
You are currently browsing the monthly archive for October 2007.
This month I have been at the Institute for Advanced Study, participating in their semester program on additive combinatorics. Today I gave a talk on my forthcoming paper with Tim Austin on the property testing of graphs and hypergraphs (I hope to make a preprint available here soon). There has been an immense amount of progress on these topics recently, based in large part on the graph and hypergraph regularity lemmas; but we have discovered some surprising subtleties regarding these results, namely a distinction between undirected and directed graphs, between graphs and hypergraphs, between partite hypergraphs and non-partite hypergraphs, and between monotone hypergraph properties and hereditary ones.
For simplicity let us first work with (uncoloured, undirected, loop-free) graphs G = (V,E). In the subject of graph property testing, one is given a property 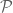
- G is planar.
- G is four-colourable.
- G has a number of edges equal to a power of two.
- G contains no triangles.
- G is bipartite.
- G is empty.
- G is a complete bipartite graph.
We assume that the labeling of the graph is irrelevant. More precisely, we assume that whenever two graphs G, G’ are isomorphic, that G satisfies
We shall think of G as being very large (so 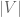
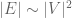

- (No false negatives) If G indeed satisfies
- (Few false positives in the
-far case) If G fails to satisfy
edges in G before
When a test with the above properties exists for each given
An example should illustrate this definition. Consider for instance property 6 above (the property that G is empty). To test whether a graph is empty, one can perform the following obvious algorithm: take k vertices in G at random and check whether they have any edges at all between them. If they do, then the test of course rejects G as being non-empty, while if they don’t, the test accepts G as being empty. Clearly there are no false negatives in this test, and if k is large enough depending on
On the other hand, it is intuitively obvious that property 3 (having an number of edges equal to a power of 2) is not testable with one-sided error.
So it is reasonable to ask: what types of graph properties are testable with one-sided error, and which ones are not?
Today I’d like to discuss (part of) a cute and surprising theorem of Fritz John in the area of non-linear wave equations, and specifically for the equation

where 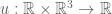
The evolution of this type of non-linear wave equation can be viewed as a “race” between the dispersive tendency of the linear wave equation
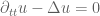
and the positive feedback tendencies of the nonlinear ODE

More precisely, solutions to (2) tend to decay in time as 

![u(t,x) = \frac{1}{4\pi t} \int_{|y-x|=t} \partial_t u(0,y)\ dS(y) + \partial_t[\frac{1}{4\pi t} \int_{|y-x|=t} u(0,y)\ dS(y)],](https://s0.wp.com/latex.php?latex=u%28t%2Cx%29+%3D++%5Cfrac%7B1%7D%7B4%5Cpi+t%7D+%5Cint_%7B%7Cy-x%7C%3Dt%7D+%5Cpartial_t+u%280%2Cy%29%5C+dS%28y%29+%2B+%5Cpartial_t%5B%5Cfrac%7B1%7D%7B4%5Cpi+t%7D+%5Cint_%7B%7Cy-x%7C%3Dt%7D+u%280%2Cy%29%5C+dS%28y%29%5D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
for such solutions in terms of the initial position 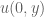

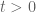
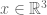
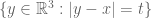
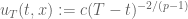
for 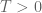


