
You are currently browsing the monthly archive for October 2015.
The Chowla conjecture asserts, among other things, that one has the asymptotic

as 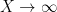
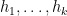



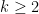

A natural generalisation of the Chowla conjecture is the Elliott conjecture. Its original formulation was basically as follows: one had
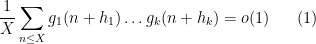
whenever 
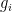
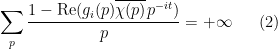
for all Dirichlet characters 

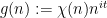


In a previous paper with Matomaki and Radziwill, we provided a counterexample to the original formulation of the Elliott conjecture, and proposed that (2) be replaced with the stronger condition

as

whenever 



for some 


under the same hypotheses, where 
In view of these results, it is tempting to conjecture that the condition (4) for one of the

when 
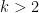
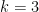
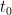

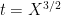
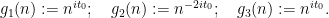
For 

and

and hence

and hence

On the other hand one can easily verify that all of the 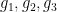
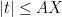
Conjecture 1 (Non-asymptotic Elliott conjecture) Let
be a natural number, and let
, let
, and let
. Let
, one has
for all Dirichlet characters
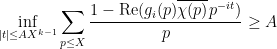

The 

A similar subtlety arises when trying to control the maximal integral
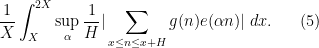
In my previous paper with Matomaki and Radziwill, we could show that easier expression

was small (for 

for some large

in order to address the counterexample in which 
One of the major activities in probability theory is studying the various statistics that can be produced from a complex system with many components. One of the simplest possible systems one can consider is a finite sequence 
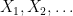

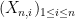

The first fundamental result about these sums is the law of large numbers (or LLN for short), which comes in two formulations, weak (WLLN) and strong (SLLN). To state these laws, we first must define the notion of convergence in probability.
Definition 1 Let
be a sequence of random variables taking values in a separable metric space
(e.g. the
or
), and let
. We say that
as
. Thus, if
are scalar, we have
as
The measure-theoretic analogue of convergence in probability is convergence in measure.
It is instructive to compare the notion of convergence in probability with almost sure convergence. it is easy to see that 


We have the following easy relationships between convergence in probability and almost sure convergence:
Exercise 2 Let
- (i) If
almost surely, show that
- (ii) Suppose that
for all
- (iii) If
of the
almost surely.
- (iv) If
are absolutely integrable and
as
- (v) (Urysohn subsequence principle) Suppose that every subsequence
that converges to
- (vi) Does the Urysohn subsequence principle still hold if “in probability” is replaced with “almost surely” throughout?
- (vii) If
or
is continuous, show that
converges in probability to
. More generally, if for each
,
is a sequence of scalar random variables that converge in probability to
, and
or
is continuous, show that
converges in probability to
. (Thus, for instance, if
converge in probability to
respectively, then
and
converge in probability to
and
respectively.
- (viii) (Fatou’s lemma for convergence in probability) If
.
- (ix) (Dominated convergence in probability) If
for all
and some absolutely integrable
converges to
.
Exercise 3 Let
- (i) Suppose that there is a random variable
. Show that
- (ii) Suppose that the
such that
almost surely).
We can now state the weak and strong law of large numbers, in the model case of iid random variables.
Theorem 4 (Law of large numbers, model case) Let
be an iid sequence of copies of an absolutely integrable random variable
, and for each natural number
denote the random variable
.
- (i) (Weak law of large numbers) The random variables
converge in probability to
.
- (ii) (Strong law of large numbers) The random variables
Informally: if 
It is instructive to compare the law of large numbers with what one can obtain from the Kolmogorov zero-one law, discussed in Notes 2. Observe that if the 





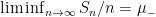

The law of large numbers asserts, roughly speaking, that the theoretical expectation 
There are several ways to prove the law of large numbers (in both forms). One basic strategy is to use the moment method – controlling statistics such as 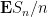

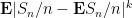


For the strong law of large numbers, one can also use methods relating to the theory of martingales, such as stopping time arguments and maximal inequalities; we present some classical arguments of Kolmogorov in this regard.
Read the rest of this entry »
In the previous set of notes, we constructed the measure-theoretic notion of the Lebesgue integral, and used this to set up the probabilistic notion of expectation on a rigorous footing. In this set of notes, we will similarly construct the measure-theoretic concept of a product measure (restricting to the case of probability measures to avoid unnecessary technicalities), and use this to set up the probabilistic notion of independence on a rigorous footing. (To quote Durrett: “measure theory ends and probability theory begins with the definition of independence.”) We will be able to take virtually any collection of random variables (or probability distributions) and couple them together to be independent via the product measure construction, though for infinite products there is the slight technicality (a requirement of the Kolmogorov extension theorem) that the random variables need to range in standard Borel spaces. This is not the only way to couple together such random variables, but it is the simplest and the easiest to compute with in practice, as we shall see in the next few sets of notes.
Read the rest of this entry »
I recently learned about a curious operation on square matrices known as sweeping, which is used in numerical linear algebra (particularly in applications to statistics), as a useful and more robust variant of the usual Gaussian elimination operations seen in undergraduate linear algebra courses. Given an 

