
You are currently browsing the monthly archive for June 2009.
The summer continues to allow some clearing of the backlog of projects accumulated during the academic year: Helge Holden, Kenneth Karlsen, Nils Risebro, and myself have uploaded to the arXiv the paper “Operator splitting for the KdV equation“, submitted to Math. Comp.. This paper is concerned with accurate numerical schemes for solving initial value problems for the Korteweg-de Vries equation

though the analysis here would be valid for a wide range of other semilinear dispersive models as well. In principle, these equations, which are completely integrable, can be solved exactly by the inverse scattering method, but fast and accurate implementations of this method are still not as satisfactory as one would like. On the other hand, the linear Korteweg-de Vries equation

can be solved exactly (with accurate and fast numerics) via the (fast) Fourier transform, while the (inviscid) Burgers equation

can also be solved exactly (and quickly) by the method of characteristics. Since the KdV equation is in some sense a combination of the equations (2) and (3), it is then reasonable to hope that some combination of the solution schemes for (2) and (3) can be used to solve (1), at least in some approximate sense.
One way to do this is by the method of operator splitting. Observe from the formal approximation 



[we do not assume A and B to commute here] and thus we formally have

if 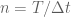
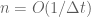

for time 


for time
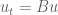
for time 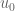
It turns out that this scheme can be formalised, and furthermore generalised to nonlinear settings such as those for the KdV equation (1). More precisely, we show that if 
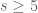

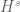
Actually, one can obtain faster convergence by modifying the scheme, at the cost of requiring higher regularity on the data; the situation is similar to that of numerical integration (or quadrature), in which the midpoint rule or Simpson’s rule provide more accuracy than the Riemann integral if the integrand is smooth. For instance, one has the variant

of (5), which can be seen by expansion to second order in 

One further paper in this stream: László Erdős, José Ramírez, Benjamin Schlein, Van Vu, Horng-Tzer Yau, and myself have just uploaded to the arXiv the paper “Bulk universality for Wigner hermitian matrices with subexponential decay“, submitted to Mathematical Research Letters. (Incidentally, this is my first six-author paper I have been involved in, not counting the polymath projects of course, though I have had a number of five-author papers.)
This short paper (9 pages) combines the machinery from two recent papers on the universality conjecture for the eigenvalue spacings in the bulk for Wigner random matrices (see my earlier blog post for more discussion). On the one hand, the paper of Erdős-Ramírez-Schlein-Yau established this conjecture under the additional hypothesis that the distribution of the individual entries obeyed some smoothness and exponential decay conditions. Meanwhile, the paper of Van Vu and myself (which I discussed in my earlier blog post) established the conjecture under a somewhat different set of hypotheses, namely that the distribution of the individual entries obeyed some moment conditions (in particular, the third moment had to vanish), a support condition (the entries had to have real part supported in at least three points), and an exponential decay condition.
After comparing our results, the six of us realised that our methods could in fact be combined rather easily to obtain a stronger result, establishing the universality conjecture assuming only a exponential decay (or more precisely, sub-exponential decay) bound 

