
You are currently browsing the tag archive for the ‘Littlewood-Offord problem’ tag.
Hoi Nguyen, Van Vu, and myself have just uploaded to the arXiv our paper “Random matrices: tail bounds for gaps between eigenvalues“. This is a followup paper to my recent paper with Van in which we showed that random matrices 
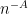

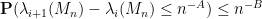
for any 


In the mean zero case, it becomes more efficient to use an inverse Littlewood-Offord theorem of Rudelson and Vershynin to obtain (with the normalisation that the entries of 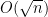

for 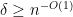


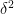
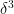
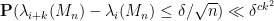
for any fixed 




In the case of Erdös-Renyi graphs, we don’t have mean zero and the Rudelson-Vershynin Littlewood-Offord theorem isn’t quite applicable, but by working carefully through the approach based on the Nguyen-Vu theorem we can almost recover (1), except for a loss of 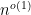
As a sample applications of the eigenvalue separation results, we can now obtain some information about eigenvectors; for instance, we can show that the components of the eigenvectors all have magnitude at least
Van Vu and I have just uploaded to the arXiv our paper “Random matrices have simple spectrum“. Recall that an 
For discrete random matrix ensembles, though, the above argument breaks down, even though general universality heuristics predict that the statistics of discrete ensembles should behave similarly to those of continuous ensembles. A model case here is the adjacency matrix 
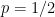
Our argument works for more general Wigner-type matrix ensembles, but for sake of illustration we will stick with the Erdös-Renyi case. Previous work on local universality for such matrix models (e.g. the work of Erdos, Knowles, Yau, and Yin) was able to show that any individual eigenvalue gap 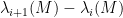
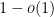
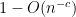
Our argument in fact gives simplicity of the spectrum with probability 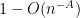
The basic idea of argument can be sketched as follows. Suppose that 

for a random 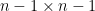


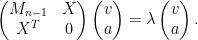
Extracting the top 
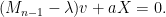
If we let 
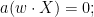
we typically expect 
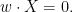
In other words, in order for
One of the most notorious problems in elementary mathematics that remains unsolved is the Collatz conjecture, concerning the function 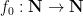
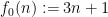


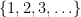
Conjecture 1 (Collatz conjecture) For any given natural number
passes through
for some
Open questions with this level of notoriety can lead to what Richard Lipton calls “mathematical diseases” (and what I termed an unhealthy amount of obsession on a single famous problem). (See also this xkcd comic regarding the Collatz conjecture.) As such, most practicing mathematicians tend to spend the majority of their time on more productive research areas that are only just beyond the range of current techniques. Nevertheless, it can still be diverting to spend a day or two each year on these sorts of questions, before returning to other matters; so I recently had a go at the problem. Needless to say, I didn’t solve the problem, but I have a better appreciation of why the conjecture is (a) plausible, and (b) unlikely be proven by current technology, and I thought I would share what I had found out here on this blog.
Let me begin with some very well known facts. If 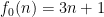
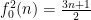
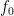
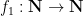
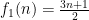
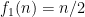

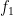
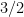



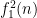
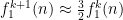
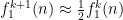

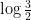
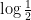
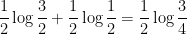
is negative, and so (by the classic gambler’s ruin) we expect the orbit to decrease over the long term. This can be viewed as heuristic justification of the Collatz conjecture, at least in the “average case” scenario in which 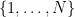
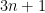
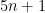
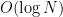
Remark 1 One can obtain a rigorous analogue of the above arguments by extending
to the
. This compact abelian group comes with a Haar probability measure, and one can verify that this measure is invariant with respect to
will be even half the time and odd half the time asymptotically, thus supporting the above heuristics. Unfortunately, this does not directly tell us much about the dynamics on
on the unit circle
is well understood from ergodic theory (in particular, almost all orbits will be uniformly distributed), but the orbit of a specific point, e.g.
, is still nearly impossible to understand (this particular problem being equivalent to the notorious unsolved question of whether the digits of
are uniformly distributed).
The above heuristic argument only suggests decreasing orbits for almost all 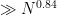

