
You are currently browsing the tag archive for the ‘eigenvalues’ tag.
Hariharan Narayanan, Scott Sheffield, and I have just uploaded to the arXiv our paper “Sums of GUE matrices and concentration of hives from correlation decay of eigengaps“. This is a personally satisfying paper for me, as it connects the work I did as a graduate student (with Allen Knutson and Chris Woodward) on sums of Hermitian matrices, with more recent work I did (with Van Vu) on random matrix theory, as well as several other results by other authors scattered across various mathematical subfields.
Suppose 

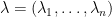
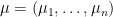
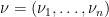
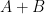
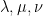

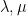



One of my favourite open problems is to come up with a theory of “free hives” that allows one to explain the latter fact from the former. This is still unresolved, but we are now beginning to make a bit of progress towards this goal. We know (for instance from the calculations of Coquereaux and Zuber) that if 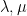
In this paper, we are able to accomplish the first half of this goal, assuming that the spectra 

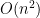
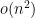
Augmented hives seem tricky to work with directly, but by adapting the octahedron recurrence introduced for this problem by Knutson, Woodward, and myself some time ago (which is related to the associativity 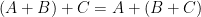
On the other hand, the piecewise linear map, initially defined by iterating the octahedron relation 
It would be more convenient to study the concentration of each linear map separately, rather than their supremum. By the Cheeger inequality, it turns out that one can relate the latter to the former provided that one has good control on the Cheeger constant of the underlying measure on the Gelfand-Tsetlin cones. Fortunately, the measure is log-concave, so one can use the very recent work of Klartag on the KLS conjecture to eliminate the supremum (up to a logarithmic loss which is only moderately annoying to deal with).
It remains to obtain concentration on the linear map associated to a given lozenge tiling. After stripping away some contributions coming from lozenges near the edge (using some eigenvalue rigidity results of Van Vu and myself), one is left with some bulk contributions which ultimately involve eigenvalue interlacing gaps such as
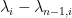
 is the
is the  eigenvalue of the top left
eigenvalue of the top left 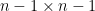 minor of , and
minor of , and  is in the bulk region
is in the bulk region  for some fixed
for some fixed  . To get the desired result, one needs some non-trivial correlation decay in for these statistics. If one was working with eigenvalue gaps
. To get the desired result, one needs some non-trivial correlation decay in for these statistics. If one was working with eigenvalue gaps 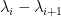 rather than interlacing results, then such correlation decay was conveniently obtained for us by recent work of Cippoloni, Erdös, and Schröder. So the last remaining challenge is to understand the relation between eigenvalue gaps and interlacing gaps.
rather than interlacing results, then such correlation decay was conveniently obtained for us by recent work of Cippoloni, Erdös, and Schröder. So the last remaining challenge is to understand the relation between eigenvalue gaps and interlacing gaps.
For this we turned to the work of Metcalfe, who uncovered a determinantal process structure to this problem, with a kernel associated to Lagrange interpolation polynomials. It is possible to satisfactorily estimate various integrals of these kernels using the residue theorem and eigenvalue rigidity estimates, thus completing the required analysis.
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv a completely rewritten version of our previous paper, now titled “Eigenvectors from Eigenvalues: a survey of a basic identity in linear algebra“. This paper is now a survey of the various literature surrounding the following basic identity in linear algebra, which we propose to call the eigenvector-eigenvalue identity:
Theorem 1 (Eigenvector-eigenvalue identity) Let
. Let
be a unit eigenvector corresponding to the eigenvalue
, and let
be the
component of
where
is the
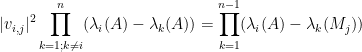
When we posted the first version of this paper, we were unaware of previous appearances of this identity in the literature; a related identity had been used by Erdos-Schlein-Yau and by myself and Van Vu for applications to random matrix theory, but to our knowledge this specific identity appeared to be new. Even two months after our preprint first appeared on the arXiv in August, we had only learned of one other place in the literature where the identity showed up (by Forrester and Zhang, who also cite an earlier paper of Baryshnikov).
The situation changed rather dramatically with the publication of a popular science article in Quanta on this identity in November, which gave this result significantly more exposure. Within a few weeks we became informed (through private communication, online discussion, and exploration of the citation tree around the references we were alerted to) of over three dozen places where the identity, or some other closely related identity, had previously appeared in the literature, in such areas as numerical linear algebra, various aspects of graph theory (graph reconstruction, chemical graph theory, and walks on graphs), inverse eigenvalue problems, random matrix theory, and neutrino physics. As a consequence, we have decided to completely rewrite our article in order to collate this crowdsourced information, and survey the history of this identity, all the known proofs (we collect seven distinct ways to prove the identity (or generalisations thereof)), and all the applications of it that we are currently aware of. The citation graph of the literature that this ad hoc crowdsourcing effort produced is only very weakly connected, which we found surprising:
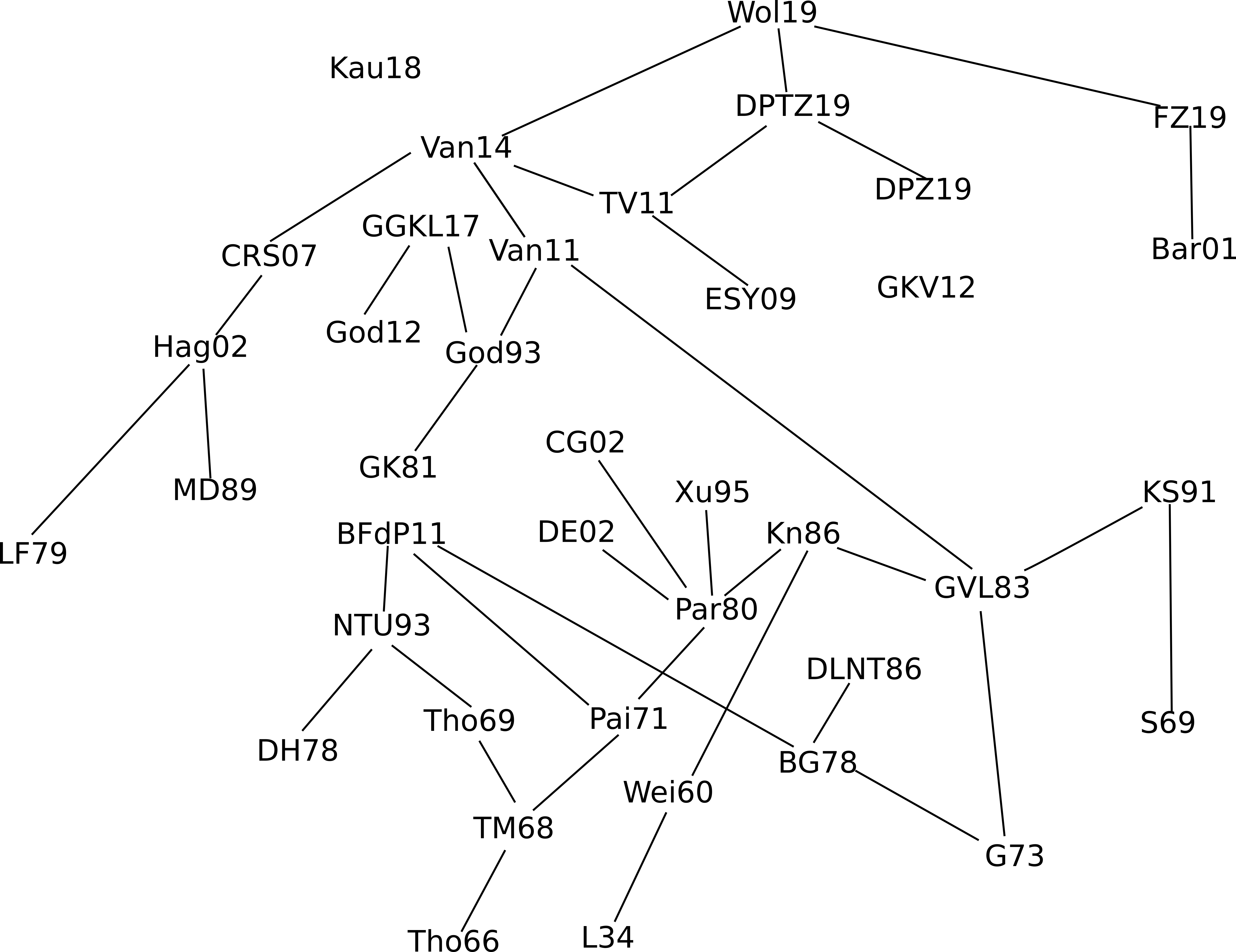
The earliest explicit appearance of the eigenvector-eigenvalue identity we are now aware of is in a 1966 paper of Thompson, although this paper is only cited (directly or indirectly) by a fraction of the known literature, and also there is a precursor identity of Löwner from 1934 that can be shown to imply the identity as a limiting case. At the end of the paper we speculate on some possible reasons why this identity only achieved a modest amount of recognition and dissemination prior to the November 2019 Quanta article.
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv the short unpublished note “Eigenvectors from eigenvalues“. This note gives two proofs of a general eigenvector identity observed recently by Denton, Parke and Zhang in the course of some quantum mechanical calculations. The identity is as follows:
Theorem 1 Let
where
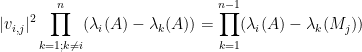
For instance, if we have
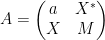
for some real number 



