
The U.S. presidential election is now only a few weeks away. The politics of this election are of course interesting and important, but I do not want to discuss these topics here (there is not exactly a shortage of other venues for such a discussion), and would request that readers refrain from doing so in the comments to this post. However, I thought it would be apropos to talk about some of the basic mathematics underlying electoral polling, and specifically to explain the fact, which can be highly unintuitive to those not well versed in statistics, that polls can be accurate even when sampling only a tiny fraction of the entire population.
Take for instance a nationwide poll of U.S. voters on which presidential candidate they intend to vote for. A typical poll will ask a number 
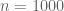



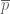
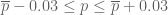
I’ll give a rigorous proof of a weaker version of the above statement (giving a margin of error of about 7%, rather than 3%) in an appendix at the end of this post. But the main point of my post here is a little different, namely to address the common misconception that the accuracy of a poll is a function of the relative sample size rather than the absolute sample size, which would suggest that a poll involving only 0.0005% of the population could not possibly have a margin of error as low as 3%. I also want to point out some limitations of the mathematical analysis; depending on the methodology and the context, some polls involving 1000 respondents may have a much higher margin of error than the idealised rate of 3%.
— Assumptions and conclusion —
Not all polls are created equal; there are a certain number of hypotheses on the methodology and effectiveness of the poll that we have to assume in order to make our mathematical conclusions valid. We will make the following idealised assumptions:
- Simple question. Voters polled can only offer one of two responses, which I will call A and not-A; thus we ignore the effect of third-party candidates, undecided voters, or refusals to respond. In particular, we do not try to combine this data with other questions about the polled voters, such as demographic data. We also assume that the question is unambiguous and cannot be misinterpreted by respondents (see Hypothesis 3 below).
- Perfect response rate. All voters polled offer a response; there are no refusals to respond to the poll, or failures to make contact with the voter being polled. (This is a special case of 1., but deserves to be emphasised.) In particular, this excludes polls that are self-selected, such as internet polls (since in most cases, a large fraction of viewers of a web page with a poll will refuse to respond to that poll).
- Honest responses. The response given by a voter to the poll is an accurate representation whether that voter intends to vote for
- Fixed poll size. The number
- Simple random sampling (without replacement). Each one of the
- Honest reporting. The results of the poll are always reported, with no inaccuracies; one cannot cancel, modify, or ignore a poll once it has begun. In particular, one cannot conduct multiple polls and only report the “best” results (thus running the risk of confirmation bias).
Polls which deviate significantly from these hypotheses (e.g. due to complex questions, self-selection or other selection bias, confirmation bias, inaccurate responses, a high refusal rate, variable poll size, or clustering) will generally be less accurate than an idealised poll with the same sample size. Of course, there is a substantial literature in statistics (and polling methodology) devoted to measuring, mitigating, avoiding, or compensating for these less ideal situations, but we will not discuss those (important) issues here. We will remark though that in practice it is difficult to make the poll selection truly uniform. For instance, if one is conducting a telephone poll, then the sample will of course be heavily biased towards those voters who actually own phones; a little more subtly, it will also be biased toward those voters who are near their phones at the time the poll was conducted, and have the time and inclination to answer phone calls. As long as these factors are not strongly correlated with the poll question (i.e. whether the voter will vote for A), this is not a major concern, but in some cases, the poll methodology will need to be adjusted (e.g. by reweighting the sample) to compensate for the non-uniformity.
As stated in the introduction, we let 
There is an important subtlety here: it is only the unconditional probability of the event 
One special case of the above point is worth emphasising: the statement that
— Nobody asked for my opinion! —
One intuitive argument against a poll of small relative size being accurate goes something like this: a poll of just 1,000 people among a population of 200,000,000 is almost certainly not going to poll myself, or any of my friends or acquaintances. If the opinions of myself, and everyone that I know, is not being considered at all in this poll, how could this poll possibly be accurate?
It is true that if you know, say, 5,000 voting-eligible people, then chances are that none of them (or maybe one of them, at best) will be contacted by the above poll. However, even though the opinions of all these people are not being directly polled, there will be many other people with equivalent opinions that will be contacted by the poll. Through those people, the views of yourself and your friends are being represented. [This may seem like a very weak form of representation, but recall that you and your 5,000 friends and acquaintances still only represent 0.0025% of the total electorate.]
Now one may argue that no two voters are identical, and that each voter arrives at a decision of who to vote for their own unique reasons. True enough – but recall that this poll is asking only a simple question: whether one is going to vote for A or not. Once one narrowly focuses on this question alone, any two voters who both decide to vote for A, or to not vote for A, are considered equivalent, even if they arrive at this decision for totally different reasons. So, for the purposes of this poll, there are only two types of voters in the world – A-voters, and not-A-voters – with all voters in one of these two types considered equivalent. In particular, any given voter is going to have millions of other equivalent voters distributed throughout the population