Conjecture 2 (Weak Collatz conjecture) Suppose that
for some
Of course, we may replace
This weaker version of the Collatz conjecture is also unproven. However, it was observed by Bohm and Sontacchi that this weak conjecture is equivalent to a divisibility problem involving powers of 
Conjecture 3 (Reformulated weak Collatz conjecture) There does not exist
such that
is a positive integer that is a proper divisor of
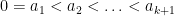
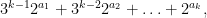
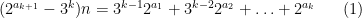
Proof: To see this, it is convenient to reformulate Conjecture 2 slightly. Define an equivalence relation 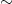
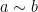


![{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle f_2( [n] ) := [3n + 2^a] \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_2%28+%5Bn%5D+%29+%3A%3D+%5B3n+%2B+2%5Ea%5D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
for any 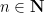
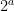

![{[1]}](https://s0.wp.com/latex.php?latex=%7B%5B1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now suppose that Conjecture 2 failed, thus there exists ![{[n] \neq [1]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D+%5Cneq+%5B1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{f_2^k([n])=[n]}](https://s0.wp.com/latex.php?latex=%7Bf_2%5Ek%28%5Bn%5D%29%3D%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
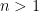
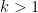
![\displaystyle f_2^k([n]) = [3^k n + 3^{k-1} 2^{a_1} + 3^{k-2} 2^{a_2} + \ldots + 2^{a_k}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_2%5Ek%28%5Bn%5D%29+%3D+%5B3%5Ek+n+%2B+3%5E%7Bk-1%7D+2%5E%7Ba_1%7D+%2B+3%5E%7Bk-2%7D+2%5E%7Ba_2%7D+%2B+%5Cldots+%2B+2%5E%7Ba_k%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
where, for each 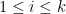
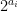
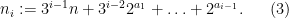
In particular, as 
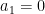

we see from induction that 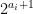
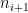
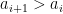
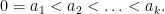
Since ![{f_2^k([n]) = [n]}](https://s0.wp.com/latex.php?latex=%7Bf_2%5Ek%28%5Bn%5D%29+%3D+%5Bn%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
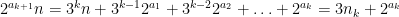
for some integer 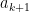
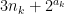
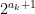
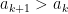
Conversely, suppose that Conjecture 3 failed. Then we have
and a natural number 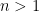
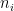
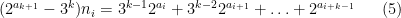
with the periodic convention 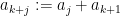
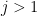

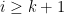
![\displaystyle f_2([n_i]) = [3n_i + 2^{a_i}] = [n_{i+1}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_2%28%5Bn_i%5D%29+%3D+%5B3n_i+%2B+2%5E%7Ba_i%7D%5D+%3D+%5Bn_%7Bi%2B1%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
and thus

Call a counterexample a tuple 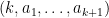
such that (1) holds for some 
Lemma 5 (Exponent bounds) Let
, and suppose that the Collatz conjecture is true for all
. Let

Proof: The first bound is immediate from the positivity of 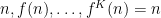

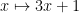
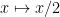
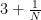
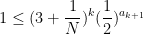
whence the claim.
The Collatz conjecture has already been verified for many values of 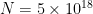
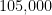
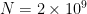
Now we can perform a heuristic count on the number of counterexamples. If we fix 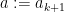
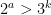
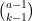
to form a potential counterexample 

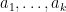
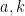
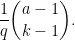
The heuristic number of solutions overall is then expected to be
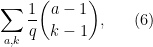
where, in view of Lemma 5, one should restrict the double summation to the heuristic regime 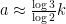
We need a lower bound on
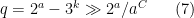
for some absolute constant 
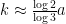
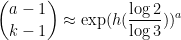
where 
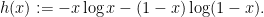
A brief computation shows that

and so (ignoring all subexponential terms)
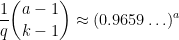
which makes the series (6) convergent. (Actually, one does not need the full strength of Lemma 5 here; anything that kept 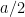
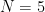
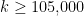
This, of course, is far short of any rigorous proof of Conjecture 2. In order to make rigorous progress on this conjecture, it seems that one would need to somehow exploit the structural properties of numbers of the form
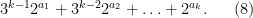
In some very special cases, this can be done. For instance, suppose that one had 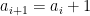


