
You are currently browsing the tag archive for the ‘Kaisa Matomaki’ tag.
Kaisa Matomäki, Xuancheng Shao, Joni Teräväinen, and myself have just uploaded to the arXiv our preprint “Higher uniformity of arithmetic functions in short intervals I. All intervals“. This paper investigates the higher order (Gowers) uniformity of standard arithmetic functions in analytic number theory (and specifically, the Möbius function 

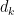
![{(X,X+H]}](https://s0.wp.com/latex.php?latex=%7B%28X%2CX%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


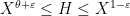
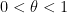

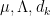
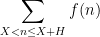
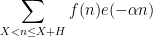
 , where
, where 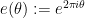 . For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations
. For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations 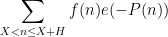
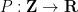 is a polynomial of some fixed degree, or more generally
is a polynomial of some fixed degree, or more generally 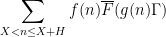
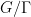 is a nilmanifold of fixed degree and dimension (and with some control on structure constants),
is a nilmanifold of fixed degree and dimension (and with some control on structure constants), 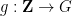 is a polynomial map, and
is a polynomial map, and  is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
Traditionally, asymptotics for such sums are expressed in terms of a “main term” of some arithmetic nature, plus an error term that is estimated in magnitude. For instance, a sum such as 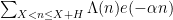
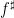
 variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
- For the Möbius function
, as per the Möbius pseudorandomness conjecture. (One could choose a more sophisticated approximant in the presence of a Siegel zero, as I did with Joni in this recent paper, but we do not do so here.)
- For the von Mangoldt function
, where
and
.
- For the divisor functions
for some explicit polynomials
, chosen so that
and
The objective is then to obtain bounds on sums such as (1) that improve upon the “trivial bound” that one can get with the triangle inequality and standard number theory bounds such as the Brun-Titchmarsh inequality. For 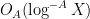


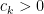

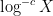

Our main estimates on sums of the form (1) work in the following ranges:
- For
, one can obtain strongly logarithmic savings on (1) for
, and power savings for
.
- For
, one can obtain weakly logarithmic savings for
.
- For
, one can obtain power savings for
.
- For
, one can obtain power savings for
.
Conjecturally, one should be able to obtain power savings in all cases, and lower 
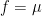
By combining these results with tools from additive combinatorics, one can obtain a number of applications:
- Direct insertion of our bounds in the recent work of Kanigowski, Lemanczyk, and Radziwill on the prime number theorem on dynamical systems that are analytic skew products gives some improvements in the exponents there.
- We can obtain a “short interval” version of a multiple ergodic theorem along primes established by Frantzikinakis-Host-Kra and Wooley-Ziegler, in which we average over intervals of the form
.
- We can obtain a “short interval” version of the “linear equations in primes” asymptotics obtained by Ben Green, Tamar Ziegler, and myself in this sequence of papers, where the variables in these equations lie in short intervals
We now briefly discuss some of the ingredients of proof of our main results. The first step is standard, using combinatorial decompositions (based on the Heath-Brown identity and (for the 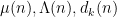
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoff
that is not too large;
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoffs
that are not too close to
or to
- Type
sums, which are basically of the form
for some weights
The precise ranges of the cutoffs 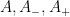
The Type
For the Type 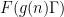
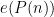


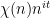



 range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
For the type
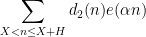

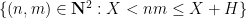 into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as
into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as  on the majority of these progressions. As it turns out, this strategy works well in the regime
on the majority of these progressions. As it turns out, this strategy works well in the regime 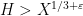 unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our
unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our 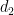 result can be as low as
result can be as low as  .
.
In a sequel to this paper (currently in preparation), we will obtain analogous results for almost all intervals ![{(x,x+H]}](https://s0.wp.com/latex.php?latex=%7B%28x%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[X,2X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Kaisa Matomäki, Maksym Radziwill, Xuancheng Shao, Joni Teräväinen, and myself have just uploaded to the arXiv our preprint “Singmaster’s conjecture in the interior of Pascal’s triangle“. This paper leverages the theory of exponential sums over primes to make progress on a well known conjecture of Singmaster which asserts that any natural number larger than 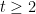

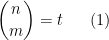
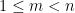 . Currently, the largest number of solutions that is known to be attainable is eight, with equal to
. Currently, the largest number of solutions that is known to be attainable is eight, with equal to 
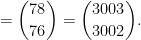
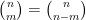 of Pascal’s triangle it is natural to restrict attention to the left half
of Pascal’s triangle it is natural to restrict attention to the left half 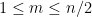 of the triangle.
of the triangle.
Our main result settles this conjecture in the “interior” region of the triangle:
Theorem 1 (Singmaster’s conjecture in the interior of the triangle) Ifand
, there are at most two solutions to (1) in the region
and hence at most four in the region
Also, there is at most one solution in the region
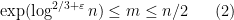

