
We now begin the rigorous theory of the incompressible Navier-Stokes equations
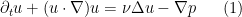
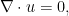
 is a given constant (the kinematic viscosity, or viscosity for short),
is a given constant (the kinematic viscosity, or viscosity for short), 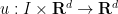 is an unknown vector field (the velocity field), and
is an unknown vector field (the velocity field), and 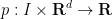 is an unknown scalar field (the pressure field). Here
is an unknown scalar field (the pressure field). Here  is a time interval, usually of the form
is a time interval, usually of the form ![{[0,T]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) or
or  . We will either be interested in spatially decaying situations, in which
. We will either be interested in spatially decaying situations, in which 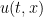 decays to zero as
decays to zero as  , or
, or 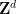 -periodic (or periodic for short) settings, in which one has
-periodic (or periodic for short) settings, in which one has 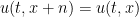 for all
for all 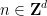 . (One can also require the pressure
. (One can also require the pressure  to be periodic as well; this brings up a small subtlety in the uniqueness theory for these equations, which we will address later in this set of notes.) As is usual, we abuse notation by identifying a -periodic function on
to be periodic as well; this brings up a small subtlety in the uniqueness theory for these equations, which we will address later in this set of notes.) As is usual, we abuse notation by identifying a -periodic function on  with a function on the torus
with a function on the torus  .
.
In order for the system (1) to even make sense, one requires some level of regularity on the unknown fields 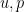
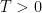
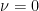
As the unknown fields involve a time parameter 

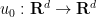
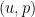
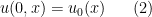
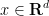 . Of course, in order for this initial condition to be compatible with the second equation in (1), we need the compatibility condition
. Of course, in order for this initial condition to be compatible with the second equation in (1), we need the compatibility condition 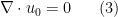
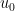 in order to be compatible with corresponding level of regularity etc. on the solution .
in order to be compatible with corresponding level of regularity etc. on the solution .
The fundamental questions in the local theory of an evolution equation are that of existence, uniqueness, and continuous dependence. In the context of the Navier-Stokes equations, these questions can be phrased (somewhat broadly) as follows:
- (a) (Local existence) Given suitable initial data
of existence? How regular is the solution?
- (b) (Uniqueness) Is it possible to have two solutions
of a certain regularity class to the same initial value problem on a common time interval
- (c) (Continuous dependence on data) If one perturbs the initial conditions
The answers to these questions tend to be more complicated than a simple “Yes” or “No”, for instance they can depend on the precise regularity hypotheses one wishes to impose on the data and on the solution, and even on exactly how one interprets the concept of a “solution”. However, once one settles on such a set of hypotheses, it generally happens that one either gets a “strong” theory (in which one has existence, uniqueness, and continuous dependence on the data), a “weak” theory (in which one has existence of somewhat low-quality solutions, but with only limited uniqueness results (or even some spectacular failures of uniqueness) and almost no continuous dependence on data), or no satsfactory theory whatsoever. In the former case, we say (roughly speaking) that the initial value problem is locally well-posed, and one can then try to build upon the theory to explore more interesting topics such as global existence and asymptotics, classifying potential blowup, rigorous justification of conservation laws, and so forth. With a weak local theory, it becomes much more difficult to address these latter sorts of questions, and there are serious analytic pitfalls that one could fall into if one tries too strenuously to treat weak solutions as if they were strong. (For instance, conservation laws that are rigorously justified for strong, high-regularity solutions may well fail for weak, low-regularity ones.) Also, even if one is primarily interested in solutions at one level of regularity, the well-posedness theory at another level of regularity can be very helpful; for instance, if one is interested in smooth solutions in 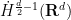
This set of notes will focus on the “strong” theory, in which a substantial amount of regularity is assumed in the initial data and solution, giving a satisfactory (albeit largely local-in-time) well-posedness theory. “Weak” solutions will be considered in later notes.
The Navier-Stokes equations are not the simplest of partial differential equations to study, in part because they are an amalgam of three more basic equations, which behave rather differently from each other (for instance the first equation is nonlinear, while the latter two are linear):
- (a) Transport equations such as
.
- (b) Diffusion equations (or heat equations) such as
.
- (c) Systems such as
,
, which (for want of a better name) we will call Leray systems.
Accordingly, we will devote some time to getting some preliminary understanding of the linear diffusion and Leray systems before returning to the theory for the Navier-Stokes equation. Transport systems will be discussed further in subsequent notes; in this set of notes, we will instead focus on a more basic example of nonlinear equations, namely the first-order ordinary differential equation
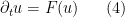
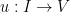 takes values in some finite-dimensional (real or complex) vector space
takes values in some finite-dimensional (real or complex) vector space  on some time interval , and
on some time interval , and  is a given linear or nonlinear function. (Here, we use “interval” to denote a connected non-empty subset of
is a given linear or nonlinear function. (Here, we use “interval” to denote a connected non-empty subset of  ; in particular, we allow intervals to be half-infinite or infinite, or to be open, closed, or half-open.) Fundamental results in this area include the Picard existence and uniqueness theorem, the Duhamel formula, and Grönwall’s inequality; they will serve as motivation for the approach to local well-posedness that we will adopt in this set of notes. (There are other ways to construct strong or weak solutions for Navier-Stokes and Euler equations, which we will discuss in later notes.)
; in particular, we allow intervals to be half-infinite or infinite, or to be open, closed, or half-open.) Fundamental results in this area include the Picard existence and uniqueness theorem, the Duhamel formula, and Grönwall’s inequality; they will serve as motivation for the approach to local well-posedness that we will adopt in this set of notes. (There are other ways to construct strong or weak solutions for Navier-Stokes and Euler equations, which we will discuss in later notes.)
A key role in our treatment here will be played by the fundamental theorem of calculus (in various forms and variations). Roughly speaking, this theorem, and its variants, allow us to recast differential equations (such as (1) or (4)) as integral equations. Such integral equations are less tractable algebraically than their differential counterparts (for instance, they are not ideal for verifying conservation laws), but are significantly more convenient for well-posedness theory, basically because integration tends to increase the regularity of a function, while differentiation reduces it. (Indeed, the problem of “losing derivatives”, or more precisely “losing regularity”, is a key obstacle that one often has to address when trying to establish well-posedness for PDE, particularly those that are quite nonlinear and with rough initial data, though for nonlinear parabolic equations such as Navier-Stokes the obstacle is not as serious as it is for some other PDE, due to the smoothing effects of the heat equation.)
One weakness of the methods deployed here are that the quantitative bounds produced deteriorate to the point of uselessness in the inviscid limit 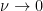
In this and subsequent set of notes, we use the following asymptotic notation (a variant of Vinogradov notation that is commonly used in PDE and harmonic analysis). The statement 

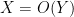
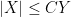


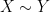
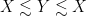

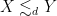
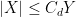

— 1. Ordinary differential equations —
We now study solutions to ordinary differential equations (4), focusing in particular on the initial value problem when the initial state 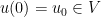
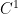


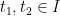 (in this post we use the signed definite integral, thus
(in this post we use the signed definite integral, thus  ).
).
We begin with homogeneous linear equations
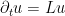
 is a linear operator. Using the integrating factor
is a linear operator. Using the integrating factor 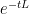 , where
, where 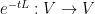 is the matrix exponential of
is the matrix exponential of 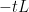 , and noting that
, and noting that 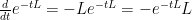 , we see that this equation is equivalent to
, we see that this equation is equivalent to 
 then we have the unique global solution
then we have the unique global solution  , or equivalently
, or equivalently 
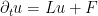
 with initial condition , then from the fundamental theorem of calculus we have a unique global solution given by
with initial condition , then from the fundamental theorem of calculus we have a unique global solution given by 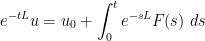
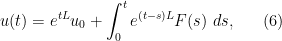
 is continuous. Intuitively, the first term
is continuous. Intuitively, the first term  represents the contribution of the initial data to the solution
represents the contribution of the initial data to the solution 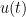 at time (with the
at time (with the 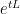 factor representing the evolution from time
factor representing the evolution from time  to time ), while the integrand
to time ), while the integrand 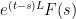 represents the contribution of the forcing term
represents the contribution of the forcing term 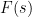 at time
at time  to the solution at time (with the
to the solution at time (with the 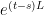 factor representing the evolution from time to time ).
factor representing the evolution from time to time ).
One can apply a similar analysis to the differential inequality

 is now a scalar continuously differentiable function,
is now a scalar continuously differentiable function, 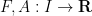 are continuous functions, and is an interval containing as its left endpoint; we also assume an initial condition
are continuous functions, and is an interval containing as its left endpoint; we also assume an initial condition 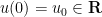 . Here, the natural integrating factor is
. Here, the natural integrating factor is 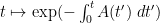 , whose derivative is
, whose derivative is 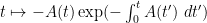 by the chain rule and the fundamental theorem of calculus. Applying this integrating factor to (7), we may write it as
by the chain rule and the fundamental theorem of calculus. Applying this integrating factor to (7), we may write it as 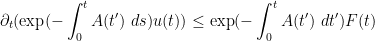
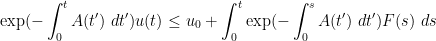
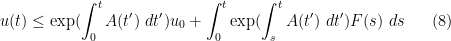
 (compare with (6)). This is the differential form of Grönwall’s inequality. In the homogeneous case
(compare with (6)). This is the differential form of Grönwall’s inequality. In the homogeneous case  , the inequality of course simplifies to
, the inequality of course simplifies to 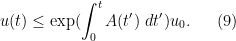
We continue assuming that
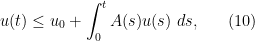 , at least when all functions involved are non-negative:
, at least when all functions involved are non-negative:
Lemma 1 (Integral form of Grönwall inequality) Let, and let
be continuous functions obeying the inequality (10) for all
Proof: From (10) and the fundamental theorem of calculus, the function 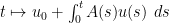
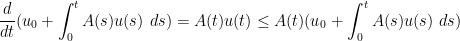
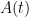 is non-negative). Applying the differential form (9) of Gronwall’s inequality, we conclude that
is non-negative). Applying the differential form (9) of Gronwall’s inequality, we conclude that 

Exercise 2 Relax the hypotheses of continuity onto that of being measurable and bounded on compact intervals. (You will need tools such as the fundamental theorem of calculus for absolutely continuous or Lipschitz functions, covered for instance in this previous set of notes.)
Gronwall’s inequality is an excellent tool for bounding the growth of a solution to an ODE or PDE, or the difference between two such solutions. Here is a basic example, one half of the Picard (or Picard-Lindeöf) theorem:
Theorem 3 (Picard uniqueness theorem) Letbe continuously differentiable solutions to the ODE (4), thus
on
for some
, then
agree identically on
for all

Proof: By translating 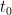

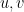

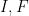


From the fundamental theorem of calculus we have
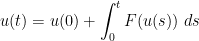
 ; subtracting, we conclude
; subtracting, we conclude 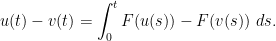 and the triangle inequality, we conclude that
and the triangle inequality, we conclude that 

