
You are currently browsing the category archive for the ‘math.NT’ category.
Earlier this year, I gave a series of lectures at the Joint Mathematics Meetings at San Francisco. I am uploading here the slides for these talks:
- “Machine assisted proof” (Video here)
- “Translational tilings of Euclidean space” (Video here)
- “Correlations of multiplicative functions” (Video here)
I also have written a text version of the first talk, which has been submitted to the Notices of the American Mathematical Society.
I have just uploaded to the arXiv my paper “Monotone non-decreasing sequences of the Euler totient function“. This paper concerns the quantity 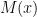



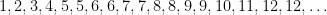
 because the totient function is non-decreasing on the set
because the totient function is non-decreasing on the set  or
or 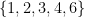 , but not on the set
, but not on the set  .
.
Since 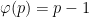

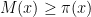
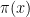
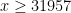
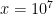

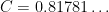
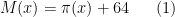
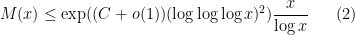

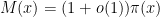 . This answers a question of Erdős, as well as a closely related question of Pollack, Pomerance, and Treviño.
. This answers a question of Erdős, as well as a closely related question of Pollack, Pomerance, and Treviño.
The methods of proof turn out to be mostly elementary (the most advanced result from analytic number theory we need is the prime number theorem with classical error term). The basic idea is to isolate one key prime factor 
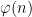


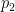 is a medium sized prime,
is a medium sized prime, 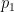 is a significantly larger prime, and
is a significantly larger prime, and  is a number with all prime factors less than . This leads to an approximation
is a number with all prime factors less than . This leads to an approximation 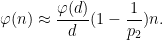 fixed, and also localize to a relatively short interval, then can only be non-decreasing in if is also non-decreasing at the same time. This turns out to significantly cut down on the possible length of a non-decreasing sequence in this regime, particularly if is large; this can be formalized by partitioning the range of into various subintervals and inspecting how this (and the monotonicity hypothesis on ) constrains the values of associated to each subinterval. When is small, we instead use a factorization
fixed, and also localize to a relatively short interval, then can only be non-decreasing in if is also non-decreasing at the same time. This turns out to significantly cut down on the possible length of a non-decreasing sequence in this regime, particularly if is large; this can be formalized by partitioning the range of into various subintervals and inspecting how this (and the monotonicity hypothesis on ) constrains the values of associated to each subinterval. When is small, we instead use a factorization 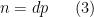 is very smooth (i.e., has no large prime factors), and is a large prime. Now we have the approximation
is very smooth (i.e., has no large prime factors), and is a large prime. Now we have the approximation 
 will have to basically be piecewise constant in order for to be non-decreasing. Pursuing this analysis more carefully (in particular controlling the size of various exceptional sets in which the above analysis breaks down), we end up achieving the main theorem so long as we can prove the preliminary inequality
will have to basically be piecewise constant in order for to be non-decreasing. Pursuing this analysis more carefully (in particular controlling the size of various exceptional sets in which the above analysis breaks down), we end up achieving the main theorem so long as we can prove the preliminary inequality 
 . This is in fact also a necessary condition; any failure of this inequality can be easily converted to a counterexample to the bound (2), by considering numbers of the form (3) with equal to a fixed constant (and omitting a few rare values of where the approximation (4) is bad enough that is temporarily decreasing). Fortunately, there is a minor miracle, relating to the fact that the largest prime factor of denominator of in lowest terms necessarily equals the largest prime factor of , that allows one to evaluate the left-hand side of (5) almost exactly (this expression either vanishes, or is the product of
. This is in fact also a necessary condition; any failure of this inequality can be easily converted to a counterexample to the bound (2), by considering numbers of the form (3) with equal to a fixed constant (and omitting a few rare values of where the approximation (4) is bad enough that is temporarily decreasing). Fortunately, there is a minor miracle, relating to the fact that the largest prime factor of denominator of in lowest terms necessarily equals the largest prime factor of , that allows one to evaluate the left-hand side of (5) almost exactly (this expression either vanishes, or is the product of 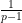 for some primes ranging up to the largest prime factor of ) that allows one to easily establish (5). If one were to try to prove an analogue of our main result for the sum-of-divisors function
for some primes ranging up to the largest prime factor of ) that allows one to easily establish (5). If one were to try to prove an analogue of our main result for the sum-of-divisors function 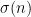 , one would need the analogue
, one would need the analogue 
In the final section of the paper we discuss some near counterexamples to the strong conjecture (1) that indicate that it is likely going to be difficult to get close to proving this conjecture without assuming some rather strong hypotheses. Firstly, we show that failure of Legendre’s conjecture on the existence of a prime between any two consecutive squares can lead to a counterexample to (1). Secondly, we show that failure of the Dickson-Hardy-Littlewood conjecture can lead to a separate (and more dramatic) failure of (1), in which the primes are no longer the dominant sequence on which the totient function is non-decreasing, but rather the numbers which are a power of two times a prime become the dominant sequence. This suggests that any significant improvement to (2) would require assuming something comparable to the prime tuples conjecture, and perhaps also some unproven hypotheses on prime gaps.
Kevin Ford, Dimitris Koukoulopoulos and I have just uploaded to the arXiv our paper “A lower bound on the mean value of the Erdős-Hooley delta function“. This paper complements the recent paper of Dimitris and myself obtaining the upper bound


