
The (classical) Möbius function 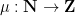
Proposition 1 (Classical Möbius inversion) Letbe functions from the natural numbers to an additive group
. Then the following two claims are equivalent:
- (i)
for all
.
- (ii)
for all
There is a generalisation of this formula to (finite) posets, due to Hall, in which one sums over chains 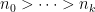
Proposition 2 (Poset Möbius inversion) Letbe a finite poset, and let
be functions from that poset to an additive group
(Note from the finite nature of
- (i)
for all
, where
is understood to range in
- (ii)
for all
are understood to range in
.)
Comparing Proposition 2 with Proposition 1, it is natural to refer to the function 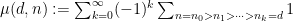
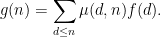
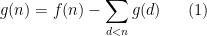 . Iterating this we obtain (ii). Conversely, from (ii) and separating out the
. Iterating this we obtain (ii). Conversely, from (ii) and separating out the  term, and grouping all the other terms based on the value of
term, and grouping all the other terms based on the value of  , we obtain (1), and hence (i).
, we obtain (1), and hence (i). 
In fact it is not completely necessary that the poset 
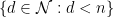
It is not difficult to see that Proposition 2 includes Proposition 1 as a special case, after verifying the combinatorial fact that the quantity

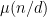 when divides , and vanishes otherwise.
when divides , and vanishes otherwise.
I recently discovered that Proposition 2 can also lead to a useful variant of the inclusion-exclusion principle. The classical version of this principle can be phrased in terms of indicator functions: if 

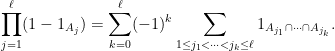
 on for which are all measurable, we have
on for which are all measurable, we have 
One drawback of this formula is that there are exponentially many terms on the right-hand side: 
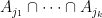
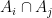
Proposition 3 (Hall-type inclusion-exclusion principle) Let(with the convention that
, one has
where
are understood to range in
to be the empty intersection) if the
are all proper subsets of
In particular, if there is a finite measure



Using the Möbius function 
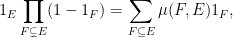


Proof: It suffices to establish (2) (to derive (3) from (2) observe that all the 
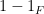
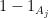
 . But this amounts to the assertion that for each
. But this amounts to the assertion that for each 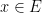 , there is precisely one
, there is precisely one  in
in 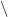 with the property that
with the property that  and
and  for any
for any 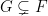 in , namely one can take
in , namely one can take  to be the intersection of all
to be the intersection of all 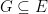 in such that
in such that  contains
contains  .
.
Example 4 Ifwith
, and
are all distinct, then we have for any finite measure
measurable that
due to the four chains
,
,
,
of length one, and the three chains
,
,
of length two. Note that this expansion just has six terms in it, as opposed to the
given by the usual inclusion-exclusion formula, though of course one can reduce the number of terms by combining the
factors. This may not seem particularly impressive, especially if one views the term
as really being three terms instead of one, but if we add a fourth set
with
for all
, the formula now becomes
and we begin to see more cancellation as we now have just seven terms (or ten if we count
as four terms) instead of
terms.


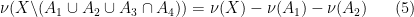
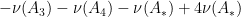
Example 5 (Variant of Legendre sieve) Ifare natural numbers, and
is some sequence of complex numbers with only finitely many terms non-zero, then by applying the above proposition to the sets
and with
we obtain a variant of the Legendre sieve
where
range over the set
(with the understanding that the empty least common multiple is
), and
denotes the assertion that
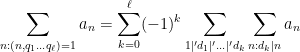
If the poset 

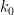
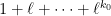
Actually in our application we need an abstraction of the above formula, in which the indicator functions are replaced by more abstract idempotents:
Proposition 6 (Hall-type inclusion-exclusion principle for idempotents) Letwith identity, which are all idempotent (thus
for
). Let
when
(note that all the elements of
where
) if all the


Morally speaking this proposition is equivalent to the previous one after applying a “spectral theorem” to simultaneously diagonalise all of the
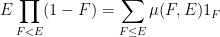
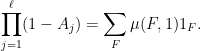
Proof: Again it suffices to verify (6). Using Proposition 2 as before, it suffices to show that 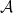


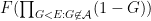
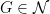
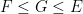
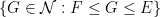

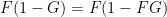

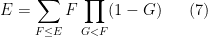
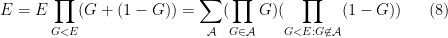

