
You are currently browsing the tag archive for the ‘inverse conjecture’ tag.
Note: this post is of a particularly technical nature, in particular presuming familiarity with nilsequences, nilsystems, characteristic factors, etc., and is primarily intended for experts.
As mentioned in the previous post, Ben Green, Tamar Ziegler, and myself proved the following inverse theorem for the Gowers norms:
Theorem 1 (Inverse theorem for Gowers norms) Let
and
be integers, and let
. Suppose that
is a function supported on
such that
Then there exists a filtered nilmanifold
of degree
and complexity
, a polynomial sequence
, and a Lipschitz function
of Lipschitz constant
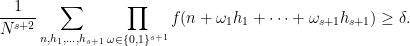

This result was conjectured earlier by Ben Green and myself; this conjecture was strongly motivated by an analogous inverse theorem in ergodic theory by Host and Kra, which we formulate here in a form designed to resemble Theorem 1 as closely as possible:
Theorem 2 (Inverse theorem for Gowers-Host-Kra seminorms) Let
be an ergodic, countably generated measure-preserving system. Suppose that one has
for all non-zero
(all
spaces are real-valued in this post). Then
is an inverse limit (in the category of measure-preserving systems, up to almost everywhere equivalence) of ergodic degree
for some degree
that acts ergodically on
![\displaystyle \lim_{N \rightarrow \infty} \frac{1}{N^{s+1}} \sum_{h_1,\dots,h_{s+1} \in [N]} \int_X \prod_{\omega \in \{0,1\}^{s+1}} f(T^{\omega_1 h_1 + \dots + \omega_{s+1} h_{s+1}}x)\ d\mu(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B1%7D%7BN%5E%7Bs%2B1%7D%7D+%5Csum_%7Bh_1%2C%5Cdots%2Ch_%7Bs%2B1%7D+%5Cin+%5BN%5D%7D+%5Cint_X+%5Cprod_%7B%5Comega+%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bs%2B1%7D%7D+f%28T%5E%7B%5Comega_1+h_1+%2B+%5Cdots+%2B+%5Comega_%7Bs%2B1%7D+h_%7Bs%2B1%7D%7Dx%29%5C+d%5Cmu%28x%29+&bg=ffffff&fg=000000&s=0&c=20201002)

It is a natural question to ask if there is any logical relationship between the two theorems. In the finite field category, one can deduce the combinatorial inverse theorem from the ergodic inverse theorem by a variant of the Furstenberg correspondence principle, as worked out by Tamar Ziegler and myself, however in the current context of 
One can split Theorem 2 into two components:
Theorem 3 (Weak inverse theorem for Gowers-Host-Kra seminorms) Let
for all non-zero
. Then
![\displaystyle \lim_{N \rightarrow \infty} \frac{1}{N^{s+1}} \sum_{h_1,\dots,h_{s+1} \in [N]} \int_X \prod_{\omega \in \{0,1\}^{s+1}} T^{\omega_1 h_1 + \dots + \omega_{s+1} h_{s+1}} f\ d\mu](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B1%7D%7BN%5E%7Bs%2B1%7D%7D+%5Csum_%7Bh_1%2C%5Cdots%2Ch_%7Bs%2B1%7D+%5Cin+%5BN%5D%7D+%5Cint_X+%5Cprod_%7B%5Comega+%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bs%2B1%7D%7D+T%5E%7B%5Comega_1+h_1+%2B+%5Cdots+%2B+%5Comega_%7Bs%2B1%7D+h_%7Bs%2B1%7D%7D+f%5C+d%5Cmu&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 4 (Pro-nilsystems closed under factors) Let
Indeed, it is clear that Theorem 2 implies both Theorem 3 and Theorem 4, and conversely that the two latter theorems jointly imply the former. Theorem 4 is, in principle, purely a fact about nilsystems, and should have an independent proof, but this is not known; the only known proofs go through the full machinery needed to prove Theorem 2 (or the closely related theorem of Ziegler). (However, the fact that a factor of a nilsystem is again a nilsystem was established previously by Parry.)
The purpose of this post is to record a partial implication in reverse direction to the correspondence principle:
As mentioned at the start of the post, a fair amount of familiarity with the area is presumed here, and some routine steps will be presented with only a fairly brief explanation.
A few years ago, Ben Green, Tamar Ziegler, and myself proved the following (rather technical-looking) inverse theorem for the Gowers norms:
Theorem 1 (Discrete inverse theorem for Gowers norms) Let
Then there exists a filtered nilmanifold
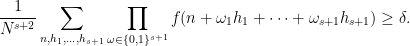