Remark 4 The same result applies for infinite-dimensional normed vector spaces
Exercise 5 (Comparison principle) Letbe a function that is Lipschitz continuous on compact intervals. Let
be continuously differentiable functions such that
and
for all
- (a) Suppose that
for some
for all
. (Hint: there are several ways to proceed here. One is to try to verify the hypotheses of Grönwall’s inequality for the quantity
or
.)
- (b) Suppose that
for some
for all
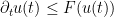
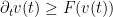
Now we turn to the existence side of the Picard theorem.
Theorem 6 (Picard existence theorem) Let, and let
lie in the closed ball
. Let
. If one sets
then there exists a continuously differentiable solution
to the ODE (4) with initial data
for all
.
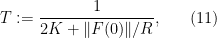
Note that the solution produced by this theorem is unique on ![{[-T,T]}](https://s0.wp.com/latex.php?latex=%7B%5B-T%2CT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
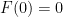
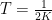
Proof: Using the fundamental theorem of calculus, we write (4) (with initial condition 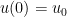
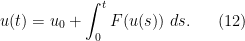 is continuously differentiable and solves (4) with on , then (12) holds on . Conversely, if is continuous and solves (12) on , then by the fundamental theorem of calculus the right-hand side of (12) (and hence ) is continuously differentiable and solves (4) with . Thus it suffices to solve the integral equation (12) with a solution taking values in .
is continuously differentiable and solves (4) with on , then (12) holds on . Conversely, if is continuous and solves (12) on , then by the fundamental theorem of calculus the right-hand side of (12) (and hence ) is continuously differentiable and solves (4) with . Thus it suffices to solve the integral equation (12) with a solution taking values in .
We can view this as a fixed point problem. Let ![{X = C([-T,T] \rightarrow \overline{B(0,2R)})}](https://s0.wp.com/latex.php?latex=%7BX+%3D+C%28%5B-T%2CT%5D+%5Crightarrow+%5Coverline%7BB%280%2C2R%29%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle d(u,v) := \sup_{t \in [-T,T]} \| u(t) - v(t) \|.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d%28u%2Cv%29+%3A%3D+%5Csup_%7Bt+%5Cin+%5B-T%2CT%5D%7D+%5C%7C+u%28t%29+-+v%28t%29+%5C%7C.&bg=ffffff&fg=000000&s=0&c=20201002)
 becomes a complete metric space with this metric. Let
becomes a complete metric space with this metric. Let  denote the map
denote the map 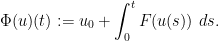
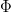 does map to . If
does map to . If 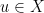 , then
, then 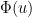 is clearly continuous. For any
is clearly continuous. For any ![{t \in [-T,T]}](https://s0.wp.com/latex.php?latex=%7Bt+%5Cin+%5B-T%2CT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , one has from the triangle inequality that
, one has from the triangle inequality that ![\displaystyle \| \Phi(u)(t) \| \leq \| u_0 \| + T \sup_{s \in [-T,T]} \| F(u(s)) \|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CPhi%28u%29%28t%29+%5C%7C+%5Cleq+%5C%7C+u_0+%5C%7C+%2B+T+%5Csup_%7Bs+%5Cin+%5B-T%2CT%5D%7D+%5C%7C+F%28u%28s%29%29+%5C%7C&bg=ffffff&fg=000000&s=0&c=20201002)

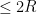 , hence
, hence  as claimed. A similar argument shows that is in fact a contraction on . Namely, if
as claimed. A similar argument shows that is in fact a contraction on . Namely, if 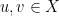 , then
, then 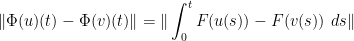
![\displaystyle \leq T \sup_{s \in [-T,T]} K \|u(s)-v(s)\|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleq+T+%5Csup_%7Bs+%5Cin+%5B-T%2CT%5D%7D+K+%5C%7Cu%28s%29-v%28s%29%5C%7C+&bg=ffffff&fg=000000&s=0&c=20201002)
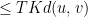
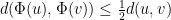 by choice of . Applying the contraction mapping theorem, we obtain a fixed point to the equation
by choice of . Applying the contraction mapping theorem, we obtain a fixed point to the equation 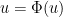 , which is precisely (12), and the claim follows.
, which is precisely (12), and the claim follows.
Remark 7 The proof extends without difficulty to infinite dimensional Banach spacesfor some
, with
. Here, the function
is of course Lipschitz with constant
, hence
, which is only larger than the time
given by the above theorem by a multiplicative constant.
We can iterate the Picard existence theorem (and combine it with the uniqueness theorem) to conclude that there is a maximal Cauchy development 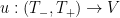
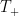

Theorem 8 (Maximal Cauchy development) Letand a continuously differentiable solution
if
if
, and
Proof: Uniqueness follows easily from Theorem 3. For existence, let 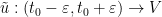
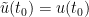
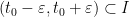
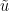
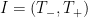
Suppose for contradiction that 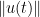
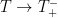


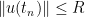


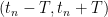

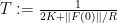
Remark 9 Theorem 6 gives a more quantitative description of the blowup: if, one must have
where
is the Lipschitz constant of
. This can be used to give some explicit lower bound on blowup rates. For instance, if
behaves like
for some
in the sense that the Lipschitz constant of
is
for any
as
, if
where
, one has explicit solutions on
of the form
where
is a positive constant depending only on
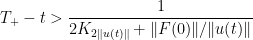

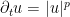
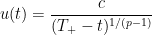
Exercise 10 (Higher regularity) Let the notation and hypotheses be as in Theorem 8. Suppose thattimes continuously differentiable for some natural number
times continuously differentiable. In particular, if
Exercise 11 (Lipschitz continuous dependence on data) Let
- (a) Let
, and
are the solutions to (4) with
given by Theorem 6, show that
- (b) Let
containing
of
, there exists a solution
of (4) with initial data
. Furthermore, the map from
to
.
![\displaystyle \sup_{t \in [-T,T]} \|u(t)-v(t)\| \leq 2 \|u_0-v_0\|.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%7Bt+%5Cin+%5B-T%2CT%5D%7D+%5C%7Cu%28t%29-v%28t%29%5C%7C+%5Cleq+2+%5C%7Cu_0-v_0%5C%7C.&bg=ffffff&fg=000000&s=0&c=20201002)
Exercise 12 (Non-autonomous Picard theorem) Letbe a function which is Lipschitz on bounded sets. Let
solving the non-autonomous ODE
for
with initial data
are unique. (Hint: this could be done by repeating all of the previous arguments, but there is also a way to deduce this non-autonomous version of the Picard theorem directly from the Picard theorem by adding one extra dimension to the space
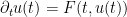
The above theory is symmetric with respect to the time reversal of replacing 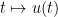
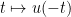
Exercise 13 Letfor all
and
. Show that there exists a continuously differentiable solution
to the ODE
with initial data
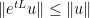

Remark 14 With the hypotheses of the above exercise, one can also solve the ODE backwards in time by an amount, where
denotes the operator norm of
. However, in the limit as the operator norm of
— 2. Leray systems —
Now we discuss the Leray system of equations

 is given, and the vector field
is given, and the vector field 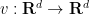 and the scalar field
and the scalar field 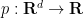 are unknown. In other words, we wish to decompose a specified function as the sum of a gradient
are unknown. In other words, we wish to decompose a specified function as the sum of a gradient  and a divergence-free vector field . We will use the usual Lebesgue spaces
and a divergence-free vector field . We will use the usual Lebesgue spaces 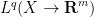 of measurable functions
of measurable functions  (up to almost everywhere equivalence) defined on some measure space
(up to almost everywhere equivalence) defined on some measure space 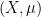 (which in our case will always be either or with Lebesgue measure) such that the
(which in our case will always be either or with Lebesgue measure) such that the 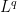 norm
norm  is finite. (For
is finite. (For 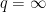 , the
, the  norm is defined instead to be the essential supremum of
norm is defined instead to be the essential supremum of 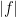 .)
.)
Proceeding purely formally, we could solve this system by taking the divergence of the first equation to conclude that

 is the Laplacian of , and then we could formally solve for as
is the Laplacian of , and then we could formally solve for as  as
as 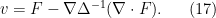
 is not quite invertible. To sort this out and make this problem well-defined, we need to specify the regularity and decay one wishes to impose on the data and on the solution
is not quite invertible. To sort this out and make this problem well-defined, we need to specify the regularity and decay one wishes to impose on the data and on the solution  . To begin with, let us suppose that
. To begin with, let us suppose that  are all smooth.
are all smooth.
We first understand the uniqueness theory for this problem. By linearity, this amounts to solving the homogeneous equation when
 and write this a single equation
and write this a single equation  to be a (smooth) harmonic function, and to be the negative gradient of . This is consistent with our preceding discussion that identified the potential lack of invertibility of as a key issue.
to be a (smooth) harmonic function, and to be the negative gradient of . This is consistent with our preceding discussion that identified the potential lack of invertibility of as a key issue.
By linearity, this implies that (smooth) solutions 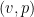
We can largely eliminate this lack of uniqueness by imposing further requirements on 
 and . Then the only freedom we have is to modify by an arbitrary periodic harmonic function (and to subtract the gradient of that function from ). However, by Liouville’s theorem, the only periodic harmonic functions are the constants, whose gradient vanishes. Thus the only freedom in this setting is to add a constant to . This freedom will be almost irrelevant when we consider the Euler and Navier-Stokes equations, since it is only the gradient of the pressure which appears in those equations, rather than the pressure itself. Nevertheless, if one wishes, one could remove this freedom by requiring that be of mean zero:
and . Then the only freedom we have is to modify by an arbitrary periodic harmonic function (and to subtract the gradient of that function from ). However, by Liouville’s theorem, the only periodic harmonic functions are the constants, whose gradient vanishes. Thus the only freedom in this setting is to add a constant to . This freedom will be almost irrelevant when we consider the Euler and Navier-Stokes equations, since it is only the gradient of the pressure which appears in those equations, rather than the pressure itself. Nevertheless, if one wishes, one could remove this freedom by requiring that be of mean zero: 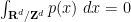 .
.
Now suppose instead that we only require that 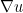
Instead of periodicity, one can also impose decay conditions on the various functions. Suppose for instance that we require the pressure to lie in an 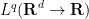

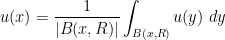
 of some radius centred around
of some radius centred around  , where
, where  denotes the measure of the ball. By Hölder’s inequality, we conclude that
denotes the measure of the ball. By Hölder’s inequality, we conclude that 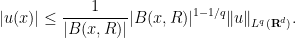
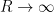 we conclude that vanishes identically; thus there are no non-trivial harmonic functions in . Thus there is uniqueness for the problem (15) if we require the pressure to lie in . If instead we require the vector field to be in
we conclude that vanishes identically; thus there are no non-trivial harmonic functions in . Thus there is uniqueness for the problem (15) if we require the pressure to lie in . If instead we require the vector field to be in  , then we can modify by a harmonic function with in
, then we can modify by a harmonic function with in  , thus vanishes identically and hence is constant. So if we require
, thus vanishes identically and hence is constant. So if we require 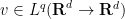 then we only have the freedom to adjust by arbitrary constants.
then we only have the freedom to adjust by arbitrary constants.
Having discussed uniqueness, we now turn to existence. We begin with the periodic setting in which 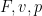


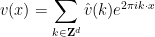

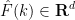 ,
,  ,
,  are given by the formulae
are given by the formulae 
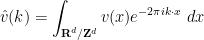
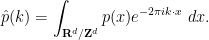 are smooth, then
are smooth, then  are rapidly decreasing as
are rapidly decreasing as 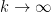 , which will allow us to justify manipulations such as interchanging summation and derivatives without difficulty. Expanding out (15) in Fourier series and then comparing Fourier coefficients (which are unique for smooth functions), we obtain the system
, which will allow us to justify manipulations such as interchanging summation and derivatives without difficulty. Expanding out (15) in Fourier series and then comparing Fourier coefficients (which are unique for smooth functions), we obtain the system 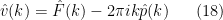