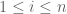
I can describe the main idea behind the unified approach here. One can arrange the Wigner matrices in a hierarchy, from most structured to least structured:
- The most structured (or special) ensemble is the Gaussian Unitary Ensemble (GUE), in which the coefficients are gaussian. Here, one has very explicit and tractable formulae for the eigenvalue distributions, gap spacing, etc.
- The next most structured ensemble of Wigner matrices are the Gaussian-divisible or Johansson matrices, which are matrices H of the form
, where
is another Wigner matrix, V is a GUE matrix independent of
is a fixed parameter independent of n. Here, one still has quite explicit (though not quite as tractable) formulae for the joint eigenvalue distribution and related statistics. Note that the limiting case t=1 is GUE.
- After this, one has the Ornstein-Uhlenbeck-evolved matrices, which are also of the form
decays at a power rate with n, rather than being comparable to 1. Explicit formulae still exist for these matrices, but extracting universality out of this is hard work (and occupies the bulk of the paper of Erdős-Ramírez-Schlein-Yau).
- Finally, one has arbitrary Wigner matrices, which can be viewed as the t=0 limit of the above Ornstein-Uhlenbeck process.
The arguments in the paper of Erdős-Ramírez-Schlein-Yau can be summarised as follows (I assume subexponential decay throughout this discussion):
- (Structured case) The universality conjecture is true for Ornstein-Uhlenbeck-evolved matrices with
. (The case
was treated in an earlier paper of Erdős-Ramírez-Schlein-Yau, while the case where t is comparable to 1 was treated by Johansson.)
- (Matching) Every Wigner matrix with suitable smoothness conditions can be “matched” with an Ornstein-Uhlenbeck-evolved matrix, in the sense that the eigenvalue statistics for the two matrices are asymptotically identical. (This is relatively easy due to the fact that
can be taken arbitrarily close to zero.)
- Combining 1. and 2. one obtains universality for all Wigner matrices obeying suitable smoothness conditions.
The arguments in the paper of Van and myself can be summarised as follows:
- (Structured case) The universality conjecture is true for Johansson matrices, by the paper of Johansson.
- (Matching) Every Wigner matrix with some moment and support conditions can be “matched” with a Johansson matrix, in the sense that the first four moments of the entries agree, and hence (by the Lindeberg strategy in our paper) have asymptotically identical statistics.
- Combining 1. and 2. one obtains universality for all Wigner matrices obtaining suitable moment and support conditions.
What we realised is by combining the hard part 1. of the paper of Erdős-Ramírez-Schlein-Yau with the hard part 2. of the paper of Van and myself, we can remove all regularity, moment, and support conditions. Roughly speaking, the unified argument proceeds as follows:
- (Structured case) By the arguments of Erdős-Ramírez-Schlein-Yau, the universality conjecture is true for Ornstein-Uhlenbeck-evolved matrices with
- (Matching) Every Wigner matrix
can be “matched” with an Ornstein-Uhlenbeck-evolved matrix
for
(say), in the sense that the first four moments of the entries almost agree, which is enough (by the arguments of Van and myself) to show that these two matrices have asymptotically identical statistics on the average.
- Combining 1. and 2. one obtains universality for the averaged statistics for all Wigner matrices.
The averaging should be removable, but this would require better convergence results to the semicircular law than are currently known (except with additional hypotheses, such as vanishing third moment). The subexponential decay should also be relaxed to a condition of finiteness for some fixed moment 
It turns out to be a favourable week or two for me to finally finish a number of papers that had been at a nearly completed stage for a while. I have just uploaded to the arXiv my article “Sumset and inverse sumset theorems for Shannon entropy“, submitted to Combinatorics, Probability, and Computing. This paper evolved from a “deleted scene” in my book with Van Vu entitled “Entropy sumset estimates“. In those notes, we developed analogues of the standard Plünnecke-Ruzsa sumset estimates (which relate quantities such as the cardinalities 
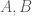

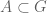

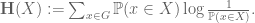
This quantity measures the information content of X; for instance, if 
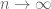
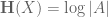
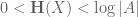
It turns out that many estimates on sumsets have entropy analogues, which resemble the “logarithm” of the sumset estimates. For instance, the trivial bounds

have the entropy analogue
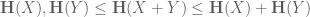
whenever X, Y are independent discrete random variables in an additive group; this is not difficult to deduce from standard entropy inequalities. Slightly more non-trivially, the sum set estimate
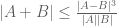
established by Ruzsa, has an entropy analogue

and similarly for a number of other standard sumset inequalities in the literature (e.g. the Rusza triangle inequality, the Plünnecke-Rusza inequality, and the Balog-Szemeredi-Gowers theorem, though the entropy analogue of the latter requires a little bit of care to state). These inequalities can actually be deduced fairly easily from elementary arithmetic identities, together with standard entropy inequalities, most notably the submodularity inequality
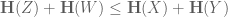
whenever X,Y,Z,W are discrete random variables such that X and Y each determine W separately (thus 


