
You are currently browsing the monthly archive for January 2012.
A few days ago, inspired by this recent post of Tim Gowers, a web page entitled “the cost of knowledge” has been set up as a location for mathematicians and other academics to declare a protest against the academic publishing practices of Reed Elsevier, in particular with regard to their exceptionally high journal prices, their policy of “bundling” journals together so that libraries are forced to purchase subscriptions to large numbers of low-quality journals in order to gain access to a handful of high-quality journals, and their opposition to the open access movement (as manifested, for instance, in their lobbying in support of legislation such as the Stop Online Piracy Act (SOPA) and the Research Works Act (RWA)). [These practices have been documented in a number of places; this wiki page, which was set up in response to Tim’s post, collects several relevant links for this purpose. Some of the other commercial publishers have exhibited similar behaviour, though usually not to the extent that Elsevier has, which is why this particular publisher is the focus of this protest.] At the protest site, one can publicly declare a refusal to either publish at an Elsevier journal, referee for an Elsevier journal, or join the board of an Elsevier journal.
(In the past, the editorial boards of several Elsevier journals have resigned over the pricing policies of the journal, most famously the board of Topology in 2006, but also the Journal of Algorithms in 2003, and a number of journals in other sciences as well. Several libraries, such as those of Harvard and Cornell, have also managed to negotiate an unbundling of Elsevier journals, but most libraries are still unable to subscribe to such journals individually.)
For a more thorough discussion as to why such a protest is warranted, please see Tim’s post on the matter (and the 100+ comments to that post). Many of the issues regarding Elsevier were already known to some extent to many mathematicians (particularly those who have served on departmental library committees), several of whom had already privately made the decision to boycott Elsevier; but nevertheless it is important to bring these issues out into the open, to make them commonly known as opposed to merely mutually known. (Amusingly, this distinction is also of crucial importance in my favorite logic puzzle, but that’s another story.) One can also see Elsevier’s side of the story in this response to Tim’s post by David Clark (the Senior Vice President for Physical Sciences at Elsevier).
For my own part, though I have sent about 9% of my papers in the past to Elsevier journals (with one or two still in press), I have now elected not to submit any further papers to these journals, nor to serve on their editorial boards, though I will continue refereeing some papers from these journals. As of this time of writing, over five hundred mathematicians and other academics have also signed on to the protest in the four days that the site has been active.
Admittedly, I am fortunate enough to be at a stage of career in which I am not pressured to publish in a very specific set of journals, and as such, I am not making a recommendation as to what anyone else should do or not do regarding this protest. However, I do feel that it is worth spreading awareness, at least, of the fact that such protests exist (and some additional petitions on related issues can be found at the previously mentioned wiki page).
Van Vu and I have just uploaded to the arXiv our paper Random matrices: Sharp concentration of eigenvalues, submitted to the Electronic Journal of Probability. As with many of our previous papers, this paper is concerned with the distribution of the eigenvalues 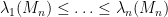

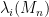


If we normalise the entries of the matrix 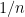

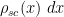
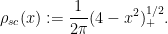
An essentially equivalent way of saying this is that for large 

![{\gamma_i \in [-2,2]}](https://s0.wp.com/latex.php?latex=%7B%5Cgamma_i+%5Cin+%5B-2%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

In particular, from the Wigner semicircle law it can be shown that asymptotically almost surely, one has
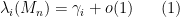
for all 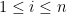
In the modern study of the spectrum of Wigner matrices (and in particular as a key tool in establishing universality results), it has become of interest to improve the error term in (1) as much as possible. A typical early result in this direction was by Bai, who used the Stieltjes transform method to obtain polynomial convergence rates of the shape 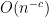

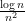
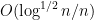


A significant advance in this direction was achieved by Erdos, Schlein, and Yau in a series of papers where they used a combination of Stieltjes transform and concentration of measure methods to obtain local semicircle laws which showed, among other things, that one had asymptotics of the form
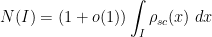
with exponentially high probability for intervals 


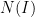
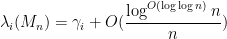
in the bulk with exponentially high probability, for Wigner matrices obeying some exponential decay conditions on the entries. This was achieved by a rather delicate high moment calculation, in which the contribution of the diagonal entries of the resolvent (whose average forms the Stieltjes transform) was shown to mostly cancel each other out.
As the GUE computations show, this concentration result is sharp up to the quasilogarithmic factor 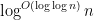
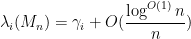
with exponentially high probability (see the paper for a more precise statement of results). The one catch is that an additional hypothesis is required, namely that the entries of the Wigner matrix have vanishing third moment. We also obtain similar results for the edge of the spectrum (but with a different scaling).
Our arguments are rather different from those of Erdos, Yau, and Yin, and thus provide an alternate approach to establishing eigenvalue concentration. The main tool is the Lindeberg exchange strategy, which is also used to prove the Four Moment Theorem (although we do not directly invoke the Four Moment Theorem in our analysis). The main novelty is that this exchange strategy is now used to establish large deviation estimates (i.e. exponentially small tail probabilities) rather than universality of the limiting distribution. Roughly speaking, the basic point is as follows. The Lindeberg exchange strategy seeks to compare a function 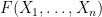
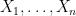
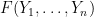
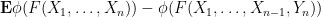
for various smooth test functions 
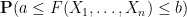
for various thresholds 