9 comments
Comments feed for this article
23 February, 2021 at 6:57 pm
Sam Hopkins
Your propositions feel very similar to “Rota’s crosscut theorem.” See for instance Section 3.9 of Stanley’s EC1, available at http://www-math.mit.edu/~rstan/ec/ec1/.
26 February, 2021 at 10:43 pm
Aditya Guha Roy
I had a similar feeling at first glance. But proposition 6 is actually not exactly the same as the crosscut theorem; it deals with a different treatment.
24 February, 2021 at 6:17 am
allenknutson
My favorite statement about Möbius inversion is the computation of the Möbius function for a simplicial complex (i.e. the coefficients needed when trying to write the function 1 as a linear combination of the characteristic functions of the closed simplices). It says: the coefficient of a face is 1 – the Euler characteristic of the link of that face.
When the simplicial complex is a (shellable) ball, the links of interior faces are spheres, giving the coefficient (-1)^codimension. Whereas the links of exterior faces are hemispheres, giving the coefficient 0.
24 February, 2021 at 12:53 pm
Anonymous
Is it true that since only finitary operations (e.g. finite sums) are involved, all proofs of such results can be based on only formal(!) arguments?
26 February, 2021 at 10:58 pm
Aditya Guha Roy
In trying to extend the idea to infinite posets you may need additional conditions to deal with the infinite products and sums which you’ll encounter; for instance if you look at Proposition 2, then you can see how the sum in ii can bother you if you try to extend the idea to deal with an infinite poset.
25 February, 2021 at 8:42 am
Oliver Knill
Here is a topological angle to the Moebius picture (complementing Allen Knutsen’s remark): a poset P has as its Barycentric refinement the finite abstract simplicial complex G in which the elements are the non-empty subsets of P. For a subset X of G, the number chi(X) = sum_{x in X} omega(x) is known as the Euler characteristic of X, where omega(x) = (-1)^dim(x), dim(x)=|x|-1 and |x| is cardinality. With the core W^-(x)={y, y x } one can write the Moebius function as mu(x,y) =chi(W^+(x) \cap W^-(y)). (I like to think of W^+ and W^- as unstable and stable manifolds and W^+ cap W^- as a heteroclinic point The Hall equations then read f(x) = sum_{y<x} g(y), g(x) = sum_{y A to a ring A, define chi(X)=sum_{x in X} h(x) and the symmetric matrices L(x,y)=chi(W^-(x) cap W^-(y)) g(x,y) = omega(x) omega(y) chi(W^+(x) cap W^+(y)). The later can be seen as Green functions because g is the inverse of the Laplacian L in the case if h takes values in the units One should think of g(x,y) as the potential energy between x and y. As V(x) = sum_y g(x,y) is a potential or index, Poincare-Hopf then is chi(G) = sum_{x,y in G} g(x,y). This so far only uses the additive structure of A. If A is a ring, then det(L)=det(g)=prod_{x in G} h(x). In the topological case h(x)=omega(x), the number theoretically interesting h(x)=1 or if h(x) takes values in the unit circle of the complex plane, L and g^* are unimodular matrices which are inverses of each other. For h(x)=1, one gets positive definite integral quadratic forms which are inverses of each other. Inclusion-exclusion is used in the proof https://arxiv.org/abs/2010.09152 .
4 June, 2021 at 4:32 pm
Benjamin Steinberg
Proposition 6 is a slight variant of Theorem 1 of Louis Solomon’s classical paper The Burnside algebra of a finite group, Journal of Combinatorial Theory Volume 2, Issue 4, June 1967, Pages 603-615. Theorem 1 and the remark after it show that the primitive idempotents of the algebra of a finite meet semilattice are of the form
are of the form  (he does something slightly more general). Your commuting projections generate a finite meet semilattice.
(he does something slightly more general). Your commuting projections generate a finite meet semilattice.
24 June, 2021 at 2:37 pm
Nishad T M
Prof Tao,
I am Nishad T M from Kerala, India. During Lockdown, I tried to bring the Mathematical Proof of Collatz Conjecture. Since June 2020 I tried, now it is completed. Initially I sent it to Annals of Pure and Applied Mathematics, India to get reviews. As per initial review, I did some slight modifications and submitted to another Journal The Albertian Journal of Pure and Applied Mathematics, publishing from Research Department of Mathematics, St Alberts College Ernakulam, Kerala. I expect its Review report at 30th July.
I hope the Proof is convincing to Mathematics Graduates and Post Graduates.
An Introduction to Soul Set, IJSER,
Soul Process,
Statistical Soul Process Control,
The Motto Of Sreenarayanaguru in View of Soul Analysis,
Origin IJSER
Soul Set of a Product
The Errors in awarded PhDs in Mathematics from Kerala State India and Errors in Mathematics Text Books prescribed by Indian Universities, etc
are some of my Independent effort to bring a new Branch in Mathematics that helps to connect Mathematics with Humanity.
The Theorem 1 in article Origin, IJSER is very Simple and very effective.
Thanks for Reading.
12 January, 2022 at 7:33 pm
Isaac Bernabé Duarte Alvarenga
I have a conjecture that I think is true and I think it is weak enough to be proven, for all n→ Pn+3—(Pn+2)(Pn+1)/Pn is smaller than 0 and for all n such that n is not divisible by 2→Pn+2—(Pn+1)^2/Pn is bigger than 0 and forma all n such that n is divisible by 2 →Pn+2—(Pn+1)^2/Pn is smaller than 0 that’s all I hope someone who is reading this can solve it.