
You are currently browsing the monthly archive for May 2009.
As readers of this blog are no doubt aware, I (in conjunction with Tim Gowers and many others) have been working collaboratively on a mathematical project. To do this, we have been jury-rigging together a wide variety of online tools for this, including at least two blogs, a wiki, some online spreadsheets, and good old-fashioned email, together with offline tools such as Maple, LaTeX, C, and other programming languages and packages. (To a lesser extent, I also rely this sort of mish-mash of semi-compatible online and offline software packages in my more normal mathematical collaborations, though polymath1 has been particularly chaotic in this regard.)
While this has been working reasonably well so far, the mix of all the various tools has been somewhat clunky, to put it charitably, and it would be good to have a more integrated online framework to do all of these things seamlessly; currently there seem to be software that achieves various subsets of what one would need for this, but not all. (This point has also recently been made at the Secret Blogging Seminar.)
Yesterday, though, Google Australia unveiled a new collaborative software platform called “Google Wave” which incorporates many of these features already, and looks flexible enough to incorporate them all eventually. (Full disclosure: my brother is one of the software engineers for this project.) It’s nowhere near ready for release yet – it’s still in the development phase – but with the right type of support for things like LaTeX, this could be an extremely useful platform for mathematical collaboration (including the more traditional type of collaboration with just a handful of authors).
There is a demo for the product below. It’s 80 minutes long, and aimed more at software developers than at end users, but I found it quite interesting, and worth watching through to the end:
[Update, May 30: Apparently a LaTeX renderer is already being developed as an API extension to Google Wave; here is a very preliminary screenshot. Also, a shorter explanation of what Google Wave is and does can be found here. ]
[Update, Jun 7: Another review can be found here.]
[This post should have appeared several months ago, but I didn’t have a link to the newsletter at the time, and I subsequently forgot about it until now. -T.]
Last year, Emmanuel Candés and I were two of the recipients of the 2008 IEEE Information Theory Society Paper Award, for our paper “Near-optimal signal recovery from random projections: universal encoding strategies?” published in IEEE Inf. Thy.. (The other recipient is David Donoho, for the closely related paper “Compressed sensing” in the same journal.) These papers helped initiate the modern subject of compressed sensing, which I have talked about earlier on this blog, although of course they also built upon a number of important precursor results in signal recovery, high-dimensional geometry, Fourier analysis, linear programming, and probability. As part of our response to this award, Emmanuel and I wrote a short piece commenting on these developments, entitled “Reflections on compressed sensing“, which appears in the Dec 2008 issue of the IEEE Information Theory newsletter. In it we place our results in the context of these precursor results, and also mention some of the many active directions (theoretical, numerical, and applied) that compressed sensing is now developing in.
Now that the quarter is nearing an end, I’m returning to the half of the polymath1 project hosted here, which focussed on computing density Hales-Jewett numbers and related quantities. The purpose of this thread is to try to organise the task of actually writing up the results that we already have; as this is a metathread, I don’t think we need to number the comments as in the research threads.
To start the ball rolling, I have put up a proposed outline of the paper on the wiki. At present, everything in there is negotiable: title, abstract, introduction, and choice and ordering of sections. I suppose we could start by trying to get some consensus as to what should or should not go into this paper, how to organise it, what notational conventions to use, whether the paper is too big or too small, and so forth. Once there is some reasonable consensus, I will try creating some TeX files for the individual sections (much as is already being done with the first polymath1 paper) and get different contributors working on different sections (presumably we will be able to coordinate all this through this thread). This, like everything else in the polymath1 project, will be an experiment, with the rules made up as we go along; presumably once we get started it will become clearer what kind of collaborative writing frameworks work well, and which ones do not.
A fundamental characteristic of many mathematical spaces (e.g. vector spaces, metric spaces, topological spaces, etc.) is their dimension, which measures the “complexity” or “degrees of freedom” inherent in the space. There is no single notion of dimension; instead, there are a variety of different versions of this concept, with different versions being suitable for different classes of mathematical spaces. Typically, a single mathematical object may have several subtly different notions of dimension that one can place on it, which will be related to each other, and which will often agree with each other in “non-pathological” cases, but can also deviate from each other in many other situations. For instance:
- One can define the dimension of a space
by seeing how it compares to some standard reference spaces, such as
or
; one may view a space as having dimension
if it can be (locally or globally) identified with a standard
- Another way to define dimension of a space
- One can also try to define dimension inductively, for instance declaring a space
-dimensional object; thus an
, depending on how one initialises the chain and how one defines length). This can give a notion of dimension for a topological space or a commutative ring.
The notions of dimension as defined above tend to necessarily take values in the natural numbers (or the cardinal numbers); there is no such space as 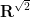






