range from 0 to 1-y.
. For (x,y) in the two opposing triangles S_1, S_3, z can range from 0 to 1-x; but for (x,y) in the other two triangles S_2, S_4, z can range from 0 to 1-y.
The calculus of variations analysis as in the main blog post gives us an ansatz
on R, where is supported on the union of the triangles
is supported on the union of the triangles ![T_0= \{ (x,y) \in [0,1]^2: x+y \leq 1-\varepsilon \} \subset S_1 \cup S_4](https://s0.wp.com/latex.php?latex=T_0%3D+%5C%7B+%28x%2Cy%29+%5Cin+%5B0%2C1%5D%5E2%3A+x%2By+%5Cleq+1-%5Cvarepsilon+%5C%7D+%5Csubset+S_1+%5Ccup+S_4&bg=ffffff&fg=545454&s=0&c=20201002) and
and ![T_1 = \{ (x,y)\in [0,1]^2: x+y \geq 1+\varepsilon \} \subset S_2 \cup S_3](https://s0.wp.com/latex.php?latex=T_1+%3D+%5C%7B+%28x%2Cy%29%5Cin+%5B0%2C1%5D%5E2%3A+x%2By+%5Cgeq+1%2B%5Cvarepsilon+%5C%7D+%5Csubset+S_2+%5Ccup+S_3&bg=ffffff&fg=545454&s=0&c=20201002) . Letting G_0 and G_1 be the portions of G on these triangles, the vanishing moment conditions become
. Letting G_0 and G_1 be the portions of G on these triangles, the vanishing moment conditions become
on T_1, so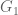 can be exactly solved in terms of
can be exactly solved in terms of  by a formula somewhat simpler than in the symmetric polytope case (no logarithms!) In particular, one could set G_0 to be a piecewise polynomial and G_1 would be piecewise rational, so the integrals on R should still be reasonably computable.
by a formula somewhat simpler than in the symmetric polytope case (no logarithms!) In particular, one could set G_0 to be a piecewise polynomial and G_1 would be piecewise rational, so the integrals on R should still be reasonably computable.
23 January, 2014 at 1:12 pm
Eytan Paldi
How this is defined (in terms of
is defined (in terms of  )?
)?
23 January, 2014 at 2:31 pm
Terence Tao
We have for
for 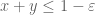 .
.
23 January, 2014 at 3:02 pm
Pace Nielsen
Here is data on this new non-convex simplex. The best epsilon is near 147/1000. Using this epsilon and incrementing degrees from 1 to 4, we get the following bounds on : 1.9359, 1.9386, 1.9397, 1.9400.
: 1.9359, 1.9386, 1.9397, 1.9400.
To compare this simplex with the other two, the lower bound for M” using degree 4 polynomials is 1.847. This seems so low as compared with the other two simplexes that I doubled checked my work, but did not find any mistakes. I’m pretty sure that the decomposition I used is valid for any![\varepsilon\in [0,1/5]](https://s0.wp.com/latex.php?latex=%5Cvarepsilon%5Cin+%5B0%2C1%2F5%5D&bg=ffffff&fg=545454&s=0&c=20201002) . If someone wants to double-check my formulas, just go to: http://www.math.byu.edu/~pace/BddGaps.pdf
. If someone wants to double-check my formulas, just go to: http://www.math.byu.edu/~pace/BddGaps.pdf
23 January, 2014 at 3:15 pm
Terence Tao
That’s slightly odd, because the data you’re reporting for is worse than the data
is worse than the data  you got, admittedly for degree 5 and for partitioning the simplex (but it is also worse than the earlier value of 1.9527 you got with degree 11 and no partitioning). (The values of epsilon are a bit different though.) I’ll take a look at your formulae to see if anything jumps out at me.
you got, admittedly for degree 5 and for partitioning the simplex (but it is also worse than the earlier value of 1.9527 you got with degree 11 and no partitioning). (The values of epsilon are a bit different though.) I’ll take a look at your formulae to see if anything jumps out at me.
23 January, 2014 at 3:34 pm
Terence Tao
OK, my guess for what is going on is that the E,G,H polytopes are not being optimally partitioned; a single G polytope, for instance, is being forced to obey four different vanishing marginal conditions (M1=0, M2=0, M3=0, M4=0) which at low degree will really cut down on the possible options for what one can place on G. If one sliced G up into four pieces, they would each obey a separate vanishing marginal condition and one would have a lot more degrees of freedom, and similarly for E and H. (One nice thing about the non-convex polytope here is that each region faces at most one vanishing marginal condition, so we don’t end up in a nightmarish infinite regress in which every decomposition we use to try to fix up one marginal condition necessitates a further decomposition for another marginal condition.)
23 January, 2014 at 3:37 pm
Pace Nielsen
I’ll make that change! Good spotting.
23 January, 2014 at 7:22 pm
Pace Nielsen
I started making the changes to the decomposition, but by decomposing those pieces as wanted we end up with around 20 regions in the (x,y)-plane to integrate over to compute J. This is just getting a bit too complicated. I think I’ll hold off working this all out to give people some time to think about the (perhaps easier) 2-dimensional version of the problem.
By the way, I understand that the epsilon expansion trick doesn’t give us an asymptotic in the numerator (i.e.J-integrals). Are we losing much information here? We only need a smidgen more.
23 January, 2014 at 8:39 pm
Terence Tao
Maybe the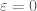 case could be worked out without too much difficulty to see how much we’re losing on the
case could be worked out without too much difficulty to see how much we’re losing on the  computation? Here we only have the A and E polytopes (but then I guess we only have the M_2 moment condition, and so there is no point in partitioning further?).
computation? Here we only have the A and E polytopes (but then I guess we only have the M_2 moment condition, and so there is no point in partitioning further?).
We can also work out the formulae for M”_3 in the G(x,y) formulation, it looks like a good test bed to compare the two approaches. As mentioned before, we use the ansatz
on R, where ,
,  is supported on the triangle
is supported on the triangle 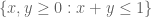 , and
, and 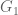 is supported on the triangle
is supported on the triangle 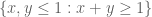 and is given in terms of
and is given in terms of  by the formula
by the formula
coming from the vanishing marginal condition. (I had a slight typo in my previous formula for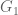 , now corrected.) The I(F) integral is
, now corrected.) The I(F) integral is
and the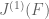 integral is
integral is
These are messy, but they are all quadratic forms in on the triangle
on the triangle  which could presumably be computed in terms of a polynomial basis on this triangle (there may be some slight singularity at
which could presumably be computed in terms of a polynomial basis on this triangle (there may be some slight singularity at 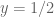 and
and  , but we might be able to get good results without further partitioning here).
