
You are currently browsing the tag archive for the ‘Cauchy-Schwarz’ tag.
Let 

![{H[X]}](https://s0.wp.com/latex.php?latex=%7BH%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle H[X] = -\sum_{s \in S} {\bf P}[X = s] \log {\bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%5BX%5D+%3D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Lemma 1 (Gibbs variational formula) Letbe a function. Then
![\displaystyle \log \sum_{s \in S} \exp(f(s)) = \sup_X {\bf E} f(X) + {\bf H}[X]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clog+%5Csum_%7Bs+%5Cin+S%7D+%5Cexp%28f%28s%29%29+%3D+%5Csup_X+%7B%5Cbf+E%7D+f%28X%29+%2B+%7B%5Cbf+H%7D%5BX%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Note that shifting 



![\displaystyle 0 = \sup_X \sum_{s \in S} {\bf P}[X = s] \log {\bf P}[Y = s] -\sum_{s \in S} {\bf P}[X = s] \log {\bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++0+%3D+%5Csup_X+%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BY+%3D+s%5D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
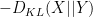 , where
, where 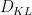 denotes Kullback-Leibler divergence. One can also interpret this inequality as a special case of the Fenchel–Young inequality relating the conjugate convex functions
denotes Kullback-Leibler divergence. One can also interpret this inequality as a special case of the Fenchel–Young inequality relating the conjugate convex functions  and
and  .)
.) 
In this note I would like to use this variational formula (which is also known as the Donsker-Varadhan variational formula) to give another proof of the following inequality of Carbery.
Theorem 2 (Generalized Cauchy-Schwarz inequality) Let, let
be finite non-empty sets, and let
be functions for each
. Let
and
be positive functions for each
where
is the quantity
where
is the set of all tuples
such that
for
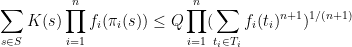

Thus for instance, the identity is trivial for 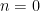

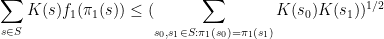

 the inequality reads
the inequality reads 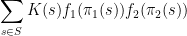
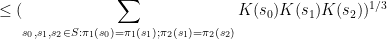

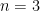 , the existing proofs require the “tensor power trick” in order to reduce to the case when the
, the existing proofs require the “tensor power trick” in order to reduce to the case when the  are step functions (in which case the inequality can be proven elementarily, as discussed in the above paper of Carbery).
are step functions (in which case the inequality can be proven elementarily, as discussed in the above paper of Carbery).
We now prove this inequality. We write 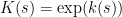
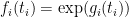

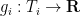
![\displaystyle \sup_X {\bf E} k(X) + \sum_{i=1}^n g_i(\pi_i(X)) + {\bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_X+%7B%5Cbf+E%7D+k%28X%29+%2B+%5Csum_%7Bi%3D1%7D%5En+g_i%28%5Cpi_i%28X%29%29+%2B+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \leq \frac{1}{n+1} \sup_{(X_0,\dots,X_n)} {\bf E} k(X_0)+\dots+k(X_n) + {\bf H}[X_0,\dots,X_n]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleq+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csup_%7B%28X_0%2C%5Cdots%2CX_n%29%7D+%7B%5Cbf+E%7D+k%28X_0%29%2B%5Cdots%2Bk%28X_n%29+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + \frac{1}{n+1} \sum_{i=1}^n \sup_{Y_i} (n+1) {\bf E} g_i(Y_i) + {\bf H}[Y_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%2B+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csum_%7Bi%3D1%7D%5En+%5Csup_%7BY_i%7D+%28n%2B1%29+%7B%5Cbf+E%7D+g_i%28Y_i%29+%2B+%7B%5Cbf+H%7D%5BY_i%5D&bg=ffffff&fg=000000&s=0&c=20201002) ranges over random variables taking values in ,
ranges over random variables taking values in ,  range over tuples of random variables taking values in , and
range over tuples of random variables taking values in , and 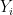 range over random variables taking values in
range over random variables taking values in 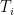 . Comparing the suprema, the claim now reduces to
. Comparing the suprema, the claim now reduces to
Lemma 3 (Conditional expectation computation) Let, where each
has the same distribution as
![\displaystyle {\bf H}[X_0,\dots,X_n] = (n+1) {\bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%28n%2B1%29+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle - {\bf H}[\pi_1(X)] - \dots - {\bf H}[\pi_n(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We induct on 



