
You are currently browsing the monthly archive for July 2011.
Christian Elsholtz and I have recently finished our joint paper “Counting the number of solutions to the Erdös-Straus equation on unit fractions“, submitted to the Journal of the Australian Mathematical Society. This supercedes my previous paper on the subject, by obtaining stronger and more general results. (The paper is currently in the process of being resubmitted to the arXiv, and should appear at this link within a few days.)
As with the previous paper, the main object of study is the number 

with 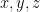

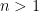
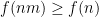
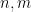


We single out two special types of solutions: Type I solutions, in which 

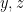

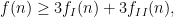
with equality when 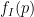
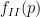
Our first main results are the asymptotics
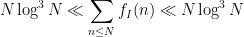

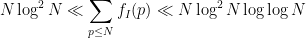
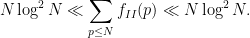
This improves upon the results in the previous paper, which only established
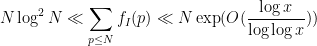
and
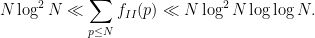
The double logarithmic factor in the upper bound for 
The methods are similar to those in the previous paper (which were also independently discovered in unpublished work of Elsholtz and Heath-Brown), but with the additional input of the Erdös divisor bound on expressions of the form 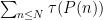

We also note an observation of Heath-Brown, that in our notation gives the lower bound
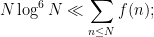
thus, we see that for typical
We also have a number other new results. We find a way to systematically unify all the previously known parameterisations of solutions to the Erdös-Straus equation, by lifting the Cayley-type surface 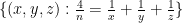


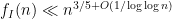
and
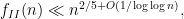
which should be compared to a recent previous bound 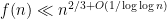
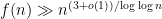
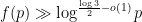
We also completely classify all the congruence classes that can be solved by polynomials, completing the partial list discussed in the previous post. Specifically, the Erdös-Straus conjecture is true for
-
, where
are such that
.
-
and
, where
are such that
.
-
and
, where
are such that
.
-
or
, where
are such that
and
.
-
, where
.
-
, where
are such that
.
In principle, this suggests a way to extend the existing verification of the Erdös-Straus conjecture beyond the current range of 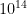
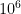
Finally, we begin a study of the more general equation
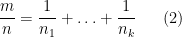
where 

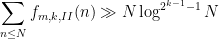
and
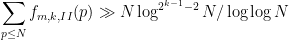
were 

One of the basic problems in analytic number theory is to obtain bounds and asymptotics for sums of the form

in the limit 
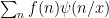
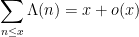
where 

It is thus of interest to develop techniques to estimate such sums 

At the easiest end of the spectrum are those functions 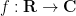

One can already get quite good bounds on this quantity by comparison with the integral 

with sharper bounds available by using tools such as the Euler-Maclaurin formula (see this blog post). Exponentiating such asymptotics, incidentally, leads to one of the standard proofs of Stirling’s formula (as discussed in this blog post).
One can also consider “non-Archimedean” notions of smoothness, such as periodicity relative to a small period 
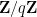

In particular, we have the fundamental estimate

This is a good estimate when 

One can also consider functions
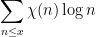
where 
Another class of functions that is reasonably well controlled are the multiplicative functions, in which 

which are clearly related to the partial sums
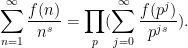
One also obtains similar types of representations for functions that are not quite multiplicative, but are closely related to multiplicative functions, such as the von Mangoldt function 
Moving another notch along the spectrum between well-controlled and ill-controlled functions, one can consider functions

for some other arithmetic function 

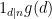


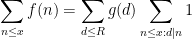
and thus by (1) one can bound this by the sum of a main term 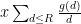
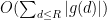

or expressions of the form

where each 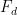

One of the simplest examples of this comes when estimating the divisor function

which counts the number of divisors up to



Here, we are (barely) able to keep the error term smaller than the main term; this is right at the edge of the divisor sum method, because the level

where 



From Dirichlet series methods, it is not difficult to establish the identities
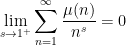
and

This suggests (but does not quite prove) that one has

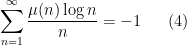
in the sense of conditionally convergent series. Assuming one can justify this (which, ultimately, requires one to exclude zeroes of the Riemann zeta function on the line 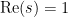
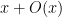
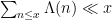