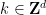 . As mentioned above, the Fourier transform has diagonalised the system (15), in that there are no interactions between different frequencies , and we now have a decoupled system of vector equations. To solve these equations, we can take the inner product of both sides of (18) with and apply (19) to conclude that
. As mentioned above, the Fourier transform has diagonalised the system (15), in that there are no interactions between different frequencies , and we now have a decoupled system of vector equations. To solve these equations, we can take the inner product of both sides of (18) with and apply (19) to conclude that  , we can then solve for
, we can then solve for 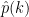 and hence
and hence 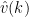 by the formulae
by the formulae 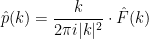
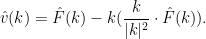
 , these formulae no longer apply; however from (18) we see that
, these formulae no longer apply; however from (18) we see that 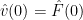 , while
, while 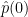 can be arbitrary (which corresponds to the aforementioned freedom to add an arbitrary constant to ). Thus we have the explicit general solution
can be arbitrary (which corresponds to the aforementioned freedom to add an arbitrary constant to ). Thus we have the explicit general solution 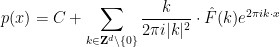
 is an arbitrary constant. Note that if is smooth, then
is an arbitrary constant. Note that if is smooth, then  is rapidly decreasing and the functions
is rapidly decreasing and the functions 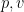 defined by the above formulae are also smooth.
defined by the above formulae are also smooth.
We can write the above general solution in a form similar to (16), (17) as


 of a smooth periodic function
of a smooth periodic function 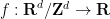 of mean zero is given by the Fourier series formula
of mean zero is given by the Fourier series formula 
 automatically has mean zero.) It is easy to see that
automatically has mean zero.) It is easy to see that 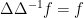 for such functions
for such functions  , thus justifying the choice of notation. We refer to
, thus justifying the choice of notation. We refer to 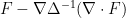 as the (periodic) Leray projection of and denote it
as the (periodic) Leray projection of and denote it 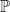 , thus in the above solution we have
, thus in the above solution we have 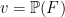 . By construction,
. By construction, 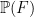 is divergence-free, and vanishes whenever is a gradient
is divergence-free, and vanishes whenever is a gradient  .
.
If we require 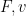
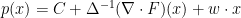
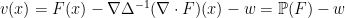
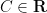 and
and  are arbitrary.
are arbitrary.
The above discussion was for smooth periodic functions 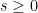
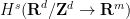

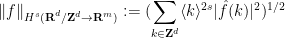
 . (One can also define Sobolev spaces for negative , but we will not need them here.) Basic properties of these Sobolev spaces can be found in this previous post. From comparing Fourier coefficients we see that the operators
. (One can also define Sobolev spaces for negative , but we will not need them here.) Basic properties of these Sobolev spaces can be found in this previous post. From comparing Fourier coefficients we see that the operators  and
and 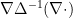 defined for smooth periodic functions can be extended without difficulty to
defined for smooth periodic functions can be extended without difficulty to  (taking values in
(taking values in  and
and  respectively), with bounds of the form
respectively), with bounds of the form 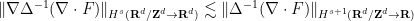

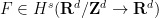 , then one can solve (15) (in the sense of distributions, at least) with some
, then one can solve (15) (in the sense of distributions, at least) with some 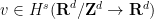 and
and  , with bounds
, with bounds  is bounded on . (In fact it is a non-expansive map; see Exercise 16.)
is bounded on . (In fact it is a non-expansive map; see Exercise 16.)
One can argue similarly in the non-periodic setting, as long as one avoids the one-dimensional case 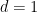

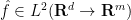


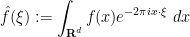 by continuous extension in the
by continuous extension in the  topology, taking advantage of the Plancherel identity
topology, taking advantage of the Plancherel identity 
We then define the Sobolev space 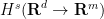
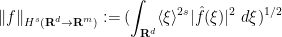

 is defined by
is defined by 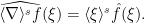 in the Schwartz class, we define
in the Schwartz class, we define  to be the scalar tempered distribution whose (distributional) Fourier transform is given by the formula
to be the scalar tempered distribution whose (distributional) Fourier transform is given by the formula 
 to be the vector-valued distribution
to be the vector-valued distribution 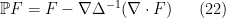
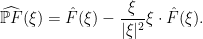
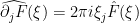
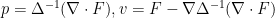 have locally integrable Fourier transforms that are rapidly decreasing away from the origin, and are thus smooth.
have locally integrable Fourier transforms that are rapidly decreasing away from the origin, and are thus smooth.
As in the periodic case we see that we have the bound
 (in fact is again a non-expansive map), so we can extend the Leray projection without difficulty to
(in fact is again a non-expansive map), so we can extend the Leray projection without difficulty to 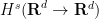 functions. The operator
functions. The operator  can similarly be extended continuously to a map from to the space
can similarly be extended continuously to a map from to the space  of scalar tempered distributions with gradient in , although we will not need to work directly with the pressure much in this course. This allows us to solve (15) in a distributional sense for all
of scalar tempered distributions with gradient in , although we will not need to work directly with the pressure much in this course. This allows us to solve (15) in a distributional sense for all  .
.
Remark 15 (Remark removed due to inaccuracy.)
Exercise 16 (Hodge decomposition) Define the following three subspaces of the Hilbert space:
is the space of all elements of
(in the sense of distributions) for some
;
is the space of all elements of
(in the sense of distributions).
is the space of all elements
of
(with the usual summation conventions) for some tensor
obeying the antisymmetry property
.
- (a) Show that these three spaces are closed subspaces of
This is a simple case of a more general splitting known as the Hodge decomposition, which is available for more general differential forms on manifolds.
- (b) Show that on
.
- (c) Show that the Leray projection is a non-expansive map on
).

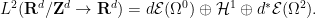
Exercise 17 (Helmholtz decomposition) Define the following two subspaces of the Hilbert space:
is the space of functions
which are divergence-free, by which we mean that
in the sense of distributions.
is the space of functions
in the sense of distributions, where
is the rank two tensor with components
.
- (a) Show that these two spaces are closed subspaces of
This is known as the Helmholtz decomposition (particularly in the three-dimensional case
, in which one can interpret
- (b) Show that on
- (c) Show that the Leray projection is a non-expansive map on
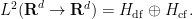
Exercise 18 (Singular integral form of Leray projection) Let. Then the function
is locally integrable and thus well-defined as a distribution.
- (a) For
, show that the distribution
, defined on test functions
by the formula
can be expressed in principal value form as
where
denotes the surface area of the unit sphere
in
is the Kronecker delta.
- (b) Conclude in particular the Newtonian potential identity
where (at the risk of a mild notational clash)
is the Dirac delta distribution at
- (c) For a test vector field
- (d) Extend part (c) to the case
. (Hint: Replace the role of
with
, in the spirit of the replica trick from physics.)



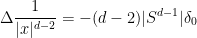
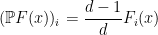

Remark 19 One can also solve (15) inother than
by using Calderón-Zygmund theory and the singular integral form of the Leray projection given in Exercise 18. However, we will try to avoid having to rely on this theory in these notes.
— 3. The heat equation —
We now turn to the study of the heat equation
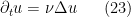
![{[0,T] \times {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) , with initial data , where is a fixed constant; we also consider the inhomogeneous analog
, with initial data , where is a fixed constant; we also consider the inhomogeneous analog 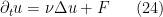
![{F: [0,T] \times {\bf R}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7BF%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Formally, the solution to the initial value problem for (23) should be given by 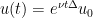
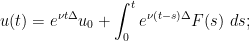 .
.
The first issue is that even if
Exercise 20 (Tychonoff example) Letbe a real number, and let
- (a) Show that there exists smooth, compactly supported function
, not identically zero, obeying the derivative bounds
for all
and
. (Hint: one can construct
as the convolution of an infinite number of approximate identities
, where each
, and use the identity
repeatedly. To justify things rigorously, one may need to first work with finite convolutions and take limits.)
- (b) With
as in part (i) show that the function
is well-defined as a smooth function on
that is compactly supported in time, and obeys the heat equation (23) for
- (c) Show that the initial value problem to (23) is not unique (for any dimension
) if
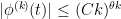
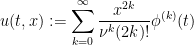
Exercise 21 (Kowalevski example)This classic example, due to Sofia Kowalevski, demonstrates the need for some hypotheses on the PDE in order to invoke the Cauchy-Kowaleski theorem.
- (a) Let
be the function
. Show that there does not exist any solution
to (23) that is jointly real analytic in
at
- (b) Modify the above example by replacing
by a function that extends to an entire function on
(as opposed to
, which has poles at
).
One can recover uniqueness (forwards in time) by imposing some growth condition at infinity. We give a simple example of this, which illustrates a basic tool in the subject, namely the energy method, which is based on understanding the rate of change of various “energy” integrals of integrands which primarily involve quadratic expressions of the solution or its derivatives. The reason for favouring quadratic expressions is that they are more likely to produce integrals with a definite sign (positive definite or negative definite), such as (squares of)
Proposition 22 (Uniqueness with energy bounds) Letbe smooth solutions to (24) with common initial data
and forcing term
such that the norm
of
.
![\displaystyle \| u \|_{L^\infty_t L^2_x([0,T] \times {\bf R} \rightarrow {\bf R}^m)} := \sup_{t \in [0,T]} \|u(t)\|_{L^2({\bf R} \rightarrow {\bf R}^m)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+u+%5C%7C_%7BL%5E%5Cinfty_t+L%5E2_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+%3A%3D+%5Csup_%7Bt+%5Cin+%5B0%2CT%5D%7D+%5C%7Cu%28t%29%5C%7C_%7BL%5E2%28%7B%5Cbf+R%7D+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: As the heat equation (23) is linear, we may subtract 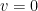