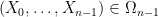
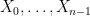
![\displaystyle {\bf H}[X_0,\dots,X_{n-1}] = n {\bf H}[X] - {\bf H}[\pi_1(X)] - \dots - {\bf H}[\pi_{n-1}(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%3D+n+%7B%5Cbf+H%7D%5BX%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_%7Bn-1%7D%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
 has the same distribution as
has the same distribution as 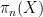 . For each value
. For each value 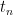 attained by , we can take conditionally independent copies of
attained by , we can take conditionally independent copies of  and conditioned to the events
and conditioned to the events 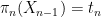 and
and 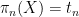 respectively, and then concatenate them to form a tuple in , with
respectively, and then concatenate them to form a tuple in , with 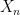 a further copy of that is conditionally independent of relative to
a further copy of that is conditionally independent of relative to  . One can the use the entropy chain rule to compute
. One can the use the entropy chain rule to compute ![\displaystyle {\bf H}[X_0,\dots,X_n] = {\bf H}[\pi_n(X_n)] + {\bf H}[X_0,\dots,X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%7C+%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X_n)] + {\bf H}[X_0,\dots,X_{n-1}| \pi_n(X_n)] + {\bf H}[X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X)] + {\bf H}[X_0,\dots,X_{n-1}| \pi_n(X_{n-1})] + {\bf H}[X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_%7Bn-1%7D%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X)] + ({\bf H}[X_0,\dots,X_{n-1}] - {\bf H}[\pi_n(X_{n-1})])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%28%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_%7Bn-1%7D%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + ({\bf H}[X_n] - {\bf H}[\pi_n(X_n)])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%2B+%28%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle ={\bf H}[X_0,\dots,X_{n-1}] + {\bf H}[X_n] - {\bf H}[\pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%2B+%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
With a little more effort, one can replace
Given two unit vectors 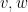
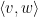
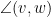






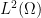
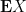
One can also define correlation for complex (Hermitian) inner product spaces by taking the real part 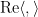
While reading the (highly recommended) recent popular maths book “How not to be wrong“, by my friend and co-author Jordan Ellenberg, I came across the (important) point that correlation is not necessarily transitive: if 

in the Euclidean plane 

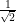
However, there are at least two situations in which some partial version of transitivity of correlation can be recovered. The first is in the “99%” regime in which the correlations are very close to 
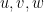
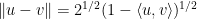
(and similarly for 


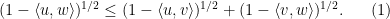
Thus, for instance, if 
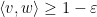
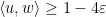

Remark 1 (Thanks to Andrew Granville for conversations leading to this observation.) The inequality (1) also holds for sub-unit vectors, i.e. vectors
. This comes by extending
if necessary. More concretely, one can apply (1) to the unit vectors
in
.

But even in the “

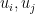
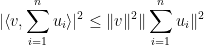
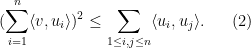
Thus, for instance, if 






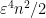


A similar argument (multiplying each 

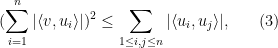
and this inequality is also true for complex inner product spaces. (Also, the
Geometrically, the picture is this: if 
A particularly common special case of the van der Corput inequality arises when 


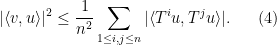
(In fact, one can even remove the absolute values from the right-hand side, by using (2) instead of (4).) Thus, to show that
Here is a basic application of the van der Corput inequality:
Proposition 2 (Weyl equidistribution estimate) Let
be a polynomial with at least one non-constant coefficient irrational. Then one has
where
.