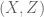

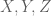
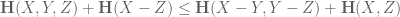
which soon leads to the entropy Rusza triangle inequality

which is an analogue of the combinatorial Ruzsa triangle inequality

All of this was already in the unpublished notes with Van, though I include it in this paper in order to place it in the literature. The main novelty of the paper, though, is to consider the entropy analogue of Freiman’s theorem, which classifies those sets A for which 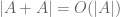

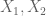
For instance, the uniform distribution U on a finite subgroup H of G has small doubling (in fact 
Theorem 1. (Informal statement) X has small doubling if and only if
for some uniform distribution U on a coset progression (of bounded rank), and Y has bounded entropy.
For instance, suppose that X was the uniform distribution on a dense subset A of a finite group G. Then Theorem 1 asserts that X is close in a “transport metric” sense to the uniform distribution U on G, in the sense that it is possible to rearrange or transport the probability distribution of X to the probability distribution of U (or vice versa) by shifting each component of the mass of X by an amount Y which has bounded entropy (which basically means that it primarily ranges inside a set of bounded cardinality). The way one shows this is by randomly translating the mass of X around by a few random shifts to approximately uniformise the distribution, and then deal with the residual fluctuation in the distribution by hand. Theorem 1 as a whole is established by using the Freiman theorem in the combinatorial setting combined with various elementary convexity and entropy inequality arguments to reduce matters to the above model case when X is supported inside a finite group G and has near-maximal entropy.
I also show a variant of the above statement: if X, Y are independent and 

In the last part of the paper I relate these discrete entropies to their continuous counterparts
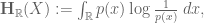
where X is now a continuous random variable on the real line with density function 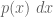
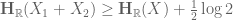
for independent copies

whenever 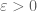
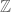

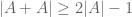
though notice that we have a gain of just 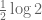
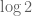

I also conjecture more generally that the entropy monotonicity inequalities established by Artstein, Barthe, Ball, and Naor in the continuous case also hold in the above sense in the discrete case, though my method of proof breaks down because I no longer can assume small doubling.
I’m continuing the stream of uploaded papers this week with my paper “Freiman’s theorem for solvable groups“, submitted to Contrib. Disc. Math.. This paper concerns the problem (discussed in this earlier blog post) of determining the correct analogue of Freiman’s theorem in a general non-abelian group 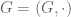
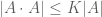
When G is the integers (with the additive group operation), Freiman’s theorem then tells us that A is controlled by a generalised arithmetic progression P, where I say that one set A is controlled by another P if they have comparable size, and the former can be covered by a finite number of translates of the latter. (One can view generalised arithmetic progressions as an approximate version of a subgroup, in which one only uses the generators of the progression for a finite amount of time before stopping, as opposed to groups which allow words of unbounded length in the generators.) For more general abelian groups, the Freiman theorem of Green and Ruzsa tells us that a set of bounded doubling is controlled by a generalised coset progression 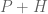
In this paper we address the case when G is a solvable group of bounded derived length. The main result is that if a subset of G has small doubing, then it is controlled by an object which I call a “coset nilprogression”, which is a certain technical generalisation of a coset progression, in which the generators do not quite commute, but have commutator expressible in terms of “higher order” generators. This is essentially a sharp characterisation of such sets, except for the fact that one would like a more explicit description of these coset nilprogressions. In the torsion-free case, a more explicit description (analogous to the Mal’cev basis description of nilpotent groups) has appeared in a very recent paper of Breulliard and Green; in the case of monomial groups (a class of groups that overlaps to a large extent with solvable groups), and assuming a polynomial growth condition rather than a doubling condition, a related result controlling A by balls in a suitable type of metric has appeared in very recent work of Sanders. In the nilpotent case there is also a nice recent argument of Fisher, Peng, and Katz which shows that sets of small doubling remain of small doubling with respect to the Lie algebra operations of addition and Lie bracket, and thus are amenable to the abelian Freiman theorems.
The conclusion of my paper is easiest to state (and easiest to prove) in the model case of the lamplighter group 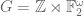