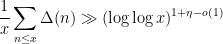
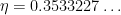 is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that
is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that 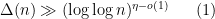 outside of a set of density zero. The previous best known lower bound for the mean value was
outside of a set of density zero. The previous best known lower bound for the mean value was 
The point is the main contributions to the mean value of 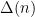
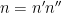
 is the product of primes between some intermediate threshold
is the product of primes between some intermediate threshold 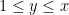 and and behaves “typically” (so in particular, it has about
and and behaves “typically” (so in particular, it has about  prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but
prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but 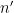 is the product of primes up to
is the product of primes up to  and has double the number of typical prime factors –
and has double the number of typical prime factors –  , rather than
, rather than  – thus is the type of number that would make a significant contribution to the mean value of the divisor function
– thus is the type of number that would make a significant contribution to the mean value of the divisor function  . Here is such that
. Here is such that  is an integer in the range
is an integer in the range 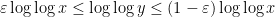
 there are basically
there are basically 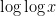 different values of give essentially disjoint contributions. From the easy inequalities
different values of give essentially disjoint contributions. From the easy inequalities 
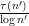 has mean about one, one would expect to get the above result provided that one could get a lower bound of the form
has mean about one, one would expect to get the above result provided that one could get a lower bound of the form 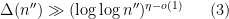 with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality
with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality 

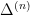 when
when 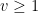 . This inequality is easily proven by applying the pigeonhole principle to the factors of of the form
. This inequality is easily proven by applying the pigeonhole principle to the factors of of the form 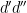 , where
, where 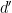 is one of the
is one of the  factors of , and
factors of , and  is one of the
is one of the 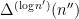 factors of in the optimal interval
factors of in the optimal interval ![{[e^u, e^{u+\log n'}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B%5Clog+n%27%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The extra room provided by the enlargement of the range
. The extra room provided by the enlargement of the range ![{[e^u, e^{u+1}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset
to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset  of
of ![{[D^c, D]}](https://s0.wp.com/latex.php?latex=%7B%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some small
for some small  and sufficiently large
and sufficiently large  with each
with each ![{n \in [D^c, D]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) lying in with an independent probability
lying in with an independent probability 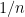 , then with high probability there should be
, then with high probability there should be  subset sums of that attain the same value. (Initially, what “high probability” means is just “close to “, but one can reduce the failure probability significantly as
subset sums of that attain the same value. (Initially, what “high probability” means is just “close to “, but one can reduce the failure probability significantly as  by a “tensor power trick” taking advantage of Bennett’s inequality.)
by a “tensor power trick” taking advantage of Bennett’s inequality.)
I have just uploaded to the arXiv my paper “The convergence of an alternating series of Erdős, assuming the Hardy–Littlewood prime tuples conjecture“. This paper concerns an old problem of Erdős concerning whether the alternating series 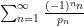

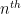
The alternating series test does not apply here because the ratios 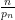
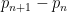
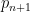
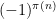
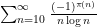
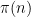
The prime tuples conjecture does not directly say much about the value of 
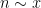
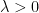


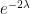

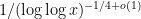
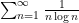
To get around this obstacle, we take advantage of the random sifted model 
![{[n, n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2C+n%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x,2x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C2x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
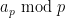
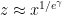

For this problem, the main advantage of working with the random sifted model, rather than with the primes or the singular series arising from the prime tuples conjecture, is that the sifted model can be studied iteratively from the partially sifted sets 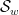
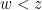


![{[n,n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2Cn%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


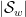
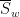


Dimitris Koukoulopoulos and I have just uploaded to the arXiv our paper “An upper bound on the mean value of the Erdős-Hooley delta function“. This paper concerns a (still somewhat poorly understood) basic arithmetic function in multiplicative number theory, namely the Erdos-Hooley delta function
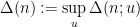

 measures the extent to which the divisors of a natural number can be concentrated in a dyadic (or more precisely,
measures the extent to which the divisors of a natural number can be concentrated in a dyadic (or more precisely,  -dyadic) interval
-dyadic) interval ![{(e^u, e^{u+1}]}](https://s0.wp.com/latex.php?latex=%7B%28e%5Eu%2C+e%5E%7Bu%2B1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . From the pigeonhole principle, we have the bounds
. From the pigeonhole principle, we have the bounds 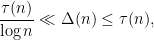
 is the usual divisor function. The statistical behavior of the divisor function is well understood; for instance, if is drawn at random from to , then the mean value of
is the usual divisor function. The statistical behavior of the divisor function is well understood; for instance, if is drawn at random from to , then the mean value of 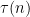 is roughly
is roughly 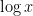 , the median is roughly
, the median is roughly 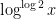 , and (by the Erdős-Kac theorem) asymptotically has a log-normal distribution. In particular, there are a small proportion of highly divisible numbers that skew the mean to be significantly higher than the median.
, and (by the Erdős-Kac theorem) asymptotically has a log-normal distribution. In particular, there are a small proportion of highly divisible numbers that skew the mean to be significantly higher than the median.
On the other hand, the statistical behavior of the Erdős-Hooley delta function is significantly less well understood, even conjecturally. Again drawing 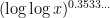
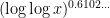


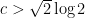 , with the lower bound due to Hall and Tenenbaum, and the upper bound a recent result of La Bretèche and Tenenbaum.
, with the lower bound due to Hall and Tenenbaum, and the upper bound a recent result of La Bretèche and Tenenbaum.
The main result of this paper is an improvement of the upper bound to
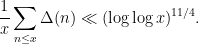
The reason we looked into this problem was that it was connected to forthcoming work of David Conlon, Jacob Fox, and Huy Pham on the following problem of Erdos: what is the size of the largest subset 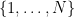


