
You are currently browsing the monthly archive for October 2022.
Just a short post to advertise the workshop “Machine assisted proofs” that will be held on Feb 13-17 next year, here at the Institute for Pure and Applied Mathematics (IPAM); I am one of the organizers of this event together with Erika Abraham, Jeremy Avigad, Kevin Buzzard, Jordan Ellenberg, Tim Gowers, and Marijn Heule. The purpose of this event is to bring together experts in the various types of formal computer-assisted methods used to verify, discover, or otherwise assist with mathematical proofs, as well as pure mathematicians who are interested in learning about the current and future state of the art with such tools; this seems to be an opportune time to bring these communities together, given some recent high-profile applications of formal methods in pure mathematics (e.g, the liquid tensor experiment). The workshop will consist of a number of lectures from both communities, as well as a panel to discuss future directions. The workshop is open to general participants (both in person and remotely), although there is a registration process and a moderate registration fee to cover costs and to restrict the capacity to genuine applicants.
This is a spinoff from the previous post. In that post, we remarked that whenever one receives a new piece of information 
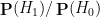
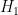

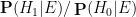

 is the likelihood of this information under the alternative hypothesis , and
is the likelihood of this information under the alternative hypothesis , and  is the likelihood of this information under the null hypothesis . If there are no other hypotheses under consideration, then the two posterior probabilities
is the likelihood of this information under the null hypothesis . If there are no other hypotheses under consideration, then the two posterior probabilities 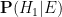 ,
,  must add up to one, and so can be recovered from the posterior odds
must add up to one, and so can be recovered from the posterior odds 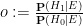 by the formulae
by the formulae 

A PDF version of the worksheet and instructions can be found here. One can fill in this worksheet in the following order:
- In Box 1, one enters in the precise statement of the null hypothesis
- In Box 2, one enters in the precise statement of the alternative hypothesis
- In Box 3, one enters in the prior probability
(or the best estimate thereof) of the null hypothesis
- In Box 4, one enters in the prior probability
(or the best estimate thereof) of the alternative hypothesis
.
- In Box 5, one enters in the ratio
between Box 4 and Box 3.
- In Box 6, one enters in the precise new information
- In Box 7, one enters in the likelihood
- In Box 8, one enters in the likelihood
- In Box 9, one enters in the ratio
betwen Box 8 and Box 7.
- In Box 10, one enters in the product of Box 5 and Box 9.
- (Assuming there are no other hypotheses than
divided by
- (Assuming there are no other hypotheses than
To illustrate this procedure, let us consider a standard Bayesian update problem. Suppose that a given point in time, 