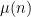
However, there are a number of tricks available to reduce the level of divisor sums. The simplest comes from exploiting the change of variables 
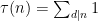


except when
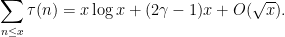
This type of argument is also known as the Dirichlet hyperbola method. A variant of this argument can also deduce the prime number theorem from (3), (4) (and with some additional effort, one can even drop the use of (4)); this is discussed at this previous blog post.
Using this square root trick, one can now also control divisor sums such as
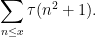
(Note that 
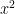

which one can rewrite as

The constraint 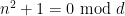

where 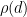
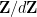
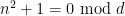

The function 

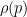



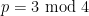

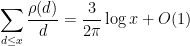
and also

and thus

Similar arguments give asymptotics for 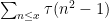



However, the square root trick is insufficient by itself to deal with higher order sums involving the divisor function, such as
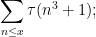
the level here is initially of order 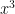

Nevertheless, there is an ingenious argument of Erdös that allows one to obtain good upper and lower bounds for these sorts of sums, in particular establishing the asymptotic
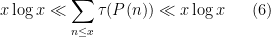
for any fixed irreducible non-constant polynomial 

for any fixed 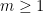

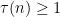

for any fixed
The lower bound in (6) is easy, since one can simply lower the level in (5) to obtain the lower bound

for any 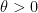

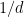
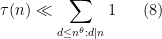
for any fixed 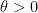
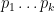
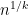

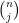
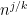


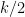
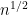
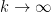
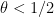
This however can be fixed in a number of ways. First of all, even when 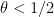

for some 

For Erdös’s upper bound (6), though, one cannot afford to lose these additional factors of 
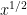

which, thanks to Mertens’ theorem
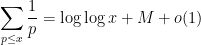
for some absolute constant 


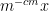
The Erdös argument is quite robust; for instance, the more general inequality

for fixed irreducible

which turn out to be enough to obtain the right asymptotics for the number of solutions to the equation 
Below the fold I will provide some more details of the arguments of Landreau and of Erdös.
I’ve just opened the research thread for the mini-polymath3 project over at the polymath blog. I decided to use Q2 of this year’s IMO, in part to see how the polymath format copes with a geometric problem. (The full list of questions for this year is available here.)
This post will serve as the discussion thread of the project, intended to focus all the non-research aspects of the project such as organisational matters or commentary on the progress of the project. The third component of the project is the wiki page, which is intended to summarise the progress made so far on the problem.
As with mini-polymath1 and mini-polymath2, I myself will be serving primarily as a moderator, and hope other participants will take the lead in the research and in keeping the wiki up-to-date.
Just a reminder that the mini-polymath3 project begins in 24 hours, on July 19, 8pm UTC.
An algebraic (affine) plane curve of degree 

where
- Degree
, which are simply the lines;
- Degree
, which (when
) include the classical conic sections (i.e. ellipses, hyperbolae, and parabolae), but also include the reducible example of the union of two lines; and
- Degree
(cubic) curves
, which include the elliptic curves
(with non-zero discriminant
, so that the curve is smooth) as examples (ignoring some technicalities when
- etc.
Algebraic affine plane curves can also be extended to the projective plane ![{{\Bbb P} k^2 = \{ [x,y,z]: (x,y,z) \in k^3 \backslash 0 \}}](https://s0.wp.com/latex.php?latex=%7B%7B%5CBbb+P%7D+k%5E2+%3D+%5C%7B+%5Bx%2Cy%2Cz%5D%3A+%28x%2Cy%2Cz%29+%5Cin+k%5E3+%5Cbackslash+0+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\{ [x,y,z] \in {\Bbb P} k^2: ax^2+bxy+cy^2+dxz+eyz+fz^2=0\}}](https://s0.wp.com/latex.php?latex=%7B%5C%7B+%5Bx%2Cy%2Cz%5D+%5Cin+%7B%5CBbb+P%7D+k%5E2%3A+ax%5E2%2Bbxy%2Bcy%5E2%2Bdxz%2Beyz%2Bfz%5E2%3D0%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
One of the fundamental theorems about algebraic plane curves is Bézout’s theorem, which asserts that if a degree 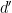
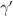

From linear algebra we also have the fundamental fact that one can build algebraic curves through various specified points. For instance, for any two points 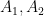

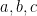


In the degree 

For cubic curves, the situation is more complicated still. Consider for instance two distinct cubic curves 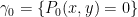
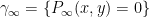