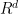

between volume, scale, and dimension. Formalising this heuristic leads to a number of useful notions of dimension for subsets of
[In 
Minkowski dimension can either be defined externally (relating the external volume of 

One use of the notion of dimension is to create finer distinctions between various types of “small” subsets of spaces such as 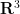



Read the rest of this entry »
In this post I would like to make some technical notes on a standard reduction used in the (Euclidean, maximal) Kakeya problem, known as the two ends reduction. This reduction (which takes advantage of the approximate scale-invariance of the Kakeya problem) was introduced by Wolff, and has since been used many times, both for the Kakeya problem and in other similar problems (e.g. by Jim Wright and myself to study curved Radon-like transforms). I was asked about it recently, so I thought I would describe the trick here. As an application I give a proof of the 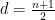
Below the fold is a version of my talk “Recent progress on the Kakeya conjecture” that I gave at the Fefferman conference.
In a previous post, we discussed the Szemerédi regularity lemma, and how a given graph could be regularised by partitioning the vertex set into random neighbourhoods. More precisely, we gave a proof of
Lemma 1 (Regularity lemma via random neighbourhoods) Let
. Then there exists integers
with the following property: whenever
be a graph on finitely many vertices, if one selects one of the integers
at random from
uniformly from
vertex cells
(some of which can be empty) generated by the vertex neighbourhoods
for
, will obey the regularity property
with probability at least
, where the sum is over all pairs
for which
is not
-regular between
and
. [Recall that a pair
is
for any
and
with
, where
is the density of edges between
and
.]


The proof was a combinatorial one, based on the standard energy increment argument.
In this post I would like to discuss an alternate approach to the regularity lemma, which is an infinitary approach passing through a graph-theoretic version of the Furstenberg correspondence principle (mentioned briefly in this earlier post of mine). While this approach superficially looks quite different from the combinatorial approach, it in fact uses many of the same ingredients, most notably a reliance on random neighbourhoods to regularise the graph. This approach was introduced by myself back in 2006, and used by Austin and by Austin and myself to establish some property testing results for hypergraphs; more recently, a closely related infinitary hypergraph removal lemma developed in the 2006 paper was also used by Austin to give new proofs of the multidimensional Szemeredi theorem and of the density Hales-Jewett theorem (the latter being a spinoff of the polymath1 project).
For various technical reasons we will not be able to use the correspondence principle to recover Lemma 1 in its full strength; instead, we will establish the following slightly weaker variant.
Lemma 2 (Regularity lemma via random neighbourhoods, weak version) Let
with the following property: whenever
such that if one selects
vertices
uniformly from
vertex cells
generated by the vertex neighbourhoods
, will obey the regularity property (1) with probability at least
.
Roughly speaking, Lemma 1 asserts that one can regularise a large graph 
I am currently at Princeton for the conference “The power of Analysis” honouring Charlie Fefferman‘s 60th birthday. I myself gave a talk at this conference entitled “Recent progress on the Kakeya conjecture”; I plan to post a version of this talk on this blog shortly.
But one nice thing about attending these sorts of conferences is that one can also learn some neat mathematical facts, and I wanted to show two such small gems here; neither is particularly deep, but I found both of them cute. The first one, which I learned from my former student Soonsik Kwon, is a unified way to view the mean, median, and mode of a probability distribution 
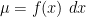




the median is the value of
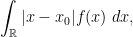
and the mode is the value of

(Note that the Dirac delta function 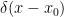
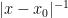
The other fact, which I learned from my former classmate Diego Córdoba (and used in a joint paper of Diego with Antonio Córdoba), is a pointwise inequality

for the fractional differentiation operators 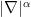