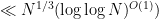
Let me now discuss some of the ingredients of the proof. The first few steps are standard. Firstly we may restrict attention to square-free numbers without much difficulty (the point being that if a number 


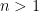


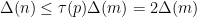


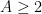 , we have a bound
, we have a bound 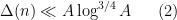
 which is small in the sense that
which is small in the sense that 
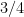 to
to 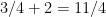 ).
).
To get some intuition on the size of 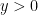

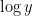
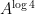

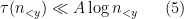
At this point we perform another standard technique, namely the moment method of controlling the supremum 
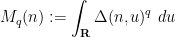 ; it is not difficult to establish the bound
; it is not difficult to establish the bound 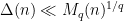
 . We will be able to show a moment bound
. We will be able to show a moment bound 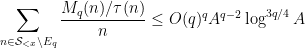
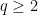 for some exceptional set
for some exceptional set  obeying the smallness condition (3) (actually, for technical reasons we need to improve the right-hand side slightly to close an induction on ); this will imply the distributional bound (2) from a standard Markov inequality argument (setting ).
obeying the smallness condition (3) (actually, for technical reasons we need to improve the right-hand side slightly to close an induction on ); this will imply the distributional bound (2) from a standard Markov inequality argument (setting ).
The strategy is then to obtain a good recursive inequality for (averages of) 
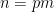
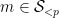
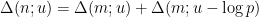
 ; taking moments, one obtains the identity
; taking moments, one obtains the identity  here and apply Hölder’s inequality. But it convenient to first use the symmetry of the summand in
here and apply Hölder’s inequality. But it convenient to first use the symmetry of the summand in  to reduce to the case of relatively small values of
to reduce to the case of relatively small values of  :
: 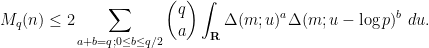
 term as
term as 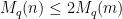
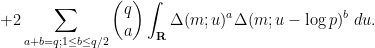
 by dividing out by the divisor function:
by dividing out by the divisor function: 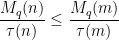
 and . After some standard manipulations (using the Brun–Titchmarsh and Hölder inequalities), one is able to estimate sums such as
and . After some standard manipulations (using the Brun–Titchmarsh and Hölder inequalities), one is able to estimate sums such as 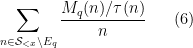
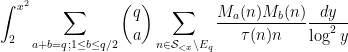 that turns out to hold in our application). By an induction hypothesis and a Markov inequality argument, one can get a reasonable pointwise upper bound on
that turns out to hold in our application). By an induction hypothesis and a Markov inequality argument, one can get a reasonable pointwise upper bound on  (after removing another exceptional set), and the net result is that one can basically control the sum (6) in terms of expressions such as
(after removing another exceptional set), and the net result is that one can basically control the sum (6) in terms of expressions such as 
 . This allows one to estimate these expressions efficiently by induction.
. This allows one to estimate these expressions efficiently by induction.
Tamar Ziegler and I have just uploaded to the arXiv our paper “Infinite partial sumsets in the primes“. This is a short paper inspired by a recent result of Kra, Moreira, Richter, and Robertson (discussed for instance in this Quanta article from last December) showing that for any set 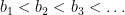


Theorem 1
- (i) If the Hardy-Littlewood prime tuples conjecture (or the weaker conjecture of Dickson) is true, then there exists an increasing sequence
is prime for all
.
- (ii) Unconditionally, there exist increasing sequences
and
of natural numbers such that
is prime for all
- (iii) These conclusions fail if “prime” is replaced by “positive (relative) density subset of the primes” (even if the density is equal to 1).
We remark that it was shown by Balog that there (unconditionally) exist arbitrarily long but finite sequences 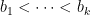

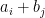

The conclusion of (i) is stronger than that of (ii) (which is of course consistent with the former being conditional and the latter unconditional). The conclusion (ii) also implies the well-known theorem of Maynard that for any given 
Our proof of (i) was initially inspired by the topological dynamics methods used by Kra, Moreira, Richter, and Robertson, but we managed to condense it to a purely elementary argument (taking up only half a page) that makes no reference to topological dynamics and builds up the sequence
The proof of (ii) takes up the majority of the paper. It is easiest to phrase the argument in terms of “prime-producing tuples” – tuples 

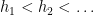
Lemma 2 (Bergelson intersectivity lemma) Letbe subsets of a probability space
of measure uniformly bounded away from zero, thus
. Then there exists a subsequence
such that
for all

This lemma has a short proof, though not an entirely obvious one. Firstly, by deleting a null set from 
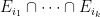
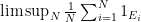

It turns out that one cannot quite combine the standard Maynard sieve with the intersectivity lemma because the events 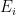
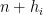
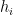
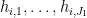

Kaisa Matomäki, Xuancheng Shao, Joni Teräväinen, and myself have just uploaded to the arXiv our preprint “Higher uniformity of arithmetic functions in short intervals I. All intervals“. This paper investigates the higher order (Gowers) uniformity of standard arithmetic functions in analytic number theory (and specifically, the Möbius function 

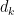
![{(X,X+H]}](https://s0.wp.com/latex.php?latex=%7B%28X%2CX%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

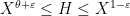
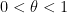

