
You are currently browsing the monthly archive for July 2020.
Kaisa Matomäki, Maksym Radziwill, Joni Teräväinen, Tamar Ziegler and I have uploaded to the arXiv our paper Higher uniformity of bounded multiplicative functions in short intervals on average. This paper (which originated from a working group at an AIM workshop on Sarnak’s conjecture) focuses on the local Fourier uniformity conjecture for bounded multiplicative functions such as the Liouville function 
![\displaystyle \int_0^X \| \lambda \|_{U^k([x,x+H])}\ dx = o(X) \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cint_0%5EX+%5C%7C+%5Clambda+%5C%7C_%7BU%5Ek%28%5Bx%2Cx%2BH%5D%29%7D%5C+dx+%3D+o%28X%29+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
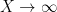 for any fixed
for any fixed  and any
and any 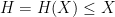 that goes to infinity as , where
that goes to infinity as , where ![{U^k([x,x+H])}](https://s0.wp.com/latex.php?latex=%7BU%5Ek%28%5Bx%2Cx%2BH%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) is the (normalized) Gowers uniformity norm. Among other things this conjecture implies (logarithmically averaged version of) the Chowla and Sarnak conjectures for the Liouville function (or the Möbius function), see this previous blog post.
is the (normalized) Gowers uniformity norm. Among other things this conjecture implies (logarithmically averaged version of) the Chowla and Sarnak conjectures for the Liouville function (or the Möbius function), see this previous blog post.
The conjecture gets more difficult as 



