
You are currently browsing the monthly archive for November 2010.
One of the key difficulties in performing analysis in infinite-dimensional function spaces, as opposed to finite-dimensional vector spaces, is that the Bolzano-Weierstrass theorem no longer holds: a bounded sequence in an infinite-dimensional function space need not have any convergent subsequences (when viewed using the strong topology). To put it another way, the closed unit ball in an infinite-dimensional function space usually fails to be (sequentially) compact.
As compactness is such a useful property to have in analysis, various tools have been developed over the years to try to salvage some sort of substitute for the compactness property in infinite-dimensional spaces. One of these tools is concentration compactness, which was discussed previously on this blog. This can be viewed as a compromise between weak compactness (which is true in very general circumstances, but is often too weak for applications) and strong compactness (which would be very useful in applications, but is usually false), in which one obtains convergence in an intermediate sense that involves a group of symmetries acting on the function space in question.
Concentration compactness is usually stated and proved in the language of standard analysis: epsilons and deltas, limits and supremas, and so forth. In this post, I wanted to note that one could also state and prove the basic foundations of concentration compactness in the framework of nonstandard analysis, in which one now deals with infinitesimals and ultralimits instead of epsilons and ordinary limits. This is a fairly mild change of viewpoint, but I found it to be informative to view this subject from a slightly different perspective. The nonstandard proofs require a fair amount of general machinery to set up, but conversely, once all the machinery is up and running, the proofs become slightly shorter, and can exploit tools from (standard) infinitary analysis, such as orthogonal projections in Hilbert spaces, or the continuous-pure point decomposition of measures. Because of the substantial amount of setup required, nonstandard proofs tend to have significantly more net complexity than their standard counterparts when it comes to basic results (such as those presented in this post), but the gap between the two narrows when the results become more difficult, and for particularly intricate and deep results it can happen that nonstandard proofs end up being simpler overall than their standard analogues, particularly if the nonstandard proof is able to tap the power of some existing mature body of infinitary mathematics (e.g. ergodic theory, measure theory, Hilbert space theory, or topological group theory) which is difficult to directly access in the standard formulation of the argument.
Read the rest of this entry »
Many structures in mathematics are incomplete in one or more ways. For instance, the field of rationals 



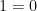
Similarly, the rationals 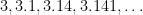

A third type of incompleteness is that of logical incompleteness, which applies now to formal theories rather than to fields or metric spaces. For instance, Zermelo-Frankel-Choice (ZFC) set theory is logically incomplete, because there exist statements (such as the consistency of ZFC) which could potentially be provable by the theory (because it does not lead to a contradiction, or at least so we believe, just from the axioms and deductive rules of the theory), but is not actually provable in this theory.
A fourth type of incompleteness, which is slightly less well known than the above three, is what I will call elementary incompleteness (and which model theorists call the failure of the countable saturation property). It applies to any structure that is describable by a first-order language, such as a field, a metric space, or a universe of sets. For instance, in the language of ordered real fields, the real line 


In each of these cases, though, it is possible to start with an incomplete structure and complete it to a much larger structure to eliminate the incompleteness. For instance, starting with an arbitrary field 
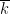
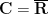
Similarly, starting with an arbitrary metric space 
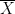

In a similar vein, we have the Gödel completeness theorem, which implies (among other things) that for any consistent first-order theory 




Finally, if one starts with an arbitrary structure 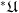
As mentioned earlier, completion tends to make a space much larger and more complicated. If one algebraically completes a finite field, for instance, one necessarily obtains an infinite field as a consequence. If one metrically completes a countable metric space with no isolated points, such as 
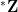
However, there are substantial benefits to working in the completed structure which can make it well worth the massive increase in size. For instance, by working in the algebraic completion of a field, one gains access to the full power of algebraic geometry. By working in the metric completion of a metric space, one gains access to powerful tools of real analysis, such as the Baire category theorem, the Heine-Borel theorem, and (in the case of Euclidean completions) the Bolzano-Weierstrass theorem. By working in a logically and elementarily completed theory (aka a saturated model) of a first-order theory, one gains access to the branch of model theory known as definability theory, which allows one to analyse the structure of definable sets in much the same way that algebraic geometry allows one to analyse the structure of algebraic sets. Finally, when working in an elementary completion of a structure, one gains a sequential compactness property, analogous to the Bolzano-Weierstrass theorem, which can be interpreted as the foundation for much of nonstandard analysis, as well as providing a unifying framework to describe various correspondence principles between finitary and infinitary mathematics.
In this post, I wish to expand upon these above points with regard to elementary completion, and to present nonstandard analysis as a completion of standard analysis in much the same way as, say, complex algebra is a completion of real algebra, or real metric geometry is a completion of rational metric geometry.
Combinatorial incidence geometry is the study of the possible combinatorial configurations between geometric objects such as lines and circles. One of the basic open problems in the subject has been the Erdős distance problem, posed in 1946:
Problem 1 (Erdős distance problem) Let
be a large natural number. What is the least number
of distances that are determined by
in the plane?
Erdős called this least number 
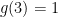
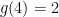