Amusingly, there is a slight connection to Littlewood-Offord theory in additive combinatorics – the study of the 

generated by some elements 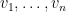

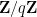

then the set 

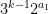
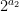



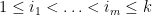
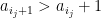
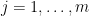

If the weak Collatz conjecture is true, then the set 

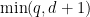

Proposition 6 Suppose the weak Collatz conjecture is true. Then for any natural numbers
.
This bound is very weak when compared against the unconditional bound (7). However, I know of no way to get a nontrivial separation property between powers of
By using more sophisticated tools in additive combinatorics, one can improve the above proposition (though it is still well short of the transcendence theory bound (7)):
Proposition 7 Suppose the weak Collatz conjecture is true. Then for any natural numbers
for some absolute constant
.
Proof: (Informal sketch only) Suppose not, then we can find 


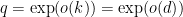
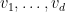
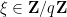
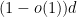
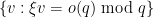
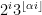

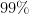

Thus we see that any proposed proof of the Collatz conjecture must either use transcendence theory, or introduce new techniques that are powerful enough to create exponential separation between powers of
Unfortunately, once one uses the transcendence theory bound (7), the size
One possible toy model problem for the (weak) Collatz conjecture is a conjecture of Erdos asserting that for 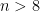
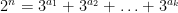
with 
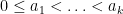
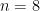
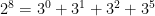
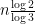

Now we turn attention to another important spectral statistic, the least singular value 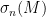


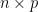
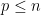
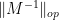
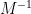

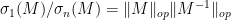
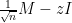

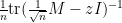
The least singular value

which sits at the “hard edge” of the spectrum, bears a superficial similarity to the operator norm

at the “soft edge” of the spectrum, that was discussed back in Notes 3, so one may at first think that the methods that were effective in controlling the latter, namely the epsilon-net argument and the moment method, would also work to control the former. The epsilon-net method does indeed have some effectiveness when dealing with rectangular matrices (in which the spectrum stays well away from zero), but the situation becomes more delicate for square matrices; it can control some “low entropy” portions of the infimum that arise from “structured” or “compressible” choices of 
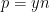
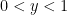
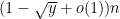


So one needs to supplement these existing methods with additional tools. It turns out that the key issue is to understand the distance between one of the 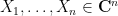
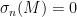
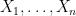

More generally, if the least singular value
When working with random matrices with jointly independent coefficients, we have the crucial property that the unit normal 
These methods rely quite strongly on the joint independence on all the entries; it remains a challenge to extend them to more general settings. Even for Wigner matrices, the methods run into difficulty because of the non-independence of some of the entries (although it turns out one can understand the least singular value in such cases by rather different methods).
To simplify the exposition, we shall focus primarily on just one specific ensemble of random matrices, the Bernoulli ensemble 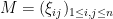
Van Vu and I have just uploaded to the arXiv our joint paper “The Littlewood-Offord problem in high dimensions and a conjecture of Frankl and Füredi“. In this short paper we give a different proof of a high-dimensional Littlewood-Offord result of Frankl and Füredi, and in the process also affirmatively answer one of their open problems.
Let 
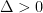

where 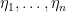



where
The one-dimensional case of this problem was answered by Erdös. First, one observes that one can normalise all the 


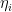

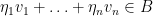
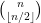

when 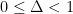

A similar argument works for higher values of

whenever 
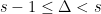


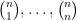
Now consider the higher-dimensional problem. One has the obvious bound

but it is not obvious whether this inequality is strict. In other words, is there some way to exploit the additional freedom given by higher dimensions to make random walks concentrate more than in the one-dimensional case?
For some values of

for some 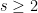





In the positive direction, Frankl and Füredi established the asymptotic
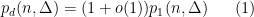
as 