For the definitions of “filtered nilmanifold”, “degree”, “complexity”, and “polynomial sequence”, see the paper of Ben, Tammy, and myself. (I should caution the reader that this blog post will presume a fair amount of familiarity with this subfield of additive combinatorics.) This result has a number of applications, for instance to establishing asymptotics for linear equations in the primes, but this will not be the focus of discussion here.
The purpose of this post is to record the observation that this “discrete” inverse theorem, together with an equidistribution theorem for nilsequences that Ben and I worked out in a separate paper, implies a continuous version:
Theorem 2 (Continuous inverse theorem for Gowers norms) Let
. Suppose that
is a measurable function supported on
such that
Then there exists a filtered nilmanifold
, and a Lipschitz function


The interval 



It is likely that one could prove Theorem 2 by carefully going through the proof of Theorem 1 and replacing all instances of 
![{\frac{1}{N} \cdot [N]}](https://s0.wp.com/latex.php?latex=%7B%5Cfrac%7B1%7D%7BN%7D+%5Ccdot+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



Ben Green, and I have just uploaded to the arXiv a short (six-page) paper “Yet another proof of Szemeredi’s theorem“, submitted to the 70th birthday conference proceedings for Endre Szemerédi. In this paper we put in print a folklore observation, namely that the inverse conjecture for the Gowers norm, together with the density increment argument, easily implies Szemerédi’s famous theorem on arithmetic progressions. This is unsurprising, given that Gowers’ proof of Szemerédi’s theorem proceeds through a weaker version of the inverse conjecture and a density increment argument, and also given that it is possible to derive Szemerédi’s theorem from knowledge of the characteristic factor for multiple recurrence (the ergodic theory analogue of the inverse conjecture, first established by Host and Kra), as was done by Bergelson, Leibman, and Lesigne (and also implicitly in the earlier paper of Bergelson, Host, and Kra); but to our knowledge the exact derivation of Szemerédi’s theorem from the inverse conjecture was not in the literature. Ordinarily this type of folklore might be considered too trifling (and too well known among experts in the field) to publish; but we felt that the venue of the Szemerédi birthday conference provided a natural venue for this particular observation.
The key point is that one can show (by an elementary argument relying primarily an induction on dimension argument and the Weyl recurrence theorem, i.e. that given any real 
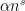
![{[N] = \{1,\ldots,N\}}](https://s0.wp.com/latex.php?latex=%7B%5BN%5D+%3D+%5C%7B1%2C%5Cldots%2CN%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Technically, one might call this the shortest proof of Szemerédi’s theorem in the literature (and would be something like the sixteenth such genuinely distinct proof, by our count), but that would be cheating quite a bit, primarily due to the fact that it assumes the inverse conjecture for the Gowers norm, our current proof of which is checking in at about 100 pages…
Ben Green, Tamar Ziegler and I have just uploaded to the arXiv our paper “An inverse theorem for the Gowers 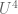
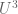
![[N] = \{1,\ldots,N\}](https://s0.wp.com/latex.php?latex=%5BN%5D+%3D+%5C%7B1%2C%5Cldots%2CN%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
To state the inverse conjecture properly requires a certain amount of notation. Given a function 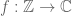
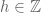

and then define the Gowers ![U^{s+1}[N]](https://s0.wp.com/latex.php?latex=U%5E%7Bs%2B1%7D%5BN%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![f: [N] \to {\Bbb C}](https://s0.wp.com/latex.php?latex=f%3A+%5BN%5D+%5Cto+%7B%5CBbb+C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![\| f\|_{U^{s+1}[N]} := ({\Bbb E}_{h_1,\ldots,h_{s+1} \in [-N,N]} {\Bbb E}_{x \in [N]} |\Delta_{h_1} \ldots \Delta_{h_{s+1}} f(x)|)^{1/2^{s+1}},](https://s0.wp.com/latex.php?latex=%5C%7C+f%5C%7C_%7BU%5E%7Bs%2B1%7D%5BN%5D%7D+%3A%3D+%28%7B%5CBbb+E%7D_%7Bh_1%2C%5Cldots%2Ch_%7Bs%2B1%7D+%5Cin+%5B-N%2CN%5D%7D+%7B%5CBbb+E%7D_%7Bx+%5Cin+%5BN%5D%7D+%7C%5CDelta_%7Bh_1%7D+%5Cldots+%5CDelta_%7Bh_%7Bs%2B1%7D%7D+f%28x%29%7C%29%5E%7B1%2F2%5E%7Bs%2B1%7D%7D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
where we extend f by zero outside of ![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=ffffff&fg=545454&s=0&c=20201002)

Informally, the Gowers norm ![\|f\|_{U^{s+1}[N]}](https://s0.wp.com/latex.php?latex=%5C%7Cf%5C%7C_%7BU%5E%7Bs%2B1%7D%5BN%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002)
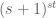