Note that this assertion implies the more general assertion

for any non-zero integer 

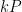

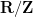
Proof: We induct on the degree 
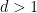

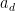
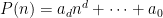
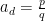

In order to use the van der Corput inequality as stated above (i.e. in the formalism of inner product spaces) we will need a non-principal ultrafilter 
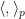
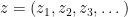
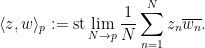
Strictly speaking, this inner product is only positive semi-definite rather than positive definite, but one can quotient out by the null vectors to obtain a positive-definite inner product. To establish the claim, it will suffice to show that
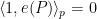
for every non-principal ultrafilter
Note that the space of bounded sequences (modulo null vectors) admits a shift
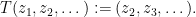
This shift becomes unitary once we quotient out by null vectors, and the constant sequence
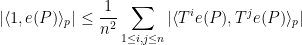
for any 
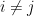
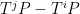
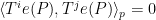
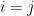
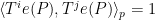

for any 
This is the final continuation of the online reading seminar of Zhang’s paper for the polymath8 project. (There are two other continuations; this previous post, which deals with the combinatorial aspects of the second part of Zhang’s paper, and this previous post, that covers the Type I and Type II sums.) The main purpose of this post is to present (and hopefully, to improve upon) the treatment of the final and most innovative of the key estimates in Zhang’s paper, namely the Type III estimate.
The main estimate was already stated as Theorem 17 in the previous post, but we quickly recall the relevant definitions here. As in other posts, we always take 
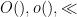
Definition 1 (Coefficient sequences) A coefficient sequence is a finitely supported sequence
that obeys the bounds
for all
is the divisor function.
- (i) If
is a coefficient sequence and
is a primitive residue class, the (signed) discrepancy
of
- (ii) A coefficient sequence
for some
if it is supported on an interval of the form
.
- (iii) A coefficient sequence
for some smooth function
supported on
obeying the derivative bounds
for all fixed
(note that the implied constant in the
notation may depend on
).



For any 
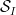

Theorem 2 (Type III estimate) Let
be fixed quantities, and let
be quantities such that
and
and
for some fixed
. Let
be coefficient sequences at scale
respectively with
smooth. Then for any
we have
In fact we have the stronger “pointwise” estimate
for all
with
and all
, and some fixed
.





(This is very slightly stronger than previously claimed, in that the condition 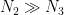
It turns out that Zhang does not exploit any averaging of the
Theorem 3 (Type III estimate without
be fixed, and let
be quantities such that
and
and
for some fixed
respectively. Then we have
for all
and some fixed

![\displaystyle d \in {\mathcal S}_{[1,x^\delta]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+d+%5Cin+%7B%5Cmathcal+S%7D_%7B%5B1%2Cx%5E%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Let us quickly see how Theorem 3 implies Theorem 2. To show (4), it suffices to establish the bound

for all 


From Theorem 3 we have

where the quantity 

It remains to establish Theorem 3. This is done by a set of tools similar to that used to control the Type I and Type II sums:
- (i) completion of sums;
- (ii) the Weil conjectures and bounds on Ramanujan sums;
- (iii) factorisation of smooth moduli
- (iv) the Cauchy-Schwarz and triangle inequalities (Weyl differencing).
The specifics are slightly different though. For the Type I and Type II sums, it was the classical Weil bound on Kloosterman sums that were the key source of power saving; Ramanujan sums only played a minor role, controlling a secondary error term. For the Type III sums, one needs a significantly deeper consequence of the Weil conjectures, namely the estimate of Bombieri and Birch on a three-dimensional variant of a Kloosterman sum. Furthermore, the Ramanujan sums – which are a rare example of sums that actually exhibit better than square root cancellation, thus going beyond even what the Weil conjectures can offer – make a crucial appearance, when combined with the factorisation of the smooth modulus
The following result is due independently to Furstenberg and to Sarkozy:
Theorem 1 (Furstenberg-Sarkozy theorem) Let
. Then every subset
of
of density
at least
for some natural numbers
with
.
This theorem is of course similar in spirit to results such as Roth’s theorem or Szemerédi’s theorem, in which the pattern 
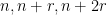

