
You are currently browsing the monthly archive for November 2015.
A basic estimate in multiplicative number theory (particularly if one is using the Granville-Soundararajan “pretentious” approach to this subject) is the following inequality of Halasz (formulated here in a quantitative form introduced by Montgomery and Tenenbaum).
Theorem 1 (Halasz inequality) Let
be a multiplicative function bounded in magnitude by
, and suppose that
,
, and
are such that
for all real numbers
with
. Then

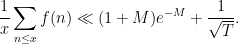
As a qualitative corollary, we conclude (by standard compactness arguments) that if


as 

is obtained (with a more precise description of the 
The usual proofs of Halasz’s theorem are somewhat lengthy (though there has been a recent simplification, in forthcoming work of Granville, Harper, and Soundarajan). Below the fold I would like to give a relatively short proof of the following “cheap” version of the inequality, which has slightly weaker quantitative bounds, but still suffices to give qualitative conclusions such as (2).
Theorem 2 (Cheap Halasz inequality) Let
, and suppose that
is sufficiently large depending on
. If (1) holds for all

The non-optimal exponent 
The idea of the argument is to split 
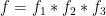
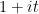



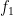
I thank Andrew Granville for helpful comments which led to significant simplifications of the argument.
In the previous set of notes we established the central limit theorem, which we formulate here as follows:
Theorem 1 (Central limit theorem) Let
be iid copies of a real random variable
of mean
and variance
, and write
. Then, for any fixed
, we have

This is however not the end of the matter; there are many variants, refinements, and generalisations of the central limit theorem, and the purpose of this set of notes is to present a small sample of these variants.
First of all, the above theorem does not quantify the rate of convergence in (1). We have already addressed this issue to some extent with the Berry-Esséen theorem, which roughly speaking gives a convergence rate of 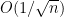

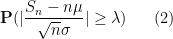
in the setting where 

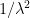
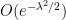
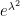
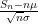
In the other direction, we can also look at the fine scale behaviour of the sums 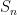

where 


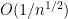
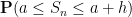

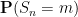
We also discuss other limit theorems in which the limiting distribution is something other than the normal distribution. Perhaps the most common example of these theorems is the Poisson limit theorems, in which one sums a large number of indicator variables (or approximate indicator variables), each of which is rarely non-zero, but which collectively add up to a random variable of medium-sized mean. In this case, it turns out that the limiting distribution should be a Poisson random variable; this again is an easy application of the Fourier method. Finally, we briefly discuss limit theorems for other stable laws than the normal distribution, which are suitable for summing random variables of infinite variance, such as the Cauchy distribution.
Finally, we mention a very important class of generalisations to the CLT (and to the variants of the CLT discussed in this post), in which the hypothesis of joint independence between the variables 
Kevin Ford, James Maynard, and I have uploaded to the arXiv our preprint “Chains of large gaps between primes“. This paper was announced in our previous paper with Konyagin and Green, which was concerned with the largest gap
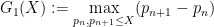
between consecutive primes up to

to
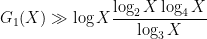
for large 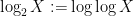


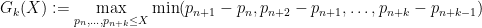
which measures how far apart the gaps between chains of 
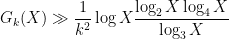
whenever 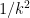
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Our arguments combine those from the previous paper with the matrix method of Maier, who (in our notation) showed that

for an infinite sequence of
As its name suggests, the Maier matrix method is usually presented by imagining a matrix of numbers, and using information about the distribution of primes in the columns of this matrix to deduce information about the primes in at least one of the rows of the matrix. We found it convenient to interpret this method in an equivalent probabilistic form as follows. Suppose one wants to find an interval 



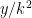
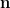

By carefully choosing the residue class of 








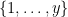
Using a version of the prime number theorem in arithmetic progressions due to Gallagher, one can show that for each remaining shift 


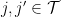



Klaus Roth, who made fundamental contributions to analytic number theory, died this Tuesday, aged 90.
I never met or communicated with Roth personally, but was certainly influenced by his work; he wrote relatively few papers, but they tended to have outsized impact. For instance, he was one of the key people (together with Bombieri) to work on simplifying and generalising the large sieve, taking it from the technically formidable original formulation of Linnik and Rényi to the clean and general almost orthogonality principle that we have today (discussed for instance in these lecture notes of mine). The paper of Roth that had the most impact on my own personal work was his three-page paper proving what is now known as Roth’s theorem on arithmetic progressions:
Theorem 1 (Roth’s theorem on arithmetic progressions) Let
be a set of natural numbers of positive upper density (thus
). Then
of length three (with
non-zero of course).
At the heart of Roth’s elegant argument was the following (surprising at the time) dichotomy: if 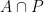
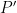
The Erdös discrepancy problem also is connected with another well known theorem of Roth:
Theorem 2 (Roth’s discrepancy theorem for arithmetic progressions) Let
be a sequence in
. Then there exists an arithmetic progression
in
with
for an absolute constant
.