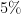

We can fill out the entries in the worksheet one at a time:
- Box 1: The null hypothesis
- Box 2: The alternative hypothesis
- Box 3: In the absence of any better information, the prior probability
, or
.
- Box 4: Similarly, the prior probability
.
- Box 5: The prior odds
.
- Box 6: The new information
- Box 7: The likelihood
(the false positive rate).
- Box 8: The likelihood
, or
(one minus the false negative rate).
- Box 9: The likelihood ratio
.
- Box 10: The product of Box 5 and Box 9 is approximately
.
- Box 11: The posterior probability
is approximately
.
- Box 12: The posterior probability
is approximately
.
The filled worksheet looks like this:
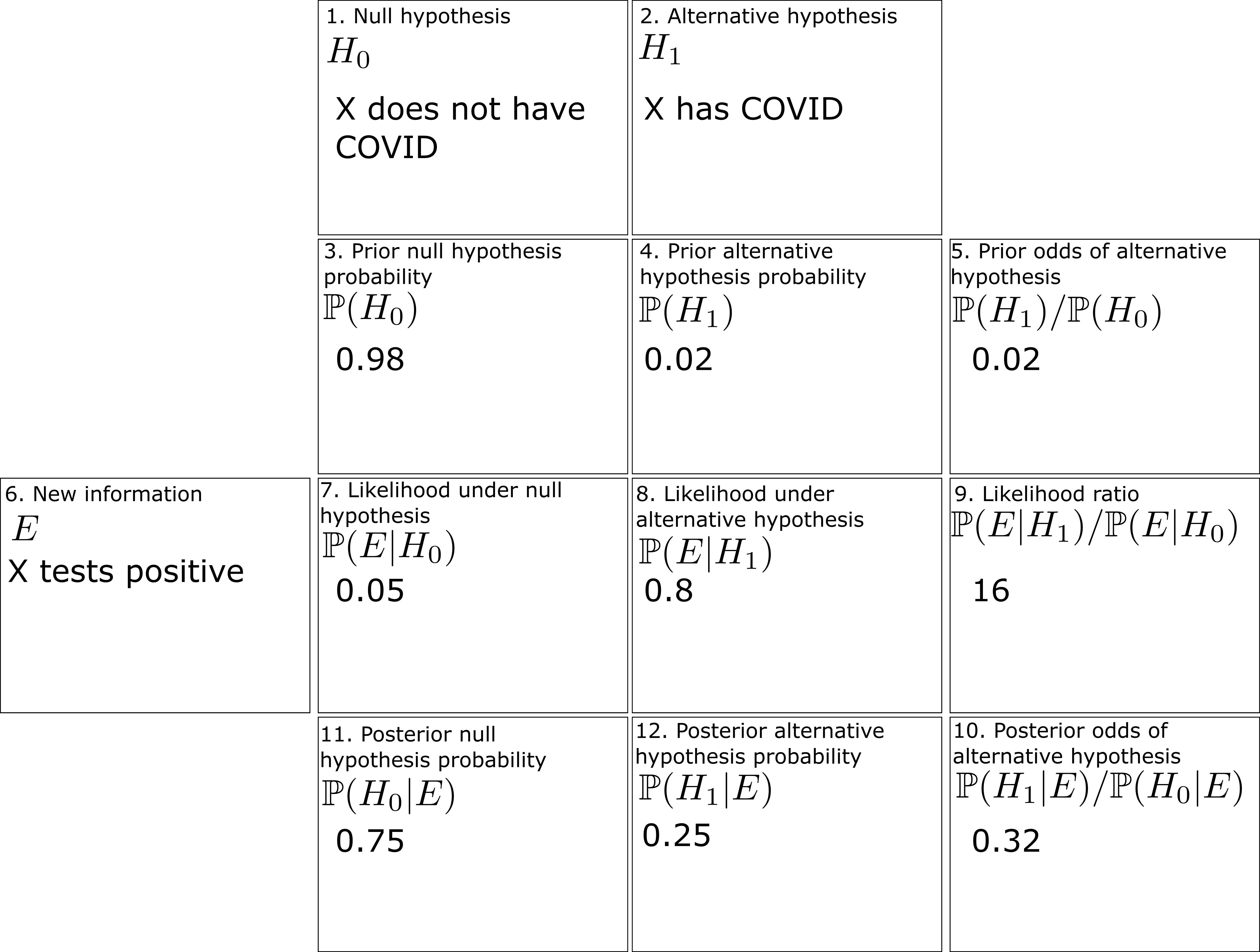
Perhaps surprisingly, despite the positive COVID test, the employee 
We remark that if we switch the roles of the null hypothesis and alternative hypothesis, then some of the odds in the worksheet change, but the ultimate conclusions remain unchanged:

So the question of which hypothesis to designate as the null hypothesis and which one to designate as the alternative hypothesis is largely a matter of convention.
Now let us take a superficially similar situation in which a mother observers her daughter exhibiting COVID-like symptoms, to the point where she estimates the probability of her daughter having COVID at 
One can fill out the worksheet much as before, but now with the prior probability of the alternative hypothesis raised from 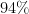

Thus we see that prior probabilities can make a significant impact on the posterior probabilities.
Now we use the worksheet to analyze an infamous probability puzzle, the Monty Hall problem. Let us use the formulation given in that Wikipedia page:
Problem 1 Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the doors, opens another door, say No. 3, which has a goat. He then says to you, “Do you want to pick door No. 2?” Is it to your advantage to switch your choice?
For this problem, the precise formulation of the null hypothesis and the alternative hypothesis become rather important. Suppose we take the following two hypotheses:
- Null hypothesis
- Alternative hypothesis
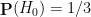 and
and 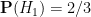 . The new information is that, after door 1 is selected, door 3 is revealed and shown to be a goat. After some thought, we conclude that is equal to
. The new information is that, after door 1 is selected, door 3 is revealed and shown to be a goat. After some thought, we conclude that is equal to  (the host has a fifty-fifty chance of revealing door 3 instead of door 2) but that is also equal to (if the car is behind door 2, the host must reveal door 3, whereas if the car is behind door 3, the host cannot reveal door 3). Filling in the worksheet, we see that the new information does not in fact alter the odds, and the probability that the car is not behind door 1 remains at 2/3, so it is advantageous to switch.
(the host has a fifty-fifty chance of revealing door 3 instead of door 2) but that is also equal to (if the car is behind door 2, the host must reveal door 3, whereas if the car is behind door 3, the host cannot reveal door 3). Filling in the worksheet, we see that the new information does not in fact alter the odds, and the probability that the car is not behind door 1 remains at 2/3, so it is advantageous to switch.