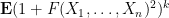
for various moderately large 

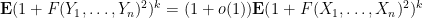
after performing all the relevant exchanges. As such, one can then use large deviation estimates on
In this paper we also take advantage of a simplification, first noted by Erdos, Yau, and Yin, that Four Moment Theorems become somewhat easier to prove if one works with resolvents 

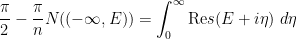
for any energy level 


We have now seen two ways to construct expander Cayley graphs 

We now pursue the second approach more thoroughly. The main difficulty here is to figure out how to ensure flattening of the random walk, as it is then an easy matter to use quasirandomness to show that the random walk becomes mixing soon after it becomes flat. In the case of Selberg’s theorem, we achieved this through an explicit formula for the heat kernel on the hyperbolic plane (which is a proxy for the random walk). However, in most situations such an explicit formula is not available, and one must develop some other tool for forcing flattening, and specifically an estimate of the form
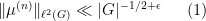
for some 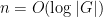


In 2006, Bourgain and Gamburd introduced a general method for achieving this goal. The intuition here is that the main obstruction that prevents a random walk from spreading out to become flat over the entire group 

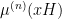
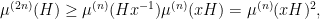
since 
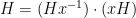

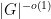
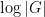
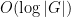
A potentially more general obstruction of this type would be if the random walk gets trapped in (a coset of) an approximate group 

It turns out that this latter observation has a converse: if a measure does not concentrate in cosets of approximate groups, then some flattening occurs. More precisely, one has the following combinatorial lemma:
Lemma 1 (Weighted Balog-Szemerédi-Gowers lemma) Let
be a finitely supported probability measure on
for all
), and let
. Then one of the following statements hold:
- (i) (Flattening) One has
.
- (ii) (Concentration in an approximate group) There exists an
-approximate group
and an element
such that
.
This lemma is a variant of the more well-known Balog-Szemerédi-Gowers lemma in additive combinatorics due to Gowers (which roughly speaking corresponds to the case when 
The lemma is particularly useful when the group
Theorem 2 (Bourgain-Gamburd expansion machine) Suppose that
is a symmetric set of
with the following properties.
- (Quasirandomness). The smallest dimension of a nontrivial representation
of
;
- (Product theorem). For all
there is some
such that the following is true. If
is a
-approximate subgroup with
then
- (Non-concentration estimate). There is some even number
such that
where the supremum is over all proper subgroups
.
Then
-expander for some
depending only on
, and the function
(and this constant

This criterion for expansion is implicitly contained in this paper of Bourgain and Gamburd, who used it to establish the expansion of various Cayley graphs in 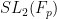

Let 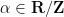
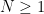
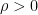
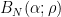
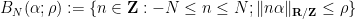
where 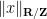

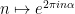
Observe that Bohr sets enjoy the doubling property

thus doubling the Bohr set doubles both the length parameter 

![{[-1,1] \times [-\rho,\rho] \subset {\bf R} \times {\bf R}/{\bf Z}}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D+%5Ctimes+%5B-%5Crho%2C%5Crho%5D+%5Csubset+%7B%5Cbf+R%7D+%5Ctimes+%7B%5Cbf+R%7D%2F%7B%5Cbf+Z%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Another class of finite set with two-dimensional behaviour is the class of (rank two) generalised arithmetic progressions

with 
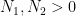
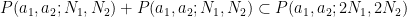
and so we see, as with the Bohr set, that doubling the generalised arithmetic progressions doubles the two defining parameters of that progression.
More generally, there is an analogy between rank 

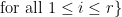
and the rank 
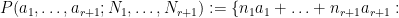

One of the aims of additive combinatorics is to formalise analogies such as the one given above. By using some arguments from the geometry of numbers, for instance, one can show that for any rank 
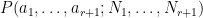
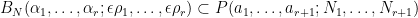

for some explicit 
In the special case when 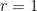
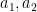
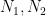
It is unfortunate that the theory of continued fractions is restricted to the rank one setting (it relies very heavily on the total ordering of one-dimensional sets such as 

Recent Comments