As mentioned before, polls which offer complex questions (for instance, trying to discern the motivation behind one’s voting choices) will inherently be less accurate; there are now fewer equivalent voters for each individual, and it is harder for a poll to pick up each equivalence class in a representative manner. (In particular, the more questions that are asked, the more likely it becomes that the responses to at least one of these questions will be inaccurate by an amount exceeding its margin of error. This provides a limit as to how much information one can confidently extract from data mining any given data set.)
— Is there enough information? —
Another common objection to the accuracy of polls argues that there is not enough information (or “degrees of freedom”) present in the poll sample to accurately describe the much larger amount of data present in the full population; 1,000 bits of data cannot possibly contain 200,000,000 bits of information. However, we are not asking to find out so much information; the purpose of the poll is to estimate just a single piece of information, namely the number
As before, the accuracy degrades as one asks more and more complicated questions. For instance, if one were to poll 1,000 voters for their opinions on two unrelated questions A and B, each of the answers to A and B would be accurate to within 3% with probability 95%, but the probability that the answers to A and B were simultaneously accurate to within 3% would be lower (around 90% or so), and so any data analysis that relies on the responses to both A and B may not have as high a confidence level as data analysis that relies on A and B separately. This is consistent with the information-theoretic perspective: we are demanding more and more bits of information on our population, and it is harder for our fixed data set to supply so much information accurately and confidently.
— Swings —
One intuitive way to gauge the margin of error of a poll is to see how likely such a poll is to accurately detect a swing in the electorate. Suppose for instance that over the course of a given time period (e.g. a week), 7% of the voters switch their vote from not-A to A, while another 2% of the voters switch their vote from A to not-A, leading to a net increase of 5% in the proportion
If the poll was conducted by simple random sampling, then each of the 1,000 voters polled would have a 7% probability of switching from not-A to A, and and a 2% probability of switching from A to not-A. Thus, one would expect about 70 of the 1,000 voters polled to switch to A, and about 20 to switch to not-A, leading to a net swing of 50 voters, that would increase
It is worth noting that this swing of 5% in an electorate of 200,000,000 voters represents quite a large shift in absolute terms: fourteen million voters switching to A and four million switching away from A. Quite a few of these shifting voters will be picked up by the poll (in contrast to one’s sphere of friends and acquaintances, which is likely to be missed completely).
— Irregularity —
Another intuitive objection to polling accuracy is that the voting population is far from homogeneous. For instance, it is clear that voting preferences for the U.S. presidential election vary widely among the 50 states – shouldn’t one need to multiply the poll size by 50 just to accomodate this fact? Similarly for distinctions in voting patterns based on gender, race, party affiliation, etc.
Again, these irregularities in voter distribution do not affect the final accuracy of the poll, for two reasons. Firstly, we are asking only the simple question of whether a voter votes for A or not-A, and are not breaking down the answers to this question by state, gender, race, or any other factor; as stated before, two voters are considered equivalent as long as they have the same preference for A, even if they are in different states, have different genders, etc. Secondly, while it is conceivable that the poll will cluster its sample in one particular state (or one particular gender, etc.), thus potentially skewing the poll, the fact that the voters are selected uniformly and independently of each other prevents this from happening very often. (And in any event, clustering in a demographic or geographic category is not what is of direct importance to the accuracy of the poll; the only thing that really matters in the end is whether there is clustering in the category of A-voters or not-A-voters.) The independence hypothesis is rather important. If for instance one were to poll by picking one particular location in the U.S. at random, and polling 1,000 people from that location, then the responses would be highly correlated (as one could have picked a location which happens to highly favour A, or highly favour not-A) and would have a much larger margin of error than if one polled 1,000 people at random across the U.S..
[Incidentally, in the specific case of the U.S. presidential election, statewide polls are in fact more relevant to the outcome of the election than nationwide polls, due to the mechanics of the U.S. Electoral College, but this does not detract from the above points.]
— Analogies —
Some analogies may help explain why the relative size of a sample is largely irrelevant to the accuracy of a poll.
Suppose one is in front of a large body of water (e.g. a sea or ocean), and wants to determine whether it is a freshwater or saltwater body. This can be done very easily: dip one’s finger into the body of water and taste a single drop. This gives an extremely accurate result, even though the relative proportion of the sample size to the population size is, literally, a drop in the ocean; the quintillions of water molecues and salt molecues present in that drop are more than sufficient to give a good reading of the salinity of the water body.
[To be fair, in order for this reading to be accurate, one needs to assume that the salinity is uniformly distributed across the body of water; if for instance the body happened to be nearly fresh on one side and much saltier on the other, then dipping one’s finger in just one of these two sides would lead to an inaccurate measurement of average salinity. But if one were to stir the body of water vigorously, this irregularity of distribution disappears. The procedure of taking a random sample, with each sample point being independent of all the others, is analogous to this stirring procedure.]
Another analogy comes from digital imaging. As we all know, a digital camera takes a picture of a real-world object (e.g. a human face) and converts it into an array of pixels; an image with a larger number of pixels will generally lead to a more accurate image than one with fewer. But even with just a handful of pixels, say 1,000 pixels, one is already able to make crude distinctions between different images, for instance to distinguish a light-skinned face from a dark-skinned face (despite the fact that skin colour is determined by millions of cells and quintillions of pigment molecues). See for instance this well-known (and very low resolution) image of a US president, by Leon Harmon:

— Appendix: Mathematical justification —
One can compute the margin of error for this simple sampling problem very precisely using the binomial distribution; however I would like to present here a cruder but more robust estimate, based on the second moment method, that works in much greater generality than the setting discussed here. (It is closely related to the arguments in my previous post on the law of large numbers.) The main mathematical result we need is
Theorem. Let X be a finite set, let A be a subset of X, and let
be the proportion of elements of X that lie in A. Let
be sampled independently and uniformly at random from X (in particular, we allow repetitions). Let
be the proportion of the
(counting repetition) that lie in A. Then for any
, one has
. (1)
Proof. We use the second moment method. For each 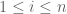
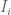

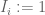
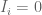

On the other hand, we have

Thus

squaring this and taking expectations, we obtain

where 


By assumption, the random variable 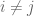
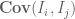

for each i. Putting all this together we conclude that
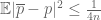
and the claim (1) follows from Markov’s inequality.

Applying this theorem with n=1000 and 
Remark 1. Observe that the proof of the above theorem did not really need the 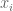


Remark 2. If one assumes joint independence instead of pairwise independence, one can obtain slightly sharper inequalities than (1) (e.g. by using the Chernoff inequality), but at the 95% confidence level, this gives a relatively modest improvement only in the margin of error (in our specific example, the optimal margin of error is about 3% rather than 7%).
Remark 3. An inspection of the argument shows that if p is known to be very small or very large, then the margin of error is better than what (1) predicts. (In the most extreme case, if p=0 or p=1, then it is easy to see that the margin of error is zero.) But in the case of election polls, p is generally expected to be close to 1/2, and so one does not expect to be able to improve the margin of error much from this effect. And in any case, we don’t know the value of p exactly in practice (otherwise why would we be doing the poll in the first place?).
Remark 4. In real world situations, it can be difficult or impractical to get the
[Updated, October 13: added emphasis that the confidence level only applies before one performs the poll, not afterwards.]
[Updated, October 17: Minor corrections; thanks to Tom Verhoeff for pointing them out.]