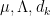
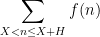
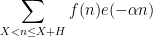
 , where
, where 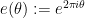 . For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations
. For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations 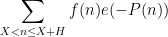
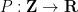 is a polynomial of some fixed degree, or more generally
is a polynomial of some fixed degree, or more generally 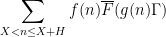
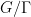 is a nilmanifold of fixed degree and dimension (and with some control on structure constants),
is a nilmanifold of fixed degree and dimension (and with some control on structure constants), 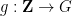 is a polynomial map, and
is a polynomial map, and  is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
Traditionally, asymptotics for such sums are expressed in terms of a “main term” of some arithmetic nature, plus an error term that is estimated in magnitude. For instance, a sum such as 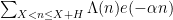
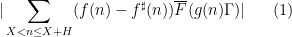 variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
- For the Möbius function
, as per the Möbius pseudorandomness conjecture. (One could choose a more sophisticated approximant in the presence of a Siegel zero, as I did with Joni in this recent paper, but we do not do so here.)
- For the von Mangoldt function
, where
and
.
- For the divisor functions
for some explicit polynomials
, chosen so that
and
The objective is then to obtain bounds on sums such as (1) that improve upon the “trivial bound” that one can get with the triangle inequality and standard number theory bounds such as the Brun-Titchmarsh inequality. For 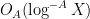


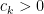

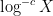
Our main estimates on sums of the form (1) work in the following ranges:
- For
, one can obtain strongly logarithmic savings on (1) for
, and power savings for
.
- For
, one can obtain weakly logarithmic savings for
.
- For
, one can obtain power savings for
.
- For
, one can obtain power savings for
.
Conjecturally, one should be able to obtain power savings in all cases, and lower 
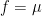
By combining these results with tools from additive combinatorics, one can obtain a number of applications:
- Direct insertion of our bounds in the recent work of Kanigowski, Lemanczyk, and Radziwill on the prime number theorem on dynamical systems that are analytic skew products gives some improvements in the exponents there.
- We can obtain a “short interval” version of a multiple ergodic theorem along primes established by Frantzikinakis-Host-Kra and Wooley-Ziegler, in which we average over intervals of the form
.
- We can obtain a “short interval” version of the “linear equations in primes” asymptotics obtained by Ben Green, Tamar Ziegler, and myself in this sequence of papers, where the variables in these equations lie in short intervals
We now briefly discuss some of the ingredients of proof of our main results. The first step is standard, using combinatorial decompositions (based on the Heath-Brown identity and (for the 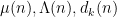
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoff
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoffs
that are not too close to
- Type
sums, which are basically of the form
for some weights
The precise ranges of the cutoffs 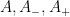
The Type
For the Type 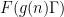
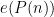


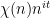


 range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
For the type
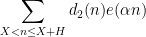

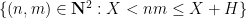 into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as
into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as  on the majority of these progressions. As it turns out, this strategy works well in the regime
on the majority of these progressions. As it turns out, this strategy works well in the regime 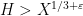 unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our
unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our 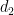 result can be as low as
result can be as low as  .
.
In a sequel to this paper (currently in preparation), we will obtain analogous results for almost all intervals ![{(x,x+H]}](https://s0.wp.com/latex.php?latex=%7B%28x%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[X,2X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Joni Teräväinen and I have just uploaded to the arXiv our preprint “The Hardy–Littlewood–Chowla conjecture in the presence of a Siegel zero“. This paper is a development of the theme that certain conjectures in analytic number theory become easier if one makes the hypothesis that Siegel zeroes exist; this places one in a presumably “illusory” universe, since the widely believed Generalised Riemann Hypothesis (GRH) precludes the existence of such zeroes, yet this illusory universe seems remarkably self-consistent and notoriously impossible to eliminate from one’s analysis.
For the purposes of this paper, a Siegel zero is a zero 

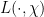
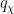
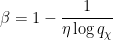
 (which we will call the quality) of the Siegel zero. The significance of these zeroes is that they force the Möbius function and the Liouville function to “pretend” to be like the exceptional character for primes of magnitude comparable to . Indeed, if we define an exceptional prime to be a prime
(which we will call the quality) of the Siegel zero. The significance of these zeroes is that they force the Möbius function and the Liouville function to “pretend” to be like the exceptional character for primes of magnitude comparable to . Indeed, if we define an exceptional prime to be a prime 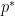 in which
in which  , then very few primes near will be exceptional; in our paper we use some elementary arguments to establish the bounds
, then very few primes near will be exceptional; in our paper we use some elementary arguments to establish the bounds 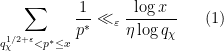
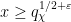 and , where the sum is over exceptional primes in the indicated range
and , where the sum is over exceptional primes in the indicated range 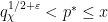 ; this bound is non-trivial for as large as
; this bound is non-trivial for as large as 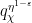 . (See Section 1 of this blog post for some variants of this argument, which were inspired by work of Heath-Brown.) There is also a companion bound (somewhat weaker) that covers a range of a little bit below
. (See Section 1 of this blog post for some variants of this argument, which were inspired by work of Heath-Brown.) There is also a companion bound (somewhat weaker) that covers a range of a little bit below 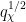 .
.
One of the early influential results in this area was the following result of Heath-Brown, which I previously blogged about here:
Theorem 1 (Hardy-Littlewood assuming Siegel zero) Letbe a fixed natural number. Suppose one has a Siegel zero
for all
, where
is the singular series
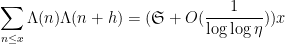
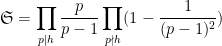
In particular, Heath-Brown showed that if there are infinitely many Siegel zeroes, then there are also infinitely many twin primes, with the correct asymptotic predicted by the Hardy-Littlewood prime tuple conjecture at infinitely many scales.
Very recently, Chinis established an analogous result for the Chowla conjecture (building upon earlier work of Germán and Katai):
Theorem 2 (Chowla assuming Siegel zero) Letbe distinct fixed natural numbers. Suppose one has a Siegel zero
in the range
, where
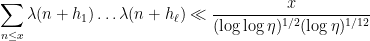
In our paper we unify these results and also improve the quantitative estimates and range of
Theorem 3 (Hardy-Littlewood-Chowla assuming Siegel zero) Letbe distinct fixed natural numbers with
. Suppose one has a Siegel zero
for
for any fixed