(so that the above counterexample can be avoided) they showed that 

The factor 

thus matching the counterexample exactly. This conjecture was verified for 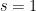
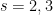
In this paper we verify the conjecture of Frankl and Füredi (and give a new proof of their asymptotic (1)). Our main tool is the following high-dimensional Littlewood-Offord inequality:
Theorem 1 Suppose that
which is genuinely
going through the origin, one has
for at least

Theorem 1 can be viewed as a high-dimensional variant of Erdös’s inequality (but without the sharp upper bound). It is proven by the Fourier-analytic method of Halász. (This theorem was announced in my book with Van Vu several years ago, but we did not get around to publishing it until now.)
Using Theorem 1, one can verify the conjecture of Frankl and Füredi fairly quickly (the deduction takes a little over a page). The main point is that if there is excessive concentration, then Theorem 1 quickly places almost all of the vectors 
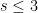
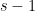
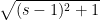
One moral that one can draw from this argument is that one can use a quasi-sharp estimate (such as Theorem 1), which ostensibly loses constant factors, to then deduce a sharp estimate (such as the Frankl-Furëdi conjecture) that loses no constant factors, as long as one is in an asymptotic regime (in this case, 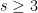

Van Vu and I have just uploaded to the arXiv our preprint “On the permanent of random Bernoulli matrices“, submitted to Adv. Math. This paper establishes analogues of some recent results on the determinant of random 
More precisely, let M be a random 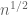
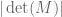
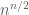
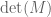
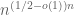
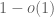
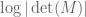
The permanent 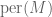

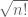
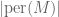

In particular, this shows that the probability that the permanent vanishes completely is o(1) (in fact, we get a bound of 
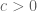



This is my second Milliman lecture, in which I talk about recent applications of ideas from additive combinatorics (and in particular, from the inverse Littlewood-Offord problem) to the theory of discrete random matrices.
Read the rest of this entry »
Van Vu and I have recently uploaded our joint paper, “Random matrices: the circular law“, submitted to Contributions to Discrete Mathematics. In this paper we come close to fully resolving the circular law conjecture regarding the eigenvalue distribution of random matrices, for arbitrary choices of coefficient distribution.
More precisely, suppose we have an 
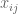


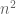



Numerical evidence (as seen for instance here) soon reveals that these n eigenvalues appear to distribute themselves uniformly in the unit circle 
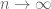
![\mu_n: {\Bbb R}^2 \to [0,1]](https://s0.wp.com/latex.php?latex=%5Cmu_n%3A+%7B%5CBbb+R%7D%5E2+%5Cto+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

then with probability 1, 

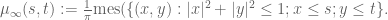
This statement is known as the circular law conjecture. In the case when x is a complex Gaussian, this law was verified by Mehta (using an explicit formula of Ginibre for the joint density function of the eigenvalues in this case). A strategy for attacking the general case was then formulated by Girko, although a fully rigorous execution of that strategy was first achieved by Bai (and then improved slightly by Bai and Silverstein). They established the circular law under the assumption that x had slightly better than bounded second moment (i.e. 
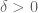
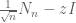
In the last few years, work of Rudelson, of myself with Van Vu, and of Rudelson-Vershynin (building upon earlier work of Kahn, Komlos, and Szemerédi, and of Van and myself), have opened the way to control the condition number of random matrices even when the matrices are discrete, and so there have been a recent string of results using these techniques to extend the circular law to discrete settings. In particular, Gotze and Tikhomirov established the circular law for discrete random variables which were sub-Gaussian, which was then relaxed by Pan and Zhou to an assumption of bounded fourth moment. In our paper, we get very close to the ideal assumption of bounded second moment; we need 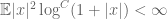

The main new difficulty that arises when relaxing the moment condition so close to the optimal one is that one begins to lose control on the largest singular value of 
I’ve arXived the paper “On the condition number of a randomly perturbed matrix”, authored with Van Vu, which will appear at STOC 2007. (This paper was actually finished and submitted several months ago, but for some reason I neglected to upload it to the arXiv until now.) Here we show that given an arbitrary 



Recent Comments