35 comments
Comments feed for this article
10 October, 2008 at 6:44 pm
weiyu
thanks. interesting article.
11 October, 2008 at 1:35 am
hmm
very difficult article, did not understand any of it. :) but it’s ok, i am used to your posts being super difficult :)
11 October, 2008 at 7:06 am
eyeadventures
I could understand a part of this. Looking very informative.
eyeadventures.wordpress.com
11 October, 2008 at 7:49 am
Ed Jones
This is a really useful post. We conduct random sample research in an event marketing measurement context. These are things I worry about and try to point out when I see a client take results and run with them that may have significant weaknesses. For example, very high level executives are not nearly as likely to respond to a poll because they are very busy or they have an assistant screen their correspondence, so they are under-represented in the result.
Also, people tend to believe everything they hear on TV and the myriad of polls we see reported daily have many of these issues. I believe that is why networks famously called states incorrectly on election day. I would guess we are usually looking at close to 10% possible (not probable) error on most of the better political polls reported on TV.
Thanks for a very thoughtful article. If you could dumb it down a bit, it should be required reporting on every network.
Ed Jones
Constellation Communication Corp. http://constellationcc.com
11 October, 2008 at 9:47 am
bradlongo
nice post. I found this really interesting.
11 October, 2008 at 9:49 am
mohammadyasir
interesting
11 October, 2008 at 11:04 am
Encuestas electorales y margen de error « Series Divergentes
[…] under Matemáticas, Series divergentes Terence Tao publicó en su blog el artículo Small samples, and the margin of error, en el cual discute las matemáticas de las encuestas electorales, al menos las ideas básicas en […]
11 October, 2008 at 4:17 pm
Top Posts « WordPress.com
[…] Small samples, and the margin of error The U.S. presidential election is now only a few weeks away. The politics of this election are of course interesting […] […]
11 October, 2008 at 9:38 pm
Let’s Read The Internet! Week 1 « Arcsecond
[…] <h4>Small samples, and the margin of error</h4> […]
12 October, 2008 at 10:46 am
Mathematics of Elections: Polling « OU Math Club
[…] his blog, Terence Tao discusses the mathematics of how one verify the confidence level and margin of error even when you only poll […]
12 October, 2008 at 11:35 am
jonm
There seems to be a typo in the equation after “Putting all this together we conclude that”. The n^2 should just be an n. [Fixed – T.]
12 October, 2008 at 11:38 am
David Asher Silvera
…”there is not exactly a shortage of other venues for such a discussion”…[ about the U.S. presidential election]
This must be the understatement of the year!
Congratulations on your very wise decision not to discuss this topic.
As usual I am overwhelmed by the diversity of subjects about which
you are able to write so intelligently.
Dear Terry , just to prove you are human, could you tell us about something you do NOT know?
Best, Asher
12 October, 2008 at 1:12 pm
Chris Sogge
A big factor in the accuracy of Presidential polls is the common practice of weighting for party ID. Most seem to do it now. Some, such as Rasmussen are up front about it, and he’s been pretty accurate in past races. Currently he weighs Democrats 6% more heavily than Republicans, and he has Obama up by 6. In other cases, you have to dig into the internals to see what’s behind the polls. For instance, Newsweek just came up with a national poll saying that Obama was up by 11 points. Digging into their internals, of the people polled, 27 percent were Republican, 40 percent Democrat, and 30 percent Independent. That’s a 13 point spread of Democrats versus Republicans. Over the last 5 presidential elections, the biggest spread between Democrats and Republicans was 4 points. In 2004, the spread was even, 37-37. Over the last 5 presidential elections, the spread never changed by more than 4 points.
14 October, 2008 at 11:11 pm
Wiskundemeisjes » De wiskunde achter polls
[…] Tao schreef op zijn blog een mooi artikel over de wiskunde achter polls: Small samples, and the margin of error. Hoe kan een steekproef van slechts duizend Amerikanen nou voorspellen wat er gebeurt als miljoenen […]
15 October, 2008 at 2:04 pm
Kieran
….if the poll reports that 55% of respondents would vote for A, then the true percentage of the electorate that would vote for A has at least a 95% chance of lying between 52% and 58%.
This isn’t true. The 95% probability refers to the sampling error, not to the interval itself. The true population percentage is either in the interval or it is not. If we conducted the same survey many times, drawing a new sample each time, and we calculated the 95% confidence interval around the estimated proportion in each of these, then we would have many confidence intervals. 95% of these would contain the true population percentage, 5% would not.
When conducting only one survey, there is a 95% probability that you will draw a sample which will produce a confidence interval that contains the population parameter.
15 October, 2008 at 2:13 pm
Terence Tao
Dear Kieran,
Yes, you are right; I say in the post that this is an oversimplification, and discuss it in detail a little later in the post.
15 October, 2008 at 3:47 pm
DTyson
Kieran,
Well noted. I stress this very concept to my Statistics students. 95% confidence is NOT 95% probability. This notion is unsettlingly subtle, but really important to understand.
I think most of the difficulty lies in the idea that long term relative frequencies are empirical probabilities, and so relative frequencies are connected with probabilities in my students’ minds.