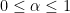

The proof is as follows. By a limiting argument we may assume that 

for some explicit constant 
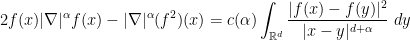
and the claim follows.
In a recent Cabinet meeting, President Obama called for a $100 million spending cut in 90 days from the various federal departments as a sign of budget discipline. While this is nominally quite a large number, it was pointed out correctly by many people that this was in fact a negligible fraction of the total federal budget; for instance, Greg Mankiw noted that the cut was comparable to a family with an annual spending of $100,000 and a deficit of $34,000 deciding on a spending cut of $3. (Of course, this is by no means the only budgetary initiative being proposed by the administration; just today, for instance, a change in the taxation law for offshore income was proposed which could potentially raise about $210 billion over the next ten years, or about $630 a year with the above scaling, though it is not clear yet how feasible or effective this change would be.)
I thought that this sort of rescaling (converting $100 million to $3) was actually a rather good way of comprehending the vast amounts of money in the federal budget: we are not so adept at distinguishing easily between $1 million, $1 billion, and $1 trillion, but we are fairly good at grasping the distinction between $0.03, $30, and $30,000. So I decided to rescale (selected items in) the federal budget, together with some related numbers for comparison, by this ratio 100 million:3, to put various figures in perspective.
This is certainly not an advanced application of mathematics by any means, but I still found the results to be instructive. The same rescaling puts the entire population of the US at about nine – the size of a (large) family – which is of course consistent with the goal of putting the federal budget roughly on the scale of a family budget (bearing in mind, of course, that the federal government is only about a fifth of the entire US economy, so one might perhaps view the government as being roughly analogous to the “heads of household” of this large family). The implied (horizontal) length rescaling of 
One caveat: the rescaling used here does create some noticeable distortions in other dimensional quantities. For example, if one rescales length by the implied factor of 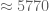
All amounts here are rounded to three significant figures (and in some cases, the precision may be worse than this). I am using here the FY2008 budget instead of the 2009 or 2010 one, as the data is more finalised; as such, the numbers here are slightly different from those of Mankiw. (For instance, the 2010 budget includes the expenditures for Iraq & Afghanistan, whereas in previous budgets these were appropriated separately.) I have tried to locate the most official and accurate statistics whenever possible, but corrections and better links are of course welcome.
FY 2008 budget:
- Total revenue: $75,700
- Total spending: $89,500
- Budget deficit: $13,800
- Additional appropriations (not included in regular budget)
- Iraq & Afghanistan: $5,640
- Spending cuts within 90 days of Apr 20, 2009: $3
- Air force NY flyover “photo shoot”, Apr 27, 2009: $0.01
- Additional spending cuts for FY2010, proposed May 7, 2009: $510
- Projected annual revenue from proposed offshore tax code change: $630
Other figures (for comparison)
- National debt held by public 2008: $174,000
- Held by foreign/international owners 2008: $85,900
- National debt held by government agencies, 2008: $126,000
- National GDP 2008: $427,000
- National population 2008: 9
- GDP per capita 2008: $47,000
- Land mass: 0.27 sq km (0.1 sq mi, or 68 acres)
- World GDP 2008: $1,680,000
- World population 2008: 204
- GDP per capita 2008 (PPP): $10,400
- Land mass: 4.47 sq km (1.73 sq mi)
- World’s richest (non-rescaled) person: Bill Gates (net worth $1,200, March 2009)
- 2008/2009 Bailout package (TARP): $21,000 (maximum)
- 2009/2010 Stimulus package (ARRA): $23,600
- Tax cuts (spread out over 10 years): $8,640
- State and local fiscal relief: $4,320
- Education: $3,000
- “Race to the top” education fund: $150
- Investments in scientific research: $645
- NSF allocation: $90 (was initially $42)
- ARPA-E: $12
- Pandemic flu preparedness: $1.50 (was initially $27, after being dropped from FY2008 and FY2009 budgets)
- Additional request after A(H1N1) (“swine flu”) outbreak, Apr 28: $45
- Volcano monitoring: $0.46 (erroneously reported as $5.20)
- Salt marsh mouse preservation (aka “Pelosi’s mouse“): $0.00 (erroneously reported as $0.90)
- Market capitalization of NYSE
- Value of US housing stock (2007): $545,760
- Credit default swap contracts, total notional value:
- US trade balance (2007)

{kind=link}
Recent Comments