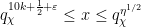
Our argument proceeds by a series of steps in which we replace
- (i) Replace the Liouville function
, which is a completely multiplicative function that agrees with
- (ii) Replace the von Mangoldt function
, which is the Dirichlet convolution
multiplied by a Selberg sieve weight
to essentially restrict that convolution to almost primes.
- (iii) Replace
which has the structure of a “Type I sum”, and which agrees with
- (iv) Replace the approximant
which has the structure of a “Type I sum”.
- (v) Now that all terms in the correlation have been replaced with tractable Type I sums, use standard Euler product calculations and Fourier analysis, similar in spirit to the proof of the pseudorandomness of the Selberg sieve majorant for the primes in this paper of Ben Green and myself, to evaluate the correlation to high accuracy.
Steps (i), (ii) proceed mainly through estimates such as (1) and standard sieve theory bounds. Step (iii) is based primarily on estimates on the number of smooth numbers of a certain size.
The restriction 
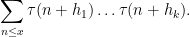
 this sum can be easily controlled by the Dirichlet hyperbola method. For
this sum can be easily controlled by the Dirichlet hyperbola method. For  one needs the fact that has a level of distribution greater than
one needs the fact that has a level of distribution greater than  ; in fact Kloosterman sum bounds give a level of distribution of
; in fact Kloosterman sum bounds give a level of distribution of  , a folklore fact that seems to have first been observed by Linnik and Selberg. We use a (notationally more complicated) version of this argument to treat the sums arising in (iv) for . Unfortunately for
, a folklore fact that seems to have first been observed by Linnik and Selberg. We use a (notationally more complicated) version of this argument to treat the sums arising in (iv) for . Unfortunately for 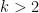 there are no known techniques to unconditionally obtain asymptotics, even for the model sum
there are no known techniques to unconditionally obtain asymptotics, even for the model sum 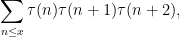 hypothesis in our main theorem at our current level of understanding of analytic number theory.
hypothesis in our main theorem at our current level of understanding of analytic number theory.
Step (v) is a tedious but straightforward sieve theoretic computation, similar in many ways to the correlation estimates of Goldston and Yildirim used in their work on small gaps between primes (as discussed for instance here), and then also used by Ben Green and myself to locate arithmetic progressions in primes.
Joni Teräväinen and myself have just uploaded to the arXiv our preprint “Quantitative bounds for Gowers uniformity of the Möbius and von Mangoldt functions“. This paper makes quantitative the Gowers uniformity estimates on the Möbius function
To discuss the results we first discuss the situation of the Möbius function, which is technically simpler in some (though not all) ways. We assume familiarity with Gowers norms and standard notations around these norms, such as the averaging notation ![{\mathop{\bf E}_{n \in [N]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
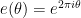
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) = o(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%3D+o%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
 . With Vinogradov-Korobov error term, the prime number theorem is strengthened to
. With Vinogradov-Korobov error term, the prime number theorem is strengthened to ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} );](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29%3B&bg=ffffff&fg=000000&s=0&c=20201002)
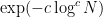 type factors) as pseudopolynomial decay. Equivalently, we obtain pseudopolynomial decay of Gowers
type factors) as pseudopolynomial decay. Equivalently, we obtain pseudopolynomial decay of Gowers 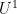 seminorm of :
seminorm of : ![\displaystyle \| \mu \|_{U^1([N])} \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} ).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^1([N])} \ll_\varepsilon N^{-1/2+\varepsilon}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll_%5Cvarepsilon+N%5E%7B-1%2F2%2B%5Cvarepsilon%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Once one restricts to arithmetic progressions, the situation gets worse: the Siegel-Walfisz theorem gives the bound
![\displaystyle \| \mu 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll_A \log^{-A} N \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
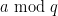 and any , but with the catch that the implied constant is ineffective in . This ineffectivity cannot be removed without further progress on the notorious Siegel zero problem.
and any , but with the catch that the implied constant is ineffective in . This ineffectivity cannot be removed without further progress on the notorious Siegel zero problem.
In 1937, Davenport was able to show the discorrelation estimate
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) e(-\alpha n) \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+e%28-%5Calpha+n%29+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) uniformly in
uniformly in  , which leads (by standard Fourier arguments) to the Fourier uniformity estimate
, which leads (by standard Fourier arguments) to the Fourier uniformity estimate ![\displaystyle \| \mu \|_{U^2([N])} \ll_A \log^{-A} N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^2([N])} \ll \log^{-c} N \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c%7D+N+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002) .
.
For the situation with the 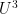
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \ll_{A,F,G/\Gamma} \log^{-A} N \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll_%7BA%2CF%2CG%2F%5CGamma%7D+%5Clog%5E%7B-A%7D+N+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002) , any degree two (filtered) nilmanifold , any polynomial sequence , and any Lipschitz function ; again, the implied constants are ineffective. On the other hand, in a separate paper of Ben Green and myself, we established the following inverse theorem: if for instance we knew that
, any degree two (filtered) nilmanifold , any polynomial sequence , and any Lipschitz function ; again, the implied constants are ineffective. On the other hand, in a separate paper of Ben Green and myself, we established the following inverse theorem: if for instance we knew that ![\displaystyle \| \mu \|_{U^3([N])} \geq \delta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E3%28%5BN%5D%29%7D+%5Cgeq+%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
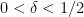 , then there exists a degree two nilmanifold of dimension
, then there exists a degree two nilmanifold of dimension 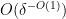 , complexity , a polynomial sequence , and Lipschitz function of Lipschitz constant
, complexity , a polynomial sequence , and Lipschitz function of Lipschitz constant 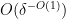 such that
such that ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \gg \exp(-\delta^{-O(1)}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cgg+%5Cexp%28-%5Cdelta%5E%7B-O%281%29%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^3([N])} = o(1).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E3%28%5BN%5D%29%7D+%3D+o%281%29.&bg=ffffff&fg=000000&s=0&c=20201002)
 produced by this argument is completely ineffective: obtaining a bound on when this quantity dips below a given threshold
produced by this argument is completely ineffective: obtaining a bound on when this quantity dips below a given threshold  depends on the implied constant in (3) for some whose dimension depends on , and the dependence on obtained in this fashion is ineffective in the face of a Siegel zero.
depends on the implied constant in (3) for some whose dimension depends on , and the dependence on obtained in this fashion is ineffective in the face of a Siegel zero.
For higher norms 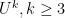