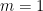
Let 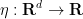
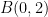
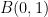
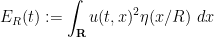 . As
. As  , we have
, we have  . As is smooth and
. As is smooth and  is compactly supported,
is compactly supported, 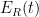 depends smoothly on , and we can differentiate under the integral sign to obtain
depends smoothly on , and we can differentiate under the integral sign to obtain 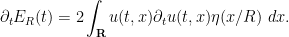
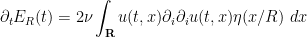
A basic rule of thumb in the energy method is this: whenever one is faced with an integral in which one term in the integrand has much lower regularity (or much less control on regularity) than any other, due to a large number of derivatives placed on that term, one should integrate by parts to move one or more derivatives off of that term to other terms in order to make the distribution of derivatives more balanced (which, as we shall see, tends to make the integrals easier to estimate, or to ascribe a definite sign to). Accordingly, we integrate by parts to write
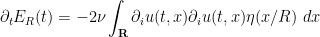
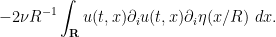
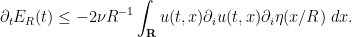

 to conclude
to conclude 
![\displaystyle \partial_t E_R(t) \lesssim_{\nu,\eta} R^{-2} \| u \|_{L^\infty_t L^2_x([0,T] \times {\bf R})}^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cpartial_t+E_R%28t%29+%5Clesssim_%7B%5Cnu%2C%5Ceta%7D+R%5E%7B-2%7D+%5C%7C+u+%5C%7C_%7BL%5E%5Cinfty_t+L%5E2_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%29%7D%5E2+&bg=ffffff&fg=000000&s=0&c=20201002)
 and . Since
and . Since 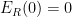 , we conclude from the fundamental theorem of calculus that
, we conclude from the fundamental theorem of calculus that ![\displaystyle E_R(t) \lesssim_{\nu,\eta,T} R^{-2} \| u \|_{L^\infty_t L^2_x([0,T] \times {\bf R})}^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++E_R%28t%29+%5Clesssim_%7B%5Cnu%2C%5Ceta%2CT%7D+R%5E%7B-2%7D+%5C%7C+u+%5C%7C_%7BL%5E%5Cinfty_t+L%5E2_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%29%7D%5E2+&bg=ffffff&fg=000000&s=0&c=20201002) (note how it is important here that we evolve forwards in time, rather than backwards). Sending and using the dominated convergence theorem, we conclude that
(note how it is important here that we evolve forwards in time, rather than backwards). Sending and using the dominated convergence theorem, we conclude that 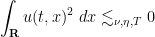 vanishes identically, as required.
vanishes identically, as required.
Now we turn to existence for the heat equation, restricting attention to forward in time solutions. Formally, if one solves the heat equation (23), then on taking spatial Fourier transforms
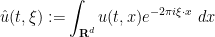
 gives
gives 
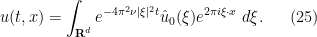 , the exponential factor
, the exponential factor 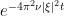 here is bounded. In the case that
here is bounded. In the case that 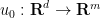 is a Schwartz function, then
is a Schwartz function, then  is also Schwartz, and this formula is certainly well-defined to be smooth in both time and space (and rapidly decreasing in space for any fixed time), and in particular in
is also Schwartz, and this formula is certainly well-defined to be smooth in both time and space (and rapidly decreasing in space for any fixed time), and in particular in  ; one can easily justify differentiation under the integral sign to conclude that (23) is indeed verified, and the Fourier inversion formula shows that we have the initial data condition . So this is the unique solution to the initial value problem (23) for the heat equation that lies in
; one can easily justify differentiation under the integral sign to conclude that (23) is indeed verified, and the Fourier inversion formula shows that we have the initial data condition . So this is the unique solution to the initial value problem (23) for the heat equation that lies in  . By definition we declare the right-hand side of (25) to be
. By definition we declare the right-hand side of (25) to be  , thus
, thus  and all Schwartz functions ; equivalently, one has
and all Schwartz functions ; equivalently, one has  , as discussed for instance in this previous blog post, but we will not do so here since the Fourier transform is available as a substitute.) It is also clear from (27) that
, as discussed for instance in this previous blog post, but we will not do so here since the Fourier transform is available as a substitute.) It is also clear from (27) that 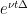 commutes with other Fourier multipliers such as or constant-coefficient differential operators, on Schwartz functions at least.
commutes with other Fourier multipliers such as or constant-coefficient differential operators, on Schwartz functions at least.
From (27) and Plancherel’s theorem we see that 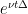
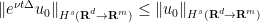
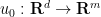 and any
and any 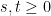 . Thus by density one can extend the heat propagator for to all of , in a fashion that is a non-expansive map on and more generally on . By a limiting argument, (27) holds almost everywhere for all
. Thus by density one can extend the heat propagator for to all of , in a fashion that is a non-expansive map on and more generally on . By a limiting argument, (27) holds almost everywhere for all 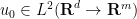 .
.
There is also a smoothing effect:
Exercise 23 (Smoothing effect) Let. Show that
for all
and
.
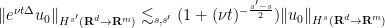
Exercise 24 (Fundamental solution for the heat equation) For, establish the identity
for almost every
is smooth for any
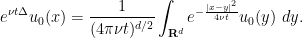
Exercise 25 (Ill-posedness of the backwards heat equation) Show that there exists a Schwartz functionwith the property that there is no solution
to (23) with final data
. (Hint: choose
Exercise 26 (Continuity in the strong operator topology) For anydenote the Banach space of functions
such that for each
and varies continuously and boundedly in
Show that if
and
, then
with
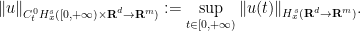
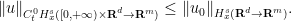
Similar considerations apply to the inhomogeneous heat equation (24). If ![{F: [0,T] \times {\bf R}^d \rightarrow {\bf R}^m}](https://s0.wp.com/latex.php?latex=%7BF%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{u: [0,T] \times {\bf R}^d \rightarrow {\bf R}^m}](https://s0.wp.com/latex.php?latex=%7Bu%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%7D&bg=ffffff&fg=000000&s=0&c=20201002)
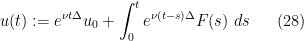 ; by Proposition 22, this is the only such solution in
; by Proposition 22, this is the only such solution in ![{L^\infty_t L^2_x([0,T] \times {\bf R}^d \rightarrow {\bf R}^m)}](https://s0.wp.com/latex.php?latex=%7BL%5E%5Cinfty_t+L%5E2_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) . It also obeys good estimates:
. It also obeys good estimates:
Exercise 27 (Energy estimates) Letbe Schwartz functions for some
with initial condition
in two different ways:
Here of course we are using the norms
- (i) By using the Fourier representation (27) and Plancherel’s formula;
- (ii) By using energy methods as in the proof of Proposition 22. (Hint: first reduce to the case
. You may find the arithmetic mean-geometric mean inequality
to useful.)
and
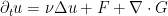
![\displaystyle \| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d\rightarrow {\bf R})} + \nu^{1/2} \| \nabla u \|_{L^2_t H^s_x([0,T] \times {\bf R}^d\rightarrow {\bf R})} \ \ \ \ \ (29)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09+%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%29%7D+%2B+%5Cnu%5E%7B1%2F2%7D+%5C%7C+%5Cnabla+u+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%29%7D+%09%5C+%5C+%5C+%5C+%5C+%2829%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim \|u_0\|_{H^s_x({\bf R}^d \rightarrow {\bf R})} + \| F \|_{L^1_t H^s_x([0,T] \times {\bf R}^d\rightarrow {\bf R})}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Clesssim+%5C%7Cu_0%5C%7C_%7BH%5Es_x%28%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%29%7D+%2B+%5C%7C+F+%5C%7C_%7BL%5E1_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + \nu^{-1/2} \| G \|_{L^2_t H^s_x([0,T] \times {\bf R}^d\rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%2B+%5Cnu%5E%7B-1%2F2%7D+%5C%7C+G+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%09&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| F \|_{L^1_t H^s_x([0,T] \times {\bf R}^d \rightarrow {\bf R}^m)} := \int_{[0,T]} \| F(t) \|_{H^s({\bf R}^d \rightarrow {\bf R}^m)}\ dt](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+F+%5C%7C_%7BL%5E1_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+%3A%3D+%5Cint_%7B%5B0%2CT%5D%7D+%5C%7C+F%28t%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D%5C+dt&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| G \|_{L^2_t H^s_x([0,T] \times {\bf R}^d \rightarrow {\bf R}^m)} := (\int_{[0,T]} \| G(t) \|_{H^s({\bf R}^d \rightarrow {\bf R}^m)}^2\ dt)^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+G+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+%3A%3D+%28%5Cint_%7B%5B0%2CT%5D%7D+%5C%7C+G%28t%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D%5E2%5C+dt%29%5E%7B1%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The energy estimate contains some smoothing effects similar (though not identical) to those in Exercise 23, since it shows that 
Exercise 28 (Distributional solution) Let, and let
for some
be given by the Duhamel formula (28). Show that (24) is true in the spacetime distributional sense, or more precisely that
in the sense of spacetime distributions for any test function
supported in the interior of

Pretty much all of the above discussion can be extended to the periodic setting:
Exercise 29 Letand
.
- (a) If
is smooth, define
by the formula
where
are the Fourier coefficients of
then the function
lies in
.
- (b) For
and
for almost every
with
in the usual fashion.
- (c) If
, and
are smooth, show that the function
defined by (28) is smooth and solves the inhomogeneous equation (24) with initial data
- (d) If
are smooth, and
with
- (e) If
, show that the function
and obeys (24) in the sense of spacetime distributions (30).

![\displaystyle \| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^m)} + \nu^{1/2} \| \nabla u \|_{L^2_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^m)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+%2B+%5Cnu%5E%7B1%2F2%7D+%5C%7C+%5Cnabla+u+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim \|u_0 \|_{H^s_x({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^m)} + \| F \|_{L^1_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^m)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clesssim+%5C%7Cu_0+%5C%7C_%7BH%5Es_x%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+%2B+%5C%7C+F+%5C%7C_%7BL%5E1_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Em%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + \nu^{-1/2} \| G \|_{L^2_t H^{s}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^{d \times m})}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%2B+%5Cnu%5E%7B-1%2F2%7D+%5C%7C+G+%5C%7C_%7BL%5E2_t+H%5E%7Bs%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5E%7Bd+%5Ctimes+m%7D%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Remark 30 The heat equation for negative viscositiescan be transformed into a positive viscosity heat equation by time reversal: if
, then
solves the equation
. However, we will generally keep the parameter
— 4. Local well-posedness for Navier-Stokes —
We now have all the ingredients necessary to create a local well-posedness theory for the Navier-Stokes equations (1).
We first dispose of the one-dimensional case
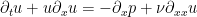
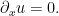 is just a function of time,
is just a function of time,  , and the first equation becomes
, and the first equation becomes 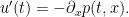
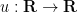 to be an arbitrary smooth function of time, and then set
to be an arbitrary smooth function of time, and then set 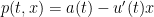
 . If one requires the pressure to be bounded, then
. If one requires the pressure to be bounded, then 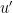 vanishes identically, and then is constant in time, which among other things shows that the initial value problem is (rather trivially) well-posed in the category of smooth solutions, up to the ability to alter the pressure by an arbitrary constant
vanishes identically, and then is constant in time, which among other things shows that the initial value problem is (rather trivially) well-posed in the category of smooth solutions, up to the ability to alter the pressure by an arbitrary constant 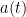 . On the other hand, if one does not require the pressure to stay bounded, then one has a lot less uniqueness, since the function is essentially unconstrained.
. On the other hand, if one does not require the pressure to stay bounded, then one has a lot less uniqueness, since the function is essentially unconstrained.
Now we work in two or higher dimensions 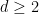
![{u: [0,T] \times {\bf R}^d \rightarrow {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7Bu%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)

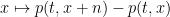
 and some function
and some function 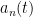 of . The map
of . The map 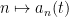 is a homomorphism for fixed , so we can write
is a homomorphism for fixed , so we can write 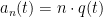 for some
for some ![{a: [0,T] \rightarrow {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7Ba%3A+%5B0%2CT%5D+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which will be smooth since is smooth. We thus have
, which will be smooth since is smooth. We thus have 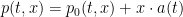 for some smooth -periodic function
for some smooth -periodic function 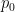 . By subtracting off the mean, we can further decompose
. By subtracting off the mean, we can further decompose 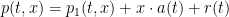
![{r: [0,T] \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Br%3A+%5B0%2CT%5D+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and some smooth -periodic function
and some smooth -periodic function ![{p_1: [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bp_1%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) which has mean zero at every time.
which has mean zero at every time.
Note that one can simply omit the constant term 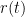