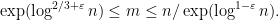
To verify Singmaster’s conjecture in full, it thus suffices in view of this result to verify the conjecture in the boundary region
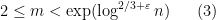
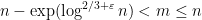 ); we have deleted the
); we have deleted the 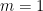 case as it of course automatically supplies exactly one solution to (1). It is in fact possible that for sufficiently large there are no further collisions
case as it of course automatically supplies exactly one solution to (1). It is in fact possible that for sufficiently large there are no further collisions 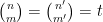 for
for  in the region (3), in which case there would never be more than eight solutions to (1) for sufficiently large . This is latter claim known for bounded values of
in the region (3), in which case there would never be more than eight solutions to (1) for sufficiently large . This is latter claim known for bounded values of 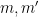 by Beukers, Shorey, and Tildeman, with the main tool used being Siegel’s theorem on integral points.
by Beukers, Shorey, and Tildeman, with the main tool used being Siegel’s theorem on integral points.
The upper bound of two here for the number of solutions in the region (2) is best possible, due to the infinite family of solutions to the equation

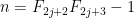 ,
,  and
and 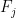 is the
is the  Fibonacci number.
Fibonacci number.
The appearance of the quantity 
To try to control solutions to (1) we use a combination of “Archimedean” and “non-Archimedean” approaches. In the “Archimedean” approach (following earlier work of Kane on this problem) we view 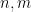
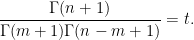 in terms of
in terms of 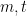 as
as 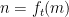
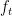 whose asymptotics are easily computable (for instance one has the asymptotic
whose asymptotics are easily computable (for instance one has the asymptotic 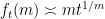 ). One can then view the problem as one of trying to control the number of lattice points on the graph
). One can then view the problem as one of trying to control the number of lattice points on the graph 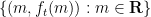 . Here we can take advantage of the fact that in the regime
. Here we can take advantage of the fact that in the regime 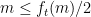 (which corresponds to working in the left half
(which corresponds to working in the left half 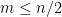 of Pascal’s triangle), the function can be shown to be convex, but not too convex, in the sense that one has both upper and lower bounds on the second derivative of (in fact one can show that
of Pascal’s triangle), the function can be shown to be convex, but not too convex, in the sense that one has both upper and lower bounds on the second derivative of (in fact one can show that 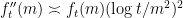 ). This can be used to preclude the possibility of having a cluster of three or more nearby lattice points on the graph , basically because the area subtended by the triangle connecting three of these points would lie between and
). This can be used to preclude the possibility of having a cluster of three or more nearby lattice points on the graph , basically because the area subtended by the triangle connecting three of these points would lie between and  , contradicting Pick’s theorem. Developing these ideas, we were able to show
, contradicting Pick’s theorem. Developing these ideas, we were able to show
Proposition 2 Let, and suppose
is a solution to (1) in the left half
to this equation in the left half with
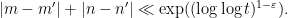
Again, the example of (4) shows that a cluster of two solutions is certainly possible; the convexity argument only kicks in once one has a cluster of three or more solutions.
To finish the proof of Theorem 1, one has to show that any two solutions 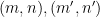

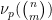
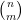
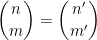

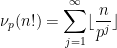
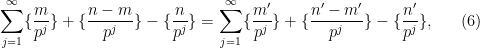
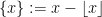 denotes the fractional part of . (These sums are not truly infinite, because the summands vanish once
denotes the fractional part of . (These sums are not truly infinite, because the summands vanish once  is larger than
is larger than 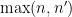 .)
.)
A key idea in our approach is to view this condition (6) statistically, for instance by viewing ![{[P, P + P \log^{-100} P]}](https://s0.wp.com/latex.php?latex=%7B%5BP%2C+P+%2B+P+%5Clog%5E%7B-100%7D+P%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

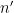
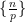

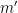
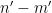

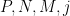 , where . Fortunately, the methods of Vinogradov (which more generally can handle sums such as
, where . Fortunately, the methods of Vinogradov (which more generally can handle sums such as 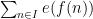 and
and 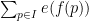 for various analytic functions ) can give useful bounds on such sums as long as
for various analytic functions ) can give useful bounds on such sums as long as  and
and  are not too large compared to ; more specifically, Vinogradov’s estimates are non-trivial in the regime
are not too large compared to ; more specifically, Vinogradov’s estimates are non-trivial in the regime 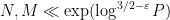 , and this ultimately leads to a distance bound
, and this ultimately leads to a distance bound  in the left half of Pascal’s triangle, as well as the variant bound
in the left half of Pascal’s triangle, as well as the variant bound 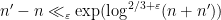
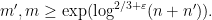 , we can conclude Theorem 1.
, we can conclude Theorem 1.
A modification of the arguments also gives similar results for the equation

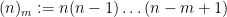 is the falling factorial:
is the falling factorial:
Theorem 3 If