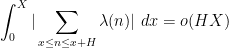 ) in a landmark paper of Matomäki and Radziwill, discussed for instance in this blog post.
) in a landmark paper of Matomäki and Radziwill, discussed for instance in this blog post.
For 
 (and it would be a major breakthrough in particular if one could obtain this bound for as small as
(and it would be a major breakthrough in particular if one could obtain this bound for as small as  for any fixed
for any fixed  , particularly if applicable to more general bounded multiplicative functions than , as this would have new implications for a generalization of the Chowla conjecture known as the Elliott conjecture). Recently, Kaisa, Maks and myself were able to establish this conjecture in the range
, particularly if applicable to more general bounded multiplicative functions than , as this would have new implications for a generalization of the Chowla conjecture known as the Elliott conjecture). Recently, Kaisa, Maks and myself were able to establish this conjecture in the range  (in fact we have since worked out in the current paper that we can get as small as
(in fact we have since worked out in the current paper that we can get as small as  ). In our current paper we establish Fourier uniformity conjecture for higher for the same range of . This in particular implies local orthogonality to polynomial phases,
). In our current paper we establish Fourier uniformity conjecture for higher for the same range of . This in particular implies local orthogonality to polynomial phases, 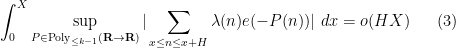
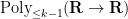 denotes the polynomials of degree at most
denotes the polynomials of degree at most 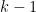 , but the full conjecture is a bit stronger than this, establishing the more general statement
, but the full conjecture is a bit stronger than this, establishing the more general statement 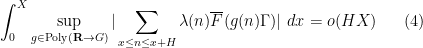 filtered nilmanifold
filtered nilmanifold 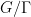 and Lipschitz function
and Lipschitz function  , where
, where  now ranges over polynomial maps from
now ranges over polynomial maps from  to
to  . The method of proof follows the same general strategy as in the previous paper with Kaisa and Maks. (The equivalence of (4) and (1) follows from the inverse conjecture for the Gowers norms, proven in this paper.) We quickly sketch first the proof of (3), using very informal language to avoid many technicalities regarding the precise quantitative form of various estimates. If the estimate (3) fails, then we have the correlation estimate
. The method of proof follows the same general strategy as in the previous paper with Kaisa and Maks. (The equivalence of (4) and (1) follows from the inverse conjecture for the Gowers norms, proven in this paper.) We quickly sketch first the proof of (3), using very informal language to avoid many technicalities regarding the precise quantitative form of various estimates. If the estimate (3) fails, then we have the correlation estimate 
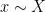 and some polynomial
and some polynomial 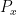 depending on
depending on  . The difficulty here is to understand how can depend on . We write the above correlation estimate more suggestively as
. The difficulty here is to understand how can depend on . We write the above correlation estimate more suggestively as ![\displaystyle \lambda(n) \sim_{[x,x+H]} e(P_x(n)).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clambda%28n%29+%5Csim_%7B%5Bx%2Cx%2BH%5D%7D+e%28P_x%28n%29%29.&bg=ffffff&fg=000000&s=0&c=20201002)
 at small primes
at small primes  , one expects to have a relation of the form
, one expects to have a relation of the form ![\displaystyle e(P_{x'}(p'n)) \sim_{[x/p,x/p+H/p]} e(P_x(pn)) \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e%28P_%7Bx%27%7D%28p%27n%29%29+%5Csim_%7B%5Bx%2Fp%2Cx%2Fp%2BH%2Fp%5D%7D+e%28P_x%28pn%29%29+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
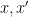 for which
for which 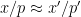 for some small primes
for some small primes 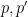 . (This can be formalised using an inequality of Elliott related to the Turan-Kubilius theorem.) This gives a relationship between and
. (This can be formalised using an inequality of Elliott related to the Turan-Kubilius theorem.) This gives a relationship between and  for “edges” in a rather sparse “graph” connecting the elements of say
for “edges” in a rather sparse “graph” connecting the elements of say ![{[X/2,X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2F2%2CX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Using some graph theory one can locate some non-trivial “cycles” in this graph that eventually lead (in conjunction to a certain technical but important “Chinese remainder theorem” step to modify the to eliminate a rather serious “aliasing” issue that was already discussed in this previous post) to obtain functional equations of the form
. Using some graph theory one can locate some non-trivial “cycles” in this graph that eventually lead (in conjunction to a certain technical but important “Chinese remainder theorem” step to modify the to eliminate a rather serious “aliasing” issue that was already discussed in this previous post) to obtain functional equations of the form 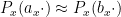
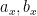 , where
, where 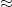 should be viewed as a first approximation (ignoring a certain “profinite” or “major arc” term for simplicity) as “differing by a slowly varying polynomial” and the polynomials should now be viewed as taking values on the reals rather than the integers. This functional equation can be solved to obtain a relation of the form
should be viewed as a first approximation (ignoring a certain “profinite” or “major arc” term for simplicity) as “differing by a slowly varying polynomial” and the polynomials should now be viewed as taking values on the reals rather than the integers. This functional equation can be solved to obtain a relation of the form 
 of polynomial size, and with further analysis of the relation (5) one can make basically independent of . This simplifies (3) to something like
of polynomial size, and with further analysis of the relation (5) one can make basically independent of . This simplifies (3) to something like 
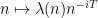 is a bounded multiplicative function). (Actually because of the profinite term mentioned previously, one also has to insert a Dirichlet character of bounded conductor into this latter conclusion, but we will ignore this technicality.)