A few years ago, Ben Green, Tamar Ziegler, and myself observed that it is possible to prove the Furstenberg-Sarkozy theorem by just using the Cauchy-Schwarz inequality (or van der Corput lemma) and the density increment argument, removing all invocations of Fourier analysis, and instead relying on Cauchy-Schwarz to linearise the quadratic shift 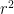
The first step is to use the density increment argument that goes back to Roth. For any 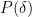
![{A \subset [N]}](https://s0.wp.com/latex.php?latex=%7BA+%5Csubset+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

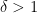
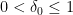

for some absolute constant 
It remains to establish the implication (1). Suppose for sake of contradiction that we can find 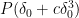

![{[N]}](https://s0.wp.com/latex.php?latex=%7B%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h \in [N^{1/100}]} 1_A(n) 1_A(n+(r+h)^2) = 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+1_A%28n%29+1_A%28n%2B%28r%2Bh%29%5E2%29+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)
(The exact ranges of 
Let 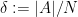
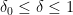
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h \in [N^{1/100}]} 1_A(n) \delta 1_{[N]}(n+(r+h)^2) = \delta^2 + O(N^{-1/3})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+1_A%28n%29+%5Cdelta+1_%7B%5BN%5D%7D%28n%2B%28r%2Bh%29%5E2%29+%3D+%5Cdelta%5E2+%2B+O%28N%5E%7B-1%2F3%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h \in [N^{1/100}]} \delta 1_{[N]}(n) \delta 1_{[N]}(n+(r+h)^2) = \delta^2 + O(N^{-1/3})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+%5Cdelta+1_%7B%5BN%5D%7D%28n%29+%5Cdelta+1_%7B%5BN%5D%7D%28n%2B%28r%2Bh%29%5E2%29+%3D+%5Cdelta%5E2+%2B+O%28N%5E%7B-1%2F3%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h \in [N^{1/100}]} \delta 1_{[N]}(n) 1_A(n+(r+h)^2) = \delta^2 + O( N^{-1/3} ).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+%5Cdelta+1_%7B%5BN%5D%7D%28n%29+1_A%28n%2B%28r%2Bh%29%5E2%29+%3D+%5Cdelta%5E2+%2B+O%28+N%5E%7B-1%2F3%7D+%29.&bg=ffffff&fg=000000&s=0&c=20201002)
If we thus set ![{f := 1_A - \delta 1_{[N]}}](https://s0.wp.com/latex.php?latex=%7Bf+%3A%3D+1_A+-+%5Cdelta+1_%7B%5BN%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h \in [N^{1/100}]} f(n) f(n+(r+h)^2) = -\delta^2 + O( N^{-1/3} ).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+f%28n%29+f%28n%2B%28r%2Bh%29%5E2%29+%3D+-%5Cdelta%5E2+%2B+O%28+N%5E%7B-1%2F3%7D+%29.&bg=ffffff&fg=000000&s=0&c=20201002)
In particular, for
![\displaystyle \mathop{\bf E}_{n \in [N]} |f(n)| \mathop{\bf E}_{r \in [N^{1/3}]} |\mathop{\bf E}_{h \in [N^{1/100}]} f(n+(r+h)^2)| \gg \delta^2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%7Cf%28n%29%7C+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%7C%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+f%28n%2B%28r%2Bh%29%5E2%29%7C+%5Cgg+%5Cdelta%5E2.&bg=ffffff&fg=000000&s=0&c=20201002)
On the other hand, one easily sees that
![\displaystyle \mathop{\bf E}_{n \in [N]} |f(n)|^2 = O(\delta)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%7Cf%28n%29%7C%5E2+%3D+O%28%5Cdelta%29&bg=ffffff&fg=000000&s=0&c=20201002)
and hence by the Cauchy-Schwarz inequality
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} |\mathop{\bf E}_{h \in [N^{1/100}]} f(n+(r+h)^2)|^2 \gg \delta^3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%7C%5Cmathop%7B%5Cbf+E%7D_%7Bh+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+f%28n%2B%28r%2Bh%29%5E2%29%7C%5E2+%5Cgg+%5Cdelta%5E3&bg=ffffff&fg=000000&s=0&c=20201002)
which we can rearrange as