![\displaystyle \| \mu \|_{U^k([N])} \geq \delta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cgeq+%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
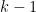 nilmanifold of dimension , complexity
nilmanifold of dimension , complexity 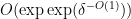 , a polynomial sequence , and Lipschitz function of Lipschitz constant
, a polynomial sequence , and Lipschitz function of Lipschitz constant 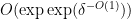 such that
such that ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \gg \exp\exp(-\delta^{-O(1)}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cgg+%5Cexp%5Cexp%28-%5Cdelta%5E%7B-O%281%29%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002) .) Meanwhile, the bound (3) was extended to arbitrary nilmanifolds by Ben and myself. Again, the two results when concatenated give the qualitative decay
.) Meanwhile, the bound (3) was extended to arbitrary nilmanifolds by Ben and myself. Again, the two results when concatenated give the qualitative decay ![\displaystyle \| \mu \|_{U^k([N])} = o(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%3D+o%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Our first result gives an effective decay bound:
Theorem 1 For any, we have
for some
This is off by a logarithm from the best effective bound (2) in the 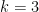
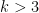
We have analogues of all the above results for the von Mangoldt function 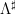
![\displaystyle \| \Lambda - 1 \|_{U^1([N])} \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CLambda+-+1+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
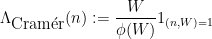
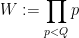
 is the quasipolynomial quantity
is the quasipolynomial quantity 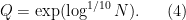
![\displaystyle \mathop{\bf E}_{n \in [N]} (\Lambda - \Lambda_{\hbox{Cram\'er}}(n)) e(-\alpha n) \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BCram%5C%27er%7D%7D%28n%29%29+e%28-%5Calpha+n%29+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda - \Lambda_{\hbox{Cram\'er}}\|_{U^2([N])} \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CLambda+-+%5CLambda_%7B%5Chbox%7BCram%5C%27er%7D%7D%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) and (with an ineffective dependence on ), again regaining effectivity if is replaced by a sufficiently small constant . All the previously stated discorrelation and Gowers uniformity results for then have analogues for , and our main result is similarly analogous:
and (with an ineffective dependence on ), again regaining effectivity if is replaced by a sufficiently small constant . All the previously stated discorrelation and Gowers uniformity results for then have analogues for , and our main result is similarly analogous:
Theorem 2 For anyfor some
By standard methods, this result also gives quantitative asymptotics for counting solutions to various systems of linear equations in primes, with error terms that gain a factor of 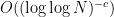
We now discuss the methods of proof, focusing first on the case of the Möbius function. Suppose first that there is no “Siegel zero”, by which we mean a quadratic character 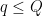
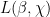