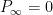

In fact, these are the only cubics that pass through these nine points, or even through eight of the nine points. More precisely, we have the following useful fact, known as the Cayley-Bacharach theorem:
Proposition 1 (Cayley-Bacharach theorem) Let
. Let
). Then
, and in particular vanishes on the ninth point
.
Proof: (This proof is based off of a text of Husemöller.) We assume for contradiction that there is a cubic polynomial 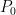
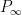
We first make some observations on the points 
One consequence of this is that any five of the 

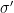
Now suppose that three of the first eight points, say 

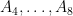





In a similar vein, suppose next that six of the first eight points, say 

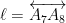
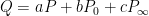
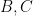
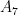
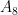
Finally, let 

I recently learned of this proposition and its role in unifying many incidence geometry facts concerning lines, quadric curves, and cubic curves. For instance, we can recover the proof of the classical theorem of Pappus:
Theorem 2 (Pappus’ theorem) Let
be two distinct lines, let
, and let
be distinct points on
, the lines
and
meet at a point
. Then the points
are collinear.
Proof: We may assume that 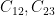
Let 



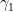







The same argument gives the closely related theorem of Pascal:
Theorem 3 (Pascal’s theorem) Let
be distinct points on a conic section
Proof: Repeat the proof of Pappus’ theorem, with 

One can view Pappus’s theorem as the degenerate case of Pascal’s theorem, when the conic section degenerates to the union of two lines.
Finally, Proposition 1 gives the associativity of the elliptic curve group law:
Theorem 4 (Associativity of the elliptic curve law) Let
be a (projective) elliptic curve, where
is the point at infinity on the
-axis, and the discriminant
on
to equal
, where
and
are disjoint) or tangent to
), and
are collinear), with the convention
. Then
and inverse
.
Proof: It is clear that 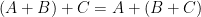


Let 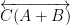
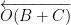
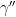

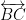

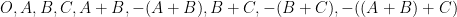


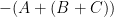


One can view Pappus’s theorem and Pascal’s theorem as a degeneration of the associativity of the elliptic curve law, when the elliptic curve degenerates to three lines (in the case of Pappus) or the union of one line and one conic section (in the case of Pascal’s theorem).
This is another installment of my my series of posts on Hilbert’s fifth problem. One formulation of this problem is answered by the following theorem of Gleason and Montgomery-Zippin:
Theorem 1 (Hilbert’s fifth problem) Let
be a topological group which is locally Euclidean. Then
Theorem 1 is deep and difficult result, but the discussion in the previous posts has reduced the proof of this Theorem to that of establishing two simpler results, involving the concepts of a no small subgroups (NSS) subgroup, and that of a Gleason metric. We briefly recall the relevant definitions:
Definition 2 (NSS) A topological group
of the identity in
.
Definition 3 (Gleason metric) Let
which generates the topology on
, writing
for
:
- (Escape property) If
and
is such that
, then
- (Commutator estimate) If
are such that
, then
where
is the commutator of
.

![\displaystyle \|[g,h]\| \leq C \|g\| \|h\|, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C%5Bg%2Ch%5D%5C%7C+%5Cleq+C+%5C%7Cg%5C%7C+%5C%7Ch%5C%7C%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
The remaining steps in the resolution of Hilbert’s fifth problem are then as follows:
Theorem 4 (Reduction to the NSS case) Let
of
of
is NSS and locally compact.
Theorem 5 (Gleason’s lemma) Let
The purpose of this post is to establish these two results, using arguments that are originally due to Gleason. We will split this task into several subtasks, each of which improves the structure on the group
Proposition 6 (From locally compact to metrisable) Let
For any open neighbourhood 
Proposition 7 (From metrisable to subgroup trapping) Let
of the identity such that
generates a subgroup
contained in
Proposition 8 (From subgroup trapping to NSS) Let
Proposition 9 (From NSS to the escape property) Let
Proposition 10 (From escape to the commutator estimate) Let
It is clear that Propositions 6, 7, and 8 combine to give Theorem 4, and Propositions 9, 10 combine to give Theorem 5.
Propositions 6–10 are all proven separately, but their proofs share some common strategies and ideas. The first main idea is to construct metrics on a locally compact group 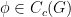