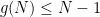

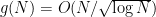
On the other hand, lower bounds are more difficult to obtain. As observed by Erdős, an easy argument, ultimately based on the incidence geometry fact that any two circles intersect in at most two points, gives the lower bound 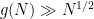



Very recently, though, Guth and Katz have obtained a near-optimal result:
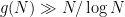 .
. The proof neatly combines together several powerful and modern tools in a new way: a recent geometric reformulation of the problem due to Elekes and Sharir; the polynomial method as used recently by Dvir, Guth, and Guth-Katz on related incidence geometry problems (and discussed previously on this blog); and the somewhat older method of cell decomposition (also discussed on this blog). A key new insight is that the polynomial method (and more specifically, the polynomial Ham Sandwich theorem, also discussed previously on this blog) can be used to efficiently create cells.
In this post, I thought I would sketch some of the key ideas used in the proof, though I will not give the full argument here (the paper itself is largely self-contained, well motivated, and of only moderate length). In particular I will not go through all the various cases of configuration types that one has to deal with in the full argument, but only some illustrative special cases.
To simplify the exposition, I will repeatedly rely on “pigeonholing cheats”. A typical such cheat: if I have 

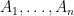
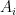
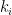
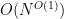
![{[k,2k]}](https://s0.wp.com/latex.php?latex=%7B%5Bk%2C2k%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
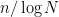
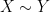
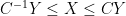



I will also use asymptotic notation rather loosely, to avoid cluttering the exposition with a certain amount of routine but tedious bookkeeping of constants. In particular, I will use the informal notation 
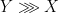

See also Janos Pach’s recent reaction to the Guth-Katz paper on Kalai’s blog.
[Some advertising on behalf of my department. The inaugural 2009 scholarship was announced on this blog last year. – T.]
Last year, the UCLA mathematics department launched a scholarship opportunity for entering freshman students with exceptional background and promise in mathematics. We intend to offer one new scholarship every year.
The UCLA Math Undergraduate Merit Scholarship provides for full tuition, and a room and board allowance for 4 years. In addition, scholarship recipients follow an individualized accelerated program of study, as determined after consultation with UCLA faculty. [For instance, this year’s scholarship recipient is currently taking my graduate real analysis class – T.] The program of study leads to a Masters degree in Mathematics in four years.
More information and an application form for the scholarship can be found on the web at:
To be considered for Fall 2011, candidates must apply for the scholarship and also for admission to UCLA on or before November 30, 2010.
Hans Lindblad and I have just uploaded to the arXiv our joint paper “Asymptotic decay for a one-dimensional nonlinear wave equation“, submitted to Analysis & PDE. This paper, to our knowledge, is the first paper to analyse the asymptotic behaviour of the one-dimensional defocusing nonlinear wave equation

where 
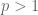
![E[u] := \int_{{\bf R}} \frac{1}{2} |u_t|^2 + \frac{1}{2} |u_x|^2 + \frac{1}{p+1} |u|^{p+1}\ dx](https://s0.wp.com/latex.php?latex=E%5Bu%5D+%3A%3D+%5Cint_%7B%7B%5Cbf+R%7D%7D+%5Cfrac%7B1%7D%7B2%7D+%7Cu_t%7C%5E2+%2B+%5Cfrac%7B1%7D%7B2%7D+%7Cu_x%7C%5E2+%2B+%5Cfrac%7B1%7D%7Bp%2B1%7D+%7Cu%7C%5E%7Bp%2B1%7D%5C+dx&bg=ffffff&fg=545454&s=0&c=20201002)
is finite, will exist globally for all time (and remain finite energy, of course). In particular, from the one-dimensional Gagliardo-Nirenberg inequality (a variant of the Sobolev embedding theorem), such solutions will remain uniformly bounded in 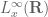
However, this leaves open the question of the asymptotic behaviour of such solutions in the limit as 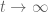