However, consider the following different set of hypotheses:
- Null hypothesis
: The car is behind door number 1, and if you pick the door with the car, the host will reveal another door to entice you to switch. Otherwise, the host will not reveal a door.
- Alternative hypothesis
: The car is behind door number 2 or 3, and if you pick the door with the car, the host will reveal another door to entice you to switch. Otherwise, the host will not reveal a door.
Here we still have 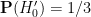


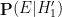
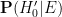

Finally, we consider another famous probability puzzle, the Sleeping Beauty problem. Again we quote the problem as formulated on the Wikipedia page:
Problem 2 Sleeping Beauty volunteers to undergo the following experiment and is told all of the following details: On Sunday she will be put to sleep. Once or twice, during the experiment, Sleeping Beauty will be awakened, interviewed, and put back to sleep with an amnesia-inducing drug that makes her forget that awakening. A fair coin will be tossed to determine which experimental procedure to undertake:Any time Sleeping Beauty is awakened and interviewed she will not be able to tell which day it is or whether she has been awakened before. During the interview Sleeping Beauty is asked: “What is your credence now for the proposition that the coin landed heads?”‘
- If the coin comes up heads, Sleeping Beauty will be awakened and interviewed on Monday only.
- If the coin comes up tails, she will be awakened and interviewed on Monday and Tuesday.
- In either case, she will be awakened on Wednesday without interview and the experiment ends.
Here the situation can be confusing because there are key portions of this experiment in which the observer is unconscious, but nevertheless Bayesian probability continues to operate regardless of whether the observer is conscious. To make this issue more precise, let us assume that the awakenings mentioned in the problem always occur at 8am, so in particular at 7am, Sleeping beauty will always be unconscious.
Here, the null and alternative hypotheses are easy to state precisely:
- Null hypothesis
- Alternative hypothesis
The subtle thing here is to work out what the correct prior state is (in most other applications of Bayesian probability, this state is obvious from the problem). It turns out that the most reasonable choice of prior state is “unconscious at 7am, on either Monday or Tuesday, with an equal chance of each”. (Note that whatever the outcome of the coin flip is, Sleeping Beauty will be unconscious at 7am Monday and unconscious again at 7am Tuesday, so it makes sense to give each of these two states an equal probability.) The new information is then
- New information
With this formulation, we see that 

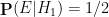
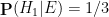


There are arguments advanced in the literature to adopt the position that
If one has multiple pieces of information 
 is withheld from the person filling out the worksheet, for instance if that person relies exclusively on a news source that only reports information that supports the alternative hypothesis and omits information that debunks it, then the outcome of the worksheet is likely to be highly inaccurate, and one should only perform a Bayesian analysis when one has a high confidence that all relevant information (both favorable and unfavorable to the alternative hypothesis) is being reported to the user.
is withheld from the person filling out the worksheet, for instance if that person relies exclusively on a news source that only reports information that supports the alternative hypothesis and omits information that debunks it, then the outcome of the worksheet is likely to be highly inaccurate, and one should only perform a Bayesian analysis when one has a high confidence that all relevant information (both favorable and unfavorable to the alternative hypothesis) is being reported to the user.
An unusual lottery result made the news recently: on October 1, 2022, the PCSO Grand Lotto in the Philippines, which draws six numbers from 
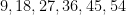
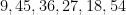
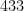
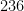

Whenever an event like this happens, journalists often contact mathematicians to ask the question: “What are the odds of this happening?”, and in fact I myself received one such inquiry this time around. This is a number that is not too difficult to compute – in this case, the probability of the lottery producing the six numbers 
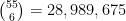
But on the previous draw of the same lottery, on September 28, 2022, the unremarkable sequence of numbers 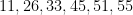
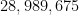
Part of the explanation surely lies in the unusually large number (
- The question “what are the odds of happening” is often easy to answer mathematically, but it is not the correct question to ask.
- The question “what is the probability that an alternative hypothesis is the truth” is (one of) the correct questions to ask, but is very difficult to answer (it involves both mathematical and non-mathematical considerations).
- The answer to the first question is one of the quantities needed to calculate the answer to the second, but it is far from the only such quantity. Most of the other quantities involved cannot be calculated exactly.
- However, by making some educated guesses, one can still sometimes get a very rough gauge of which events are “more surprising” than others, in that they would lead to relatively higher answers to the second question.
To explain these points it is convenient to adopt the framework of Bayesian probability. In this framework, one imagines that there are competing hypotheses to explain the world, and that one assigns a probability to each such hypothesis representing one’s belief in the truth of that hypothesis. For simplicity, let us assume that there are just two competing hypotheses to be entertained: the null hypothesis
- Null hypothesis
- Alternative hypothesis
At any given point in time, a person would have a probability 
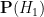
Bayesian probability does not provide a rule for calculating the initial (or prior) probabilities 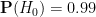
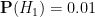

