
You are currently browsing the monthly archive for August 2007.
For the past several years, my good friend and fellow Medalist Timothy Gowers has been devoting an enormous amount of effort towards editing (with the help of June Barrow-Green and Imre Leader) a forthcoming book, the Princeton Companion to Mathematics. This immense project is somewhat difficult to explain succinctly; a zeroth order approximation would be that it is an “Encyclopedia of mathematics”, but the aim is not to be a comprehensive technical reference, nor is it a repository of key mathematical definitions and theorems; it is neither Scholarpedia nor Wikipedia. Instead, the idea is to give a flavour of a subject or mathematical concept by means of motivating examples, questions, and so forth, somewhat analogous to the “What is a …?” series in the Notices of the AMS. Ideally, any interested reader with a basic mathematics undergraduate education could use this book to get a rough handle on what (say) Ricci flow is and why it is useful, or what questions mathematicians are trying to answer about (say) harmonic analysis, without getting into the technical details (which are abundantly available elsewhere). There are contributions from many, many mathematicians on a wide range of topics, from symplectic geometry to modular forms to the history and influence of mathematics; I myself have contributed or been otherwise involved in about a dozen articles.
If all goes well, the Companion should be finalised later this year and available around March 2008. As a sort of “advertising campaign” for this project (and with Tim’s approval), I plan to gradually release to this blog (at the rate of one or two a month) the various articles I contributed for the project over the last few years. [As part of this advertising, I might add that the Companion can already be pre-ordered on Amazon.]
I’ll inaugurate this series with my article on “wave maps”. This describes, in general terms, what a wave map is (it is a mathematical model for a vibrating membrane in a manifold), and its relationship with other concepts such as harmonic maps and general relativity. As it turns out, for editing reasons various articles solicited for the Companion had to be removed from the print edition (but possibly may survive in the on-line version of the Companion, though details are unclear at this point); Tim and I agreed that as wave maps were not the most crucial geometric PDE that needed to be covered for the Companion (there are other articles on the Einstein equations and Ricci flow, for instance), that this particular article would end up being one of the “deleted scenes”. As such, it seems like a logical choice for the first article to release here.
I recently discovered a CSS hack which automatically makes wordpress pages friendlier to print (stripping out the sidebar, header, footer, and comments), and installed it on this blog (in response to an emailed suggestion). There should be no visible changes unless one “print previews” the page.
In order to prevent this post from being totally devoid of mathematical content, I’ll mention that I recently came across the phenomenon of nonfirstorderisability in mathematical logic: there are perfectly meaningful and useful statements in mathematics which cannot be phrased within the confines of first order logic (combined with the language of set theory, or any other standard mathematical theory); one must use a more powerful language such as second order logic instead. This phenomenon is very well known among logicians, but I hadn’t learned about it until very recently, and had naively assumed that first order logic sufficed for “everyday” usage of mathematics.
Van Vu and I have recently uploaded our joint paper, “Random matrices: the circular law“, submitted to Contributions to Discrete Mathematics. In this paper we come close to fully resolving the circular law conjecture regarding the eigenvalue distribution of random matrices, for arbitrary choices of coefficient distribution.
More precisely, suppose we have an 

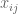


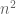



Numerical evidence (as seen for instance here) soon reveals that these n eigenvalues appear to distribute themselves uniformly in the unit circle 
![\mu_n: {\Bbb R}^2 \to [0,1]](https://s0.wp.com/latex.php?latex=%5Cmu_n%3A+%7B%5CBbb+R%7D%5E2+%5Cto+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

then with probability 1, 

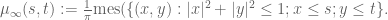
This statement is known as the circular law conjecture. In the case when x is a complex Gaussian, this law was verified by Mehta (using an explicit formula of Ginibre for the joint density function of the eigenvalues in this case). A strategy for attacking the general case was then formulated by Girko, although a fully rigorous execution of that strategy was first achieved by Bai (and then improved slightly by Bai and Silverstein). They established the circular law under the assumption that x had slightly better than bounded second moment (i.e. 
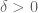
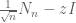
In the last few years, work of Rudelson, of myself with Van Vu, and of Rudelson-Vershynin (building upon earlier work of Kahn, Komlos, and Szemerédi, and of Van and myself), have opened the way to control the condition number of random matrices even when the matrices are discrete, and so there have been a recent string of results using these techniques to extend the circular law to discrete settings. In particular, Gotze and Tikhomirov established the circular law for discrete random variables which were sub-Gaussian, which was then relaxed by Pan and Zhou to an assumption of bounded fourth moment. In our paper, we get very close to the ideal assumption of bounded second moment; we need 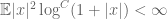