Again the upper bound of two is best possible, thanks to identities such as
Kaisa Matomäki, Maksym Radziwill, Joni Teräväinen, Tamar Ziegler and I have uploaded to the arXiv our paper Higher uniformity of bounded multiplicative functions in short intervals on average. This paper (which originated from a working group at an AIM workshop on Sarnak’s conjecture) focuses on the local Fourier uniformity conjecture for bounded multiplicative functions such as the Liouville function 
![\displaystyle \int_0^X \| \lambda \|_{U^k([x,x+H])}\ dx = o(X) \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint_0%5EX+%5C%7C+%5Clambda+%5C%7C_%7BU%5Ek%28%5Bx%2Cx%2BH%5D%29%7D%5C+dx+%3D+o%28X%29+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
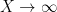 for any fixed
for any fixed  and any
and any 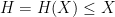 that goes to infinity as , where
that goes to infinity as , where ![{U^k([x,x+H])}](https://s0.wp.com/latex.php?latex=%7BU%5Ek%28%5Bx%2Cx%2BH%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) is the (normalized) Gowers uniformity norm. Among other things this conjecture implies (logarithmically averaged version of) the Chowla and Sarnak conjectures for the Liouville function (or the Möbius function), see this previous blog post.
is the (normalized) Gowers uniformity norm. Among other things this conjecture implies (logarithmically averaged version of) the Chowla and Sarnak conjectures for the Liouville function (or the Möbius function), see this previous blog post.
The conjecture gets more difficult as 