, but we might be able to get good results without further partitioning here).
23 January, 2014 at 9:09 pm
Terence Tao
A small observation: if is polynomial, then
is polynomial, then 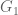 is also polynomial for
is also polynomial for  (or for
(or for 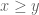 ); I had thought it was merely a rational function, but
); I had thought it was merely a rational function, but  is polynomial in x and y when P is a polynomial. This makes all the coefficients in the relevant quadratic form rational numbers, so we can work exactly without having to do any numerical integration.
is polynomial in x and y when P is a polynomial. This makes all the coefficients in the relevant quadratic form rational numbers, so we can work exactly without having to do any numerical integration.
23 January, 2014 at 9:16 pm
Terence Tao
Regarding the possibility of squeezing more gain out of the numerator – this is a great question, and I have been trying on and off for several weeks now to see if there is anything to get here. The key problem is that for the k=3 problem we are already well beyond the reach of unconditional methods (Bombieri-Vinogradov, Polymath8a, etc.) and so we have to cling to the GEH hypothesis as the only tool available for estimating all the sieve-theoretic sums that we encounter. So there’s not much else to work with, unless we cheat by adding another hypothesis even stronger than GEH and designed specifically to help us out.
Somehow the enemy is a weird cancellation in which the contributions to a divisor sum with
with 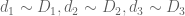 are almost canceled out by the contribution to the same sum with
are almost canceled out by the contribution to the same sum with  . (This is very vague and imprecise, I’m afraid.) This cancellation would be quite bizarre if it really happened, but I don’t see yet how to rule out this sort of thing.
. (This is very vague and imprecise, I’m afraid.) This cancellation would be quite bizarre if it really happened, but I don’t see yet how to rule out this sort of thing.
25 January, 2014 at 5:02 pm
Pace Nielsen
One thing I’ve noticed in these computations is that different simplexes have different optimal epsilons. I wonder if there is a way to vary the epsilon value as one passes from one region of the simplex to the next.
23 January, 2014 at 3:46 pm
Terence Tao
Actually, this might not be so odd after all: the computation for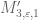 is on the polytope
is on the polytope  which is not necessarily contained in
which is not necessarily contained in  , so there is no obvious inequality between
, so there is no obvious inequality between 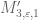 and
and  . (But there is an inequality
. (But there is an inequality  , so it was a bit odd that those two were so close together, probably because of the abovementioned problem that the marginal conditions are too restrictive right now.)
, so it was a bit odd that those two were so close together, probably because of the abovementioned problem that the marginal conditions are too restrictive right now.)
23 January, 2014 at 4:08 pm
Eytan Paldi
I suggest to remove the convexity requirement of from the formulation of problem 1, and to add this non-convex example to the two given examples.
from the formulation of problem 1, and to add this non-convex example to the two given examples.
[Done – T.]
23 January, 2014 at 4:44 pm
arch1
Thanks Terry. In case it helps others: I think you can visualize this R as the volume between a ‘floor’ [0,1]x[0,1] in the x-y plane and a ‘roof’ z(x,y). z is valley-shaped for x+y less than 1, ridge-shaped for x+y greater than 1, and discontinuous on x+y=1. The valley’s trough is half of the diagonal (0,0,1) to (1,1,0); the ridge’s ridgeline is the other half. Finally z=0 on the base of Terry’s S2 and S3, and z=1 on the base of S1 and S4.
23 January, 2014 at 4:56 pm
Pace Nielsen
For those with Mathematica, I discovered that a nice way to visualize these regions is to use the RegionPlot3D command.
25 January, 2014 at 4:50 am
Aubrey de Grey
In trying to gain a better understanding of the epsilon trick (and why it’s not working for the J-integrals) I hit a question: does the epsilon trick when theta=1 actually need divisor sums not covered by von Mangoldt? GEH was introduced in order to extend R to R’ and the various R” polytopes, but the discussion of epsilon didn’t seem to rely on similar considerations. If von Mangoldt is enough for M_k,epsilon,1 then we currently have k down to 4 on EH, with no need to resort to GEH, so this seems worth clarifying.
25 January, 2014 at 9:15 am
Terence Tao
The epsilon trick does not directly require GEH (so in particular it works in the Bombieri-Vinogradov case without any additional assumptions), but in the theta=1 case the epsilon trick does not gain anything numerically unless one is allowed to go outside the original simplex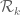 , and when theta=1 this requires GEH.
, and when theta=1 this requires GEH.
25 January, 2014 at 10:39 am
Eytan Paldi
In the wiki page on the variational problem , there is some (latex ) typo in the line above the last one.
[Corrected, thanks – T.]
26 January, 2014 at 1:10 am
Eytan Paldi
Is it possible to generalize the statement of problem 1 by making dependent on
dependent on  (and similarly for
(and similarly for  )?
)?
26 January, 2014 at 5:42 am
Pace Nielsen
That is exactly the question of my last post. Thank you for putting it more cleanly!
26 January, 2014 at 7:14 am
Eytan Paldi
My (clarifying) question was indeed stimulated by yours!
In fact, there may be further generalization in which the marginals are supported on sets and the outer integrals are over corresponding subsets
and the outer integrals are over corresponding subsets 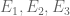 (as done in the derivation of the necessary conditions for the optimal
(as done in the derivation of the necessary conditions for the optimal  in a previous comment).
in a previous comment). ) that the sets
) that the sets  should satisfy.
should satisfy.
It would be interesting to find general sufficient conditions (as in the above conditions on
26 January, 2014 at 10:00 am
Terence Tao
Unfortunately I don’t see a way to do this with the Selberg sieve. The first sum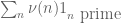 that shows up in the numerator is determined by the first marginal
that shows up in the numerator is determined by the first marginal 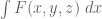 , and if this non-vanishing at some
, and if this non-vanishing at some  with
with 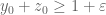 then I can’t see any way to use any of the terms with
then I can’t see any way to use any of the terms with 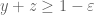 for the purposes of getting a lower bound (because I have no control on the inner product of those terms with the contribution at
for the purposes of getting a lower bound (because I have no control on the inner product of those terms with the contribution at  , and the total contribution of all these terms may well cancel itself out completely.