The main new difficulty that arises when relaxing the moment condition so close to the optimal one is that one begins to lose control on the largest singular value of 
As you may already know, Danica McKellar, the actress and UCLA mathematics alumnus, has recently launched her book “Math Doesn’t Suck“, which is aimed at pre-teenage girls and is a friendly introduction to middle-school mathematics, such as the arithmetic of fractions. The book has received quite a bit of publicity, most of it rather favourable, and is selling quite well; at one point, it even made the Amazon top 20 bestseller list, which is a remarkable achievement for a mathematics book. (The current Amazon rank can be viewed in the product details of the Amazon page for this book.)
I’m very happy that the book is successful for a number of reasons. Firstly, I got to know Danica for a few months (she took my Introduction to Topology class way back in 1997, and in fact was the second-best student there; the class web page has long since disappeared, but you can at least see the midterm and final), and it is always very heartening to see a former student put her or his mathematical knowledge to good use :-) . Secondly, Danica is a wonderful role model and it seems that this book will encourage many school-age kids to give maths a chance. But the final reason is that the book is, in fact, rather good; the mathematical content is organised in a logical manner (for instance, it begins with prime factorisation, then covers least common multiples, then addition of fractions), well motivated, and interleaved with some entertaining, insightful, and slightly goofy digressions, anecdotes, and analogies. (To give one example: to motivate why dividing 6 by 1/2 should yield 12, she first discussed why 6 divided by 2 should give 3, by telling a story about having to serve lattes to a whole bunch of actors, where each actor demands two lattes each, but one could only carry the weight of six lattes at a time, so that only 

While I am not exactly in the target audience for this book, I can relate to its pedagogical approach. When I was a kid myself, one of my favourite maths books was a very obscure (and now completely out of print) book called “Creating Calculus“, which introduced the basics of single-variable calculus via concocting a number of slightly silly and rather contrived stories which always involved one or more ants. For instance, to illustrate the concept of a derivative, in one of these stories one of the ants kept walking up a mathematician’s shin while he was relaxing against a tree, but started slipping down at a point where the slope of the shin reached a certain threshold; this got the mathematician interested enough to compute that slope from first principles. The humour in the book was rather corny, involving for instance some truly awful puns, but it was perfect for me when I was 11: it inspired me to play with calculus, which is an important step towards improving one’s understanding of the subject beyond a superficial level. (Two other books in a similarly playful spirit, yet still full of genuine scientific substance, are “Darwin for beginners” and “Mr. Tompkins in paperback“, both of which I also enjoyed very much as a kid. They are of course no substitute for a serious textbook on these subjects, but they complement such treatments excellently.)
Anyway, Danica’s book has already been reviewed in several places, and there’s not much more I can add to what has been said elsewhere. I thought however that I could talk about another of Danica’s contributions to mathematics, namely her paper “Percolation and Gibbs states multiplicity for ferromagnetic Ashkin-Teller models on 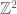
[Update, Aug 23: I added a non-technical “executive summary” of what the Chayes-McKellar-Winn theorem is at the very end of this post.]
[This post is authored by Gil Kalai, who has kindly “guest blogged” this week’s “open problem of the week”. – T.]
The entropy-influence conjecture seeks to relate two somewhat different measures as to how a boolean function has concentrated Fourier coefficients, namely the total influence and the entropy.
We begin by defining the total influence. Let 
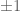
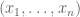
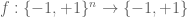

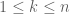
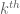

We give the cube 


where 

Thus for instance a dictator function has total influence 1, whereas majority vote has total influence comparable to 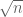
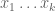







Atle Selberg, who made immense and fundamental contributions to analytic number theory and related areas of mathematics, died last Monday, aged 90.
Selberg’s early work was focused on the study of the Riemann zeta function 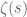
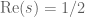
In working on the zeta function, Selberg developed two powerful tools which are still used routinely in analytic number theory today. The first is the method of mollifiers to smooth out the magnitude oscillations of the zeta function, making the (more interesting) phase oscillation more visible. The second was the method of the Selberg 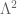
For all of these achievements, Selberg was awarded the Fields Medal in 1950. Around that time, Selberg and Erdős also produced the first elementary proof of the prime number theorem. A key ingredient here was the Selberg symmetry formula, which is an elementary analogue of the prime number theorem for almost primes.
But perhaps Selberg’s greatest contribution to mathematics was his discovery of the Selberg trace formula, which is a non-abelian generalisation of the Poisson summation formula, and which led to many further deep connections between representation theory and number theory, and in particular being one of the main inspirations for the Langlands program, which in turn has had an impact on many different parts of mathematics (for instance, it plays a role in Wiles’ proof of Fermat’s last theorem). For an introduction to the trace formula, its history, and its impact, I recommend the survey article of Arthur.
Other major contributions of Selberg include the Rankin-Selberg theory connecting Artin L-functions from representation theory to the integrals of automorphic forms (very much in the spirit of the Langlands program), and the Chowla-Selberg formula relating the Gamma function at rational values to the periods of elliptic curves with complex multiplication. He also made an influential conjecture on the spectral gap of the Laplacian on quotients of 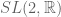
[This post is authored by Alexandre Borovik. An extended version of this post, with further links and background information, can be found on Alexandre’s blog.]
I had never in my life seen an arrested blackboard encircled by a police tape, still with some group theory problems on it.