![\displaystyle \| \mu 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N). \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N) \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002) nilmanifolds of dimension
nilmanifolds of dimension 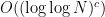 and complexity
and complexity 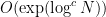 , all polynomial sequences
, all polynomial sequences  , and all Lipschitz functions of norm . If the nilmanifold had bounded dimension, then one could repeat the arguments of Ben and myself more or less verbatim to establish this claim from (5), which relied on the quantitative equidistribution theory on nilmanifolds developed in a separate paper of Ben and myself. Unfortunately, in the latter paper the dependence of the quantitative bounds on the dimension was not explicitly given. In an appendix to the current paper, we go through that paper to account for this dependence, showing that all exponents depend at most doubly exponentially in the dimension , which is barely sufficient to handle the dimension of that arises here.
, and all Lipschitz functions of norm . If the nilmanifold had bounded dimension, then one could repeat the arguments of Ben and myself more or less verbatim to establish this claim from (5), which relied on the quantitative equidistribution theory on nilmanifolds developed in a separate paper of Ben and myself. Unfortunately, in the latter paper the dependence of the quantitative bounds on the dimension was not explicitly given. In an appendix to the current paper, we go through that paper to account for this dependence, showing that all exponents depend at most doubly exponentially in the dimension , which is barely sufficient to handle the dimension of that arises here.
Now suppose we have a Siegel zero 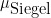
![\displaystyle \| (\mu - \mu_{\hbox{Siegel}}) 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N) \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%28%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D%29+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002) . The Siegel approximant to is actually a little bit complicated, and to our knowledge the first appearance of this sort of approximant only appears as late as this 2010 paper of Germán and Katai. Our version of this approximant is defined as the multiplicative function such that
. The Siegel approximant to is actually a little bit complicated, and to our knowledge the first appearance of this sort of approximant only appears as late as this 2010 paper of Germán and Katai. Our version of this approximant is defined as the multiplicative function such that 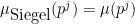
 , and
, and 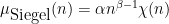 is coprime to all primes
is coprime to all primes 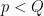 , and is a normalising constant given by the formula
, and is a normalising constant given by the formula 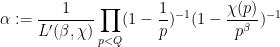
 and plays only a minor role in the analysis). This is a rather complicated formula, but it seems to be virtually the only choice of approximant that allows for bounds such as (7) to hold. (This is the one aspect of the problem where the von Mangoldt theory is simpler than the Möbius theory, as in the former one only needs to work with very rough numbers for which one does not need to make any special accommodations for the behavior at small primes when introducing the Siegel correction term.) With this starting point it is then possible to repeat the analysis of my previous papers with Ben and obtain the pseudopolynomial discorrelation bound
and plays only a minor role in the analysis). This is a rather complicated formula, but it seems to be virtually the only choice of approximant that allows for bounds such as (7) to hold. (This is the one aspect of the problem where the von Mangoldt theory is simpler than the Möbius theory, as in the former one only needs to work with very rough numbers for which one does not need to make any special accommodations for the behavior at small primes when introducing the Siegel correction term.) With this starting point it is then possible to repeat the analysis of my previous papers with Ben and obtain the pseudopolynomial discorrelation bound ![\displaystyle \mathop{\bf E}_{n \in [N]} (\mu - \mu_{\hbox{Siegel}})(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D%29%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+&bg=ffffff&fg=000000&s=0&c=20201002) as before, which when combined with Manners’ inverse theorem gives the doubly logarithmic bound
as before, which when combined with Manners’ inverse theorem gives the doubly logarithmic bound ![\displaystyle \| \mu - \mu_{\hbox{Siegel}} \|_{U^k([N])} \ll (\log\log N)^{-c_k}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%28%5Clog%5Clog+N%29%5E%7B-c_k%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu_{\hbox{Siegel}} \|_{U^k([N])} \ll \log^{-c_k} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c_k%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) seems to play a rather essential component in the proof, even if it is absent in the final statement. We note that this approximant seems to be a useful tool to explore the “illusory world” of the Siegel zero further; see for instance the recent paper of Chinis for some work in this direction.
seems to play a rather essential component in the proof, even if it is absent in the final statement. We note that this approximant seems to be a useful tool to explore the “illusory world” of the Siegel zero further; see for instance the recent paper of Chinis for some work in this direction.
For the analogous problem with the von Mangoldt function (assuming a Siegel zero for sake of discussion), the approximant 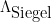
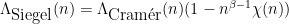
![\displaystyle \| (\Lambda - \Lambda_{\hbox{Siegel}}) 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D%29+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} (\Lambda - \Lambda_{\hbox{Siegel}})(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N) \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D%29%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda_{\hbox{Siegel}} \|_{U^k([N])} \ll \log^{-c_k} N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c_k%7D+N.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda - \Lambda_{\hbox{Siegel}} \|_{U^k([N])} \ll (\log\log N)^{-c_k}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%28%5Clog%5Clog+N%29%5E%7B-c_k%7D.&bg=ffffff&fg=000000&s=0&c=20201002) and are unbounded. There is a standard tool for getting around this issue, now known as the dense model theorem, which is the standard engine powering the transference principle from theorems about bounded functions to theorems about certain types of unbounded functions. However the quantitative versions of the dense model theorem in the literature are expensive and would basically weaken the doubly logarithmic gain here to a triply logarithmic one. Instead, we bypass the dense model theorem and directly transfer the inverse theorem for bounded functions to an inverse theorem for unbounded functions by using the densification approach to transference introduced by Conlon, Fox, and Zhao. This technique turns out to be quantitatively quite efficient (the dependencies of the main parameters in the transference are polynomial in nature), and also has the technical advantage of avoiding the somewhat tricky “correlation condition” present in early transference results which are also not beneficial for quantitative bounds.
and are unbounded. There is a standard tool for getting around this issue, now known as the dense model theorem, which is the standard engine powering the transference principle from theorems about bounded functions to theorems about certain types of unbounded functions. However the quantitative versions of the dense model theorem in the literature are expensive and would basically weaken the doubly logarithmic gain here to a triply logarithmic one. Instead, we bypass the dense model theorem and directly transfer the inverse theorem for bounded functions to an inverse theorem for unbounded functions by using the densification approach to transference introduced by Conlon, Fox, and Zhao. This technique turns out to be quantitatively quite efficient (the dependencies of the main parameters in the transference are polynomial in nature), and also has the technical advantage of avoiding the somewhat tricky “correlation condition” present in early transference results which are also not beneficial for quantitative bounds.
In principle, the above results can be improved for 
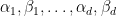
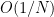
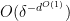
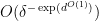
Kaisa Matomäki, Maksym Radziwill, Xuancheng Shao, Joni Teräväinen, and myself have just uploaded to the arXiv our preprint “Singmaster’s conjecture in the interior of Pascal’s triangle“. This paper leverages the theory of exponential sums over primes to make progress on a well known conjecture of Singmaster which asserts that any natural number larger than 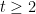
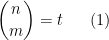
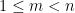 . Currently, the largest number of solutions that is known to be attainable is eight, with equal to
. Currently, the largest number of solutions that is known to be attainable is eight, with equal to 
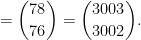
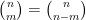 of Pascal’s triangle it is natural to restrict attention to the left half
of Pascal’s triangle it is natural to restrict attention to the left half 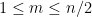 of the triangle.
of the triangle.
Our main result settles this conjecture in the “interior” region of the triangle:
Theorem 1 (Singmaster’s conjecture in the interior of the triangle) Ifand
, there are at most two solutions to (1) in the region
and hence at most four in the region
Also, there is at most one solution in the region
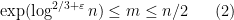