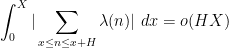 ) in a landmark paper of Matomäki and Radziwill, discussed for instance in this blog post.
) in a landmark paper of Matomäki and Radziwill, discussed for instance in this blog post.
For 
 (and it would be a major breakthrough in particular if one could obtain this bound for as small as
(and it would be a major breakthrough in particular if one could obtain this bound for as small as  for any fixed , particularly if applicable to more general bounded multiplicative functions than , as this would have new implications for a generalization of the Chowla conjecture known as the Elliott conjecture). Recently, Kaisa, Maks and myself were able to establish this conjecture in the range
for any fixed , particularly if applicable to more general bounded multiplicative functions than , as this would have new implications for a generalization of the Chowla conjecture known as the Elliott conjecture). Recently, Kaisa, Maks and myself were able to establish this conjecture in the range  (in fact we have since worked out in the current paper that we can get as small as
(in fact we have since worked out in the current paper that we can get as small as  ). In our current paper we establish Fourier uniformity conjecture for higher for the same range of . This in particular implies local orthogonality to polynomial phases,
). In our current paper we establish Fourier uniformity conjecture for higher for the same range of . This in particular implies local orthogonality to polynomial phases, 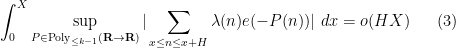
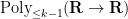 denotes the polynomials of degree at most
denotes the polynomials of degree at most 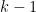 , but the full conjecture is a bit stronger than this, establishing the more general statement
, but the full conjecture is a bit stronger than this, establishing the more general statement 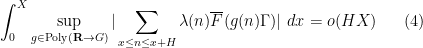 filtered nilmanifold and Lipschitz function , where
filtered nilmanifold and Lipschitz function , where  now ranges over polynomial maps from
now ranges over polynomial maps from  to . The method of proof follows the same general strategy as in the previous paper with Kaisa and Maks. (The equivalence of (4) and (1) follows from the inverse conjecture for the Gowers norms, proven in this paper.) We quickly sketch first the proof of (3), using very informal language to avoid many technicalities regarding the precise quantitative form of various estimates. If the estimate (3) fails, then we have the correlation estimate
to . The method of proof follows the same general strategy as in the previous paper with Kaisa and Maks. (The equivalence of (4) and (1) follows from the inverse conjecture for the Gowers norms, proven in this paper.) We quickly sketch first the proof of (3), using very informal language to avoid many technicalities regarding the precise quantitative form of various estimates. If the estimate (3) fails, then we have the correlation estimate 
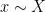 and some polynomial
and some polynomial 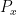 depending on . The difficulty here is to understand how can depend on . We write the above correlation estimate more suggestively as
depending on . The difficulty here is to understand how can depend on . We write the above correlation estimate more suggestively as ![\displaystyle \lambda(n) \sim_{[x,x+H]} e(P_x(n)).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clambda%28n%29+%5Csim_%7B%5Bx%2Cx%2BH%5D%7D+e%28P_x%28n%29%29.&bg=ffffff&fg=000000&s=0&c=20201002)
 at small primes , one expects to have a relation of the form
at small primes , one expects to have a relation of the form ![\displaystyle e(P_{x'}(p'n)) \sim_{[x/p,x/p+H/p]} e(P_x(pn)) \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e%28P_%7Bx%27%7D%28p%27n%29%29+%5Csim_%7B%5Bx%2Fp%2Cx%2Fp%2BH%2Fp%5D%7D+e%28P_x%28pn%29%29+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
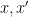 for which
for which 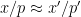 for some small primes
for some small primes 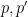 . (This can be formalised using an inequality of Elliott related to the Turan-Kubilius theorem.) This gives a relationship between and
. (This can be formalised using an inequality of Elliott related to the Turan-Kubilius theorem.) This gives a relationship between and  for “edges” in a rather sparse “graph” connecting the elements of say
for “edges” in a rather sparse “graph” connecting the elements of say ![{[X/2,X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2F2%2CX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Using some graph theory one can locate some non-trivial “cycles” in this graph that eventually lead (in conjunction to a certain technical but important “Chinese remainder theorem” step to modify the to eliminate a rather serious “aliasing” issue that was already discussed in this previous post) to obtain functional equations of the form
. Using some graph theory one can locate some non-trivial “cycles” in this graph that eventually lead (in conjunction to a certain technical but important “Chinese remainder theorem” step to modify the to eliminate a rather serious “aliasing” issue that was already discussed in this previous post) to obtain functional equations of the form 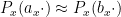
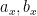 , where
, where 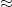 should be viewed as a first approximation (ignoring a certain “profinite” or “major arc” term for simplicity) as “differing by a slowly varying polynomial” and the polynomials should now be viewed as taking values on the reals rather than the integers. This functional equation can be solved to obtain a relation of the form
should be viewed as a first approximation (ignoring a certain “profinite” or “major arc” term for simplicity) as “differing by a slowly varying polynomial” and the polynomials should now be viewed as taking values on the reals rather than the integers. This functional equation can be solved to obtain a relation of the form 
 of polynomial size, and with further analysis of the relation (5) one can make basically independent of . This simplifies (3) to something like
of polynomial size, and with further analysis of the relation (5) one can make basically independent of . This simplifies (3) to something like 
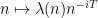 is a bounded multiplicative function). (Actually because of the profinite term mentioned previously, one also has to insert a Dirichlet character of bounded conductor into this latter conclusion, but we will ignore this technicality.)
is a bounded multiplicative function). (Actually because of the profinite term mentioned previously, one also has to insert a Dirichlet character of bounded conductor into this latter conclusion, but we will ignore this technicality.)
Now we apply the same strategy to (4). For abelian 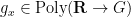
 is rather technical and will not be detailed here. A new difficulty arises in that there are some unwanted solutions to this equation, such as
is rather technical and will not be detailed here. A new difficulty arises in that there are some unwanted solutions to this equation, such as 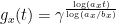
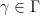 , which do not necessarily lead to multiplicative characters like
, which do not necessarily lead to multiplicative characters like 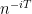 as in the polynomial case, but instead to some unfriendly looking “generalized multiplicative characters” (think of
as in the polynomial case, but instead to some unfriendly looking “generalized multiplicative characters” (think of  as a rough caricature). To avoid this problem, we rework the graph theory portion of the argument to produce not just one functional equation of the form (6)for each , but many, leading to dilation invariances
as a rough caricature). To avoid this problem, we rework the graph theory portion of the argument to produce not just one functional equation of the form (6)for each , but many, leading to dilation invariances 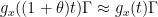 . From a certain amount of Lie algebra theory (ultimately arising from an understanding of the behaviour of the exponential map on nilpotent matrices, and exploiting the hypothesis that is non-abelian) one can conclude that (after some initial preparations to avoid degenerate cases)
. From a certain amount of Lie algebra theory (ultimately arising from an understanding of the behaviour of the exponential map on nilpotent matrices, and exploiting the hypothesis that is non-abelian) one can conclude that (after some initial preparations to avoid degenerate cases)  must behave like
must behave like  for some central element
for some central element 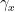 of . This eventually brings one back to the multiplicative characters that arose in the polynomial case, and the arguments now proceed as before.
of . This eventually brings one back to the multiplicative characters that arose in the polynomial case, and the arguments now proceed as before.
We give two applications of this higher order Fourier uniformity. One regards the growth of the number
 sign patterns in the Liouville function. The Chowla conjecture implies that
sign patterns in the Liouville function. The Chowla conjecture implies that  , but even the weaker conjecture of Sarnak that
, but even the weaker conjecture of Sarnak that  for some remains open. Until recently, the best asymptotic lower bound on
for some remains open. Until recently, the best asymptotic lower bound on 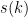 was
was  , due to McNamara; with our result, we can now show
, due to McNamara; with our result, we can now show  for any (in fact we can get
for any (in fact we can get 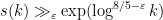 for any ). The idea is to repeat the now-standard argument to exploit multiplicativity at small primes to deduce Chowla-type conjectures from Fourier uniformity conjectures, noting that the Chowla conjecture would give all the sign patterns one could hope for. The usual argument here uses the “entropy decrement argument” to eliminate a certain error term (involving the large but mean zero factor
for any ). The idea is to repeat the now-standard argument to exploit multiplicativity at small primes to deduce Chowla-type conjectures from Fourier uniformity conjectures, noting that the Chowla conjecture would give all the sign patterns one could hope for. The usual argument here uses the “entropy decrement argument” to eliminate a certain error term (involving the large but mean zero factor  ). However the observation is that if there are extremely few sign patterns of length , then the entropy decrement argument is unnecessary (there isn’t much entropy to begin with), and a more low-tech moment method argument (similar to the derivation of Chowla’s conjecture from Sarnak’s conjecture, as discussed for instance in this post) gives enough of Chowla’s conjecture to produce plenty of length sign patterns. If there are not extremely few sign patterns of length then we are done anyway. One quirk of this argument is that the sign patterns it produces may only appear exactly once; in contrast with preceding arguments, we were not able to produce a large number of sign patterns that each occur infinitely often.
). However the observation is that if there are extremely few sign patterns of length , then the entropy decrement argument is unnecessary (there isn’t much entropy to begin with), and a more low-tech moment method argument (similar to the derivation of Chowla’s conjecture from Sarnak’s conjecture, as discussed for instance in this post) gives enough of Chowla’s conjecture to produce plenty of length sign patterns. If there are not extremely few sign patterns of length then we are done anyway. One quirk of this argument is that the sign patterns it produces may only appear exactly once; in contrast with preceding arguments, we were not able to produce a large number of sign patterns that each occur infinitely often.
The second application is to obtain cancellation for various polynomial averages involving the Liouville function
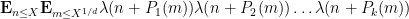
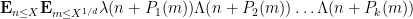
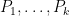 are polynomials of degree at most
are polynomials of degree at most  , no two of which differ by a constant (the latter is essential to avoid having to establish the Chowla or Hardy-Littlewood conjectures, which of course remain open). Results of this type were previously obtained by Tamar Ziegler and myself in the “true complexity zero” case when the polynomials had distinct degrees, in which one could use the theory of Matomäki and Radziwill; now that higher is available at the scale
, no two of which differ by a constant (the latter is essential to avoid having to establish the Chowla or Hardy-Littlewood conjectures, which of course remain open). Results of this type were previously obtained by Tamar Ziegler and myself in the “true complexity zero” case when the polynomials had distinct degrees, in which one could use the theory of Matomäki and Radziwill; now that higher is available at the scale 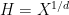 we can now remove this restriction.
we can now remove this restriction.
Kaisa Matomäki, Maksym Radziwill, and I just uploaded to the arXiv our paper “Fourier uniformity of bounded multiplicative functions in short intervals on average“. This paper is the outcome of our attempts during the MSRI program in analytic number theory last year to attack the local Fourier uniformity conjecture for the Liouville function