 , and
, and 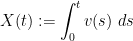 , then a short calculation reveals that the smooth function
, then a short calculation reveals that the smooth function ![{u_2: [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7Bu_2%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) defined by
defined by 
![{p_2: [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bp_2%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) defined by
defined by 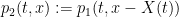
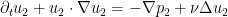
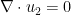
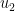 having the same initial data as ; conversely, if
having the same initial data as ; conversely, if 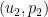 is a solution to Navier-Stokes, then so is . In particular this reveals a lack of uniqueness for the periodic Navier-Stokes equations that is essentially the same lack of uniqueness that is present for the Leray system: one can add an arbitrary spatially affine function to the pressure by applying a suitable Galilean transform to . On the other hand, we can eliminate this lack of uniqueness by requiring that the pressure be normalised in the sense that
is a solution to Navier-Stokes, then so is . In particular this reveals a lack of uniqueness for the periodic Navier-Stokes equations that is essentially the same lack of uniqueness that is present for the Leray system: one can add an arbitrary spatially affine function to the pressure by applying a suitable Galilean transform to . On the other hand, we can eliminate this lack of uniqueness by requiring that the pressure be normalised in the sense that 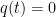 and
and  , that is to say we require to be -periodic and mean zero. The above discussion shows that any smooth solution to Navier-Stokes with periodic can be transformed by a Galilean transformation to one in which the pressure is normalised.
, that is to say we require to be -periodic and mean zero. The above discussion shows that any smooth solution to Navier-Stokes with periodic can be transformed by a Galilean transformation to one in which the pressure is normalised.
Once the pressure is normalised, it turns out that one can recover uniqueness (much as was the case with the Leray system):
Theorem 31 (Uniqueness with normalised pressure) Letbe two smooth periodic solutions to (1) on
. Then
.
Proof: We use the energy method. Write 

![{w: [0,T] \times {\bf R}^d \rightarrow {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7Bw%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)

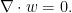
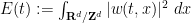 . This varies smoothly with , and we can differentiate under the integral sign to obtain
. This varies smoothly with , and we can differentiate under the integral sign to obtain 
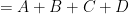
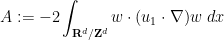
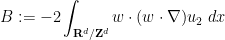
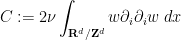
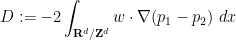 and for brevity.
and for brevity.
For 

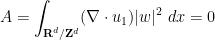
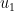 is divergence-free. Similarly, integration by parts shows that
is divergence-free. Similarly, integration by parts shows that  vanishes since
vanishes since  is divergence-free. Another integration by parts gives
is divergence-free. Another integration by parts gives 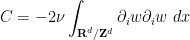
 . Finally, from Hölder’s inequality we have
. Finally, from Hölder’s inequality we have ![\displaystyle B \leq 2 E(t) \|\nabla u_2 \|_{L^\infty_t L^\infty_x([0,T] \times {\bf R}^d/{\bf Z}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++B+%5Cleq+2+E%28t%29+%5C%7C%5Cnabla+u_2+%5C%7C_%7BL%5E%5Cinfty_t+L%5E%5Cinfty_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \partial_t E(t) \leq 2 E(t) \|\nabla u_2 \|_{L^\infty_t L^\infty_x([0,T] \times {\bf R}^d/{\bf Z}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cpartial_t+E%28t%29+%5Cleq+2+E%28t%29+%5C%7C%5Cnabla+u_2+%5C%7C_%7BL%5E%5Cinfty_t+L%5E%5Cinfty_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
 , we conclude from Gronwall’s inequality that
, we conclude from Gronwall’s inequality that 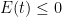 for all , and hence is identically zero, thus
for all , and hence is identically zero, thus  . Substituting this into (1) we conclude that
. Substituting this into (1) we conclude that  ; as
; as 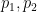 have mean zero, we conclude (e.g., from Fourier inversion) that
have mean zero, we conclude (e.g., from Fourier inversion) that  , and the claim follows.
, and the claim follows.
Now we turn to existence in the periodic setting, assuming normalised pressure. For various technical reasons, it is convenient to reduce to the case when the velocity field 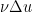

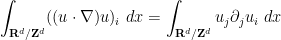

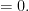
 is a conserved integral of motion: if
is a conserved integral of motion: if  is the mean initial velocity, and is a solution to (1) (obeying some minimal regularity hypothesis), then continues to have mean velocity for all subsequent times. On the other hand, if is a smooth periodic solution to (1) with normalised pressure and initial velocity , then the Galilean transform
is the mean initial velocity, and is a solution to (1) (obeying some minimal regularity hypothesis), then continues to have mean velocity for all subsequent times. On the other hand, if is a smooth periodic solution to (1) with normalised pressure and initial velocity , then the Galilean transform 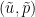 defined by
defined by 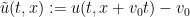

 . Of course, one can reconstruct from
. Of course, one can reconstruct from  by the inverse tranformation
by the inverse tranformation 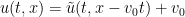
 is equivalent to that of
is equivalent to that of  , so we may assume without loss of generality that the initial velocity (and hence the velocity at all subsequent times) has zero mean.
, so we may assume without loss of generality that the initial velocity (and hence the velocity at all subsequent times) has zero mean.
A general rule of thumb is that whenever an integral of a solution to a PDE can be proven to vanish (or be equal to boundary terms) by integration by parts, it is because the integrand can be rewritten in “divergence form” – as the divergence of a tensor of one higher rank. (This is because the integration by parts identity 

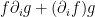

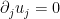 , we thus have from the Leibniz rule that
, we thus have from the Leibniz rule that 
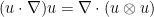
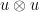 is the tensor product
is the tensor product 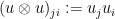 and
and  denotes the divergence
denotes the divergence 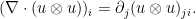
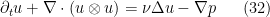
Next, we observe that we can use the Leray projection operator 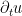
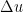
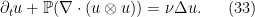
![{u: [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d}](https://s0.wp.com/latex.php?latex=%7Bu%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) to (33) with initial condition for some smooth periodic divergence-free vector field
to (33) with initial condition for some smooth periodic divergence-free vector field 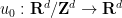 . Taking divergences of both sides of (33), we then conclude that
. Taking divergences of both sides of (33), we then conclude that 
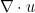 obeys the heat equation (23). Since is periodic, smooth, and vanishes at , we see from Exercise 29(c) that vanishes on all of
obeys the heat equation (23). Since is periodic, smooth, and vanishes at , we see from Exercise 29(c) that vanishes on all of ![{[0,T] \times {\bf R}^d/{\bf Z}^d}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002) , thus is divergence free on the entire time interval . From (33) and (22) we thus see that if one defines
, thus is divergence free on the entire time interval . From (33) and (22) we thus see that if one defines ![{p: [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bp%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to be the function
to be the function  is a smooth periodic solution to (1) with normalised pressure and initial condition (and is thus the unique solution to this system, thanks to Theorem 31). Thus, the problem of finding a smooth solution to (1) in the smooth periodic setting with normalised pressure and divergence-free initial data is equivalent to that of solving (33) with the same initial data.
is a smooth periodic solution to (1) with normalised pressure and initial condition (and is thus the unique solution to this system, thanks to Theorem 31). Thus, the problem of finding a smooth solution to (1) in the smooth periodic setting with normalised pressure and divergence-free initial data is equivalent to that of solving (33) with the same initial data.
By Duhamel’s formula (Exercise 29(c)), any smooth solution

 is sometimes referred to as the Oseen operator in the literature.) Conversely, a smooth solution to (34) will solve the initial value problem (33) with initial data .
is sometimes referred to as the Oseen operator in the literature.) Conversely, a smooth solution to (34) will solve the initial value problem (33) with initial data .
To obtain existence of smooth periodic solutions (with normalised pressure) to the Navier-Stokes equations with given smooth divergence-free periodic initial data
- (i) (Existence at finite regularity) Construct a solution
- (ii) (Propagation of regularity) show that if
The reason for this two step procedure is that one wishes to solve (34) using iteration-type methods (which for instance power the contraction mapping theorem that was used to prove the Picard existence theorem); however the function space ![{C^\infty([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%7BC%5E%5Cinfty%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{C([0,T] \rightarrow \overline{B(0,2R)})}](https://s0.wp.com/latex.php?latex=%7BC%28%5B0%2CT%5D+%5Crightarrow+%5Coverline%7BB%280%2C2R%29%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Of course, to run this procedure, one actually has to write down an explicit function space in which one will perform the iteration argument. Selection of this space is actually a non-trivial matter and often requires a substantial amount of trial and error, as well as experience with similar iteration arguments for other PDE. Often one is guided by the function space theory for the linearised counterpart of the PDE, which in this case is the heat equation (23). As such, the following definition can be at least partially motivated by the energy estimates in Exercise 29(d).
Definition 32 (Mild solution) Letbe divergence-free, where
denotes the subspace of
-mild solution (or Fujita-Kato mild solution to the Navier-Stokes equations with initial data
that obeys the integral equation (34) (in the sense of distributions) for all
if it is a mild solution on
.
![\displaystyle u \in C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++u+%5Cin+C%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \cap L^2_t H^{s+1}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ccap+L%5E2_t+H%5E%7Bs%2B1%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0+&bg=ffffff&fg=000000&s=0&c=20201002)
Remark 33 The definition of a mild solution could be extended to those choices of initial data
Note that the regularity on 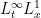
Exercise 34 (Splitting) Letbe divergence-free, and let
Let
. Show that the following are equivalent:
- (i)
- (ii)
is an
with initial data
defined by
is an
.
![\displaystyle u \in C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+u+%5Cin+C%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \cap L^2_t H^{s+1}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ccap+L%5E2_t+H%5E%7Bs%2B1%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0.&bg=ffffff&fg=000000&s=0&c=20201002)
To use this notion of a mild solution, we will need the following harmonic analysis estimate:
Proposition 35 (Product estimate) Let. Then one has
, with the estimate
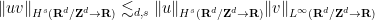

When 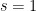
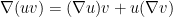
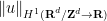



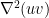
We also need a simple case of Sobolev embedding:
Exercise 36 (Sobolev embedding)
- (a) If
, show that for any
, one has
with
- (b) Show that the inequality fails at
.
- (c) Establish the same statements with
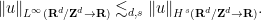
In particular, combining this exercise with Proposition 35 we see that for 
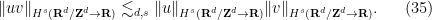
Now we can construct mild solutions at high regularities
Theorem 37 (Local well-posedness of mild solutions at high regularity) Letand an