is a bounded multiplicative function). (Actually because of the profinite term mentioned previously, one also has to insert a Dirichlet character of bounded conductor into this latter conclusion, but we will ignore this technicality.)
Now we apply the same strategy to (4). For abelian 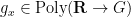
 is rather technical and will not be detailed here. A new difficulty arises in that there are some unwanted solutions to this equation, such as
is rather technical and will not be detailed here. A new difficulty arises in that there are some unwanted solutions to this equation, such as 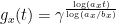
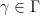 , which do not necessarily lead to multiplicative characters like
, which do not necessarily lead to multiplicative characters like 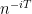 as in the polynomial case, but instead to some unfriendly looking “generalized multiplicative characters” (think of
as in the polynomial case, but instead to some unfriendly looking “generalized multiplicative characters” (think of  as a rough caricature). To avoid this problem, we rework the graph theory portion of the argument to produce not just one functional equation of the form (6)for each , but many, leading to dilation invariances
as a rough caricature). To avoid this problem, we rework the graph theory portion of the argument to produce not just one functional equation of the form (6)for each , but many, leading to dilation invariances 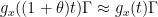
 . From a certain amount of Lie algebra theory (ultimately arising from an understanding of the behaviour of the exponential map on nilpotent matrices, and exploiting the hypothesis that is non-abelian) one can conclude that (after some initial preparations to avoid degenerate cases)
. From a certain amount of Lie algebra theory (ultimately arising from an understanding of the behaviour of the exponential map on nilpotent matrices, and exploiting the hypothesis that is non-abelian) one can conclude that (after some initial preparations to avoid degenerate cases)  must behave like
must behave like  for some central element
for some central element 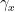 of . This eventually brings one back to the multiplicative characters that arose in the polynomial case, and the arguments now proceed as before.
of . This eventually brings one back to the multiplicative characters that arose in the polynomial case, and the arguments now proceed as before.
We give two applications of this higher order Fourier uniformity. One regards the growth of the number
 sign patterns in the Liouville function. The Chowla conjecture implies that
sign patterns in the Liouville function. The Chowla conjecture implies that  , but even the weaker conjecture of Sarnak that
, but even the weaker conjecture of Sarnak that  for some remains open. Until recently, the best asymptotic lower bound on
for some remains open. Until recently, the best asymptotic lower bound on 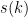 was
was  , due to McNamara; with our result, we can now show
, due to McNamara; with our result, we can now show  for any
for any  (in fact we can get
(in fact we can get 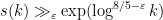 for any ). The idea is to repeat the now-standard argument to exploit multiplicativity at small primes to deduce Chowla-type conjectures from Fourier uniformity conjectures, noting that the Chowla conjecture would give all the sign patterns one could hope for. The usual argument here uses the “entropy decrement argument” to eliminate a certain error term (involving the large but mean zero factor
for any ). The idea is to repeat the now-standard argument to exploit multiplicativity at small primes to deduce Chowla-type conjectures from Fourier uniformity conjectures, noting that the Chowla conjecture would give all the sign patterns one could hope for. The usual argument here uses the “entropy decrement argument” to eliminate a certain error term (involving the large but mean zero factor  ). However the observation is that if there are extremely few sign patterns of length , then the entropy decrement argument is unnecessary (there isn’t much entropy to begin with), and a more low-tech moment method argument (similar to the derivation of Chowla’s conjecture from Sarnak’s conjecture, as discussed for instance in this post) gives enough of Chowla’s conjecture to produce plenty of length sign patterns. If there are not extremely few sign patterns of length then we are done anyway. One quirk of this argument is that the sign patterns it produces may only appear exactly once; in contrast with preceding arguments, we were not able to produce a large number of sign patterns that each occur infinitely often.
). However the observation is that if there are extremely few sign patterns of length , then the entropy decrement argument is unnecessary (there isn’t much entropy to begin with), and a more low-tech moment method argument (similar to the derivation of Chowla’s conjecture from Sarnak’s conjecture, as discussed for instance in this post) gives enough of Chowla’s conjecture to produce plenty of length sign patterns. If there are not extremely few sign patterns of length then we are done anyway. One quirk of this argument is that the sign patterns it produces may only appear exactly once; in contrast with preceding arguments, we were not able to produce a large number of sign patterns that each occur infinitely often.
The second application is to obtain cancellation for various polynomial averages involving the Liouville function 
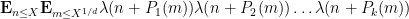
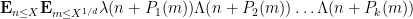
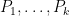 are polynomials of degree at most
are polynomials of degree at most  , no two of which differ by a constant (the latter is essential to avoid having to establish the Chowla or Hardy-Littlewood conjectures, which of course remain open). Results of this type were previously obtained by Tamar Ziegler and myself in the “true complexity zero” case when the polynomials
, no two of which differ by a constant (the latter is essential to avoid having to establish the Chowla or Hardy-Littlewood conjectures, which of course remain open). Results of this type were previously obtained by Tamar Ziegler and myself in the “true complexity zero” case when the polynomials  had distinct degrees, in which one could use the theory of Matomäki and Radziwill; now that higher is available at the scale
had distinct degrees, in which one could use the theory of Matomäki and Radziwill; now that higher is available at the scale 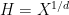 we can now remove this restriction.
we can now remove this restriction.
A family 
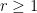
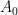
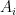
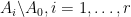