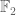
Theorem 1. (Freiman’s theorem for the lamplighter group) If
has bounded doubling, then A is controlled either by a finite subspace of the “vertical” group
, or else by a set of the form
, where
is a generalised arithmetic progression, and
obeys the Freiman isomorphism property
whenever
and
.
This result, incidentally, recovers an earlier result of Lindenstrauss that the lamplighter group does not contain a Følner sequence of sets of uniformly bounded doubling. It is a good exercise to establish the “exact” version of this theorem, in which one classifies subgroups of the lamplighter group rather than sets of small doubling; indeed, the proof of this the above theorem follows fairly closely the natural proof of the exact version.
One application of the solvable Freiman theorem is the following quantitative version of a classical result of Milnor and of Wolf, which asserts that any solvable group of polynomial growth is virtually nilpotent:
Theorem 2. (Quantitative Milnor-Wolf theorem) Let G be a solvable group of derived length O(1), let S be a set of generators for G, and suppose one has the polynomial growth condition
for some d = O(1), where
is the set of all words generated by S of length at most R. If R is sufficiently large, then this implies that G is virtually nilpotent; more precisely, G contains a nilpotent subgroup of step O(1) and index
.
The key points here are that one only needs polynomial growth at a single scale R, rather than on many scales, and that the index of the nilpotent subgroup has polynomial size.
The proofs are based on an induction on the derived length. After some standard manipulations (basically, splitting A by an approximate version of a short exact sequence), the problem boils down to that of understanding the action 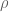
In the course of the proof we need two new additive combinatorial results which may be of independent interest. The first is a variant of a well-known theorem of Sárközy, which asserts that if A is a large subset of an arithmetic progression P, then an iterated sumset kA of A for some 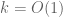
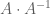
For a number of reasons, including the start of the summer break for me and my coauthors, a number of papers that we have been working on are being released this week. For instance, Ben Green and I have just uploaded to the arXiv our paper “An equivalence between inverse sumset theorems and inverse conjectures for the 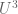
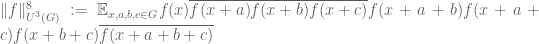
on finite additive group G, where 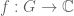
As usual, the connection is easiest to state in a finite field model such as 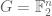
Theorem 1. If
is such that
, then A can be covered by a translate of a subspace of
of cardinality at most
.
The constant 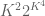

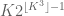
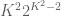

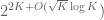
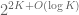
Conjecture 1. (Polynomial Freiman-Ruzsa conjecture for
translates of subspaces of
This conjecture was verified for downsets by Green and myself, but is open in general. This conjecture has a number of equivalent formulations; see this paper of Green for more discussion. In this previous post we show that a stronger version of this conjecture fails.
Meanwhile, for the Gowers norm, we have the following inverse theorem, due to Samorodnitsky:
Theorem 2. Let
be a function whose
such that
.
Note that the quadratic phases 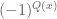
It is conjectured that the exponentially weak correlation here can be strengthened to a polynomial one:
Conjecture 2. (Polynomial inverse conjecture for the
norm). Let
.
The first main result of this paper is
Theorem 3. Conjecture 1 and Conjecture 2 are equivalent.
This result was also independently observed by Shachar Lovett (private communication). We also establish an analogous result for the cyclic group 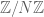
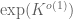
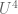
Below the fold, we sketch the proof of Theorem 3.
I’ve just uploaded to the arXiv my paper “Global regularity for a logarithmically supercritical hyperdissipative Navier-Stokes equation“, submitted to Analysis & PDE. It is a famous problem to establish the existence of global smooth solutions to the three-dimensional Navier-Stokes system of equations
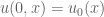
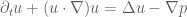

given smooth, compactly supported, divergence-free initial data 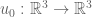
I do not claim to have any substantial progress on this problem here. Instead, the paper makes a small observation about the hyper-dissipative version of the Navier-Stokes equations, namely
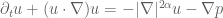
for some 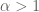