, and the total contribution of all these terms may well cancel itself out completely.
Perhaps more fruitful would be to vary R (viewing the variational problem as a free boundary problem). One thing about the symmetric polytope![R = \{ (x,y,z) \in [0,1]^3: x+y+z \leq 3/2\}](https://s0.wp.com/latex.php?latex=R+%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5B0%2C1%5D%5E3%3A+x%2By%2Bz+%5Cleq+3%2F2%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002) is that the sumset
is that the sumset 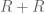 meets the constraining region $\{ (x,y,z) \in [0,2]^3: \min(x+y,y+z,z+x) \leq 2 \}$ in only one point (1,1,1); this is in contrast to the other polytopes we have tried (the prism and the non-convex polytope). Roughly speaking, this means that we can add a small piece to R somewhere as long as we delete the corresponding reflection of that piece around (1/2,1/2,1/2). So if the extremiser to the symmetric polytope problem is somehow unbalanced with respect to this reflection, one can hope to gain this way. Unfortunately effect of the process of adding and subtracting small pieces to R is a bit tricky to analyse due to all the vanishing marginal conditions. I should get around to doing a perturbative analysis of this though – it looks like a solvable problem, just a messy one.
meets the constraining region $\{ (x,y,z) \in [0,2]^3: \min(x+y,y+z,z+x) \leq 2 \}$ in only one point (1,1,1); this is in contrast to the other polytopes we have tried (the prism and the non-convex polytope). Roughly speaking, this means that we can add a small piece to R somewhere as long as we delete the corresponding reflection of that piece around (1/2,1/2,1/2). So if the extremiser to the symmetric polytope problem is somehow unbalanced with respect to this reflection, one can hope to gain this way. Unfortunately effect of the process of adding and subtracting small pieces to R is a bit tricky to analyse due to all the vanishing marginal conditions. I should get around to doing a perturbative analysis of this though – it looks like a solvable problem, just a messy one.
26 January, 2014 at 10:37 am
Aubrey de Grey
Terry: by “viewing the variational problem as a free boundary problem” do you mean that the search for an optimal F could actually “push its envelope”, so to speak? In other words, maybe one could start with an R of the current form, then find F’s that extended slightly beyond R only at some narrowly-circumscribed location, and then see whether that F allowed the reflection of that location to be deleted from R?
It would be great to have a precise description of which half-cubes are permitted by the sumset constraint, since for sure there are plenty of half-cubes that violate it. Clearly, for any point (x,y,z) that is included within a candidate R, we know the domain of other points (x’,y’,z’) that can also be included: it is simply those such that the midpoint between the two lies within the union-of-prisms (the half-sized version of the permitted R+R). But collapsing this into a general description of which R’s are permitted seems really tricky. I’m working on it :-)
26 January, 2014 at 3:22 pm
Eytan Paldi
Concerning the restriction of to
to 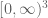 , is it really needed? (in particular, do our examples always need to have faces with
, is it really needed? (in particular, do our examples always need to have faces with  ?)
?)
27 January, 2014 at 11:44 am
Terence Tao
Well, if R doesn’t have faces at x=0,y=0,z=0, one could always replace it with the downset completion , whose sumset
, whose sumset  obeys the same containment hypotheses that
obeys the same containment hypotheses that 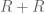 .does, so unfortunately there doesn’t seem to be any gain here. (Note also that even if F is supported on a polytope R which does not have faces at x=0,y=0,z=0, the associated sieve weights
.does, so unfortunately there doesn’t seem to be any gain here. (Note also that even if F is supported on a polytope R which does not have faces at x=0,y=0,z=0, the associated sieve weights  are essentially supported in the downset completion R’ anyway, due to the construction of the Selberg sieve (which involves a mixed antiderivative f of F, rather than F itself).
are essentially supported in the downset completion R’ anyway, due to the construction of the Selberg sieve (which involves a mixed antiderivative f of F, rather than F itself).
27 January, 2014 at 7:40 am
James Maynard
I’ve been thinking about a variation which I’m optimistic might finally get us down to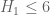 . Yesterday I was looking through some of the earlier posts about the epsilon-expansion I realized that Terry had already had essentially the same idea, but I hadn’t noticed it before!
. Yesterday I was looking through some of the earlier posts about the epsilon-expansion I realized that Terry had already had essentially the same idea, but I hadn’t noticed it before!
I’ll recap the basic idea:
Instead of considering just the sieve weights


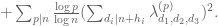
we can look at the more general weights
My original motivation for looking at this was to split the sieve weights to obtain a more flexible epsilon-expansion, but I think simply the flexibility of this more general choice might be enough.
Let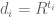 and
and  with
with 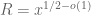 . We assume that
. We assume that  are supported on the region
are supported on the region ![\{t_1+t_2,t_1+t_3,t_2+t_3\le 1+\epsilon\}\cap [0,1]^3](https://s0.wp.com/latex.php?latex=%5C%7Bt_1%2Bt_2%2Ct_1%2Bt_3%2Ct_2%2Bt_3%5Cle+1%2B%5Cepsilon%5C%7D%5Ccap+%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) , which will enable us to evaluate the term not involving the
, which will enable us to evaluate the term not involving the  ‘s using the epsilon expansion trick. To evaluate the terms with the
‘s using the epsilon expansion trick. To evaluate the terms with the  conditions we choose
conditions we choose 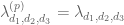 unless
unless
![(t_1,t_2,t_3,u)\in\{t_1+u+t_2,t_1+u+t_3,t_2+t_3\le 1\}\cap[0,1]^4,](https://s0.wp.com/latex.php?latex=%28t_1%2Ct_2%2Ct_3%2Cu%29%5Cin%5C%7Bt_1%2Bu%2Bt_2%2Ct_1%2Bu%2Bt_3%2Ct_2%2Bt_3%5Cle+1%5C%7D%5Ccap%5B0%2C1%5D%5E4%2C&bg=ffffff&fg=545454&s=0&c=20201002)
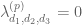 . This means that under GEH we can obtain asymptotic estimates for each of the
. This means that under GEH we can obtain asymptotic estimates for each of the  terms.