But this had actually happened when the Turkish authorities closed
down the Mathematical Summer School run by Ali Nesin for Turkish undergraduate students; Ali Nesin may face prosecution for an Orwellian offence of “education without permission“. Please sign the online petition in his support.
Read the rest of this entry »
[This post is authored by Emmanuel Kowalski.]
This post may be seen as complementary to the post “The parity problem in sieve theory“. In addition to a survey of another important sieve technique, it might be interesting as a discussion of some of the foundational issues which were discussed in the comments to that post.
Many readers will certainly have heard already of one form or another of the “large sieve inequality”. The name itself is misleading however, and what is meant by this may be something having very little, if anything, to do with sieves. What I will discuss are genuine sieve situations.
The framework I will describe is explained in the preprint arXiv:math.NT/0610021, and in a forthcoming Cambridge Tract. I started looking at this first to have a common setting for the usual large sieve and a “sieve for Frobenius” I had devised earlier to study some arithmetic properties of families of zeta functions over finite fields. Another version of such a sieve was described by Zywina (“The large sieve and Galois representations”, preprint), and his approach was quite helpful in suggesting more general settings than I had considered at first. The latest generalizations more or less took life naturally when looking at new applications, such as discrete groups.
Unfortunately (maybe), there will be quite a bit of notation involved; hopefully, the illustrations related to the classical case of sieving integers to obtain the primes (or other subsets of integers with special multiplicative features) will clarify the general case, and the “new” examples will motivate readers to find yet more interesting applications of sieves.
Almost a year ago today, I was in Madrid attending the 2006 International Congress of Mathematicians (ICM). One of the many highlights of an ICM meeting are the plenary talks, which offer an excellent opportunity to hear about current developments in mathematics from leaders in various fields, aimed at a general mathematical audience. All the speakers sweat quite a lot over preparing these high-profile talks; for instance, I rewrote the slides for my own talk from scratch after the first version produced bemused reactions from those friends I had shown them to.
I didn’t write about these talks at the time, since my blog had not started then (and also, things were rather hectic for me in Madrid). During the congress, these talks were webcast live, but the video for these talks no longer seems to be available on-line.
A couple weeks ago, though, I received the first volume of the ICM proceedings, which is the one which among other things contains the articles contributed by the plenary speakers (the other two volumes were available at the congress itself). On reading through this volume, I discovered a pleasant surprise – the publishers had included a CD-ROM on the back page which had all the video and slides of the plenary talks, as well as the opening and closing ceremonies! This was a very nice bonus and I hope that the proceedings of future congresses also include something like this.
Of course, I won’t be able to put the data on that CD-ROM on-line, for both technical and legal reasons; but I thought I would discuss a particularly beautiful plenary lecture given by Étienne Ghys on “Knots and dynamics“. His talk was not only very clear and fascinating, but he also made a superb use of the computer, in particular using well-timed videos and images (developed in collaboration with Jos Leys) to illustrate key ideas and concepts very effectively. (The video on the CD-ROM unfortunately does not fully capture this, as it only has stills from his computer presentation rather than animations.) To give you some idea of how good the talk was, Étienne ended up running over time by about fifteen minutes or so; and yet, in an audience of over a thousand, only a handful of people actually left before the end.
The slides for Étienne’s talk can be found here, although, being in PDF format, they only have stills rather than full animations. Some of the animations though can be found on this page. (Étienne’s article for the proceedings can be found here, though like the contributions of most other plenary speakers, the print article is more detailed and technical than the talk.) I of course cannot replicate Étienne’s remarkable lecture style, but I can at least present the beautiful mathematics he discussed.
Read the rest of this entry »

{kind=link}
Recent Comments