On the other hand, the solution to the linear one-dimensional wave equation

does not exhibit any decay in time; as one learns in an undergraduate PDE class, the general (finite energy) solution to such an equation is given by the superposition of two travelling waves,

where 
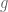

Nevertheless, we were able to establish a nonlinear decay effect for equation (1), caused more by the nonlinear right-hand side of (1) than by the linear left-hand side, to obtain
Theorem 1. (Average
decay) If
is a finite energy solution to (1), then
tends to zero as
.
Actually we prove a slightly stronger statement than Theorem 1, in that the decay is uniform among all solutions with a given energy bound, but I will stick to the above formulation of the main result for simplicity.
Informally, the reason for the nonlinear decay is as follows. The linear evolution tries to force waves to move at constant velocity (indeed, from (3) we see that linear waves move at the speed of light 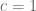
Now, just because the linear wave equation propagates along constant velocity worldlines, this does not mean that the nonlinear wave equation does too; one could imagine that a wave packet could propagate along a more complicated trajectory 


And now we deploy a trick which appears to be new to the field of nonlinear wave equations: we invoke the Rademacher differentiation theorem (or Lebesgue differentiation theorem), which asserts that Lipschitz continuous functions are almost everywhere differentiable. (By coincidence, I am teaching this theorem in my current course, both in one dimension (which is the case of interest here) and in higher dimensions.) A compactness argument allows one to extract a quantitative estimate from this theorem (cf. this earlier blog post of mine) which, roughly speaking, tells us that there are large portions of the trajectory
There is still scope for further work to be done on the asymptotics. In particular, we still do not have a good understanding of what the asymptotic profile of the solution should be, even in the perturbative regime; standard nonlinear geometric optics methods do not appear to work very well due to the extremely weak decay.
This is the third in a series of posts on the “no self-defeating object” argument in mathematics – a powerful and useful argument based on formalising the observation that any object or structure that is so powerful that it can “defeat” even itself, cannot actually exist. This argument is used to establish many basic impossibility results in mathematics, such as Gödel’s theorem that it is impossible for any sufficiently sophisticated formal axiom system to prove its own consistency, Turing’s theorem that it is impossible for any sufficiently sophisticated programming language to solve its own halting problem, or Cantor’s theorem that it is impossible for any set to enumerate its own power set (and as a corollary, the natural numbers cannot enumerate the real numbers).
As remarked in the previous posts, many people who encounter these theorems can feel uneasy about their conclusions, and their method of proof; this seems to be particularly the case with regard to Cantor’s result that the reals are uncountable. In the previous post in this series, I focused on one particular aspect of the standard proofs which one might be uncomfortable with, namely their counterfactual nature, and observed that many of these proofs can be largely (though not completely) converted to non-counterfactual form. However, this does not fully dispel the sense that the conclusions of these theorems – that the reals are not countable, that the class of all sets is not itself a set, that truth cannot be captured by a predicate, that consistency is not provable, etc. – are highly unintuitive, and even objectionable to “common sense” in some cases.
How can intuition lead one to doubt the conclusions of these mathematical results? I believe that one reason is because these results are sensitive to the amount of vagueness in one’s mental model of mathematics. In the formal mathematical world, where every statement is either absolutely true or absolutely false with no middle ground, and all concepts require a precise definition (or at least a precise axiomatisation) before they can be used, then one can rigorously state and prove Cantor’s theorem, Gödel’s theorem, and all the other results mentioned in the previous posts without difficulty. However, in the vague and fuzzy world of mathematical intuition, in which one’s impression of the truth or falsity of a statement may be influenced by recent mental reference points, definitions are malleable and blurry with no sharp dividing lines between what is and what is not covered by such definitions, and key mathematical objects may be incompletely specified and thus “moving targets” subject to interpretation, then one can argue with some degree of justification that the conclusions of the above results are incorrect; in the vague world, it seems quite plausible that one can always enumerate all the real numbers “that one needs to”, one can always justify the consistency of one’s reasoning system, one can reason using truth as if it were a predicate, and so forth. The impossibility results only kick in once one tries to clear away the fog of vagueness and nail down all the definitions and mathematical statements precisely. (To put it another way, the no-self-defeating object argument relies very much on the disconnected, definite, and absolute nature of the boolean truth space 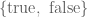

Recent Comments