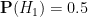
What Bayesian probability does do, however, is provide a rule to update these probabilities 

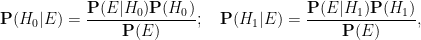
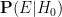 is the probability that the event would have occurred under the null hypothesis , and
is the probability that the event would have occurred under the null hypothesis , and 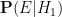 is the probability that the event would have occurred under the alternative hypothesis . Let us divide the second equation by the first to cancel the
is the probability that the event would have occurred under the alternative hypothesis . Let us divide the second equation by the first to cancel the 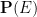 denominator, and obtain
denominator, and obtain 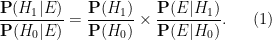
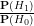 as the prior odds of the alternative hypothesis, and
as the prior odds of the alternative hypothesis, and 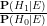 as the posterior odds of the alternative hypothesis. The identity (1) then says that in order to compute the posterior odds
as the posterior odds of the alternative hypothesis. The identity (1) then says that in order to compute the posterior odds 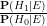 of the alternative hypothesis in light of the new information , one needs to know three things:
of the alternative hypothesis in light of the new information , one needs to know three things:
- The prior odds
- The probability
- The probability
As previously discussed, the prior odds 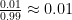

 . This is incredibly difficult to compute, because it requires a precise theory for how events would play out under the alternative hypothesis , and in particular is very sensitive as to what the alternative hypothesis actually is.
. This is incredibly difficult to compute, because it requires a precise theory for how events would play out under the alternative hypothesis , and in particular is very sensitive as to what the alternative hypothesis actually is.
For instance, suppose we replace the alternative hypothesis
- Alternative hypothesis
, and views October 1 as their holiest day. On this day, they will manipulate the lottery to only select those balls that are multiples of
Under this alternative hypothesis 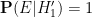
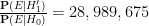
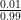




Remark 1 The contrast between alternative hypothesis
At the opposite extreme, consider instead the following hypothesis:
- Alternative hypothesis
: The lottery is rigged by some corrupt officials, who on October 1 decide to randomly determine the winning numbers in advance, share these numbers with their collaborators, and then manipulate the lottery to choose those numbers that they selected.
If these corrupt officials are indeed choosing their predetermined winning numbers randomly, then the probability 
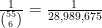
Now let us consider a third alternative hypothesis:
- Alternative hypothesis
: On October 1, the lottery machine developed a fault and now only selects numbers that exhibit unusual patterns.
Setting aside the question of precisely what faulty mechanism could induce this sort of effect, it is not clear at all how to compute 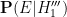
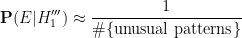
 lottery outcomes that are “unusual”. Among such patterns would presumably be the multiples-of-9 pattern
lottery outcomes that are “unusual”. Among such patterns would presumably be the multiples-of-9 pattern 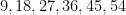 , but one could easily come up with other patterns that are equally “unusual”, such as consecutive strings such as
, but one could easily come up with other patterns that are equally “unusual”, such as consecutive strings such as  , or the first few primes
, or the first few primes  , or the first few squares
, or the first few squares 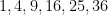 , and so forth. How many such unusual patterns are there? This is too vague a question to answer with any degree of precision, but as one illustrative statistic, the Online Encyclopedia of Integer Sequences (OEIS) currently hosts about
, and so forth. How many such unusual patterns are there? This is too vague a question to answer with any degree of precision, but as one illustrative statistic, the Online Encyclopedia of Integer Sequences (OEIS) currently hosts about  sequences. Not all of these would begin with six distinct numbers from to , and several of these sequences might generate the same set of six numbers, but this does suggests that patterns that one would deem to be “unusual” could number in the thousands, tens of thousands, or more. Using this guess, we would then expect the event to boost the odds of this hypothesis by perhaps a thousandfold or so, which is moderately impressive. But subsequent information can counteract this effect. For instance, on October 3, the same lottery produced the numbers
sequences. Not all of these would begin with six distinct numbers from to , and several of these sequences might generate the same set of six numbers, but this does suggests that patterns that one would deem to be “unusual” could number in the thousands, tens of thousands, or more. Using this guess, we would then expect the event to boost the odds of this hypothesis by perhaps a thousandfold or so, which is moderately impressive. But subsequent information can counteract this effect. For instance, on October 3, the same lottery produced the numbers  , which exhibit no unusual properties (no search results in the OEIS, for instance); if we denote this event by
, which exhibit no unusual properties (no search results in the OEIS, for instance); if we denote this event by  , then we have
, then we have 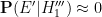 and so this new information should drive the odds for this alternative hypothesis way down again.
and so this new information should drive the odds for this alternative hypothesis way down again.
Remark 2 This example demonstrates another demagogical rhetorical technique that one sometimes sees (particularly in political or other emotionally charged contexts), which is to cherry-pick the information presented to their audience by informing them of eventsthat reported
Let us consider a superficially similar hypothesis:
- Alternative hypothesis
: On October 1, a divine being decided to send a sign to humanity by placing an unusual pattern in a lottery.
Here we (literally) stay agnostic on the prior odds of this hypothesis, and do not address the theological question of why a divine being should choose to use the medium of a lottery to send their signs. At first glance, the probability 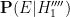