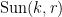

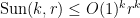

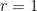
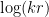
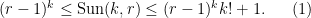

Rao’s argument used the Shannon noiseless coding theorem. It turns out that the argument can be arranged in the very slightly different language of Shannon entropy, and I would like to present it here. The argument proceeds by locating the core and petals of the sunflower separately (this strategy is also followed in Alweiss-Lovett-Wu-Zhang). In both cases the following definition will be key. In this post all random variables, such as random sets, will be understood to be discrete random variables taking values in a finite range. We always use boldface symbols to denote random variables, and non-boldface for deterministic quantities.
Definition 1 (Spread set) Let. A random set
is said to be
-spread if one has
for all sets
. A family
of sets is said to be
is non-empty and the random variable
is
is drawn uniformly from

The core can then be selected greedily in such a way that the remainder of a family becomes spread:
Lemma 2 (Locating the core) Letof cardinality at most
has cardinality at least
, and such that the family
is
and the
.
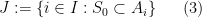
Proof: We may assume 
 be a subset of that maximizes
be a subset of that maximizes  . Since
. Since  and
and  when
when 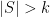 , we see that
, we see that 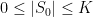 . If the are distinct and , then we also have
. If the are distinct and , then we also have 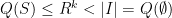 when
when 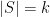 , thus in this case we have .
, thus in this case we have .
Let 


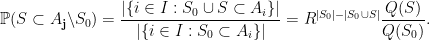
 , and the probability is only non-empty when
, and the probability is only non-empty when 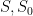 are disjoint, so that
are disjoint, so that  . The claim follows.
. The claim follows. 
In view of the above lemma, the bound (2) will then follow from
Proposition 3 (Locating the petals) Letbe natural numbers, and suppose that
for a sufficiently large constant
. Let
such that
is disjoint.
Indeed, to prove (2), we assume that 






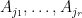
Remark 4 Proposition 3 is easy to prove if we strengthen the condition on. In this case, we have
for every
, hence by the union bound we see that for any
with
there exists
such that
is disjoint from the set
, which has cardinality at most
. Iterating this, we obtain the conclusion of Proposition 3 in this case. This recovers a bound of the form
, and by pursuing this idea a little further one can recover the original upper bound (1) of Erdös and Rado.
It remains to prove Proposition 3. In fact we can locate the petals one at a time, placing each petal inside a random set.
Proposition 5 (Locating a single petal) Let the notation and hypotheses be as in Proposition 3. Letbe a random subset of
. Then with probability greater than
,
To see that Proposition 5 implies Proposition 3, we randomly partition 

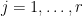
We will prove Proposition 5 by gradually increasing the density of the random set and arranging the sets
Proposition 6 (Refinement inequality) Let. Let
. Then there exists another
of
and

Note that a direct application of the first moment method gives only the bound
 to an equivalent we can replace the
to an equivalent we can replace the  factor by a quantity significantly smaller than
factor by a quantity significantly smaller than  .
.
One can iterate the above proposition, repeatedly replacing 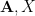
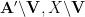
Corollary 7 (Iterated refinement inequality) Let. Let
. Then there exists another random subset

Now we can prove Proposition 5. Let 

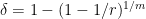

 , so that
, so that  , then by choice of we have
, then by choice of we have  , hence
, hence 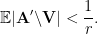
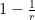 , there must exist such that
, there must exist such that  , giving the proposition.
, giving the proposition.
It remains to establish Proposition 6. This is the difficult step, and requires a clever way to find the variant 

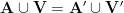

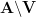
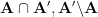




Recent Comments