
You are currently browsing the tag archive for the ‘dimensional analysis’ tag.
Many fluid equations are expected to exhibit turbulence in their solutions, in which a significant portion of their energy ends up in high frequency modes. A typical example arises from the three-dimensional periodic Navier-Stokes equations
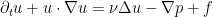

where 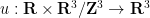
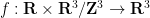
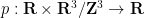
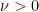
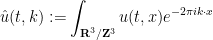
so that the system becomes
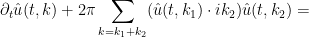

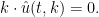
We may normalise 


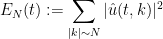
where 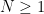

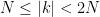
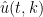

where 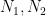
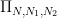
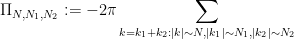



and 
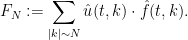
The Navier-Stokes equations are notoriously difficult to solve in general. Despite this, Kolmogorov in 1941 was able to give a convincing heuristic argument for what the distribution of the dyadic energies 

- The injection regime in which the energy injection rate
- The energy flow regime in which the flow rates
- The dissipation regime in which the dissipation
If we assume a fairly steady and smooth forcing term 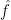
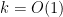


We can heuristically predict the dividing line between the energy flow regime. Of all the flow rates 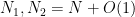
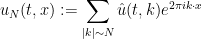
of the velocity field 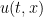

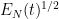
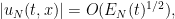
and a similar heuristic applied to 

(One can consider modifications of the Kolmogorov model in which 
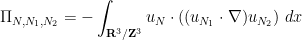
we thus arrive at the heuristic

Of course, there is the possibility that due to significant cancellation, the energy flow is significantly less than 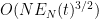
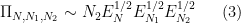
or (assuming that
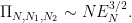
On the other hand, we clearly have

We thus expect to be in the dissipation regime when
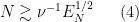
and in the energy flow regime when

Now we study the energy flow regime further. We assume a “statistically scale-invariant” dynamics in this regime, in particular assuming a power law
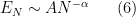
for some 
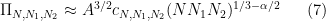
for some structure constants 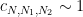
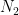
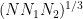

On the other hand, if one is assuming statistical scale invariance, we expect the structure constants to be scale-invariant (in the energy flow regime), in that

for dyadic 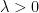

which from (7) suggests a similar cancellation among the structure constants

Combining this with the scale-invariance (9), we see that for fixed 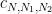
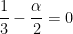
or in other words
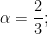
for any other value of 

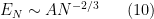
or in terms of shell energies, we have the famous Kolmogorov 5/3 law

Given that frequency interactions tend to cascade from low frequencies to high (if only because there are so many more high frequencies than low ones), the above analysis predicts a stablising effect around this power law: scales at which a law (6) holds for some 
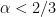
We can solve for 


and hence by (10)
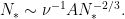
On the other hand, if we let 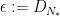

Some simple algebra then lets us solve for
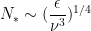
and
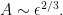
Thus, we have the Kolmogorov prediction
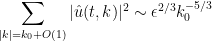
for
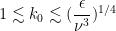
with energy dissipation occuring at the high end 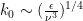
Mathematicians study a variety of different mathematical structures, but perhaps the structures that are most commonly associated with mathematics are the number systems, such as the integers 

A similar situation exists in modern physics. Physical quantities such as length, mass, momentum, charge, and so forth are routinely measured and manipulated using the real number system 
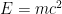
However, as any student of physics is aware, most physical quantities are not represented purely by one or more numbers, but instead by a combination of a number and some sort of unit. For instance, it would be a category error to assert that the length of some object was a number such as 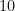
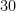
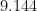

It is then common to declare that while physical quantities and units are not, strictly speaking, numbers, they should be manipulated using the laws of algebra as if they were numerical quantities. For instance, if an object travels 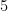
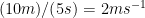
where we use the usual abbreviations of 


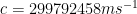
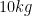
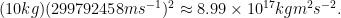
Note that the symbols 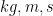



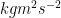
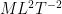

There is however one important limitation to the ability to manipulate “dimensionful” quantities as if they were numbers: one is not supposed to add, subtract, or compare two physical quantities if they have different dimensions, although it is acceptable to multiply or divide two such quantities. For instance, if 





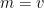
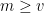
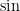
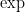

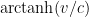
These limitations may seem like a weakness in the mathematical modeling of physical quantities; one may think that one could get a more “powerful” mathematical framework if one were allowed to perform dimensionally inconsistent operations, such as add together a mass and a velocity, add together a vector and a scalar, exponentiate a length, etc. Certainly there is some precedent for this in mathematics; for instance, the formalism of Clifford algebras does in fact allow one to (among other things) add vectors with scalars, and in differential geometry it is quite common to formally apply transcendental functions (such as the exponential function) to a differential form (for instance, the Liouville measure 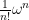
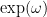

However, there are several reasons why it is advantageous to retain the limitation to only perform dimensionally consistent operations. One is that of error correction: one can often catch (and correct for) errors in one’s calculations by discovering a dimensional inconsistency, and tracing it back to the first step where it occurs. Also, by performing dimensional analysis, one can often identify the form of a physical law before one has fully derived it. For instance, if one postulates the existence of a mass-energy relationship involving only the mass of an object 