terms.
in which case we chose
Doing this, and defining in terms of
in terms of  , I find that
, I find that


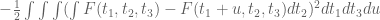

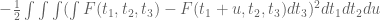

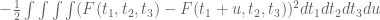
 parameter is over
parameter is over
![\{t_1+u+t_2,t_1+u+t_3,t_2+t_3\le 1\}\cap[0,1]^4.](https://s0.wp.com/latex.php?latex=%5C%7Bt_1%2Bu%2Bt_2%2Ct_1%2Bu%2Bt_3%2Ct_2%2Bt_3%5Cle+1%5C%7D%5Ccap%5B0%2C1%5D%5E4.&bg=ffffff&fg=545454&s=0&c=20201002)
 variable, I think we should expect a small win.
variable, I think we should expect a small win.
where the integration involving the
Since the optimal functions we’re looking at aren’t constant with respect to the
I’ve tried implementing this by just taking to be an arbitrary polynomial which is symmetric with respect to
to be an arbitrary polynomial which is symmetric with respect to 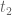 and
and  (so far just given by one polynomial on the whole region). Assuming my code is running correctly, taking
(so far just given by one polynomial on the whole region). Assuming my code is running correctly, taking  to be degree 11, I’m provisionally getting a lower bound of
to be degree 11, I’m provisionally getting a lower bound of 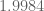 . This still should be checked, of course.
. This still should be checked, of course.
Moreover, we should expect that by splitting up on polytopes should do rather better (as per Pace’s calculations) and one might guess that degree 15 or 16 might be enough on its own.
up on polytopes should do rather better (as per Pace’s calculations) and one might guess that degree 15 or 16 might be enough on its own.
There’s also several different variations which don’t just use divisors of , or use a different
, or use a different  for the
for the  direction since the problem as stated isn’t symmetric with respect to
direction since the problem as stated isn’t symmetric with respect to  . This is also not using the extra flexibility from extended the region with vanishing marginal conditions.
. This is also not using the extra flexibility from extended the region with vanishing marginal conditions.
27 January, 2014 at 8:25 am
Pace Nielsen
James, if you just need a computer with more RAM, I’m happy to try to run your computation for bigger degrees.
27 January, 2014 at 11:41 am
Terence Tao
This is fantastic! I had previously tried to insert the twist to the sieve without the epsilon trick, and found that the eigenfunction equation for F made the original Selberg sieve a stationary point for this process, which made me pessimistic about using this to help us, but somehow the fact that the main term is estimated using the epsilon trick but the secondary terms without the epsilon trick gives a bit of extra gain, which is of course basically all we need at this point.
twist to the sieve without the epsilon trick, and found that the eigenfunction equation for F made the original Selberg sieve a stationary point for this process, which made me pessimistic about using this to help us, but somehow the fact that the main term is estimated using the epsilon trick but the secondary terms without the epsilon trick gives a bit of extra gain, which is of course basically all we need at this point.
One potential problem: to control the main I(F) term, it is not enough that F is supported on![\{ t_1+t_2,t_1+t_3,t_2+t_3 \leq 1+\varepsilon\} \cap [0,1]^3](https://s0.wp.com/latex.php?latex=%5C%7B+t_1%2Bt_2%2Ct_1%2Bt_3%2Ct_2%2Bt_3+%5Cleq+1%2B%5Cvarepsilon%5C%7D+%5Ccap+%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) ; one also has to put F in one of the polytopes R we’ve been using, e.g.
; one also has to put F in one of the polytopes R we’ve been using, e.g. ![\{ t_1+t_2+t_3 \leq 3/2 \} \cap [0,1]^3](https://s0.wp.com/latex.php?latex=%5C%7B+t_1%2Bt_2%2Bt_3+%5Cleq+3%2F2+%5C%7D+%5Ccap+%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) . (In particular, we can’t let F poke past
. (In particular, we can’t let F poke past  , as we don’t have any tools for controlling the I-integral beyond that point, even on GEH.) Hopefully this doesn’t cost us too much though. (And there is also potential to poke outside of
, as we don’t have any tools for controlling the I-integral beyond that point, even on GEH.) Hopefully this doesn’t cost us too much though. (And there is also potential to poke outside of  so long as one has vanishing marginal conditions, though we’ve seen that this only gains us a small amount in practice.)
so long as one has vanishing marginal conditions, though we’ve seen that this only gains us a small amount in practice.)
27 January, 2014 at 2:33 pm
James Maynard
I was using the restriction as well, I forgot to write this down.
as well, I forgot to write this down.
Could you explain what you mean by the eigenfunction equation for made the original optimal weights a stationary point? I think my calculations should be giving an improvement without the
made the original optimal weights a stationary point? I think my calculations should be giving an improvement without the  trick (from 1.84 to 1.87), which maybe means that I’ve made a mistake and this doesn’t really work. I see that this gives no benefit if
trick (from 1.84 to 1.87), which maybe means that I’ve made a mistake and this doesn’t really work. I see that this gives no benefit if  is constant with respect to
is constant with respect to  , but the optimal small gaps weights aren’t constant in
, but the optimal small gaps weights aren’t constant in  , so I would have guessed a win here.
, so I would have guessed a win here.
27 January, 2014 at 3:39 pm
Terence Tao
Ah, I think I isolated the problem: the term one subtracts off of J_2 is not
but rather
where is the restriction of F to the complement of
is the restriction of F to the complement of  , and F is extended by zero outside of its support. Similarly for
, and F is extended by zero outside of its support. Similarly for  .
.
Here’s the calculation (without epsilons) which seems to show that the eigenfunction for the M’_3 problem is also the extremiser for this new sieve. Suppose that is given by the eigenfunction F, and
is given by the eigenfunction F, and  is given by
is given by  where
where  is supported on
is supported on  (you chose
(you chose  to zero out
to zero out  on this region, but this is not necessarily the optimal choice). The net change to
on this region, but this is not necessarily the optimal choice). The net change to
coming from this change consists of a term linear in G_u, which I think is
where , together with a term quadratic in G_u:
, together with a term quadratic in G_u:
The quadratic term is non-positive due to the definition of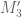 (since
(since  is non-positive, and we can throw away the J_1 contribution). As for the linear term, we use Fubini to rewrite this as an inner product of the
is non-positive, and we can throw away the J_1 contribution). As for the linear term, we use Fubini to rewrite this as an inner product of the 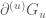 with
with 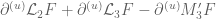 , but this vanishes on the support of
, but this vanishes on the support of 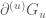 by applying
by applying  to the eigenfunction equation
to the eigenfunction equation  .