The equation (1) can be viewed as a combination of equations (2) and (3) and should thus inherit a mix of the behaviours of both its “parents”. As a general rule, when the initial data 
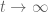
The theorem of John formalises this intuition, with a remarkable threshold value for p:
Theorem. Let
.
- If
, then there exist solutions which are arbitrarily small (both in size and in support) and smooth at time zero, but which blow up in finite time.
- If
, then for every initial data which is sufficiently small in size and support, and sufficiently smooth, one has a global solution (which goes to zero uniformly as
[At the critical threshold 
The ostensible purpose of this post is to try to explain why the curious exponent 
I’ve just come back from the 48th Annual IEEE Symposium on the Foundations of Computer science, better known as FOCS; this year it was held at Providence, near Brown University. (This conference is also being officially reported on by the blog posts of Nicole Immorlica, Luca Trevisan, and Scott Aaronson.) I was there to give a tutorial on some of the tools used these days in additive combinatorics and graph theory to distinguish structure and randomness. In a previous blog post, I had already mentioned that my lecture notes for this were available on the arXiv; now the slides for my tutorial are available too (it covers much the same ground as the lecture notes, and also incorporates some material from my ICM slides, but in a slightly different format).
In the slides, I am tentatively announcing some very recent (and not yet fully written up) work of Ben Green and myself establishing the Gowers inverse conjecture in finite fields in the special case when the function f is a bounded degree polynomial (this is a case which already has some theoretical computer science applications). I hope to expand upon this in a future post. But I will describe here a neat trick I learned at the conference (from the FOCS submission of Bogdanov and Viola) which uses majority voting to enhance a large number of small independent correlations into a much stronger single correlation. This application of majority voting is widespread in computer science (and, of course, in real-world democracies), but I had not previously been aware of its utility to the type of structure/randomness problems I am interested in (in particular, it seems to significantly simplify some of the arguments in the proof of my result with Ben mentioned above); thanks to this conference, I now know to add majority voting to my “toolbox”.
I’m continuing my series of articles for the Princeton Companion to Mathematics by uploading my article on the Fourier transform. Here, I chose to describe this transform as a means of decomposing general functions into more symmetric functions (such as sinusoids or plane waves), and to discuss a little bit how this transform is connected to differential operators such as the Laplacian. (This is of course only one of the many different uses of the Fourier transform, but again, with only five pages to work with, it’s hard to do justice to every single application. For instance, the connections with additive combinatorics are not covered at all.)
On the official web site of the Companion (which you can access with the user name “Guest” and password “PCM”), there is a more polished version of the same article, after it had gone through a few rounds of the editing process.
I’ll also point out David Ben-Zvi‘s Companion article on “moduli spaces“. This concept is deceptively simple – a space whose points are themselves spaces, or “representatives” or “equivalence classes” of such spaces – but it leads to the “correct” way of thinking about many geometric and algebraic objects, and more importantly about families of such objects, without drowning in a mess of coordinate charts and formulae which serve to obscure the underlying geometry.
[Update, Oct 21: categories fixed.]
In one of my recent posts, I used the Jordan normal form for a matrix in order to justify a couple of arguments. As a student, I learned the derivation of this form twice: firstly (as an undergraduate) by using the minimal polynomial, and secondly (as a graduate) by using the structure theorem for finitely generated modules over a principal ideal domain. I found though that the former proof was too concrete and the latter proof too abstract, and so I never really got a good intuition on how the theorem really worked. So I went back and tried to synthesise a proof that I was happy with, by taking the best bits of both arguments that I knew. I ended up with something which wasn’t too different from the standard proofs (relying primarily on the (extended) Euclidean algorithm and the fundamental theorem of algebra), but seems to get at the heart of the matter fairly quickly, so I thought I’d put it up on this blog anyway.
Before we begin, though, let us recall what the Jordan normal form theorem is. For this post, I’ll take the perspective of abstract linear transformations rather than of concrete matrices. Let 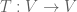