Values of 
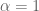
A few years ago, I observed (in the case of the spherically symmetric wave equation) that this “criticality barrier” had a very small amount of flexibility to it, in that one could push a critical argument to a slightly supercritical one by exploiting spacetime integral estimates a little bit more. I realised recently that the same principle applied to hyperdissipative Navier-Stokes; here, the relevant spacetime integral estimate is the energy dissipation inequality

which ensures that the energy dissipation 
In this paper I push the global regularity results by a fraction of a logarithm from 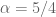

admits global smooth solutions.
The argument is in fact quite simple (the paper is seven pages in length), and relies on known technology; one just applies the energy method and a logarithmically modified Sobolev inequality in the spirit of a well-known inequality of Brezis and Wainger. It looks like it will take quite a bit of effort though to improve the logarithmic factor much further.
One way to explain the tiny bit of wiggle room beyond the critical case is as follows. The standard energy method approach to the critical Navier-Stokes equation relies at one stage on Gronwall’s inequality, which among other things asserts that if a time-dependent non-negative quantity E(t) obeys the differential inequality
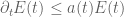
and 
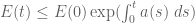
A slight modification of the argument shows that one can replace the linear inequality with a slightly superlinear inequality. For instance, the differential inequality
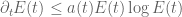
also does not blow up in time; indeed, a separation of variables argument gives the explicit double-exponential bound
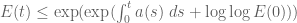
(let’s take 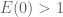


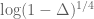
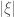
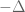
To put it another way, with a linear exponential growth model, such as 

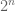
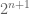
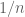

Interestingly, there is a heuristic argument that suggests that the half-logarithmic loss in (0) can be widened to a full logarithmic loss, which I give below the fold.
I’ve just uploaded to the arXiv my paper “Global regularity of wave maps VI. Abstract theory of minimal-energy blowup solutions“, to be submitted with the rest of the “heatwave” project to establish global regularity (and scattering) for energy-critical wave maps into hyperbolic space. Initially, this paper was intended to cap off the project by showing that if global regularity failed, then a special minimal energy blowup solution must exist, which enjoys a certain almost periodicity property modulo the symmetries of the equation. However, the argument was more technical than I anticipated, and so I am splitting the paper into a relatively short high-level paper (this one) that reduces the problem to four smaller propositions, and a much longer technical paper which establishes those propositions, by developing a substantial amount of perturbation theory for wave maps. I am pretty sure though that this process will not iterate any further, and paper VII will be my final paper in this series (and which I hope to finish by the end of this summer). It is also worth noting that a number of papers establishing similar results (though with slightly different hypotheses and conclusions) will shortly appear by Sterbenz-Tataru and Krieger-Schlag.
Almost periodic minimal energy blowup solutions have been constructed for a variety of critical equations, such as the nonlinear Schrodinger equation (NLS) and the nonlinear wave equation (NLW). The formal definition of almost periodicity is that the orbit of the solution 

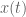



Intuitively, the reason almost periodic minimal energy blowup solutions ought to exist in the absence of global regularity is as follows. It is known (for any of the equations mentioned above) that global regularity (and scattering) holds at sufficiently small energies. Thus, if global regularity fails at high energies, there must exist a critical energy 
Now consider a solution 