![\displaystyle |\mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h,h' \in [N^{1/100}]} \mathop{\bf E}_{n \in [N]} f(n+(r+h)^2) f(n+(r+h')^2)| \gg \delta^3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh%2Ch%27+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+f%28n%2B%28r%2Bh%29%5E2%29+f%28n%2B%28r%2Bh%27%29%5E2%29%7C+%5Cgg+%5Cdelta%5E3.&bg=ffffff&fg=000000&s=0&c=20201002)
Shifting 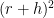
![\displaystyle |\mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{h,h' \in [N^{1/100}]} \mathop{\bf E}_{n \in [N]} f(n) f(n+(h'-h)(2r+h'+h))| \gg \delta^3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bh%2Ch%27+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+f%28n%29+f%28n%2B%28h%27-h%29%282r%2Bh%27%2Bh%29%29%7C+%5Cgg+%5Cdelta%5E3.&bg=ffffff&fg=000000&s=0&c=20201002)
In particular, by the pigeonhole principle (and deleting the diagonal case 
![{h,h' \in [N^{1/100}]}](https://s0.wp.com/latex.php?latex=%7Bh%2Ch%27+%5Cin+%5BN%5E%7B1%2F100%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle |\mathop{\bf E}_{r \in [N^{1/3}]} \mathop{\bf E}_{n \in [N]} f(n) f(n+(h'-h)(2r+h'+h))| \gg \delta^3,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+f%28n%29+f%28n%2B%28h%27-h%29%282r%2Bh%27%2Bh%29%29%7C+%5Cgg+%5Cdelta%5E3%2C&bg=ffffff&fg=000000&s=0&c=20201002)
so in particular
![\displaystyle \mathop{\bf E}_{n \in [N]} |\mathop{\bf E}_{r \in [N^{1/3}]} f(n+(h'-h)(2r+h'+h))| \gg \delta^3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%7C%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+f%28n%2B%28h%27-h%29%282r%2Bh%27%2Bh%29%29%7C+%5Cgg+%5Cdelta%5E3.&bg=ffffff&fg=000000&s=0&c=20201002)
If we set 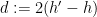
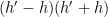
![\displaystyle \mathop{\bf E}_{n \in [N]} |\mathop{\bf E}_{r \in [N^{1/3}]} f(n+dr)| \gg \delta^3. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%7C%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+f%28n%2Bdr%29%7C+%5Cgg+%5Cdelta%5E3.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
On the other hand, since
![\displaystyle \mathop{\bf E}_{n \in [N]} f(n) = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+f%28n%29+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)
we have
![\displaystyle \mathop{\bf E}_{n \in [N]} f(n+dr) = O( N^{-2/3+1/100})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+f%28n%2Bdr%29+%3D+O%28+N%5E%7B-2%2F3%2B1%2F100%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
for any ![{r \in [N^{1/3}]}](https://s0.wp.com/latex.php?latex=%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} \mathop{\bf E}_{r \in [N^{1/3}]} f(n+dr) = O( N^{-2/3+1/100}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+f%28n%2Bdr%29+%3D+O%28+N%5E%7B-2%2F3%2B1%2F100%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
Averaging this with (2) we conclude that
![\displaystyle \mathop{\bf E}_{n \in [N]} \max( \mathop{\bf E}_{r \in [N^{1/3}]} f(n+dr), 0 ) \gg \delta^3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmax%28+%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+f%28n%2Bdr%29%2C+0+%29+%5Cgg+%5Cdelta%5E3.&bg=ffffff&fg=000000&s=0&c=20201002)
In particular, by the pigeonhole principle we can find ![{n \in [N]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{r \in [N^{1/3}]} f(n+dr) \gg \delta^3,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Br+%5Cin+%5BN%5E%7B1%2F3%7D%5D%7D+f%28n%2Bdr%29+%5Cgg+%5Cdelta%5E3%2C&bg=ffffff&fg=000000&s=0&c=20201002)
or equivalently 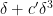
![{\{ n+dr: r \in [N^{1/3}]\}}](https://s0.wp.com/latex.php?latex=%7B%5C%7B+n%2Bdr%3A+r+%5Cin+%5BN%5E%7B1%2F3%7D%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