.
I think the intuition here is that the Selberg sieve associated to , when restricted by
, when restricted by  , behaves very much like the Selberg sieve associated to
, behaves very much like the Selberg sieve associated to 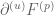 , times a normalising factor of
, times a normalising factor of 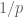 . Because the original Selberg sieve F was already optimised against perturbations of the latter type of sieve, it becomes automatically optimised against the former.
. Because the original Selberg sieve F was already optimised against perturbations of the latter type of sieve, it becomes automatically optimised against the former.
EDIT: I’m not exactly sure what is going on though when one also throws in the epsilons. There may be some flexibility gained here, but I’ll have to think about it a bit more.
27 January, 2014 at 7:17 pm
James Maynard
Argh, thanks for this – I should have checked more carefully before posting, it was silly to forget that the shifts would have a smaller support.
27 January, 2014 at 7:58 pm
Terence Tao
No problem: I myself got really excited by the trick on no less than two previous occasions, before calculating that it didn’t actually offer any gain. But maybe the fourth time will be the charm for this trick, it feels like it should somehow be useful…
trick on no less than two previous occasions, before calculating that it didn’t actually offer any gain. But maybe the fourth time will be the charm for this trick, it feels like it should somehow be useful…
27 January, 2014 at 7:49 am
James Maynard
Another comment:
In my first implementation attempt, I was missing the restriction that![(t_1,t_2,t_3)\in[0,1]^3](https://s0.wp.com/latex.php?latex=%28t_1%2Ct_2%2Ct_3%29%5Cin%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) (Pace helpfully pointed this out to me). Without this restriction I was getting a lower bound slightly larger than 2.
(Pace helpfully pointed this out to me). Without this restriction I was getting a lower bound slightly larger than 2.
How necessary is this restriction under GEH? I was thinking that we could split the contribution from terms up depending on the number of prime factors. I think that the characteristic function of numbers with exactly
of prime factors. I think that the characteristic function of numbers with exactly  prime factors (and each prime factor in a given interval) should have good distribution up to
prime factors (and each prime factor in a given interval) should have good distribution up to  under GEH, with complete uniformity in the intervals containing the prime factors. This means that sums weighted by a smooth function of the prime factors should also have good distribution, and I think this means we should be able to handle terms when e.g.
under GEH, with complete uniformity in the intervals containing the prime factors. This means that sums weighted by a smooth function of the prime factors should also have good distribution, and I think this means we should be able to handle terms when e.g. 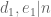 are very large, provided
are very large, provided  are suitably small. We'd need to be careful about
are suitably small. We'd need to be careful about  large, but presumably this can be handled by pre-sieving slightly. I haven't thought about this very thoroughly, so maybe I'm missing something obvious.
large, but presumably this can be handled by pre-sieving slightly. I haven't thought about this very thoroughly, so maybe I'm missing something obvious.
27 January, 2014 at 11:56 am
Terence Tao
Hmm. Presieving can certainly restrict us to the range where n,n+2,n+6 have at most (say) factors, while only costing us something like
(say) factors, while only costing us something like 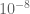 in the final estimates (which we can presumably tolerate). But I don’t see how any further restriction of the number of factors of n, n+2, or n+6 helps us. Note that GEH allows us to insert an arithmetic function of n, n+2, or n+6 into our divisor sums, but not two or more of them at once. So if one starts modulating the divisor sum
in the final estimates (which we can presumably tolerate). But I don’t see how any further restriction of the number of factors of n, n+2, or n+6 helps us. Note that GEH allows us to insert an arithmetic function of n, n+2, or n+6 into our divisor sums, but not two or more of them at once. So if one starts modulating the divisor sum  by the number of prime factors of n, for instance, one loses the ability to sum
by the number of prime factors of n, for instance, one loses the ability to sum  for prime n+2 or prime n+6, unless the modulating weight is at a very low level like
for prime n+2 or prime n+6, unless the modulating weight is at a very low level like  . Also I don’t see how knowing something about the number of prime factors helps us get past
. Also I don’t see how knowing something about the number of prime factors helps us get past ![[0,1]^3](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) – we need to understand the divisors of n that are a little bit bigger than
– we need to understand the divisors of n that are a little bit bigger than  , which does not seem to correlate with the number of prime factors (unless this number is 1, of course). We could also flip the divisor condition
, which does not seem to correlate with the number of prime factors (unless this number is 1, of course). We could also flip the divisor condition 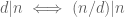 , but this introduces a Mobius function
, but this introduces a Mobius function 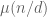 into the divisor sum which looks very unpleasant.
into the divisor sum which looks very unpleasant.
I’m a bit worried that the parity problem blocks us from going beyond![[0,1]^3](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) . In the k=2 case, taking F to be the indicator of
. In the k=2 case, taking F to be the indicator of ![[0,1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) already gets us right to the edge of the twin prime conjecture (
already gets us right to the edge of the twin prime conjecture ( ), and we should not be able to go further without doing something non-sieve-theoretic. This suggests to me that
), and we should not be able to go further without doing something non-sieve-theoretic. This suggests to me that ![[0,1]^3](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) is a real barrier and not just an artificial one.
is a real barrier and not just an artificial one.
27 January, 2014 at 3:37 pm
James Maynard
I would still be assuming the restriction , which would be necessary. I’ll try to be clearer, although I haven’t thought that much about this.
, which would be necessary. I’ll try to be clearer, although I haven’t thought that much about this.
Imagine for simplicity we’re in the case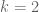 and we’re looking at the weights
and we’re looking at the weights  with the support restricted to
with the support restricted to  . We know that this is essentially optimal if we take
. We know that this is essentially optimal if we take  and
and  on this region. But imagine we wish to estimate the weights with (say)
on this region. But imagine we wish to estimate the weights with (say)
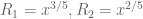
 using EH since
using EH since 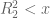 . We can apply the epsilon trick to get a lower bound for the terms weighted by
. We can apply the epsilon trick to get a lower bound for the terms weighted by  .