In fact, Roth proved a stronger estimate regarding mean square discrepancy, which I am not writing down here; as with the Roth theorem in arithmetic progressions, his proof was short and Fourier-analytic in nature (although non-Fourier-analytic proofs have since been found, for instance the semidefinite programming proof of Lovasz). The exponent 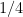
As a particular corollary of the above theorem, for an infinite sequence 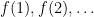


Finally, one has to mention Roth’s most famous result, cited for instance in his Fields medal citation:
Theorem 3 (Roth’s theorem on Diophantine approximation) Let
be an irrational algebraic number. Then for any
there is a quantity
such that

From the Dirichlet approximation theorem (or from the theory of continued fractions) we know that the exponent 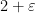


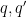
Chantal David, Andrew Granville, Emmanuel Kowalski, Phillipe Michel, Kannan Soundararajan, and I are running a program at MSRI in the Spring of 2017 (more precisely, from Jan 17, 2017 to May 26, 2017) in the area of analytic number theory, with the intention to bringing together many of the leading experts in all aspects of the subject and to present recent work on the many active areas of the subject (e.g. the distribution of the prime numbers, refinements of the circle method, a deeper understanding of the asymptotics of bounded multiplicative functions (and applications to Erdos discrepancy type problems!) and of the “pretentious” approach to analytic number theory, more “analysis-friendly” formulations of the theorems of Deligne and others involving trace functions over fields, and new subconvexity theorems for automorphic forms, to name a few). Like any other semester MSRI program, there will be a number of workshops, seminars, and similar activities taking place while the members are in residence. I’m personally looking forward to the program, which should be occurring in the midst of a particularly productive time for the subject. Needless to say, I (and the rest of the organising committee) plan to be present for most of the program.
Applications for Postdoctoral Fellowships and Research Memberships for this program (and for other MSRI programs in this time period, namely the companion program in Harmonic Analysis and the Fall program in Geometric Group Theory, as well as the complementary program in all other areas of mathematics) remain open until Dec 1. Applications are open to everyone, but require supporting documentation, such as a CV, statement of purpose, and letters of recommendation from other mathematicians; see the application page for more details.
Let 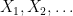
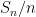

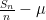


and

Then, as computed in previous notes, the normalised fluctuation 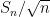


This and Chebyshev’s inequality already indicates that the “typical” size of 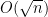

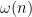

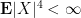

From this and the Paley-Zygmund inequality (Exercise 44 of Notes 1) we also get some lower bound for 
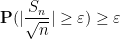
for some absolute constant 

The question remains as to what happens to the ratio
Proposition 1 Let
Proof: Suppose for contradiction that some sequence 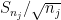


Nevertheless there is an important limit for the ratio
Definition 2 (Vague convergence and convergence in distribution) Let
be a locally compact Hausdorff topological space with the Borel
-algebra. A sequence of finite measures
on
as
. (Vague convergence is also known as weak convergence, although strictly speaking the terminology weak-* convergence would be more accurate.) A sequence of random variables
taking values in
converge vaguely to the distribution
, or equivalently if
as

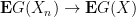
One could in principle try to extend this definition beyond the locally compact Hausdorff setting, but certain pathologies can occur when doing so (e.g. failure of the Riesz representation theorem), and we will never need to consider vague convergence in spaces that are not locally compact Hausdorff, so we restrict to this setting for simplicity.
Note that the notion of convergence in distribution depends only on the distribution of the random variables involved. One consequence of this is that convergence in distribution does not produce unique limits: if 

From the dominated convergence theorem (available for both convergence in probability and almost sure convergence) we see that convergence in probability or almost sure convergence implies convergence in distribution. The converse is not true, due to the insensitivity of convergence in distribution to equivalence in distribution; for instance, if
Remark 3 The notion of convergence in distribution is somewhat similar to the notion of convergence in the sense of distributions that arises in distribution theory (discussed for instance in this previous blog post), however strictly speaking the two notions of convergence are distinct and should not be confused with each other, despite the very similar names.
The notion of convergence in distribution simplifies in the case of real scalar random variables:
Proposition 4 Let
- (i)
- (ii)
converges to
for each continuity point
(i.e. for all real numbers
at which
is the cumulative distribution function of
Proof: First suppose that 

for every ![{t' \in [t-\delta,t+\delta]}](https://s0.wp.com/latex.php?latex=%7Bt%27+%5Cin+%5Bt-%5Cdelta%2Ct%2B%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