- The right shift. Here,
is a standard vector space, and the right shift
is defined as
, thus all elements are shifted right by one position. (For instance, the 1-dimensional right shift is just the zero operator.)
- The right shift plus a constant. Here we consider an operator
, where
is a complex number.
- Direct sums. Given two linear transformations
, we can form their direct sum
by the formula
.
Our objective is then to prove the
Jordan normal form theorem. Every linear transformation
(Of course, the same theorem also holds with left shifts instead of right shifts.)
I have just uploaded to the arXiv my paper “A quantitative formulation of the global regularity problem for the periodic Navier-Stokes equation”, submitted to Dynamics of PDE. This is a short note on one formulation of the Clay Millennium prize problem, namely that there exists a global smooth solution to the Navier-Stokes equation on the torus  given any smooth divergence-free data. (I should emphasise right off the bat that I am not claiming any major breakthrough on this problem, which remains extremely challenging in my opinion.)
given any smooth divergence-free data. (I should emphasise right off the bat that I am not claiming any major breakthrough on this problem, which remains extremely challenging in my opinion.)
This problem is formulated in a qualitative way: the conjecture asserts that the velocity field stays smooth for all time, but does not ask for a quantitative bound on the smoothness of that field in terms of the smoothness of the initial data. Nevertheless, it turns out that the compactness properties of the periodic Navier-Stokes flow allow one to equate the qualitative claim with a more concrete quantitative one. More precisely, the paper shows that the following three statements are equivalent:
stays smooth for all time, but does not ask for a quantitative bound on the smoothness of that field in terms of the smoothness of the initial data. Nevertheless, it turns out that the compactness properties of the periodic Navier-Stokes flow allow one to equate the qualitative claim with a more concrete quantitative one. More precisely, the paper shows that the following three statements are equivalent:
given any smooth divergence-free data. (I should emphasise right off the bat that I am not claiming any major breakthrough on this problem, which remains extremely challenging in my opinion.)This problem is formulated in a qualitative way: the conjecture asserts that the velocity field
stays smooth for all time, but does not ask for a quantitative bound on the smoothness of that field in terms of the smoothness of the initial data. Nevertheless, it turns out that the compactness properties of the periodic Navier-Stokes flow allow one to equate the qualitative claim with a more concrete quantitative one. More precisely, the paper shows that the following three statements are equivalent:
- (Qualitative regularity conjecture) Given any smooth divergence-free data
, there exists a global smooth solution
to the Navier-Stokes equations.
- (Local-in-time quantitative regularity conjecture)
Given any smooth solutionto the Navier-Stokes equations with
, one has the a priori bound
for some non-decreasing function
.
- (Global-in-time quantitative regularity conjecture) This is the same conjecture as 2, but with the condition
.
It is easy to see that Conjecture 3 implies Conjecture 2, which implies Conjecture 1. By using the compactness of the local periodic Navier-Stokes flow in 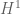
In my discussion of the Oppenheim conjecture in my recent post on Ratner’s theorems, I mentioned in passing the simple but crucial fact that the (orthochronous) special orthogonal group 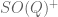
I’m continuing my series of articles for the Princeton Companion to Mathematics with my article on the Schrödinger equation – the fundamental equation of motion of quantum particles, possibly in the presence of an external field. My focus here is on the relationship between the Schrödinger equation of motion for wave functions (and the closely related Heisenberg equation of motion for quantum observables), and Hamilton’s equations of motion for classical particles (and the closely related Poisson equation of motion for classical observables). There is also some brief material on semiclassical analysis, scattering theory, and spectral theory, though with only a little more than 5 pages to work with in all, I could not devote much detail to these topics. (In particular, nonlinear Schrödinger equations, a favourite topic of mine, are not covered at all.)
As I said before, I will try to link to at least one other PCM article in every post in this series. Today I would like to highlight Madhu Sudan‘s delightful article on information and coding theory, “Reliable transmission of information“.
[Update, Oct 3: typos corrected.]
[Update, Oct 9: more typos corrected.]

Snap preview?
16 October, 2007 in admin | Tags: comments, formatting, presentation, snap preview | by Terence Tao | 39 comments
As you may have noticed, I had turned off the “Snap preview” feature on this blog (which previews any external link that the mouse hovers over) for a few weeks as an experiment. After a mixed response, I have decided to re-enable the feature for now, but would be interested in getting feedback on whether this feature makes noticeable differences (both positive and negative) to the viewing experience (in particular, to the loading time of the web page), so that I can decide whether to permanently re-enable it. (In the link above, incidentally, it is noted that one can turn off all snap preview windows by following an options link to set a cookie.)
This post would also be a good forum to discuss any other formatting and presentation issues with this blog (wordpress blogs are remarkably customisable). For instance, I have been looking out for a way to enable previewing of comments, but as far as I can tell this appears to not be possible on wordpress. But if anyone knows some workaround or substitute for this feature, I would like to hear about it.
[Update, Oct 17: Judging from the comments, the response to Snap preview continues to be mixed. But I have discovered how to turn Snap preview on and off for individual articles or links. So I will keep Snap preview on for Wikipedia links and off for the rest; see the articles currently in the front page of this blog for examples of this. I also note that in the Snap preview options menu, there are options to turn Snap off permanently, or to increase the delay before the preview shows up.
Also, following suggestions in the comments, I have darkened the text and also changed the blockquote format, in order to increase readability, and also changed the RSS feed from summaries to the full article (or more precisely, the portion of the article before the jump). ]
[Update, Oct 18: Comments moved to just below the post, as opposed to below the sidebar.]