.
We can estimate the terms weighted by
To estimate the terms weighted by the constant 1, we wish to know that
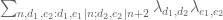
![[d_2,e_2]](https://s0.wp.com/latex.php?latex=%5Bd_2%2Ce_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) , where the sum is over
, where the sum is over 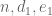 (lets not worry about the dependence on the modulus, since the absolute value is smooth with respect to the modulus). This quantity is
(lets not worry about the dependence on the modulus, since the absolute value is smooth with respect to the modulus). This quantity is
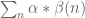
 is Dirichlet convolution,
is Dirichlet convolution, 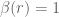 and
and
![\alpha(r)=\sum_{[d_1,e_1]=r}\lambda_{d_1,d_2}\lambda_{e_1,e_2}](https://s0.wp.com/latex.php?latex=%5Calpha%28r%29%3D%5Csum_%7B%5Bd_1%2Ce_1%5D%3Dr%7D%5Clambda_%7Bd_1%2Cd_2%7D%5Clambda_%7Be_1%2Ce_2%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![[d_1,e_1]](https://s0.wp.com/latex.php?latex=%5Bd_1%2Ce_1%5D&bg=ffffff&fg=545454&s=0&c=20201002) can be as large as
can be as large as  (since
(since  ), which means we can’t use GEH directly. I believe this is where the restriction
), which means we can’t use GEH directly. I believe this is where the restriction ![(t_1,t_2,t_3)\in[0,1]^3](https://s0.wp.com/latex.php?latex=%28t_1%2Ct_2%2Ct_3%29%5Cin%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) is coming from.
is coming from.
is well distributed in arithmetic progressions modulo
where
We’d like to apply GEH to estimate this sum, but in this model case
However, if we split the constant term 1 up into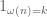 for
for  , say, then I think we should be able to estimate each of these terms in arithmetic progressions modulo
, say, then I think we should be able to estimate each of these terms in arithmetic progressions modulo ![[d_2,e_2]](https://s0.wp.com/latex.php?latex=%5Bd_2%2Ce_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) . The sum is just a smooth function of the
. The sum is just a smooth function of the  prime divisors of
prime divisors of  times
times 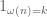 , and (I think) using a similar partitioning argument to that used in the BFI paper, this should be well-distributed modulo
, and (I think) using a similar partitioning argument to that used in the BFI paper, this should be well-distributed modulo ![[d_2,e_2]<R_2^2<x](https://s0.wp.com/latex.php?latex=%5Bd_2%2Ce_2%5D%3CR_2%5E2%3Cx&bg=ffffff&fg=545454&s=0&c=20201002) .
.
27 January, 2014 at 6:55 pm
Terence Tao
Ah, I begin to see what you are doing, nice!
A model problem here would be to understand the asymptotics of the one-dimensional Selberg sieve
When f is supported in![[0,1/2]](https://s0.wp.com/latex.php?latex=%5B0%2C1%2F2%5D&bg=ffffff&fg=545454&s=0&c=20201002) , the standard Selberg sieve calculation shows that this is asymptotic to
, the standard Selberg sieve calculation shows that this is asymptotic to  (possibly up to some
(possibly up to some  factors after restricting n to a single residue class modulo W). But by breaking n into prime factors (and supposing that the contribution of huge numbers of prime factors is negligible), it looks like this asymptotic can be extended to f supported in
factors after restricting n to a single residue class modulo W). But by breaking n into prime factors (and supposing that the contribution of huge numbers of prime factors is negligible), it looks like this asymptotic can be extended to f supported in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) . Note that this is consistent with the reflection identity
. Note that this is consistent with the reflection identity
when is square-free (which, after the W-trick, occurs almost all the time), since we get two factors of
is square-free (which, after the W-trick, occurs almost all the time), since we get two factors of 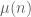 on reflecting which cancel each other out.
on reflecting which cancel each other out.
If this asymptotic holds up for the model problem, then I would tentatively believe that it also works for the multidimensional sums we have to deal with, which would mean that one can replace![[0,1]^3](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) with
with ![[0,2]^3](https://s0.wp.com/latex.php?latex=%5B0%2C2%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) in the variational problem on GEH (which, in practice, looks more or less equivalent to working on the entire orthant
in the variational problem on GEH (which, in practice, looks more or less equivalent to working on the entire orthant  ). This is contingent though on checking that the contribution of numbers that are not almost prime is negligible. There is a calculation of Pintz along these lines at http://arxiv.org/abs/1002.2899 , but one can probably also achieve a similar effect through preliminary sieving (the fundamental lemma of sieve theory). I’ll try to work this out in more detail, perhaps in time for the next blog post.
). This is contingent though on checking that the contribution of numbers that are not almost prime is negligible. There is a calculation of Pintz along these lines at http://arxiv.org/abs/1002.2899 , but one can probably also achieve a similar effect through preliminary sieving (the fundamental lemma of sieve theory). I’ll try to work this out in more detail, perhaps in time for the next blog post.
Looking at the gain from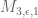 to
to 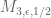 in the wiki, it looks like this new room only buys us 0.015 or so, slicing a third off of the gap – but perhaps things are a bit better in the M’ or M” world.
in the wiki, it looks like this new room only buys us 0.015 or so, slicing a third off of the gap – but perhaps things are a bit better in the M’ or M” world.
27 January, 2014 at 7:41 pm
James Maynard
A small thought: In the above problem, I think we have to be slightly careful about the precise range of support of , since if it is fully supported on the whole interval
, since if it is fully supported on the whole interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) then it can correlate with the Moebius function (since
then it can correlate with the Moebius function (since  can be written like this), but if the support is
can be written like this), but if the support is ![[0,1-\epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) then I think it should (conjecturally) have cancellation when summed with the Moebius function, and so we wouldn’t expect it to break the parity barrier (which is reassuring). I think this means that there could be large contributions from numbers with several prime factors if
then I think it should (conjecturally) have cancellation when summed with the Moebius function, and so we wouldn’t expect it to break the parity barrier (which is reassuring). I think this means that there could be large contributions from numbers with several prime factors if  had support
had support ![[0,1-\epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) (where ‘several’ is a range going to infinity as
(where ‘several’ is a range going to infinity as  goes to 0).
goes to 0).