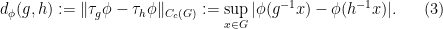
One easily verifies that this is indeed a (semi-)metric (in that it is non-negative, symmetric, and obeys the triangle inequality); it is also left-invariant, and so we have 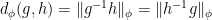

where 
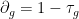

This construction was already seen in the proof of the Birkhoff-Kakutani theorem, which is the main tool used to establish Proposition 6. For the other propositions, the idea is to choose a bump function 
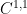

for all 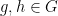
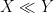

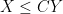
The following lemma illustrates how
Lemma 11 Suppose that
(and associated (semi-)norm
) obey the escape property (1) and the commutator property (2).
Proof: We begin with the commutator property (2). Observe the identity
![\displaystyle \tau_{[g,h]} = \tau_{hg}^{-1} \tau_{gh}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctau_%7B%5Bg%2Ch%5D%7D+%3D+%5Ctau_%7Bhg%7D%5E%7B-1%7D+%5Ctau_%7Bgh%7D&bg=ffffff&fg=000000&s=0&c=20201002)
whence
![\displaystyle \partial_{[g,h]} = \tau_{hg}^{-1} ( \tau_{hg} - \tau_{gh} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cpartial_%7B%5Bg%2Ch%5D%7D+%3D+%5Ctau_%7Bhg%7D%5E%7B-1%7D+%28+%5Ctau_%7Bhg%7D+-+%5Ctau_%7Bgh%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
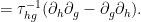
From the triangle inequality (and translation-invariance of the

for any

But from (4) (and the triangle inequality) we have
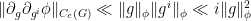
and thus we have the “Taylor expansion”
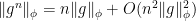
which gives (1).
It remains to obtain 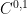

of two functions 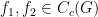


which suggests that the order of “differentiability” of 
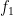

These ideas are already sufficient to establish Proposition 10 directly, and also Proposition 9 when comined with an additional bootstrap argument. The proofs of Proposition 7 and Proposition 8 use similar techniques, but is more difficult due to the potential presence of small subgroups, which require an application of the Peter-Weyl theorem to properly control. Both of these theorems will be proven below the fold, thus (when combined with the preceding posts) completing the proof of Theorem 1.
The presentation here is based on some unpublished notes of van den Dries and Goldbring on Hilbert’s fifth problem. I am indebted to Emmanuel Breuillard, Ben Green, and Tom Sanders for many discussions related to these arguments.
I have just uploaded to the arXiv my paper “On the number of solutions to 
For any positive integer
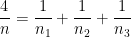
where 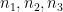
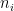

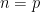

for each prime 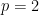
This conjecture remains open, although there is a reasonable amount of evidence towards its truth. For instance, it was shown by Vaughan that for any large 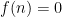
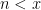
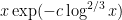


we see that the conjecture holds when 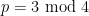


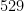
By combining these reductions with extensive numerical calculations, the Erdös-Straus conjecture was verified for all 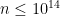
One approach to solving Diophantine equations such as (1) is to use methods of analytic number theory, such as the circle method, to obtain asymptotics (or at least lower bounds) for the number 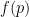
The first main result of my paper is that the number of solutions 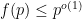

Readers familiar with analytic number theory will recognise the right-hand side from the divisor bound, which indeed plays a role in the proof.
Actually, there are more precise estimates which suggest (though do not quite prove) that the mean value of 
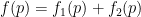
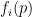

Theorem 1 For all sufficiently large
and
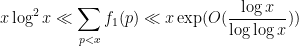

Since the number of primes less than 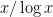

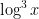
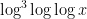


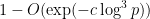
The first step in obtaining these results is an elementary description of 
Lemma 2 Let
of positive integers, with
coprime,
dividing
, and
dividing
. Similarly,
.
One direction of this lemma is very easy: if
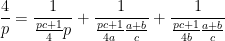
and its cyclic permutations give three contributions to
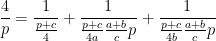
and its cyclic permutations give three contributions to
This lemma, incidentally, provides a way to quickly generate a large number of congruences of primes 
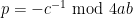
- Taking
, we see that the conjecture holds whenever
- Taking
we see that the conjecture holds whenever
(leaving only those primes
);
- Taking
, we see that the conjecture holds whenever
((leaving only those primes
);
- Taking
, we see that the conjecture holds whenever
(leaving only those primes
);
- Taking
, we see that the conjecture holds whenever
; taking instead
, we see that the conjecture holds whenever
. (This leaves only the primes
, an observation first made by Mordell.)
- etc.
If we let 
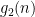