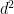

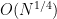
![{\{ n' + d^2 r': r' \in [N^{1/4}]\}}](https://s0.wp.com/latex.php?latex=%7B%5C%7B+n%27+%2B+d%5E2+r%27%3A+r%27+%5Cin+%5BN%5E%7B1%2F4%7D%5D%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

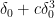
![\displaystyle A' := \{ r' \in [N^{1/4}]: n' + d^2 r' \in A \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++A%27+%3A%3D+%5C%7B+r%27+%5Cin+%5BN%5E%7B1%2F4%7D%5D%3A+n%27+%2B+d%5E2+r%27+%5Cin+A+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
we conclude (for 
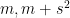


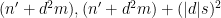
A more careful analysis of the above argument reveals a more quantitative version of Theorem 1: for 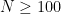


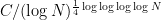



Remark 1 A similar argument also applies with
for fixed
into arithmetic progressions whose spacing
is a
power. By re-introducing Fourier analysis, one can also perform an argument of this type for
where
for polynomials
, to avoid local obstructions), because one no longer has this preservation property.
I’ve just uploaded to the arXiv my paper “Mixing for progressions in non-abelian groups“, submitted to Forum of Mathematics, Sigma (which, along with sister publication Forum of Mathematics, Pi, has just opened up its online submission system). This paper is loosely related in subject topic to my two previous papers on polynomial expansion and on recurrence in quasirandom groups (with Vitaly Bergelson), although the methods here are rather different from those in those two papers. The starting motivation for this paper was a question posed in this foundational paper of Tim Gowers on quasirandom groups. In that paper, Gowers showed (among other things) that if 




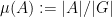


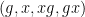




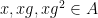
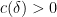
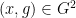


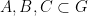



For non-quasirandom groups, such mixing properties can certainly fail. For instance, if 
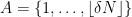
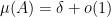




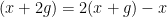



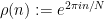
However, by definition, quasirandom groups do not have low-dimensional representations, and Gowers asked whether mixing for 





I was also able to obtain a partial result for the length four progression 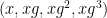

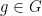
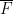
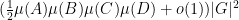



For the length three argument, the main tools used are the Cauchy-Schwarz inequality, the quasirandomness of 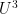
I give some details of these arguments below the fold.
Title: Use basic examples to calibrate exponents
Motivation: In the more quantitative areas of mathematics, such as analysis and combinatorics, one has to frequently keep track of a large number of exponents in one’s identities, inequalities, and estimates. For instance, if one is studying a set of N elements, then many expressions that one is faced with will often involve some power 