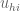


As mentioned before, this type of scheme has been successfully implemented on a number of equations such as NLS and NLW. However, there are two main obstacles in establishing it for wave maps. The first is that the wave maps equation is not a scalar equation: the unknown field takes values in a target manifold (specifically, in a hyperbolic space) rather than in a Euclidean space. As a consequence, it is not obvious how one would perform operations such as “decompose the solution into low frequency and high frequency components”, or the inverse operation “superimpose the low frequency and high frequency components to reconstitute the solution”. Another way of viewing the problem is that the various component fields of the solution have to obey a number of important compatibility conditions which can be disrupted by an overly simple-minded approach to decomposition or reconstitution of solutions.
The second problem is that the interaction between very high and very low frequencies for wave maps turns out to not be entirely negligible: the high frequencies do have a negligible impact on the evolution of the low frequencies, but the low frequencies can “rotate” the high frequencies by acting as a sort of magnetic field (or more precisely, a connection) for the evolution of those high frequencies. So the combined evolution of the high and low frequencies is not well approximated by a naive superposition of the separate evolutions of these frequency components.
This is a continuation of the previous thread here in the polymath1 project, which is now full. Ostensibly, the purpose of this thread is to continue writing up the paper containing many of the things achieved during this side of the project, though we have also been spending time on chasing down more results, in particular using new computer data to narrow down the range of the maximal size of 6D Moser sets (currently we can pin this down to between 353 and 355). At some point we have to decide what results to put in in full detail in the paper, what results to summarise only (with links to the wiki), and what results to defer to perhaps a subsequent paper, but these decisions can be taken at a leisurely pace.
I guess we’ve abandoned the numbering system now, but I suppose that if necessary we can use timestamps or URLs to link to previous comments.
The celebrated Szemerédi-Trotter theorem gives a bound for the set of incidences 




where we use the asymptotic notation 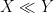

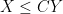



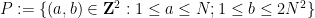


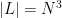
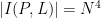
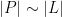
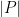

On the other hand, if one replaces the Euclidean plane 



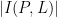
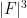

Nowadays, the slickest proof of the Szemerédi-Trotter theorem is via the crossing number inequality (as discussed in this previous post), which ultimately relies on Euler’s famous formula 
Roughly speaking, the idea is this. Using nothing more than the axiom that two points determine at most one line, one can obtain the bound
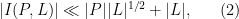
which is inferior to (1). (On the other hand, this estimate works in both Euclidean and finite field geometries, and is sharp in the latter case, as shown by the example given earlier.) Dually, the axiom that two lines determine at most one point gives the bound
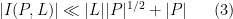
(or alternatively, one can use projective duality to interchange points and lines and deduce (3) from (2)).
An inspection of the proof of (2) shows that it is only expected to be sharp when the bushes 
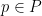
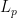

However, in Euclidean space, we have the phenomenon that the bush of a point 



More formally, the argument proceeds by applying the following lemma:
Lemma 1 (Cell decomposition) Let
. Then it is possible to find a set
of
lines in
convex regions (or cells), such that the interior of each such cell is incident to at most
lines.
The deduction of (1) from (2), (3) and Lemma 1 is very quick. Firstly we may assume we are in the range

otherwise the bound (1) follows already from either (2) or (3) and some high-school algebra.
Let 


We optimise this by selecting 



We can iterate away the 
It remains to prove (1). If one subdivides 
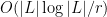
It is also worth noting that the original (somewhat complicated) argument of Szemerédi-Trotter has been adapted to establish the analogue of (1) in the complex plane 
In the theory of discrete random matrices (e.g. matrices whose entries are random signs 
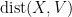
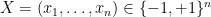

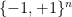



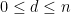
It is not hard to compute the second moment of this random variable. Indeed, if 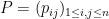
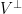

and so upon taking expectations we see that

since 
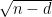
In fact, one has sharp concentration around this value, in the sense that 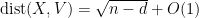
Proposition 1 (Large deviation inequality) For any
, one has
for some absolute constants
.
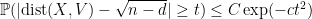
In fact the constants 

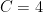
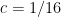
Proposition 1 is an easy consequence of the second moment computation and Talagrand’s inequality, which among other things provides a sharp concentration result for convex Lipschitz functions on the cube 

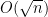
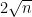


Remark 1 If one makes the coordinates of
rather than random signs, then Proposition 1 is much easier to prove; the probability distribution of a Gaussian vector is rotation-invariant, so one can rotate
, at which point
is clearly the sum of

Recent Comments