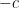


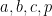
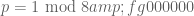

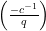


in which one or two of the 
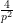

It remains to control the sums 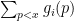

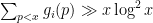
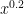

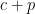
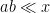
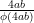
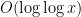
For 
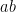


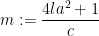
then one can convert the triple 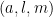

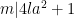
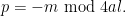
Conversely, every such triple

The point is that this transformation now places 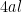

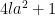

where 
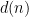


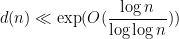
to obtain an upper bound of 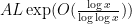
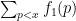

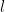

I have blogged several times in the past about nonstandard analysis, which among other things is useful in allowing one to import tools from infinitary (or qualitative) mathematics in order to establish results in finitary (or quantitative) mathematics. One drawback, though, to using nonstandard analysis methods is that the bounds one obtains by such methods are usually ineffective: in particular, the conclusions of a nonstandard analysis argument may involve an unspecified constant
Because of this fact, it would seem that quantitative bounds, such as polynomial type bounds 


Let us now illustrate this by reproving a lemma from this paper of Mei-Chu Chang (Lemma 2.14, to be precise), which was recently pointed out to me by Van Vu. Chang’s paper is focused primarily on the sum-product problem, but she uses a quantitative lemma from algebraic geometry which is of independent interest. To motivate the lemma, let us first establish a qualitative version:
Lemma 1 (Qualitative solvability) Let
be a finite number of polynomials in several variables with rational coefficients. If there is a complex solution
to the simultaneous system of equations
then there also exists a solution
whose coefficients are algebraic numbers (i.e. they lie in the algebraic closure
of the rationals).
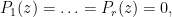
Proof: Suppose there was no solution to 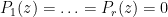
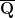

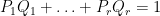
as polynomials. In particular, we have

for all 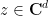

Remark 1 Observe that in the above argument, one could replace
The above lemma asserts that if a system of rational equations is solvable at all, then it is solvable with some algebraic solution. But it gives no bound on the complexity of that solution in terms of the complexity of the original equation. Chang’s lemma provides such a bound. If 

Lemma 2 (Quantitative solvability) Let
with rational coefficients, each of height at most
then there also exists a solution
, where
depends only on
.
Chang proves this lemma by essentially establishing a quantitative version of the nullstellensatz, via elementary elimination theory (somewhat similar, actually, to the approach I took to the nullstellensatz in my own blog post). She also notes that one could also establish the result through the machinery of Gröbner bases. In each of these arguments, it was not possible to use Lemma 1 (or the closely related nullstellensatz) as a black box; one actually had to unpack one of the proofs of that lemma or nullstellensatz to get the polynomial bound. However, using nonstandard analysis, it is possible to get such polynomial bounds (albeit with an ineffective value of the constant
Here’s how the proof works. Informally, the idea is that Lemma 2 should follow from Lemma 1 after replacing the field of rationals
We turn to the details. As is common whenever one uses nonstandard analysis to prove finitary results, we use a “compactness and contradiction” argument (or more precisely, an “ultralimit and contradiction” argument). Suppose for contradiction that Lemma 2 failed. Carefully negating the quantifiers (and using the axiom of choice), we conclude that there exists 
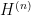

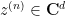

but such that there does not exist any such solution whose coefficients are algebraic numbers of degree at most 
Now we take ultralimits (see e.g. this previous blog post of a quick review of ultralimit analysis, which we will assume knowledge of in the argument that follows). Let 


of the (standard) polynomials 
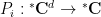



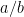


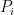
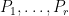
Meanwhile, if we let 
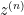
thus 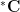
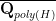

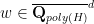
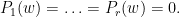
As 
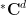


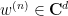



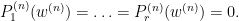
But for
Remark 2 The same argument actually gives a slightly stronger version of Lemma 2, namely that the integer coefficients used to define the algebraic solution
can be taken to be polynomials in the coefficients of
.
I recently finished the first draft of the last of my books based on my 2010 blog posts (and also my Google buzzes), entitled “Compactness and contradiction“. The PDF of this draft is available here. This is a somewhat assorted (and lightly edited) collection of posts (and buzzes), though concentrating in the areas of analysis (both standard and nonstandard), logic, and group theory. As always, comments and corrections are welcome.

Recent Comments