The hypothesis
Proof: We begin with existence. We can write (34) in the fixed point form
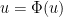
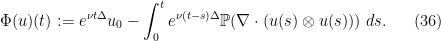 has mean zero. Let
has mean zero. Let 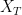 denote the function space
denote the function space ![\displaystyle X_T := C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0 \cap L^2_t H^{s+1}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)^0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++X_T+%3A%3D+C%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0+%5Ccap+L%5E2_t+H%5E%7Bs%2B1%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%5E0+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \|u\|_{X_T} := \| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{1/2} \| u \|_{L^2_t H^{s+1}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_T%7D+%3A%3D+%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B1%2F2%7D+%5C%7C+u+%5C%7C_%7BL%5E2_t+H%5E%7Bs%2B1%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002) , we may estimate
, we may estimate ![\displaystyle \|u\|_{X_T} \lesssim_{s,d} \| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{1/2} \| \nabla u \|_{L^2_t H^{s}_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^{d^2})}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_T%7D+%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B1%2F2%7D+%5C%7C+%5Cnabla+u+%5C%7C_%7BL%5E2_t+H%5E%7Bs%7D_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5E%7Bd%5E2%7D%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Note that if 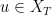
![{u \otimes u \in C^t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^{d^2})}](https://s0.wp.com/latex.php?latex=%7Bu+%5Cotimes+u+%5Cin+C%5Et+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5E%7Bd%5E2%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
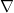
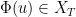
![\displaystyle \| F \|_{L^2_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R})} \leq T^{1/2} \| F \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R})} \ \ \ \ \ (37)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09+%5C%7C+F+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%29%7D+%5Cleq+T%5E%7B1%2F2%7D+%5C%7C+F+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%29%7D+%09%5C+%5C+%5C+%5C+%5C+%2837%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Phi(u) \|_{X_T} \lesssim \|u_0\|_{H^s_x({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} \| \mathbb{P} (u \otimes u) \|_{L^2_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^{d^2})}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CPhi%28u%29+%5C%7C_%7BX_T%7D+%5Clesssim+%09%5C%7Cu_0%5C%7C_%7BH%5Es_x%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+%5C%7C+%5Cmathbb%7BP%7D+%28u+%5Cotimes+u%29+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5E%7Bd%5E2%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim \|u_0\|_{H^s_x({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} T^{1/2} \| u \otimes u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^{d^2})}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Clesssim+%09%5C%7Cu_0%5C%7C_%7BH%5Es_x%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+T%5E%7B1%2F2%7D+%5C%7C+u+%5Cotimes+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5E%7Bd%5E2%7D%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim_{d,s} \|u_0\|_{H^s_x({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} T^{1/2} \| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)}^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Clesssim_%7Bd%2Cs%7D+%09%5C%7Cu_0%5C%7C_%7BH%5Es_x%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+T%5E%7B1%2F2%7D+%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
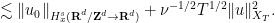
 for a suitably large constant
for a suitably large constant  , and set
, and set  for a sufficienly small constant
for a sufficienly small constant 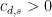 , then maps the closed ball
, then maps the closed ball 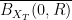 in to itself. Furthermore, for
in to itself. Furthermore, for 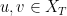 , we have by similar arguments to above
, we have by similar arguments to above ![\displaystyle \| \Phi(u) - \Phi(v) \|_{X_T} \lesssim \nu^{-1/2} \| \mathbb{P} (u \otimes u - v \otimes v) \|_{L^2_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CPhi%28u%29+-+%5CPhi%28v%29+%5C%7C_%7BX_T%7D+%5Clesssim+%5Cnu%5E%7B-1%2F2%7D+%5C%7C+%5Cmathbb%7BP%7D+%28u+%5Cotimes+u+-+v+%5Cotimes+v%29+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim \nu^{-1/2} T^{1/2} \| u \otimes u - v \otimes v\|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clesssim+%5Cnu%5E%7B-1%2F2%7D+T%5E%7B1%2F2%7D+%5C%7C+u+%5Cotimes+u+-+v+%5Cotimes+v%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim_{d,s} \nu^{-1/2} T^{1/2} \| u - v\|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clesssim_%7Bd%2Cs%7D+%5Cnu%5E%7B-1%2F2%7D+T%5E%7B1%2F2%7D+%5C%7C+u+-+v%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle (\| u \|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)} + \| v\|_{C^0_t H^s_x([0,T] \times {\bf R}^d/{\bf Z}^d\rightarrow {\bf R}^d)})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5C%7C+v%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
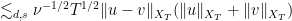
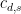 is chosen small enough, is also a contraction (with constant, say,
is chosen small enough, is also a contraction (with constant, say, 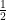 ) on . Thus there exists
) on . Thus there exists  such that
such that  , thus is an mild solution.
, thus is an mild solution.
Now we show that it is the only mild solution. Suppose for contradiction that there is another 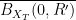
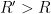
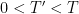


![{[0,T']}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CT%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Iterating this as in the proof of Theorem 8, we have
Theorem 38 (Maximal Cauchy development) Letand an
to (34), such that if
then
as
. Furthermore,
and
In principle, if the initial data
Proposition 39 (Blowup criterion) Letbe as in Theorem 38. If
.
Note from Exercise 36 that ![{\| u \|_{L^\infty_t L^\infty_x([0,T])}}](https://s0.wp.com/latex.php?latex=%7B%5C%7C+u+%5C%7C_%7BL%5E%5Cinfty_t+L%5E%5Cinfty_x%28%5B0%2CT%5D%29%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Proof: Suppose for contradiction that 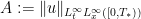

![\displaystyle \|u\|_{X_{[\tau_1,\tau_2]}} := \| u \|_{C^0_t H^s_x([\tau_1,\tau_2] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{1/2} \| u \|_{L^2_t H^{s+1}_x([\tau_1,\tau_2] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D+%3A%3D+%5C%7C+u+%5C%7C_%7BC%5E0_t+H%5Es_x%28%5B%5Ctau_1%2C%5Ctau_2%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B1%2F2%7D+%5C%7C+u+%5C%7C_%7BL%5E2_t+H%5E%7Bs%2B1%7D_x%28%5B%5Ctau_1%2C%5Ctau_2%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002) is a mild solution, this expression is finite.
is a mild solution, this expression is finite.
We adapt the proof of Theorem 37. Using Exercise 29(d) (and Exercise 34) we have
![\displaystyle \|u\|_{X_{[\tau_1,\tau_2]}} \lesssim_{s,d} \| u(\tau_1) \|_{H^s({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} \| \mathbb{P}(u \otimes u) \|_{L^2_t H^s_x([\tau_1,\tau_2] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D+%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u%28%5Ctau_1%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+%5C%7C+%5Cmathbb%7BP%7D%28u+%5Cotimes+u%29+%5C%7C_%7BL%5E2_t+H%5Es_x%28%5B%5Ctau_1%2C%5Ctau_2%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002) and use (a variant of) (37) to conclude
and use (a variant of) (37) to conclude ![\displaystyle \|u\|_{X_{[\tau_1,\tau_2]}} \lesssim_{s,d} \| u(\tau_1) \|_{H^s({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} (\tau_2-\tau_1)^{1/2} \| u \otimes u \|_{L^\infty_t H^s_x([\tau_1,\tau_2] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D+%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u%28%5Ctau_1%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+%28%5Ctau_2-%5Ctau_1%29%5E%7B1%2F2%7D+%5C%7C+u+%5Cotimes+u+%5C%7C_%7BL%5E%5Cinfty_t+H%5Es_x%28%5B%5Ctau_1%2C%5Ctau_2%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \|u\|_{X_{[\tau_1,\tau_2]}} \lesssim_{s,d} \| u(\tau_1) \|_{H^s({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} (\tau_2-\tau_1)^{1/2} A \| u \|_{L^\infty_t H^s_x([\tau_1,\tau_2] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D+%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u%28%5Ctau_1%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+%28%5Ctau_2-%5Ctau_1%29%5E%7B1%2F2%7D+A+%5C%7C+u+%5C%7C_%7BL%5E%5Cinfty_t+H%5Es_x%28%5B%5Ctau_1%2C%5Ctau_2%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \lesssim_{s,d} \| u(\tau_1) \|_{H^s({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \nu^{-1/2} (T_*-\tau_1)^{1/2} A \|u\|_{X_{[\tau_1,\tau_2]}}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u%28%5Ctau_1%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5Cnu%5E%7B-1%2F2%7D+%28T_%2A-%5Ctau_1%29%5E%7B1%2F2%7D+A+%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
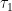 to be sufficiently close to (depending on and ), we can absorb the second term on the RHS into the LHS and conclude that
to be sufficiently close to (depending on and ), we can absorb the second term on the RHS into the LHS and conclude that ![\displaystyle \|u\|_{X_{[\tau_1,\tau_2]}} \lesssim_{s,d} \| u(\tau_1) \|_{H^s({\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_%7B%5B%5Ctau_1%2C%5Ctau_2%5D%7D%7D+%5Clesssim_%7Bs%2Cd%7D+%5C%7C+u%28%5Ctau_1%29+%5C%7C_%7BH%5Es%28%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
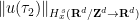 stays bounded as
stays bounded as 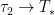 , contradicting Theorem 38.
, contradicting Theorem 38.
Corollary 40 (Existence of smooth solutions) Ifwith normalised pressure such that if
, then
Proof: As discussed previously, we may assume without loss of generality that 
By Exercise 29, one has
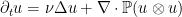
 for every , hence the left-hand side does also; this makes lie in
for every , hence the left-hand side does also; this makes lie in 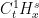 . It is then easy to see that this implies that the right-hand side of the above equation lies in for every , and so now lies in
. It is then easy to see that this implies that the right-hand side of the above equation lies in for every , and so now lies in 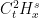 for every . Iterating this (and using Sobolev embedding) we conclude that is smooth in space and time, giving the claim.
for every . Iterating this (and using Sobolev embedding) we conclude that is smooth in space and time, giving the claim.
Remark 41 When
Exercise 42 (Instantaneous smoothing) Let(note the omission of the initial time
). (Hint: first show that
is a
mild solution for arbitrarily small
.)
Exercise 43 (Lipschitz continuous dependence on initial data) Letto the Navier-Stokes equations with initial data
metric for the solution
Now we discuss the issue of relaxing the regularity condition 

Proposition 44 Letand let
. Then the function
defined by the Duhamel formula
also has mean zero for all
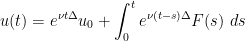
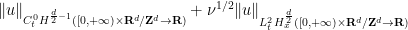
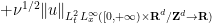
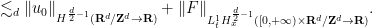
Proof: By Minkowski’s integral inequality, it will suffice to establish the bounds in the case
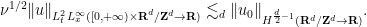
 (and also rescaling
(and also rescaling  ), we may normalise
), we may normalise  . By a limiting argument we may assume without loss of generality that is Schwarz. We cannot directly apply Exercise 36 here due to the failure of endpoint Sobolev embedding; nevertheless we may argue as follows. For any , we see from (31), the mean zero hypothesis, and the triangle inequality that
. By a limiting argument we may assume without loss of generality that is Schwarz. We cannot directly apply Exercise 36 here due to the failure of endpoint Sobolev embedding; nevertheless we may argue as follows. For any , we see from (31), the mean zero hypothesis, and the triangle inequality that 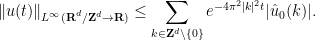
 such that
such that 
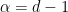 ), and use Cauchy-Schwarz to bound
), and use Cauchy-Schwarz to bound 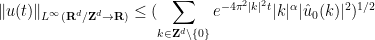

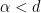 , one has the bound
, one has the bound 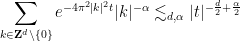
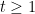 , while for
, while for 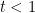 it is easy to bound the LHS by
it is easy to bound the LHS by  ) and hence
) and hence 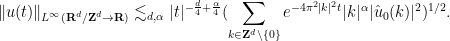
 norms and using Fubini’s theorem, we conclude
norms and using Fubini’s theorem, we conclude 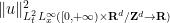
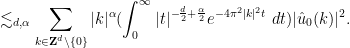
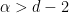 , the inner integral can be estimated as
, the inner integral can be estimated as 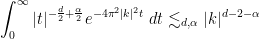
This gives the following small data global existence result, also due to Fujita and Kato:
Theorem 45 (Small data global existence) Suppose thatis divergence-free with norm at most
, where
is a sufficiently small constant depending only on
. Furthermore, if
Proof: By working with the rescaled function 

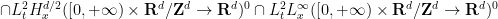
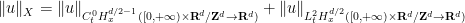
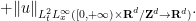 be the Duhamel operator (36). If , then by Proposition 44 and Lemma 35 one has
be the Duhamel operator (36). If , then by Proposition 44 and Lemma 35 one has 