27 January, 2014 at 8:04 pm
Terence Tao
Actually, because we are squaring the sum to play with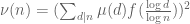 , the divisor sum can in fact start correlating with Mobius when the support of f stretches past [0,1/2], indeed it more or less has to since the quantity
, the divisor sum can in fact start correlating with Mobius when the support of f stretches past [0,1/2], indeed it more or less has to since the quantity 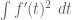 that measures the size of
that measures the size of  relative to the primes has now dipped below the parity barrier of 2. (Note also that multiplying by Mobius is more or less the same as replacing one of the f’s with its reflection
relative to the primes has now dipped below the parity barrier of 2. (Note also that multiplying by Mobius is more or less the same as replacing one of the f’s with its reflection 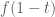 , and that
, and that 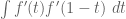 starts becoming non-zero when the support of f stretches beyond [0,1/2].) But it seems, strangely enough, that we still are able to control the sum
starts becoming non-zero when the support of f stretches beyond [0,1/2].) But it seems, strangely enough, that we still are able to control the sum 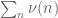 , not by using the distribution properties of 1, but instead using the distribution properties of the almost primes (and thus fully exploiting the GEH hypothesis). This makes it less clear whether the parity barrier is still in force for the purposes of blocking any progress on H_1 below 6, since Selberg’s argument presumes we are working with sieves that are always orthogonal to Mobius, but I would be surprised if such a notorious obstacle was circumvented so cheaply.
, not by using the distribution properties of 1, but instead using the distribution properties of the almost primes (and thus fully exploiting the GEH hypothesis). This makes it less clear whether the parity barrier is still in force for the purposes of blocking any progress on H_1 below 6, since Selberg’s argument presumes we are working with sieves that are always orthogonal to Mobius, but I would be surprised if such a notorious obstacle was circumvented so cheaply.
On a largely unrelated note: Motohashi has just uploaded a survey article on the bounded gaps problem between primes, with the optimistic title of “the twin prime conjecture”, at http://arxiv.org/abs/1401.6614 , aimed at a general mathematical audience.
27 January, 2014 at 8:14 pm
James Maynard
Yes, I was referring to the non-squared sum when I was talking about correlation with Moebius. I just wanted to use this to demonstrate that if has support
has support ![[0,1-\epsilon]](https://s0.wp.com/latex.php?latex=%5B0%2C1-%5Cepsilon%5D&bg=ffffff&fg=545454&s=0&c=20201002) then numbers with a large number of prime factors (depending on
then numbers with a large number of prime factors (depending on  ) will make a noticeable contribution to the squared sum.
) will make a noticeable contribution to the squared sum.
28 January, 2014 at 6:22 am
Pace Nielsen
These are very exciting ideas! This might be a silly question, but what prevents us from applying them to the k=2 case, rather than just the k=3 case?
28 January, 2014 at 5:04 am
Andrew Sutherland
The bound for m=2 without EH can be improved to 395,106.
28 January, 2014 at 7:48 am
Terence Tao
OK, I think I can justify James’ argument that (on GEH) allows one to relax the requirement that R be contained in![[0,1]^k](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) (or that
(or that  lie in
lie in ![[0,2]^k](https://s0.wp.com/latex.php?latex=%5B0%2C2%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) ) with the requirement that R be contained instead in
) with the requirement that R be contained instead in ![[0,2]^k](https://s0.wp.com/latex.php?latex=%5B0%2C2%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) (or more precisely
(or more precisely ![[0,2-o(1)]^k](https://s0.wp.com/latex.php?latex=%5B0%2C2-o%281%29%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) ). Thus for instance we gain access to the entire simplex
). Thus for instance we gain access to the entire simplex  now, bearing in mind though that if we venture too far out into this simplex without vanishing marginal conditions then we will pay for it with the epsilons.
now, bearing in mind though that if we venture too far out into this simplex without vanishing marginal conditions then we will pay for it with the epsilons.
Details will appear in the next blog post.![f: [0,a] \to {\bf R}](https://s0.wp.com/latex.php?latex=f%3A+%5B0%2Ca%5D+%5Cto+%7B%5Cbf+R%7D&bg=ffffff&fg=545454&s=0&c=20201002) is a C^1 function (i.e. continuously differentiable), then
is a C^1 function (i.e. continuously differentiable), then
The crux is the following cute identity: if
where . A bit more explicitly, the RHS of (*) expands as
. A bit more explicitly, the RHS of (*) expands as
The number-theoretic interpretation is that the LHS of (*) represents the value of , and the k^th term on the RHS of (*) represents the contribution of those n that are the products of exactly k primes. It is relatively easy to establish the inequality
, and the k^th term on the RHS of (*) represents the contribution of those n that are the products of exactly k primes. It is relatively easy to establish the inequality  , after first verifying the preliminary identity
, after first verifying the preliminary identity
getting equality requires a bit more care, and corresponds to the assertion that the sieve is mostly dominated by almost primes.
Anyway, by using this formula and Maynard’s trick, I think I can get the expected asymptotic for the numerator as long as F is supported in the (interior of) a region R with
as long as F is supported in the (interior of) a region R with
which improves upon the previous requirements by replacing![[0,2]^k](https://s0.wp.com/latex.php?latex=%5B0%2C2%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) with
with ![[0,4]^k](https://s0.wp.com/latex.php?latex=%5B0%2C4%5D%5Ek&bg=ffffff&fg=545454&s=0&c=20201002) . Details to appear in the next blog post. In particular, when k=3 we can work on the untruncated simplex
. Details to appear in the next blog post. In particular, when k=3 we can work on the untruncated simplex  , effectively giving us access to the quantities
, effectively giving us access to the quantities 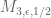 ,
, 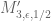 and
and  . I had noted previously that the gain of
. I had noted previously that the gain of 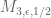 over
over 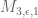 was slight (about 0.013 on current numerical data), but this was because we used a one-dimensional model to compute
was slight (about 0.013 on current numerical data), but this was because we used a one-dimensional model to compute 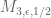 . For
. For  , the one-dimensional model is short by about 0.011, so putting everything together we might expect to advance about 0.024 with this new trick, or more than halfway. (Zeno again!)