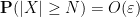
and
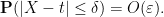
Let ![{G: {\bf R} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7BG%3A+%7B%5Cbf+R%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-2N, t]}](https://s0.wp.com/latex.php?latex=%7B%5B-2N%2C+t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-N, t-\delta]}](https://s0.wp.com/latex.php?latex=%7B%5B-N%2C+t-%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

and hence

for large enough
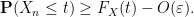
A similar argument, replacing 
![{[t,2N]}](https://s0.wp.com/latex.php?latex=%7B%5Bt%2C2N%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[t+\delta,N]}](https://s0.wp.com/latex.php?latex=%7B%5Bt%2B%5Cdelta%2CN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
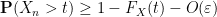
for

for 
Conversely, suppose that 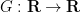
![{G_\varepsilon(t) = \sum_{i=1}^n c_i 1_{(t_i,t_{i+1}]}}](https://s0.wp.com/latex.php?latex=%7BG_%5Cvarepsilon%28t%29+%3D+%5Csum_%7Bi%3D1%7D%5En+c_i+1_%7B%28t_i%2Ct_%7Bi%2B1%7D%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


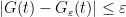
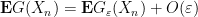
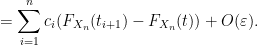
Similarly for

and on sending
The restriction to continuity points of 

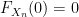

Example 5 For any natural number
, and let
Example 6 For any natural number
, then
Exercise 7 (Portmanteau theorem) Show that the properties (i) and (ii) in Proposition 4 are also equivalent to the following three statements:
- (iii) One has
for all closed sets
.
- (iv) One has
for all open sets
.
- (v) For any Borel set
whose topological boundary
is such that
, one has
.
(Note: to prove this theorem, you may wish to invoke Urysohn’s lemma. To deduce (iii) from (i), you may wish to start with the case of compact
.)
We can now state the famous central limit theorem:
Theorem 8 (Central limit theorem) Let
and finite non-zero variance
. Let
converges in distribution to a random variable with the standard normal distribution
(that is to say, a random variable with probability density function
). Thus, by abuse of notation
In the normalised case
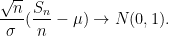

Using Proposition 4 (and the fact that the cumulative distribution function associated to

as

Informally, one can think of the central limit theorem as asserting that 


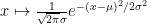
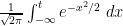


The central limit theorem is a basic example of the universality phenomenon in probability – many statistics involving a large system of many independent (or weakly dependent) variables (such as the normalised sums 
We will give several proofs of the central limit theorem in these notes; each of these proofs has their advantages and disadvantages, and can each extend to prove many further results beyond the central limit theorem. We first give Lindeberg’s proof of the central limit theorem, based on exchanging (or swapping) each component 
The following exercise illustrates the power of the central limit theorem, by establishing combinatorial estimates which would otherwise require the use of Stirling’s formula to establish.
Exercise 9 (De Moivre-Laplace theorem) Let
with
, thus
.
- (i) Show that
with
. (This is an example of a binomial distribution.)
- (ii) Assume Stirling’s formula
where
is a function of
as
.
The above special case of the central limit theorem was first established by de Moivre and Laplace.


We close this section with some basic facts about convergence of distribution that will be useful in the sequel.
Exercise 10 Let
be sequences of real random variables, and let
be further real random variables.
- (i) If
- (ii) Suppose that
for each
converges in distribution to
if and only if
- (iii) If
such that
for all sufficiently large
- (iv) Show that
and
of
converges almost surely to
- (v) If
is continuous, show that
converges in distribution to
. Generalise this claim to the case when
- (vi) (Slutsky’s theorem) If
converges in distribution to
, and
converges in distribution to
. (Hint: either use (iv), or else use (iii) to control some error terms.) This statement combines particularly well with (i). What happens if
- (vii) (Fatou lemma) If
is continuous, and
.
- (viii) (Bounded convergence) If
.
- (ix) (Dominated convergence) If
almost surely for all
.
For future reference we also mention (but will not prove) Prokhorov’s theorem that gives a partial converse to part (iii) of the above exercise:
Theorem 11 (Prokhorov’s theorem) Let
for all sufficiently large
which converges in distribution to some random variable
The proof of this theorem relies on the Riesz representation theorem, and is beyond the scope of this course; but see for instance Exercise 29 of this previous blog post. (See also the closely related Helly selection theorem, covered in Exercise 30 of the same post.)

Recent Comments