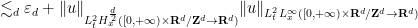
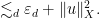 maps to . A similar argument establishes the bound
maps to . A similar argument establishes the bound  . For
. For  small enough, will be a contraction on
small enough, will be a contraction on 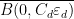 for some absolute constant depending only on , and hence has a fixed point which will be the desired mild solution.
for some absolute constant depending only on , and hence has a fixed point which will be the desired mild solution.
Now suppose that
![\displaystyle \|u\|_{X_T} = \|u\|_{C^0_t H^{d/2-1}_x( [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \|u\|_{L^2_t H^{d/2}_x( [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX_T%7D+%3D+%5C%7Cu%5C%7C_%7BC%5E0_t+H%5E%7Bd%2F2-1%7D_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5C%7Cu%5C%7C_%7BL%5E2_t+H%5E%7Bd%2F2%7D_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + \|u\|_{L^2_t L^\infty_x( [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%2B+%5C%7Cu%5C%7C_%7BL%5E2_t+L%5E%5Cinfty_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)

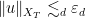 or
or  . On the other hand,
. On the other hand, 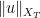 depends continuously on and converges to
depends continuously on and converges to  as
as 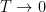 . For small enough, this implies that for all (this is an example of a “continuity argument”). Next, if we set
. For small enough, this implies that for all (this is an example of a “continuity argument”). Next, if we set ![\displaystyle \|u\|_{X^s_T} = \|u\|_{C^0_t H^{s}_x( [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)} + \|u\|_{L^2_t H^{s+1}_x( [0,T] \times {\bf R}^d/{\bf Z}^d \rightarrow {\bf R}^d)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7Cu%5C%7C_%7BX%5Es_T%7D+%3D+%5C%7Cu%5C%7C_%7BC%5E0_t+H%5E%7Bs%7D_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+%2B+%5C%7Cu%5C%7C_%7BL%5E2_t+H%5E%7Bs%2B1%7D_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed%2F%7B%5Cbf+Z%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
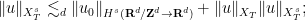
 is finite and , we conclude (for small enough) that
is finite and , we conclude (for small enough) that 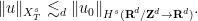
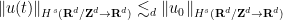
 , and hence by Theorem 38 we have
, and hence by Theorem 38 we have  . The argument used to prove Corollary 40 shows that is smooth. From the bounds on we see that, lies in with norm at most
. The argument used to prove Corollary 40 shows that is smooth. From the bounds on we see that, lies in with norm at most  , and so agrees with the fixed point of located previously. The claim follows.
, and so agrees with the fixed point of located previously. The claim follows.
Remark 46 Modifications of this argument also allow one to establish local existence of, but has large norm rather than norm less than
. See the paper of Fujita and Kato for details.
Exercise 47 (Large data critical local existence) Suppose thatis small in
and
norms. Now run a contraction mapping argument in a space of functions
norm. One will have to carefully choose all the relevant parameters in the right order, and to choose an appropriate weighted metric on this space of functions, in order to actually obtain a contraction.
We now turn attention to the non-periodic case in two and higher dimensions
In the periodic case, we focused initially on smooth solutions. Smoothness is not sufficient by itself in the non-periodic setting to provide a good well-posedness theory, as we already saw in Section 3 when discussing the linear heat equation; some additional decay at spatial infinity is needed. There is some flexibility as to how much smoothness to prescribe. Let us say that a solution ![{p: [0,T] \times {\bf R}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bp%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{C^0_t H^s_x( [0,T] \times {\bf R}^d \rightarrow {\bf R}^d )}](https://s0.wp.com/latex.php?latex=%7BC%5E0_t+H%5Es_x%28+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%5Ed+%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now we work on normalising the pressure. Suppose
 belongs to
belongs to  for every , so if we define the normalised pressure
for every , so if we define the normalised pressure 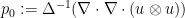
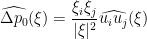 will also belong to for every . We then have
will also belong to for every . We then have  for some harmonic function
for some harmonic function ![{h: [0,T] \times {\bf R}^d \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bh%3A+%5B0%2CT%5D+%5Ctimes+%7B%5Cbf+R%7D%5Ed+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that is smooth in space and continuous in time (thus all spatial derivatives exist and are continuous in both space and time). To control this harmonic function, we return to (32), which we write as
that is smooth in space and continuous in time (thus all spatial derivatives exist and are continuous in both space and time). To control this harmonic function, we return to (32), which we write as 


 (in fact it is in for every ), hence both sides vanish. By the fundamental theorem of calculus this implies that
(in fact it is in for every ), hence both sides vanish. By the fundamental theorem of calculus this implies that 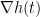 vanishes identically, thus
vanishes identically, thus  is constant in space. One can then subtract it from the pressure without affecting (1); also, we now have
is constant in space. One can then subtract it from the pressure without affecting (1); also, we now have 
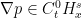 for all , which by the Navier-Stokes equations implies that
for all , which by the Navier-Stokes equations implies that 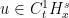 for all ; iterating this we find eventually that all time derivatives of exist in
for all ; iterating this we find eventually that all time derivatives of exist in  , and hence is smooth. Thus, in the category of classical solutions, at least, we may assume without loss of generality that we have normalised pressure
, and hence is smooth. Thus, in the category of classical solutions, at least, we may assume without loss of generality that we have normalised pressure 
Exercise 48 (Uniqueness with normalised pressure) Let
We can now define the notion of a Fujita-Kato
Exercise 49 Establish an analogue of Proposition 44 ondefined to be the closure of the Schwartz functions
with respect to the norm
and use this to state and prove an analogue of Theorem 45.
— 5. Heuristics —
There are several further extensions of these types of local and global existence results for smooth solutions, in which the role of the Sobolev spaces 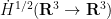



Rather tham detail these other results, let us present instead a scaling heuristic which can be used to interpret these results (and can clarify why all the positive well-posedness results discussed here involve either “subcritical” or “critical” function spaces, rather than “supercritical” ones). For simplicity we restrict our discussion to the non-periodic setting 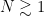

In this heuristic discussion, we assume that any given time 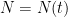

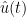
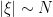
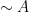

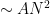

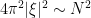

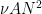
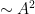

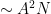
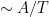
This leads to the following heuristics:
- If
(or equivalently if
), then the viscosity term
, so the natural time scale here is
.
- If
(or equivalently if
), then nonlinear effects dominate, and the behaviour is likely to be quite different to that of the heat equation. One now expects
, so the natural time scale here is
. In particular, one could theoretically have blowup or other bad behaviour after this time scale.
As a general rule of thumb, the known well-posedness theory for the Navier-Stokes equation is only applicable when the hypotheses on the initial data (and on the timescale being considered) is compatible either with the viscosity-dominated regime 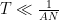
Let’s discuss some of the results in this set of notes using these heuristics. Suppose we are given that the initial data 
 exhibits some amplitude and frequency . Heuristically, the norm of should resemble
exhibits some amplitude and frequency . Heuristically, the norm of should resemble 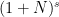 times the norm of , which should be roughly
times the norm of , which should be roughly  , where is the volume of the region where is concentrated in. Thus we morally have a bound of the form
, where is the volume of the region where is concentrated in. Thus we morally have a bound of the form 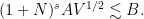
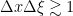 , which indicates that the data should be spatially spread out at a scale of at least the wavelength , which implies that the volume should be at least
, which indicates that the data should be spatially spread out at a scale of at least the wavelength , which implies that the volume should be at least 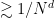 . Thus we have
. Thus we have 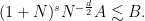
 , then we have the crude bound
, then we have the crude bound 
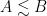 . If we are in the nonlinear regime , this implies that
. If we are in the nonlinear regime , this implies that  , and so the natural time scale here is lower bounded by
, and so the natural time scale here is lower bounded by 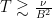 . This matches up with the local existence time given in Theorem 37 (or the non-periodic analogue of this theorem). However, the use of the crude bound (39) suggests that one can make improvements to this bound when is far from
. This matches up with the local existence time given in Theorem 37 (or the non-periodic analogue of this theorem). However, the use of the crude bound (39) suggests that one can make improvements to this bound when is far from 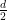 :
:
Exercise 50 If, make a heuristic argument as to why the optimal lower bound for the time of existence

In a similar spirit, suppose we have the smallness hypothesis
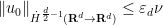
 , then a similar analysis to above leads to
, then a similar analysis to above leads to 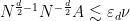 if is small enough, regardless of what time scale one uses; this is consistent with the global existence result in Theorem 45. On the other hand, if the norm is much larger than , then can be larger than
if is small enough, regardless of what time scale one uses; this is consistent with the global existence result in Theorem 45. On the other hand, if the norm is much larger than , then can be larger than 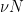 , and we can fail to be in the viscosity dominated regime at any choice of frequency ; setting to be a large multiple of and sending to infinity, we see that the natural time scale could be arbitrarily small.
, and we can fail to be in the viscosity dominated regime at any choice of frequency ; setting to be a large multiple of and sending to infinity, we see that the natural time scale could be arbitrarily small.
Finally, if one only controls a supercritical norm such as 
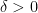
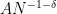
Exercise 51 Discuss the product estimate in Proposition 35, the Sobolev estimate in Exercise 36, and the energy estimates in Exercise 29(d) and Proposition 44 using the above heuristics.
Remark 52 These heuristics can also be used to locate errors in many purported solutions to the Navier-Stokes global regularity problem that proceed through a sequence of estimates on a Navier-Stokes solution. At some point, the estimates have to rule out the scenario that the solution
The above heuristics are closely tied to the classification of various function space norms as being “subcritical”, “supercritical”, or “critical”. Roughly speaking, a norm is subcritical if bounding that norm heuristically places one in the linear-dominated regime (which, for Navier-Stokes, is the viscosity-dominated regime) at high frequencies; critical if control of the norm very nearly places one in the linear-dominated regime at high frequencies; and supercritical if control of the norm completely fails to place one in the linear-dominated regime at high frequencies. When the equation in question enjoys a scaling symmetry, the distinction between subcritical, supercritical, and critical norms can be made by seeing how the the top-order component of these norms vary with respect to scaling a function to be high frequency. In the case of the Navier-Stokes equations (1), the scaling 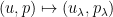
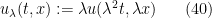
 similarly being scaled to
similarly being scaled to 
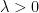 is a scaling parameter; as
is a scaling parameter; as  , the functions
, the functions 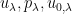 are being sent to increasingly fine scales (i.e., high frequencies). One easily checks that if solves the Navier-Stokes equations (1) with initial data , then
are being sent to increasingly fine scales (i.e., high frequencies). One easily checks that if solves the Navier-Stokes equations (1) with initial data , then 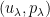 solves the same equations with initial data
solves the same equations with initial data  ; similarly for other formulations of the Navier-Stokes equations such as (33) or (34). (In terms of the parameters
; similarly for other formulations of the Navier-Stokes equations such as (33) or (34). (In terms of the parameters  from the previous heuristic discussion, this scaling corresponds to the map
from the previous heuristic discussion, this scaling corresponds to the map 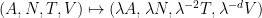 .)
.)
Typically, if one considers a function space norm of 

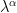

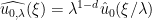
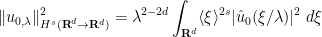
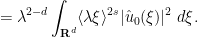 , this expression behaves like
, this expression behaves like  to top order; hence the norm is subcritical when , supercritical when
to top order; hence the norm is subcritical when , supercritical when  , and critical when
, and critical when 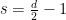 .
.
Another way to phrase this classification is to use dimensional analysis. If we use 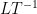


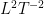
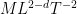

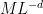
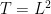
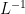


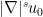
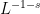


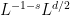
— 6. Appendix: some Littlewood-Paley theory —
We now prove Proposition 35. By a limiting argument it suffices to establish the claim for smooth 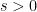
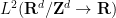
We use the technique of Littlewood-Paley projections. Let 

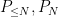

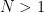 )
) 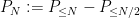
 is always understood to be restricted to be a dyadic integer.
is always understood to be restricted to be a dyadic integer.
The key point of this decomposition is that the
Exercise 53 (Basic Littlewood-Paley estimates)
- (a) For any dyadic integer
where
is the inverse Fourier transform of
between the coset
and the shift
is defined in the obvious fashion. In particular if
and
. Conclude the Bernstein inequality
for all smooth functions
, all
and
; in particular
(Recall our convention that constants that depend on
- (b) For any
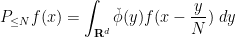
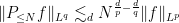


Remark 54 The more advanced Littlewood-Paley inequality, which is usually proven using the Calderón-Zygmund theory of singular integrals, asserts thatfor any
. However, we will not use this estimate here.