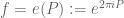


However, polynomial phases are not the only functions with large Gowers norm. For instance, consider the function 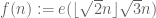
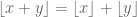
![\|f\|_{U^3[N]}](https://s0.wp.com/latex.php?latex=%5C%7Cf%5C%7C_%7BU%5E3%5BN%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002)

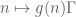
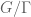

The inverse conjecture for the Gowers norm, GI(s), asserts that such nilsequences are the only obstruction to the Gowers norm being small. Roughly speaking, it goes like this:
Inverse conjecture, GI(s). (Informal statement) Suppose that
This conjecture is trivial for s=0, is a short consequence of Fourier analysis when s=1, and was proven for s=2 by Ben and myself. In this paper we establish the s=3 case. An equivalent formulation in this case is that any bounded function
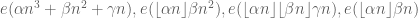
for various real numbers 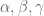
It appears that our methods also work in higher step, though for technical reasons it is convenient to make a number of adjustments to our arguments to do so, most notably a switch from standard analysis to non-standard analysis, about which I hope to say more later. But there are a number of simplifications available on the s=3 case which make the argument significantly shorter, and so we will be writing the higher s argument in a separate paper.
The arguments largely follow those for the s=2 case (which in turn are based on this paper of Gowers). Two major new ingredients are a deployment of a normal form and equidistribution theory for bracket quadratic phases, and a combinatorial decomposition of frequency space which we call the sunflower decomposition. I will sketch these ideas below the fold.
For a number of reasons, including the start of the summer break for me and my coauthors, a number of papers that we have been working on are being released this week. For instance, Ben Green and I have just uploaded to the arXiv our paper “An equivalence between inverse sumset theorems and inverse conjectures for the
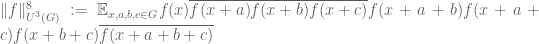
on finite additive group G, where 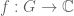
As usual, the connection is easiest to state in a finite field model such as 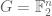
Theorem 1. If
is such that
, then A can be covered by a translate of a subspace of
of cardinality at most
.
The constant 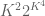

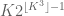
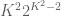

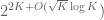
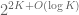
Conjecture 1. (Polynomial Freiman-Ruzsa conjecture for
translates of subspaces of
This conjecture was verified for downsets by Green and myself, but is open in general. This conjecture has a number of equivalent formulations; see this paper of Green for more discussion. In this previous post we show that a stronger version of this conjecture fails.
Meanwhile, for the Gowers norm, we have the following inverse theorem, due to Samorodnitsky:
Theorem 2. Let
be a function whose
such that
.
Note that the quadratic phases 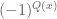
It is conjectured that the exponentially weak correlation here can be strengthened to a polynomial one:
Conjecture 2. (Polynomial inverse conjecture for the
norm). Let
.
The first main result of this paper is
Theorem 3. Conjecture 1 and Conjecture 2 are equivalent.
This result was also independently observed by Shachar Lovett (private communication). We also establish an analogous result for the cyclic group 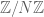
Below the fold, we sketch the proof of Theorem 3.
Tamar Ziegler and I have just uploaded to the arXiv our paper, “The inverse conjecture for the Gowers norm over finite fields via the correspondence principle“, submitted to Analysis & PDE. As announced a few months ago in this blog post, this paper establishes (most of) the inverse conjecture for the Gowers norm from an ergodic theory analogue of this conjecture (in a forthcoming paper by Vitaly Bergelson, Tamar Ziegler, and myself, which should be ready shortly), using a variant of the Furstenberg correspondence principle. Our papers were held up for a while due to some unexpected technical difficulties arising in the low characteristic case; as a consequence, our paper only establishes the full inverse conjecture in the high characteristic case 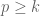

In the rest of this post, I would like to describe the inverse conjecture (in both combinatorial and ergodic forms), and sketch how one deduces one from the other via the correspondence principle (together with two additional ingredients, namely a statistical sampling lemma and a local testability result for polynomials).
Recently, I had tentatively announced a forthcoming result with Ben Green establishing the “Gowers inverse conjecture” (or more accurately, the “inverse conjecture for the Gowers uniformity norm”) for vector spaces 
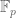

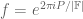
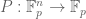
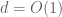
This conjecture can be informally stated as follows. By iterating the obvious fact that the derivative of a polynomial of degree at most d is a polynomial of degree at most d-1, we see that a function

for all 
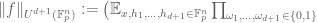

is equal to its maximal value of 1. The inverse conjecture for the Gowers norm, in its usual formulation, says that, more generally, if a function 

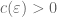
At the time of the announcement, our paper had not quite been fully written up. This turned out to be a little unfortunate, because soon afterwards we discovered that our arguments at one point had to go through a version of Newton’s interpolation formula, which involves a factor of d! in the denominator and so is only valid when the characteristic p of the field exceeds the degree. So our arguments in fact are only valid in the range 

Recent Comments