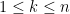

![{\hbox{Sweep}_k[A] = (\hat a_{ij})_{1 \leq i,j \leq n}}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BSweep%7D_k%5BA%5D+%3D+%28%5Chat+a_%7Bij%7D%29_%7B1+%5Cleq+i%2Cj+%5Cleq+n%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
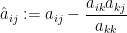



for all 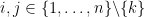

for some 

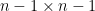

![\displaystyle \hbox{Sweep}_1[A] = \begin{pmatrix} -1/a_{11} & X / a_{11} \\ Y/a_{11} & B - a_{11}^{-1} YX \end{pmatrix}. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BSweep%7D_1%5BA%5D+%3D+%5Cbegin%7Bpmatrix%7D+-1%2Fa_%7B11%7D+%26+X+%2F+a_%7B11%7D+%5C%5C+Y%2Fa_%7B11%7D+%26+B+-+a_%7B11%7D%5E%7B-1%7D+YX+%5Cend%7Bpmatrix%7D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
The inverse sweep operation ![{\hbox{Sweep}_k^{-1}[A] = (\check a_{ij})_{1 \leq i,j \leq n}}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BSweep%7D_k%5E%7B-1%7D%5BA%5D+%3D+%28%5Ccheck+a_%7Bij%7D%29_%7B1+%5Cleq+i%2Cj+%5Cleq+n%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
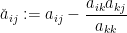



for all 

Remarkably, the sweep operators all commute with each other: 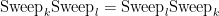
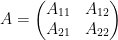
with 
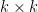




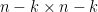
![\displaystyle \hbox{Sweep}_1 \dots \hbox{Sweep}_k[A] = \begin{pmatrix} -A_{11}^{-1} & A_{11}^{-1} A_{12} \\ A_{21} A_{11}^{-1} & A_{22} - A_{21} A_{11}^{-1} A_{12} \end{pmatrix}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BSweep%7D_1+%5Cdots+%5Chbox%7BSweep%7D_k%5BA%5D+%3D+%5Cbegin%7Bpmatrix%7D+-A_%7B11%7D%5E%7B-1%7D+%26+A_%7B11%7D%5E%7B-1%7D+A_%7B12%7D+%5C%5C+A_%7B21%7D+A_%7B11%7D%5E%7B-1%7D+%26+A_%7B22%7D+-+A_%7B21%7D+A_%7B11%7D%5E%7B-1%7D+A_%7B12%7D+%5Cend%7Bpmatrix%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Note the appearance of the Schur complement in the bottom right block. Thus, for instance, one can essentially invert a matrix
![\displaystyle \hbox{Sweep}_1 \dots \hbox{Sweep}_n[A] = -A^{-1}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BSweep%7D_1+%5Cdots+%5Chbox%7BSweep%7D_n%5BA%5D+%3D+-A%5E%7B-1%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
If a matrix has the form

for a 

![\displaystyle \hbox{Sweep}_1 \dots \hbox{Sweep}_{n-1}[A] = \begin{pmatrix} -B^{-1} & B^{-1} X \\ Y B^{-1} & a - Y B^{-1} X \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BSweep%7D_1+%5Cdots+%5Chbox%7BSweep%7D_%7Bn-1%7D%5BA%5D+%3D+%5Cbegin%7Bpmatrix%7D+-B%5E%7B-1%7D+%26+B%5E%7B-1%7D+X+%5C%5C+Y+B%5E%7B-1%7D+%26+a+-+Y+B%5E%7B-1%7D+X+%5Cend%7Bpmatrix%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and all the components of this matrix are usable for various numerical linear algebra applications in statistics (e.g. in least squares regression). Given that sweeps behave well with inverses, it is perhaps not surprising that sweeps also behave well under determinants: the determinant of ![{\hbox{Sweep}_k[A]}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BSweep%7D_k%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
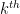
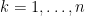
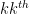
It turns out that there is a simple geometric explanation for these seemingly magical properties of the sweep operation. Any ![{\hbox{Graph}[A] := \{ (X, AX): X \in {\bf R}^n \}}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BGraph%7D%5BA%5D+%3A%3D+%5C%7B+%28X%2C+AX%29%3A+X+%5Cin+%7B%5Cbf+R%7D%5En+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