The use of units and dimensional analysis has certainly been proven to be very effective tools in physics. But one can pose the question of whether it has a properly grounded mathematical foundation, in order to settle any lingering unease about using such tools in physics, and also in order to rigorously develop such tools for purely mathematical purposes (such as analysing identities and inequalities in such fields of mathematics as harmonic analysis or partial differential equations).
The example of Euclidean geometry mentioned previously offers one possible approach to formalising the use of dimensions. For instance, one could model the length of a line segment not by a number, but rather by the equivalence class of all line segments congruent to the original line segment (cf. the Frege-Russell definition of a number). Similarly, the area of a planar region can be modeled not by a number, but by the equivalence class of all regions that are equidecomposable with the original region (one can, if one wishes, restrict attention here to measurable sets in order to avoid Banach-Tarski-type paradoxes, though that particular paradox actually only arises in three and higher dimensions). As mentioned before, it is then geometrically natural to multiply two lengths to form an area, by taking a rectangle whose line segments have the stated lengths, and using the area of that rectangle as a product. This geometric picture works well for units such as length and volume that have a spatial geometric interpretation, but it is less clear how to apply it for more general units. For instance, it does not seem geometrically natural (or, for that matter, conceptually helpful) to envision the equation
But there are at least two other ways to formalise dimensionful quantities in mathematics, which I will discuss below the fold. The first is a “parametric” model in which dimensionful objects are modeled as numbers (or vectors, matrices, etc.) depending on some base dimensional parameters (such as units of length, mass, and time, or perhaps a coordinate system for space or spacetime), and transforming according to some representation of a structure group that encodes the range of these parameters; this type of “coordinate-heavy” model is often used (either implicitly or explicitly) by physicists in order to efficiently perform calculations, particularly when manipulating vector or tensor-valued quantities. The second is an “abstract” model in which dimensionful objects now live in an abstract mathematical space (e.g. an abstract vector space), in which only a subset of the operations available to general-purpose number systems such as
In harmonic analysis and PDE, one often wants to place a function 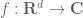
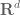
- The Lebesgue spaces
of functions
whose norm
is finite, as well as their relatives such as the weak
(and more generally the Lorentz spaces
) and Orlicz spaces such as
and
;
- The classical regularity spaces
, together with their Hölder continuous counterparts
;
- The Sobolev spaces
of functions
is finite (other equivalent definitions of this norm exist, and there are technicalities if
is negative or
), as well as relatives such as homogeneous Sobolev spaces
, Besov spaces
, and Triebel-Lizorkin spaces
. (The conventions for the superscripts and subscripts here are highly variable.)
- Hardy spaces
, the space BMO of functions of bounded mean oscillation (and the subspace VMO of functions of vanishing mean oscillation);
- The Wiener algebra
;
- Morrey spaces
;
- The space
of finite measures;
- etc., etc.
As the above partial list indicates, there is an entire zoo of function spaces one could consider, and it can be difficult at first to see how they are organised with respect to each other. However, one can get some clarity in this regard by drawing a type diagram for the function spaces one is trying to study. A type diagram assigns a tuple (usually a pair) of relevant exponents to each function space. For function spaces 


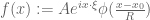
where 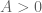
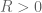
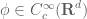
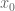
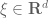
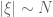
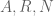
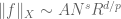
for some exponents 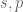


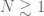
Note that the exponent 

The type diagram below plots the 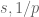

(There are some minor cheats in this diagram, for instance for the Orlicz spaces 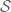
The type diagram can be used to clarify some of the relationships between function spaces, such as Sobolev embedding. For instance, when working with inhomogeneous spaces (which basically identifies low frequencies 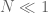
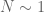
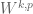
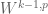
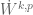
Similarly, if one is working in a compact domain rather than in 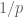


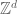
As mentioned earlier, the uncertainty principle suggests that one has the restriction 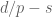
On continuous domains, one can send the frequency 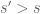
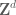
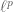
When interpolating between two spaces (using either the real or complex interpolation method), the interpolated space usually has regularity and integrability exponents on the line segment between the corresponding exponents of the endpoint spaces. (This can be heuristically justified from the formula (2) by thinking about how the real or complex interpolation methods actually work.) Typically, one can control the norm of the interpolated space by the geometric mean of the endpoint norms that is indicated by this line segment; again, this is plausible from looking at (2).
The space 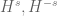
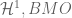
Spaces whose integrability exponent 
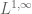
While the regularity 
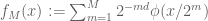
where 
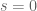
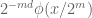
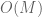
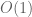
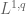
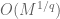
We have cheated somewhat by only working in the high frequency regime. When dealing with inhomogeneous spaces, one often has a different set of exponents for (1) in the low-frequency regime than in the high-frequency regime. In such cases, one sometimes has to use a more complicated type diagram to genuinely model the situation, e.g. by assigning to each space a convex set of type exponents rather than a single exponent, or perhaps having two separate type diagrams, one for the high frequency regime and one for the low frequency regime. Such diagrams can get quite complicated, and will probably not be much use to a beginner in the subject, though in the hands of an expert who knows what he or she is doing, they can still be an effective visual aid.

Recent Comments