whenever 
![{[x,x+H]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
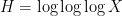

The local Fourier uniformity conjecture asserts the stronger asymptotic

under the same hypotheses on

This particular bound also follows from some slightly different arguments of Joni Teräväinen and myself, but the implication would also work for other non-pretentious bounded multiplicative functions, whereas the arguments of Joni and myself rely more heavily on the specific properties of the Liouville function (in particular that 
There is also a higher order version of the local Fourier uniformity conjecture in which the linear phase 
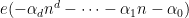

The main result of the current paper is to obtain some cases of the local Fourier uniformity conjecture:
Theorem 1 The asymptotic (2) is true when
for a fixed
.
Previously this was known for 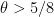


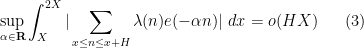
of (2) for any
Unfortunately, the restriction 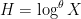

whenever
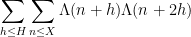
is only known in the range 
We now give an informal description of the strategy of proof of the theorem (though for numerous technical reasons, the actual proof deviates in some respects from the description given here). If (2) failed, then for many values of ![{x \in [X,2X]}](https://s0.wp.com/latex.php?latex=%7Bx+%5Cin+%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

for some frequency 
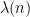


for ![{n \in [x,x+H]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5Bx%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As mentioned before, the main difficulty here is to understand how 
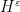


for ![{n \in [x/p, x/p + H/p]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5Bx%2Fp%2C+x%2Fp+%2B+H%2Fp%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now let ![{x, y \in [X,2X]}](https://s0.wp.com/latex.php?latex=%7Bx%2C+y+%5Cin+%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
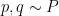


Then we have both
and

on essentially the same range of 
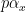


Comparing this with (5) one is led to the expectation that
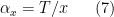
would solve (6) if 