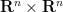
We use 

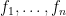

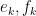

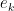
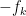
![\displaystyle \hbox{Graph}[ \hbox{Sweep}_k[A] ] = \hbox{Rot}_k \hbox{Graph}[A]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chbox%7BGraph%7D%5B+%5Chbox%7BSweep%7D_k%5BA%5D+%5D+%3D+%5Chbox%7BRot%7D_k+%5Chbox%7BGraph%7D%5BA%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
for generic ![{\hbox{Graph}[A]}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BGraph%7D%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



The image of 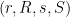
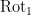


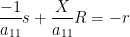
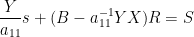
we see from (2) that ![{\hbox{Rot}_1 \hbox{Graph}[A]}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BRot%7D_1+%5Chbox%7BGraph%7D%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\hbox{Sweep}_1[A]}](https://s0.wp.com/latex.php?latex=%7B%5Chbox%7BSweep%7D_1%5BA%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
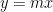
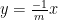
It is then an instructive exercise to use this geometric interpretation of the sweep operator to recover all the remarkable properties about these operations listed above. It is also useful to compare the geometric interpretation of sweeping as rotation of the graph to that of Gaussian elimination, which instead shears and reflects the graph by various elementary transformations (this is what is going on geometrically when one performs Gaussian elimination on an augmented matrix). Rotations are less distorting than shears, so one can see geometrically why sweeping can produce fewer numerical artefacts than Gaussian elimination.
In Notes 0, we introduced the notion of a measure space 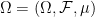
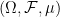




- Given events
, we defined the conjunction
, the disjunction
, and the complement
. For countable families
of events, we similarly defined
and
. We also defined the empty event
and the sure event
, and what it meant for two events to be equal.
- Given random variables
respectively, and a measurable function
, we defined the random variable
in range
. (As the special case
of this, every deterministic element
of
, we similarly defined the event
. Conversely, given an event
. Finally, we defined what it meant for two random variables to be equal.
- Given an event
.
These operations obey various axioms; for instance, the boolean operations on events obey the axioms of a Boolean algebra, and the probabilility function 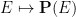
It turns out that almost all of the other operations on random events and variables we need can be constructed in terms of the above basic operations. In particular, this allows one to safely extend the sample space in probability theory whenever needed, provided one uses an extension that respects the above basic operations; this is an important operation when one needs to add new sources of randomness to an existing system of events and random variables, or to couple together two separate such systems into a joint system that extends both of the original systems. We gave a simple example of such an extension in the previous notes, but now we give a more formal definition:
Definition 1 Suppose that we are using a probability space
, together with a measurable map
(sometimes called the factor map) which is probability-preserving in the sense that
for all
. (Caution: this does not imply that
for all
– why not?)
An event
, will be modeled by the measurable set
in the extended sample space
. Similarly, a random variable
in
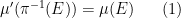
Thus, for instance, the sample space 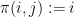
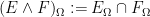
or via the extension

The two definitions are consistent with each other, thanks to the obvious set-theoretic identity
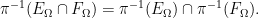
Similarly, the assumption (1) is precisely what is needed to ensure that the probability 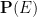
Remark 2 There is one minor exception to this general rule if we do not impose the additional requirement that the factor map
is surjective. Namely, for non-surjective
are unequal in the original sample space model, but become equal in the extension (and similarly for random variables), although the converse never happens (events that are equal in the original sample space always remain equal in the extension). For instance, let
with
and
, and let
with
, and non-surjective factor map
. Then the event modeled by
in
Roughly speaking, one can define probability theory as the study of those properties of random events and random variables that are model-independent in the sense that they are preserved by extensions. For instance, the cardinality 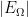



On the other hand, the supremum 
![{[-\infty,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5B-%5Cinfty%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




we thus see that one can completely specify 
In this set of notes, we will define some further important operations on scalar random variables, in particular the expectation of these variables. In the sample space models, expectation corresponds to the notion of integration on a measure space. As we will need to use both expectation and integration in this course, we will thus begin by quickly reviewing the basics of integration on a measure space, although we will then translate the key results of this theory into probabilistic language.
As the finer details of the Lebesgue integral construction are not the core focus of this probability course, some of the details of this construction will be left to exercises. See also Chapter 1 of Durrett, or these previous blog notes, for a more detailed treatment.

Recent Comments