We return now to the proof of Proposition 35. Let


The estimate (42) follows by dropping 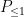

The basic strategy here is to split the product 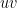

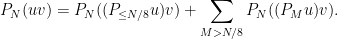

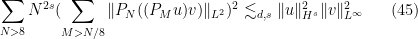
We begin with (44). We can expand further
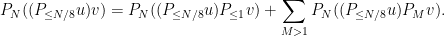
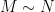 . Thus
. Thus 


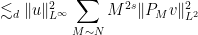 , interchanging the summations, and using Exercise 53. Now we prove (45). We bound
, interchanging the summations, and using Exercise 53. Now we prove (45). We bound 

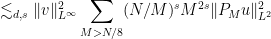 , interchanging the summations, and using Exercise 53.
, interchanging the summations, and using Exercise 53.
There is an essentially identical theory in the non-periodic setting, in which the role of smooth periodic functions are now replaced by Schwartz functions, the Littlewood-Paley projections
 is defined as before.
is defined as before.
Exercise 55 (Non-periodic Littlewood-Paley theory) With
In particular, one obtains the non-periodic analogue of Proposition 35 by repeating the proof verbatim.

92 comments
Comments feed for this article
18 April, 2021 at 1:44 am
Anonymous
I think it seems that Lemma 1 does not need to assume u_0 and u is positive?
[Fair enough; I’ve adjusted the statement appropriately. -T]
23 April, 2021 at 10:15 pm
Ning
Dear Prof. Tao,
In the Part 2 – Leray system of your notes, you said that Fourier transform tends to diagonalize linear translation-invariant equations, because the plane waves $x \mapsto e^{2\pi i k \cdot x}$ that underlie the Fourier transform are the eigenfunctions of translation.
I understood the rigorous proof below, but I did not understand this intuitive insights you presented here. I believe I have seen analogous idea in Sturm-Liouville problem. But I’m wondering what you mean by saying that ‘diagonalize linear translation-invariant equation’? I thought you used the fact that since $e^{2\pi i k \cdot x}$ are the complete eigenbasis of translation in L^2, so they are also eigenbasis for linear translation-invariant operators?
But I’m still confused about this. Could you further explain this? Thanks!
26 April, 2021 at 8:54 am
Terence Tao
Heuristically speaking, a linear operator should be diagonalised by its eigenvectors (there are subtleties if the operator is not normal, but let us ignore this issue for now). Also heuristically speaking, commuting linear operators should have the same bases of eigenvectors (again, there are subtleties when the eigenvalues have multiplicity, but we will ignore this). Since translation has the plane waves as an eigenbasis, these two heuristics predict that any other translation-invariant operator is diagonalised by the plane wave basis. And indeed on taking Fourier transforms, any (reasonable) translation-invariant operator becomes a multiplier operator, which is the continuous version of the operation of multiplying by a diagonal matrix.
28 April, 2021 at 5:37 am
Ning
Thanks for your reply! It makes sense to me now.
24 April, 2021 at 10:07 pm
Ning
Between equation (22) and Remark 15, there is a typo in ‘hence also in the classical sense since {p,F} have rapidly decreasing Fourier transforms and are thus smooth.’
I think it may be instead, and the reason for smoothness may be easier to understand in my view as following:
instead, and the reason for smoothness may be easier to understand in my view as following:
 is in
is in  for any multi-index
for any multi-index  in the setting
in the setting 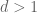 , instead of ‘rapidly decreasing’ since I think
, instead of ‘rapidly decreasing’ since I think  is not in
is not in 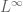 , i.e.
, i.e.  case for rapid decreasing. And actually I’m confused about what does it mean by ‘rapid decreasing of a tempered distribution’.
case for rapid decreasing. And actually I’m confused about what does it mean by ‘rapid decreasing of a tempered distribution’.
Maybe my idea is stupid, but I think it is indeed another way to think about this?
[Text clarified – T.]
25 May, 2021 at 7:50 am
Ning
The paragraph between Remark 33 and Exercise 34 says that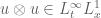 is more than enough regularity to make sense of the right-hand side of (34) in a distributional sense at least.
is more than enough regularity to make sense of the right-hand side of (34) in a distributional sense at least.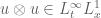 , but how could I verify that RHS of (34) is indeed a well-defined distribution?
, but how could I verify that RHS of (34) is indeed a well-defined distribution?
I got stuck here, there are too many operators here. I knew how
Thanks!
[Verify that the adjoint of the operator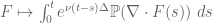 maps test functions to bounded functions. -T]
maps test functions to bounded functions. -T]
27 May, 2021 at 8:54 am
Ning
Thanks for your reply. I think I have know what is the right way to prove this but I want to make sure this is correct. with a test function
with a test function  , then use the form of heat propagator on torus which analogous to that in exercise 24, which allows us to estimate
, then use the form of heat propagator on torus which analogous to that in exercise 24, which allows us to estimate 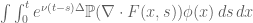 by Young’s inequality for convolution, and then use the symmetry and non-expansive property of
by Young’s inequality for convolution, and then use the symmetry and non-expansive property of  to conclude that it is bounded by
to conclude that it is bounded by 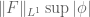 , which verifies that it is a distribution.
, which verifies that it is a distribution.
So actually I think we do not need to calculate an explicit formula for the adjoint, but we use the adjoint to define the distribution in the way similar to the definition of the distributional derivative. We pair
28 May, 2021 at 3:20 am
Ning
In exercise 29(d), I think the assumption should be G:[0,T] \times {\mathbb R}^d/{\mathbb Z}^d \rightarrow {\mathbb R}^{m^2}, and \nabla G should be changed to \nabla\cdot G. Otherwise, the dimension is not consistent.
[Corrected, thanks – T.]
6 June, 2021 at 3:15 am
Ning
Some typos and some points that confused me.
1.In the second line of the proof of Proposition 44, RHS should be LHS.
2.In the proof of Theorem 45, in first the formula to established the bound for \Phi u, \cdot should be \otimes
3.In the third line of the proof of the smooth case in Theorem 45,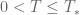 should be
should be 
4.Also in the proof of this smooth case, you missed the subsript 0 of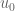 in the norm below
in the norm below
` depends continuously on
depends continuously on  and converges to
and converges to 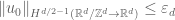 as
as  .'
.'
5.And I think the order in this proof for the smooth case should be reversed somehow.
You may first argue , then conclude that
, then conclude that 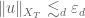 for all
for all  , then
, then  .
.
Instead of putting the argument of to the last.
to the last.
6.In this proof, you use many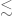 symbols. I think maybe writing these constants explicitly will be more safe for me.You said
symbols. I think maybe writing these constants explicitly will be more safe for me.You said
In particular, {u} lies in {X} with norm {O(C_d \varepsilon_d)}, and so agrees with the fixed point of {\Phi} located previously.
I am confused about why only the big O notation could tells us one agrees with another. Instead, I think we should calculate the constants carefully and find that there is a smaller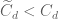 such that
such that  .(After writing out the constants carefully, I found this is the case, but I want to know how could you know only from the big O notation here?)
.(After writing out the constants carefully, I found this is the case, but I want to know how could you know only from the big O notation here?)
7.I'm curious what is it mean by having a dot on in the formulas just below the Exercise 50?
in the formulas just below the Exercise 50?
8.In the last three line of Part 5, the heuristics part, the unit of of
of  , not
, not 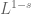
If you could reply when you are free, I will be very happy!
7 June, 2021 at 3:10 pm
Terence Tao
Thanks for the corrections. was a typo, it should have been “at most
was a typo, it should have been “at most  .
.
The dot notation was defined in Exercise 49.
I do not think there is an easy way to jump straight to establishing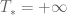 in the small data theory without first obtaining estimates on
in the small data theory without first obtaining estimates on  and
and  norms for various
norms for various  . In particular one does not know a priori that the
. In particular one does not know a priori that the 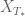 or
or  norms are finite.
norms are finite.
8 June, 2021 at 8:33 am
Ning
Thanks for your reply!
For your last comment, I think after you showed that
For {\varepsilon_d} small enough, this implies that {\|u\|_{X_T} \lesssim_d \varepsilon_d} for all {T} (this is an example of a “continuity argument”).
This did not sufficiently show that $u\in X$ since `all $T$’ here means that all $T<T_*$. Maybe after this, we first show that $T_*=\infty$ would be a fair way for us to conclude $u\in X$.
[Fair enough, I’ve rearranged the order of these sentences. -T]
8 June, 2021 at 8:47 am
Ning
Before Exercise 34, you said $u \otimes u$ is a distribution. Here you mean that it is a space-time distribution or a spatial distribution (when $t$ fixed)?
I think I have verified both by definition, but you did not use the terminology `space-time distribution’ like elsewhere, so I’m wondering what you mean in this context.
[Added a clarification that spacetime distributions are intended here. -T]
15 June, 2021 at 7:51 am
Ning
In the last two equations of Note 1,
You bound
but I think the last inequality is not correct. Maybe we could just using
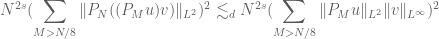
and then summing in N and interchanging summations by the Minkowski’s inequality to get your result.
[Seems fine to me (note that ). -T]
). -T]
3 May, 2022 at 4:33 am
J
Can one use the continuity method to prove Lemma 1?
If one begins with
then one has, by the assumption,
which seems not very helpful.
19 November, 2023 at 9:51 am
Anonymous
Hello. I posted my question on MO https://mathoverflow.net/questions/458716/hs-mild-solution-for-navier-stokes-why-do-we-restrict-attention-to-the-func?noredirect=1#comment1188330_458716
But I guess it is more direct to ask here. In your Remarks 33, what do you mean by estimates being “less favorable” for function spaces with the Fourier zeroth mode included?
I believe that all results and proofs below Definition 32 + Remark 33 (especially local Lipschitz continuity on the initial data) hold “equally valid” even if we do not exclude the Fourier zeroth mode.
Could you please confirm for me?
19 November, 2023 at 11:39 am
Terence Tao
Proposition 44 breaks down if the mode is included (note for instance the negative power of
mode is included (note for instance the negative power of  at the end of the proof).
at the end of the proof).
As a general rule of thumb, for local-in-time theory the zero mode is harmless, but for global-in-time theory the zero mode can cause some minor technical difficulties, due to the heat flow not causing that mode to decay exponentially in time (in contrast to all the other modes).
19 November, 2023 at 12:02 pm
Anonymous
The seroth Fourier mode in the NS problem can be harmlessly set to zero because of the Gallien invariance property. Cheers, Dr Hayes