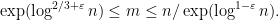
To verify Singmaster’s conjecture in full, it thus suffices in view of this result to verify the conjecture in the boundary region
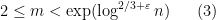
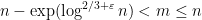 ); we have deleted the
); we have deleted the 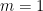 case as it of course automatically supplies exactly one solution to (1). It is in fact possible that for sufficiently large there are no further collisions
case as it of course automatically supplies exactly one solution to (1). It is in fact possible that for sufficiently large there are no further collisions 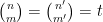 for
for  in the region (3), in which case there would never be more than eight solutions to (1) for sufficiently large . This is latter claim known for bounded values of
in the region (3), in which case there would never be more than eight solutions to (1) for sufficiently large . This is latter claim known for bounded values of 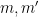 by Beukers, Shorey, and Tildeman, with the main tool used being Siegel’s theorem on integral points.
by Beukers, Shorey, and Tildeman, with the main tool used being Siegel’s theorem on integral points.
The upper bound of two here for the number of solutions in the region (2) is best possible, due to the infinite family of solutions to the equation

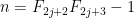 ,
,  and
and 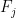 is the
is the  Fibonacci number.
Fibonacci number.
The appearance of the quantity 
To try to control solutions to (1) we use a combination of “Archimedean” and “non-Archimedean” approaches. In the “Archimedean” approach (following earlier work of Kane on this problem) we view 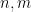
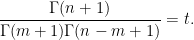 in terms of
in terms of 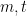 as
as 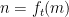
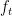 whose asymptotics are easily computable (for instance one has the asymptotic
whose asymptotics are easily computable (for instance one has the asymptotic 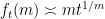 ). One can then view the problem as one of trying to control the number of lattice points on the graph
). One can then view the problem as one of trying to control the number of lattice points on the graph 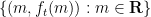 . Here we can take advantage of the fact that in the regime
. Here we can take advantage of the fact that in the regime 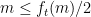 (which corresponds to working in the left half
(which corresponds to working in the left half 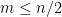 of Pascal’s triangle), the function can be shown to be convex, but not too convex, in the sense that one has both upper and lower bounds on the second derivative of (in fact one can show that
of Pascal’s triangle), the function can be shown to be convex, but not too convex, in the sense that one has both upper and lower bounds on the second derivative of (in fact one can show that 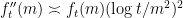 ). This can be used to preclude the possibility of having a cluster of three or more nearby lattice points on the graph , basically because the area subtended by the triangle connecting three of these points would lie between and , contradicting Pick’s theorem. Developing these ideas, we were able to show
). This can be used to preclude the possibility of having a cluster of three or more nearby lattice points on the graph , basically because the area subtended by the triangle connecting three of these points would lie between and , contradicting Pick’s theorem. Developing these ideas, we were able to show
Proposition 2 Letis a solution to (1) in the left half
to this equation in the left half with
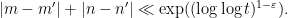
Again, the example of (4) shows that a cluster of two solutions is certainly possible; the convexity argument only kicks in once one has a cluster of three or more solutions.
To finish the proof of Theorem 1, one has to show that any two solutions 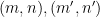
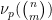
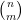
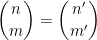

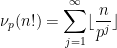
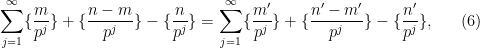
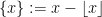 denotes the fractional part of . (These sums are not truly infinite, because the summands vanish once
denotes the fractional part of . (These sums are not truly infinite, because the summands vanish once  is larger than
is larger than 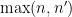 .)
.)
A key idea in our approach is to view this condition (6) statistically, for instance by viewing ![{[P, P + P \log^{-100} P]}](https://s0.wp.com/latex.php?latex=%7B%5BP%2C+P+%2B+P+%5Clog%5E%7B-100%7D+P%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

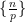
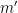
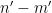

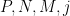 , where . Fortunately, the methods of Vinogradov (which more generally can handle sums such as
, where . Fortunately, the methods of Vinogradov (which more generally can handle sums such as 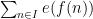 and
and 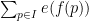 for various analytic functions ) can give useful bounds on such sums as long as
for various analytic functions ) can give useful bounds on such sums as long as  and are not too large compared to ; more specifically, Vinogradov’s estimates are non-trivial in the regime
and are not too large compared to ; more specifically, Vinogradov’s estimates are non-trivial in the regime 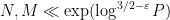 , and this ultimately leads to a distance bound
, and this ultimately leads to a distance bound  in the left half of Pascal’s triangle, as well as the variant bound
in the left half of Pascal’s triangle, as well as the variant bound 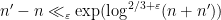
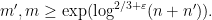 , we can conclude Theorem 1.
, we can conclude Theorem 1.
A modification of the arguments also gives similar results for the equation

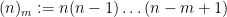 is the falling factorial:
is the falling factorial:
Theorem 3 If

Again the upper bound of two is best possible, thanks to identities such as

Recent Comments