A key obstacle in solving (6) efficiently is the fact that one only knows that 

whenever ![{x,y \in [X,2X]}](https://s0.wp.com/latex.php?latex=%7Bx%2Cy+%5Cin+%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Now suppose that we have ![{y,y' \in [X,2X]}](https://s0.wp.com/latex.php?latex=%7By%2Cy%27+%5Cin+%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

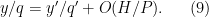
For every prime 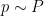
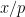


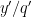

and

and thus by the triangle inequality we have
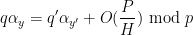
for all
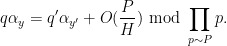
In practice, in the regime

whenever
Now let 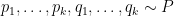

is small but non-zero. If
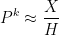
(where one is somewhat loose about what 
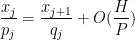
for 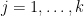
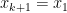

which telescopes to

and thus

and hence

In particular, for each

for some 

whenever ![{y, y' \in [X,2X]}](https://s0.wp.com/latex.php?latex=%7By%2C+y%27+%5Cin+%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now imagine a “graph” in which the vertices are elements 
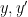

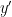

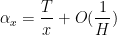
for most 
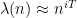
on

But this can be shown to contradict the Matomäki-Radziwill theorem (because the multiplicative function
Kaisa Matomaki, Maksym Radziwill, and I have uploaded to the arXiv our paper “Correlations of the von Mangoldt and higher divisor functions II. Divisor correlations in short ranges“. This is a sequel of sorts to our previous paper on divisor correlations, though the proof techniques in this paper are rather different. As with the previous paper, our interest is in correlations such as

for medium-sized 
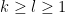

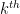
As discussed in this previous post, one heuristically expects an asymptotic of the form

for any fixed 


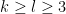
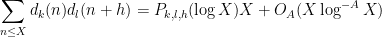
for 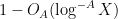

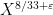


for 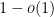
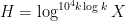



We now discuss some of the ingredients of the proof. Unsurprisingly, the first step is the circle method, expressing (1) in terms of exponential sums such as

Actually, it is convenient to first prune 

In our previous paper on bounded multiplicative functions, we used Plancherel’s theorem to estimate the global 

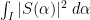
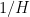



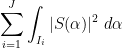
for a moderate number of disjoint intervals 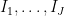

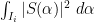
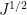

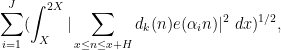
where 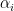



after various averaging in the 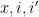
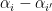
Kaisa Matomaki, Maksym Radziwill, and I have uploaded to the arXiv our paper “Correlations of the von Mangoldt and higher divisor functions I. Long shift ranges“, submitted to Proceedings of the London Mathematical Society. This paper is concerned with the estimation of correlations such as
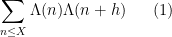
for medium-sized
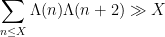
then this would easily imply the twin prime conjecture.
The (first) Hardy-Littlewood conjecture asserts an asymptotic
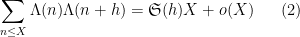
as 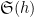
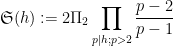
when 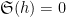
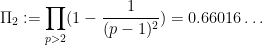
is (half of) the twin prime constant. See for instance this previous blog post for a a heuristic explanation of this conjecture. From the previous discussion we see that (2) for 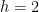
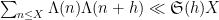
Needless to say, apart from the trivial case of odd
The first results in this direction were by van der Corput and by Lavrik, who established such a result with 
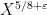

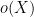
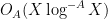
Our arguments initially proceed along standard lines. One can use the Hardy-Littlewood circle method to express the correlation in (2) as an integral involving exponential sums 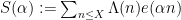
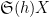
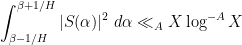
for any “minor arc” 
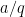
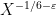
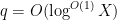
![{[x, x + x^{1/6+\varepsilon}]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C+x+%2B+x%5E%7B1%2F6%2B%5Cvarepsilon%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The next step (following some ideas we found in a paper of Zhan) is to rewrite this estimate not in terms of the exponential sums 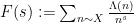
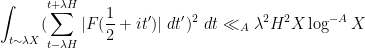
for any 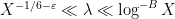

The next step, which is again standard, is the use of the Heath-Brown identity (as discussed for instance in this previous blog post) to split up 
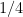
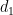


![{[X^\varepsilon, X^{-\varepsilon} H]}](https://s0.wp.com/latex.php?latex=%7B%5BX%5E%5Cvarepsilon%2C+X%5E%7B-%5Cvarepsilon%7D+H%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



for “typical” ordinates 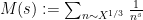
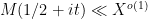
At this point, having exhausted all the Dirichlet polynomial estimates that are usefully available, we return to “physical space”. Using some further Fourier-analytic and oscillatory integral computations, we can estimate the left-hand side of (3) by an expression that is roughly of the shape
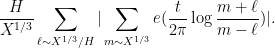
The phase 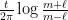
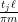
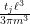
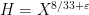
In a sequel to this paper, we will use a somewhat different method to reduce 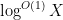
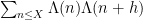