Quick description: When trying to quickly work out what an exponent p in an estimate, identity, or inequality should be without deriving that statement line-by-line, test that statement with a simple example which has non-trivial behaviour with respect to that exponent p, but trivial behaviour with respect to as many other components of that statement as one is able to manage. The “non-trivial” behaviour should be parametrised by some very large or very small parameter. By matching the dependence on this parameter on both sides of the estimate, identity, or inequality, one should recover p (or at least a good prediction as to what p should be).
General discussion: The test examples should be as basic as possible; ideally they should have trivial behaviour in all aspects except for one feature that relates to the exponent p that one is trying to calibrate, thus being only “barely” non-trivial. When the object of study is a function, then (appropriately rescaled, or otherwise modified) bump functions are very typical test objects, as are Dirac masses, constant functions, Gaussians, or other functions that are simple and easy to compute with. In additive combinatorics, when the object of study is a subset of a group, then subgroups, arithmetic progressions, or random sets are typical test objects. In graph theory, typical examples of test objects include complete graphs, complete bipartite graphs, and random graphs. And so forth.
This trick is closely related to that of using dimensional analysis to recover exponents; indeed, one can view dimensional analysis as the special case of exponent calibration when using test objects which are non-trivial in one dimensional aspect (e.g. they exist at a single very large or very small length scale) but are otherwise of a trivial or “featureless” nature. But the calibration trick is more general, as it can involve parameters (such as probabilities, angles, or eccentricities) which are not commonly associated with the physical concept of a dimension. And personally, I find example-based calibration to be a much more satisfying (and convincing) explanation of an exponent than a calibration arising from formal dimensional analysis.
When one is trying to calibrate an inequality or estimate, one should try to pick a basic example which one expects to saturate that inequality or estimate, i.e. an example for which the inequality is close to being an equality. Otherwise, one would only expect to obtain some partial information on the desired exponent p (e.g. a lower bound or an upper bound only). Knowing the examples that saturate an estimate that one is trying to prove is also useful for several other reasons – for instance, it strongly suggests that any technique which is not efficient when applied to the saturating example, is unlikely to be strong enough to prove the estimate in general, thus eliminating fruitless approaches to a problem and (hopefully) refocusing one’s attention on those strategies which actually have a chance of working.
Calibration is best used for the type of quick-and-dirty calculations one uses when trying to rapidly map out an argument that one has roughly worked out already, but without precise details; in particular, I find it particularly useful when writing up a rapid prototype. When the time comes to write out the paper in full detail, then of course one should instead carefully work things out line by line, but if all goes well, the exponents obtained in that process should match up with the preliminary guesses for those exponents obtained by calibration, which adds confidence that there are no exponent errors have been committed.
Prerequisites: Undergraduate analysis and combinatorics.
This week I was in Columbus, Ohio, attending a conference on equidistribution on manifolds. I talked about my recent paper with Ben Green on the quantitative behaviour of polynomial sequences in nilmanifolds, which I have blogged about previously. During my talk (and inspired by the immediately preceding talk of Vitaly Bergelson), I stated explicitly for the first time a generalisation of the van der Corput trick which morally underlies our paper, though it is somewhat buried there as we specialised it to our application at hand (and also had to deal with various quantitative issues that made the presentation more complicated). After the talk, several people asked me for a more precise statement of this trick, so I am presenting it here, and as an application reproving an old theorem of Leon Green that gives a necessary and sufficient condition as to whether a linear sequence 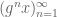
UPDATE, Feb 2013: It has been pointed out to me by Pavel Zorin that this argument does not fully recover the theorem of Leon Green; to cover all cases, one needs the more complicated van der Corput argument in our paper.
In the previous lecture, we studied the recurrence properties of compact systems, which are systems in which all measurable functions exhibit almost periodicity – they almost return completely to themselves after repeated shifting. Now, we consider the opposite extreme of mixing systems – those in which all measurable functions (of mean zero) exhibit mixing – they become orthogonal to themselves after repeated shifting. (Actually, there are two different types of mixing, strong mixing and weak mixing, depending on whether the orthogonality occurs individually or on the average; it is the latter concept which is of more importance to the task of establishing the Furstenberg recurrence theorem.)
We shall see that for weakly mixing systems, averages such as 
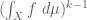
As one application of this theory, we will be able to establish Roth’s theorem (the k=3 case of Szemerédi’s theorem).

Recent Comments