If I remember correctly from “The Lady Tasting Tea” (by David Salsburg), the first appearance of the confidence interval (as we know it today) was met with some skepticism precisely because the interval estimate either captures the parameter or doesn’t. So have we really gotten an interval estimate of the parameter? Well, with 95% confidence we have…
16 October, 2008 at 6:03 am
Ruminations » Blog Archive » A Contrarian View: Why Should I Vote?
[…] to look at state voting populations and assume that polling simply reads general trends. But the math behind using small sample set polling, done properly, is overwhelming. Confidence ratings on sampling are […]
16 October, 2008 at 8:51 am
Neven
Terry,
Thank you for an illuminating article, especially about the difference in probabilities of a statement about p before and after the poll. I am thinking about weather forecasts which commonly state that the probability of rain tomorrow is say 80%. If I always disregard such forecast and go picnicking, in my lifetime I’ll end up wet 80% of time. However, if I decide to picnick tomorrow I am going to be either wet or dry and nothing more can be said today about the situation. Am I right?
21 October, 2008 at 7:16 am
mavis
Any introductory statistics book / class explains this, and in a much easier-to-understand way. Everyone should be required to take a little statistics.
2 November, 2008 at 9:24 am
The inverse conjecture for the Gowers norm over finite fields via the correspondence principle « What’s new
[…] moderately large sample sizes can be accurate even when the overall population is enormous (see my previous post for more discussion on this). To cut a long story short, this shuffling (or “statistical […]
13 November, 2008 at 9:28 pm
How Polling Works « Curious Ramblings
[…] Polling Works Terrence Tao has a great blog entry about the mathematics of polling. One thing he points out, which to me at first was unintuitive, is that polling accuracy is […]
18 November, 2008 at 9:43 pm
Margin of Error « I’m just a simple DBA on a complex production system
[…] you are really interested in the subject and not afraid of some mathematical notation, Terence Tao has a much deeper analysis of the subject. […]
22 December, 2008 at 10:24 am
balkrishnapatankar
Thanks … Very interesting article …. Please keep writing more of such non technical but a bit mathematical posts in future
3 July, 2009 at 8:10 pm
Benford’s law, Zipf’s law, and the Pareto distribution « What’s new
[…] the CIA world factbook); I have put the raw data here. This is a relatively small sample (cf. my previous post), but is already enough to discern these laws in action. For instance, here is how the data set […]
13 October, 2009 at 10:25 am
Mike
Nice to look back at somthing written before the elections. Thanks
11 August, 2010 at 9:43 am
April S.
This is a really interesting! I love statistics and hate it when I see polls that are obviously skewed in their results. I think a big part of it is biased sampling. Poll the people who will give the answer you want and most people don’t know the difference!
http://blog.thinkwell.com/2010/08/7th-grade-math-populations-and-samples.html
14 September, 2010 at 10:15 pm
A second draft of a non-technical article on universality « What’s new
[…] Tao, “Small samples and the margin of error“, blog post, […]
29 July, 2011 at 11:40 pm
Quora
How do I determine that there are less than 10% brown M&Ms in a particular group?…
The fact that the big box is 20% brown doesn’t have any bearing — you could break the box up into groups in such a way that one of the groups was entirely brown, or such that one group was entirely red, or both. In fact, since you’re only looking at…
25 September, 2011 at 7:08 am
xoeve
This isn’t true. The 95% probability refers to the sampling error, not to the interval itself. The true population percentage is either in the interval or it is not. If we conducted the same survey many times, drawing a new sample each time, and we calculated the 95% confidence interval around the estimated proportion in each of these, then we would have many confidence intervals. 95% of these would contain the true population percentage, 5% would not.
25 September, 2011 at 7:25 pm
Terence Tao
Yes, the 95% probability only applies as an unconditional probability before the poll is taken, and not as a conditional probability after the poll is taken; this is discussed at the end of the “Assumptions and conclusions” section.
17 September, 2014 at 3:24 pm
A mágica das pesquisas eleitorais | Economia de Pen Drive
[…] Quer entender melhor a matemática por trás dessa história ? https://terrytao.wordpress.com/2008/10/10/small-samples-and-the-margin-of-error/ […]
14 December, 2014 at 7:12 pm
La encuesta electoral y las intenciones políticas. Por Carlos Martínez G. | Politica Politico
[…] [4] Terence Tao. https://terrytao.wordpress.com/2008/10/10/small-samples-and-the-margin-of-error/ […]
29 November, 2015 at 4:13 pm
Pollstistics | Cogito Ergo
[…] more realistic number for mathematical reasons relating to the sampling itself and randomness (see Small samples, and the margin of error). Further, even this is somewhat idealized in scenario and questions can come up as to nature of […]
21 February, 2016 at 7:12 pm
Joung Hwang
Thank you for this exposition. I have a follow-up question. Usually, any given poll asks different questions to respondents. An example would be polling about multiple different potential presidential match-ups (e.g., Trump vs. Clinton, Trump vs. Sanders, Rubio vs. Clinton, etc.) Since the same sample is being used to estimate these different match-ups, the estimates do not appear to be statistially independent to each other. How should one think about figuring out valid margins of error when a single poll is used to produce estimates for multiple questions?