Kaisa Matomäki, Maksym Radziwiłł, and I have just uploaded to the arXiv our paper “Sign patterns of the Liouville and Möbius functions“. This paper is somewhat similar to our previous paper in that it is using the recent breakthrough of Matomäki and Radziwiłł on mean values of multiplicative functions to obtain partial results towards the Chowla conjecture. This conjecture can be phrased, roughly speaking, as follows: if ![{[1,x]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



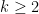
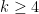

Theorem 1 Let
Thus for instance one has 
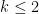


The basic strategy in all of these arguments is to assume for sake of contradiction that a certain sign pattern occurs extremely rarely, and then exploit the complete multiplicativity of 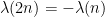
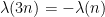



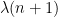



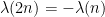


and
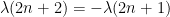
for almost all
Similarly, if we assume that the sign pattern 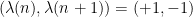



It turns out that similar (but more combinatorially intricate) arguments work for sign patterns of length three (but are unlikely to work for most sign patterns of length four or greater). We give here one fragment of such an argument (due to Hildebrand) which hopefully conveys the Sudoku-type flavour of the combinatorics. Suppose for instance that the sign pattern 



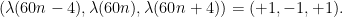
We claim that this (almost always) forces 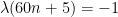
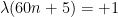



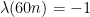



One can continue these Sudoku-type arguments and conclude eventually that 



Excluding a sign pattern of length three leads to useful implications like “if 


Our second theorem gives an analogous result for the Möbius function 
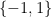
Theorem 2 Let
is attained by the Möbius function for a set
It turns out that the prime number theorem and elementary sieve theory can be used to handle the 

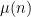

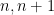

The constraints we assume on the Möbius function can be depicted using a graph on the squarefree natural numbers, in which any two adjacent squarefree natural numbers are connected by an edge. The main difficulty is then that this graph is highly disconnected due to the multiples of four not being squarefree.
To get around this, we need to enlarge the graph. Note from multiplicativity that if 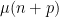


Theorem 3 For each prime
be a residue class chosen uniformly at random. Let
consist of those integers
. Then with probability
We were able to show the connectedness of this graph, though it turned out to be remarkably tricky to do so. Roughly speaking (and suppressing a number of technicalities), the main steps in the argument were as follows.
- (Early stage) Pick a large number
in
numbers in
, using relatively short paths of short diameter. (This is the most computationally intensive portion of the argument.)
- (Middle stage) Let
be a typical number in
, and let
be a scale somewhere between
and
involving three primes, and using a variant of Vinogradov’s theorem and some routine second moment computations, one can show that with quite high probability, any “good” vertex in
is connected to a “good” vertex in
by paths of length three, where the definition of “good” is somewhat technical but encompasses almost all of the vertices in
- (Late stage) Combining the two previous results together, we can show that most vertices
for any
vertices in
. By tracking everything carefully, one can control the length and diameter of the paths used to connect
- (Final stage) Now if we have two vertices
at a distance
to a large set
. Now, by using a Vinogradov-type theorem and second moment calculations again (and ensuring that the elements of
It seems of interest to understand random graphs like 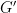

Kaisa Matomaki, Maksym Radziwill, and I have just uploaded to the arXiv our paper “An averaged form of Chowla’s conjecture“. This paper concerns a weaker variant of the famous conjecture of Chowla (discussed for instance in this previous post) that

as 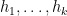
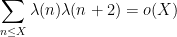
is a variant of the twin prime conjecture (though possibly a tiny bit easier to prove), and is subject to the notorious parity barrier (as discussed in this previous post).
Our main result asserts, roughly speaking, that Chowla’s conjecture can be established unconditionally provided one has non-trivial averaging in the
Theorem 1 (Chowla on the average) Suppose
, we have
In fact, we can remove one of the averaging parameters and obtain
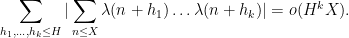
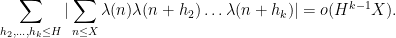
Actually we can make the decay rate a bit more quantitative, gaining about 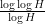
The proof of the theorem proceeds as follows. By exploiting the Fourier-analytic identity

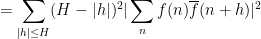
(related to a standard Fourier-analytic identity for the Gowers 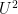
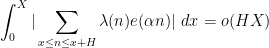
uniformly for all 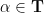

The argument also extends to other bounded multiplicative functions than the Liouville function. Chowla’s conjecture was generalised by Elliott, who roughly speaking conjectured that the 
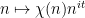

(This type of distance is incidentally now a fundamental notion in the Granville-Soundararajan “pretentious” approach to multiplicative number theory.) During our work on this project, we found that Elliott’s conjecture is not quite true as stated due to a technicality: one can cook up a bounded multiplicative function 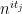


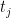
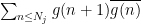