In summary, we have failed to locate any alternative hypothesis
- Has some non-negligible prior odds of being true (and in particular is not excessively specific, as with hypothesis
- Has a significantly higher probability of producing the specific event
- Does not struggle to also produce other events
; in the absence of these three factors, a moderately small numerical value of , such as does not actually do much to affect this plausibility. In this case one needs to lay out a reasonably precise alternative hypothesis and make some actual educated guesses towards the competing probability before one can lead to further conclusions. However, if is insanely small, e.g., less than 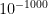 , then the possibility of a previously overlooked alternative hypothesis becomes far more plausible; as per the famous quote of Arthur Conan Doyle’s Sherlock Holmes, “When you have eliminated all which is impossible, then whatever remains, however improbable, must be the truth.”
, then the possibility of a previously overlooked alternative hypothesis becomes far more plausible; as per the famous quote of Arthur Conan Doyle’s Sherlock Holmes, “When you have eliminated all which is impossible, then whatever remains, however improbable, must be the truth.”
We now return to the fact that for this specific October 1 lottery, there were 
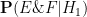
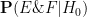
- Null hypothesis
Then 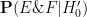
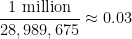
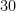 draws or so), and standard probability theory suggests that the number of winners should now follow a Poisson distribution with this mean
draws or so), and standard probability theory suggests that the number of winners should now follow a Poisson distribution with this mean  . The probability of obtaining winners would now be
. The probability of obtaining winners would now be  would be even smaller than this. So this clearly demands some sort of explanation. But in actuality, many purchasers of lottery tickets do not select their numbers completely randomly; they often have some “lucky” numbers (e.g., based on birthdays or other personally significant dates) that they prefer to use, or choose numbers according to a simple pattern rather than go to the trouble of trying to make them truly random. So if we modify the null hypothesis to
would be even smaller than this. So this clearly demands some sort of explanation. But in actuality, many purchasers of lottery tickets do not select their numbers completely randomly; they often have some “lucky” numbers (e.g., based on birthdays or other personally significant dates) that they prefer to use, or choose numbers according to a simple pattern rather than go to the trouble of trying to make them truly random. So if we modify the null hypothesis to
- Null hypothesis
: The lottery is run in a completely fair and random fashion, but a significant fraction of the purchasers of lottery tickets only select “unusual” numbers.
then it can now become quite plausible that a highly unusual set of numbers such as 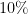
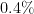
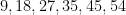
Remark 3 In view of the above discussion, one can propose a systematic way to evaluate (in as objective a fashion as possible) rhetorical claims in which an advocate is presenting evidence to support some alternative hypothesis:
- State the null hypothesis
- With the hypotheses precisely stated, give an honest estimate to the prior odds of this formulation of the alternative hypothesis.
- Consider if all the relevant information
- Estimate how likely the information
- Estimate how likely the information
- If the second estimate is significantly larger than the first, then you have cause to update your prior odds of this hypothesis (though if those prior odds were already vanishingly unlikely, this may not move the needle significantly). If not, the argument is unconvincing and no significant adjustment to the odds (except perhaps in a downwards direction) needs to be made.

Recent Comments