, the one-dimensional model is short by about 0.011, so putting everything together we might expect to advance about 0.024 with this new trick, or more than halfway. (Zeno again!)
Pace asked what happens when k=2. This is a great question. Technically, the parity barrier is not obviously present any more, although I can’t imagine that it’s this easy to get around that notorious obstacle. We can work in any R with
in particular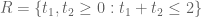 is available. But even on this enlarged region, it appears that the previous extremiser
is available. But even on this enlarged region, it appears that the previous extremiser ![F = 1_{[0,1]^2}](https://s0.wp.com/latex.php?latex=F+%3D+1_%7B%5B0%2C1%5D%5E2%7D&bg=ffffff&fg=545454&s=0&c=20201002) is still a critical point (at least for the
is still a critical point (at least for the  problem), as it solves the Euler-Lagrange equation
problem), as it solves the Euler-Lagrange equation 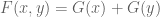 with
with  on
on ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) . One could play with the epsilons, and one should probably check this on the 1% chance that we accidentally prove the twin prime conjecture (on GEH) this way, but my guess would be that one loses more than one gains by increasing epsilon.
. One could play with the epsilons, and one should probably check this on the 1% chance that we accidentally prove the twin prime conjecture (on GEH) this way, but my guess would be that one loses more than one gains by increasing epsilon.
28 January, 2014 at 9:18 am
James Maynard
I guess its worth noting that in the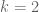 case we also just fail to prove the twin prime conjecture at the other extreme. We’re looking at divisors
case we also just fail to prove the twin prime conjecture at the other extreme. We’re looking at divisors  subject to
subject to  , so we might as well have
, so we might as well have  . If
. If  then we’re at our familiar situation, and just fail to prove twin primes. If we take the other extreme
then we’re at our familiar situation, and just fail to prove twin primes. If we take the other extreme 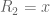 , then we effectively have multiplied everything by the characteristic function
, then we effectively have multiplied everything by the characteristic function  . We have to throw out all of the
. We have to throw out all of the  contribution from the epsilon trick, but the constant term 1 and the
contribution from the epsilon trick, but the constant term 1 and the  term contribute the same amount, so we just fail again (and this looks a lot like Bombieri’s sieve). I don’t know what happens in between, but since nothing is correlating with
term contribute the same amount, so we just fail again (and this looks a lot like Bombieri’s sieve). I don’t know what happens in between, but since nothing is correlating with  I’d be skeptical the parity barrier isn’t hiding somewhere.
I’d be skeptical the parity barrier isn’t hiding somewhere.
28 January, 2014 at 12:25 pm
Aubrey de Grey
With this new, relaxed constraint on R+R, might it be worth revisiting the prism in the k=3 case? I ask because the untruncated simplex with (1/2,1/2,1/2) on its boundary has volume 9/16, but the elongated prism in which x+y (aka t1+t2) does not exceed 1 but z (aka t3) can be as much as 2 has volume 1.
28 January, 2014 at 2:15 pm
Pace Nielsen
Computing on the region![\{(x,y,z)\in [0,2]^{3}: x+y+z\leq 3/2;x+y,y+z,z+x\leq 1+\varepsilon\}](https://s0.wp.com/latex.php?latex=%5C%7B%28x%2Cy%2Cz%29%5Cin+%5B0%2C2%5D%5E%7B3%7D%3A+x%2By%2Bz%5Cleq+3%2F2%3Bx%2By%2Cy%2Bz%2Cz%2Bx%5Cleq+1%2B%5Cvarepsilon%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002) with no marginal conditions, I get
with no marginal conditions, I get  when epsilon is about 29/100 (and this appears to be close to the optimal epsilon). I’ll next do the computation on the full symmetric half-cube with marginal conditions. This is so tantalizingly close, I think we may just make it! [Aubrey, I tried the same computation on the extended prism, but the numerics didn’t work out as well without incorporating the marginal conditions.]
when epsilon is about 29/100 (and this appears to be close to the optimal epsilon). I’ll next do the computation on the full symmetric half-cube with marginal conditions. This is so tantalizingly close, I think we may just make it! [Aubrey, I tried the same computation on the extended prism, but the numerics didn’t work out as well without incorporating the marginal conditions.]
28 January, 2014 at 2:20 pm
Pace Nielsen
By the way, with all the changes I’m getting a little confused by the M notations. To be clear, the previous computation used the epsilon expansion trick and the stated region.
28 January, 2014 at 2:33 pm
Aubrey de Grey
Right – since current notation covers values of theta other than 1, I guess the question is whether a new notation is needed to represent the fact that the bounding hypercube no longer has edge-length 1/theta, which in turn requires clarity as to whether James’s new trick translates into a bounding hypercube of edge-length 2/theta, or if not, what.
28 January, 2014 at 8:56 pm
Terence Tao
Well, fortunately we can use an older notation here: James’ new trick effectively replaces (symmetric polytope) with
(symmetric polytope) with 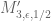 (symmetric polytope), and similarly for M and M”.
(symmetric polytope), and similarly for M and M”.
28 January, 2014 at 3:17 pm
Aubrey de Grey
Ah, sure, the extended prism’s greater volume could certainly only help when marginals are included – it would cut a big swathe off R’_3,epsilon rather than just a tip. Let’s see if you make the goal using the symmetric half-cube with marginals – but if you don’t, I still think it’s worth checking the extended prism with marginals.
28 January, 2014 at 2:39 pm
Eytan Paldi
For the relaxed condition on , it seems that the above restriction on
, it seems that the above restriction on  to be supported on the interior of
to be supported on the interior of  can be slightly relaxed to the closure of
can be slightly relaxed to the closure of  (since the condition on the M-value is open).
(since the condition on the M-value is open).
28 January, 2014 at 11:56 am
Terence Tao
Another recent paper on the arXiv: Jesse Thorner has used the multidimensional GPY-Selberg sieve to get bounded gaps between primes in residue classes or in Chebotarev classes : http://arxiv.org/abs/1401.6677
28 January, 2014 at 9:19 pm
Polymath8b, VII: Using the generalised Elliott-Halberstam hypothesis to enlarge the sieve support yet further | What's new
[…] for small values of (in particular ) or asymptotically as . The previous thread may be found here. The currently best known bounds on can be found at the wiki […]