In analytic number theory, it is a well-known phenomenon that for many arithmetic functions 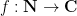

than it is to estimate summatory functions such as

(Here we are normalising 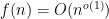







Viewed conversely, whenever one has a difficult estimate on a summatory function such as 
We begin with Halasz’s theorem. Here is a version of this theorem, due to Montgomery and to Tenenbaum:
Theorem 1 (Halasz-Montgomery-Tenenbaum) Let
for all
and
, and set
Then one has

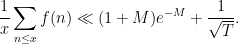
Informally, this theorem asserts that 
Theorem 2 (Cheap Halasz) Let

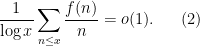
Note that now that we are content with estimating exponential sums, we no longer need to preclude the possibility that 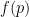
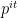
To prove this theorem, we first need a special case of the Turan-Kubilius inequality.
Lemma 3 (Turan-Kubilius) Let
be a quantity depending on
and
as
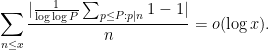
Informally, this lemma is asserting that

for most large numbers
![\displaystyle 1 \approx 1 * \frac{1}{\log\log P} 1_{{\mathcal P} \cap [1,P]}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+1+%5Capprox+1+%2A+%5Cfrac%7B1%7D%7B%5Clog%5Clog+P%7D+1_%7B%7B%5Cmathcal+P%7D+%5Ccap+%5B1%2CP%5D%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
This type of estimate was previously discussed as a tool to establish a criterion of Katai and Bourgain-Sarnak-Ziegler for Möbius orthogonality estimates in this previous blog post. See also Section 5 of Notes 1 for some similar computations.
Proof: By Cauchy-Schwarz it suffices to show that
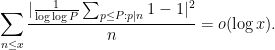
Expanding out the square, it suffices to show that

for 
We just show the 
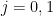
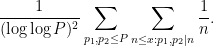
We can estimate the inner sum as ![{(1+o(1)) \frac{1}{[p_1,p_2]} \log x}](https://s0.wp.com/latex.php?latex=%7B%281%2Bo%281%29%29+%5Cfrac%7B1%7D%7B%5Bp_1%2Cp_2%5D%7D+%5Clog+x%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \sum_{p_1, p_2 \leq P} \frac{1}{[p_1,p_2]} = (1+o(1)) (\log\log P)^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bp_1%2C+p_2+%5Cleq+P%7D+%5Cfrac%7B1%7D%7B%5Bp_1%2Cp_2%5D%7D+%3D+%281%2Bo%281%29%29+%28%5Clog%5Clog+P%29%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
and the claim follows.

Remark 4 As an alternative to the Turan-Kubilius inequality, one can use the Ramaré identity
(see e.g. Section 17.3 of Friedlander-Iwaniec). This identity turns out to give superior quantitative results than the Turan-Kubilius inequality in applications; see the paper of Matomaki and Radziwiłł for an instance of this.
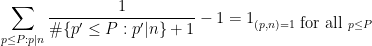
We now prove Theorem 2. Let 


We rearrange the left-hand side as

We now replace the constraint 


which by Mertens’ theorem is 
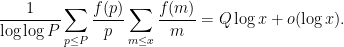
But by definition of 
![\displaystyle [1 - \frac{1}{\log\log P} \sum_{p \leq P} \frac{f(p)}{p}] Q = o(1). \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B1+-+%5Cfrac%7B1%7D%7B%5Clog%5Clog+P%7D+%5Csum_%7Bp+%5Cleq+P%7D+%5Cfrac%7Bf%28p%29%7D%7Bp%7D%5D+Q+%3D+o%281%29.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
From Mertens’ theorem, the expression in brackets can be rewritten as

and so the real part of this expression is

By (1), Mertens’ theorem and the hypothesis on

for any 

and thus the expression in brackets has real part 
The Turan-Kubilius argument is certainly not the most efficient way to estimate sums such as 
Exercise 5 (Granville-Koukoulopoulos-Matomaki)
- (i) If
for all primes
as
, where
for all primes
- (ii) If
, show that
for all
.
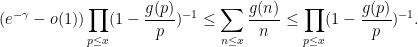

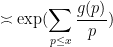
Now we turn to a very recent result of Matomaki and Radziwiłł on mean values of multiplicative functions in short intervals. For sake of illustration we specialise their results to the simpler case of the Liouville function
Theorem 6 (Matomaki-Radziwiłł, special case) Let
be a quantity going to infinity as
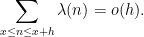

A simple sieving argument (see Exercise 18 of Supplement 4) shows that one can replace
Of course, (4) improves upon the trivial bound of 


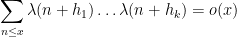
as
Below the fold, we give a “cheap” version of the Matomaki-Radziwiłł argument. More precisely, we establish
Theorem 7 (Cheap Matomaki-Radziwiłł) Let
. Then

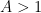 .
.Note that (5) improves upon the trivial bound of 

Recent Comments