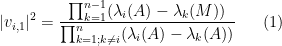
assuming that the denominator is non-zero.
Once one is aware of the identity, it is not so difficult to prove it; we give two proofs, each about half a page long, one of which is based on a variant of the Cauchy-Binet formula, and the other based on properties of the adjugate matrix. But perhaps it is surprising that such a formula exists at all; one does not normally expect to learn much information about eigenvectors purely from knowledge of eigenvalues. In the random matrix theory literature, for instance in this paper of Erdos, Schlein, and Yau, or this later paper of Van Vu and myself, a related identity has been used, namely
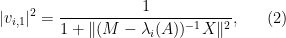
but it is not immediately obvious that one can derive the former identity from the latter. (I do so below the fold; we ended up not putting this proof in the note as it was longer than the two other proofs we found. I also give two other proofs below the fold, one from a more geometric perspective and one proceeding via Cramer’s rule.) It was certainly something of a surprise to me that there is no explicit appearance of the 
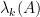

One can get some feeling of the identity (1) by considering some special cases. Suppose for instance that 
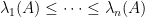
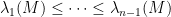
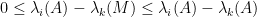
for 
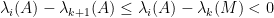
for 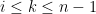

Hoi Nguyen, Van Vu, and myself have just uploaded to the arXiv our paper “Random matrices: tail bounds for gaps between eigenvalues“. This is a followup paper to my recent paper with Van in which we showed that random matrices 
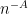
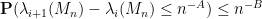
for any
In the mean zero case, it becomes more efficient to use an inverse Littlewood-Offord theorem of Rudelson and Vershynin to obtain (with the normalisation that the entries of 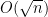

for 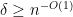


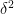
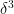
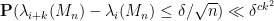
for any fixed 



In the case of Erdös-Renyi graphs, we don’t have mean zero and the Rudelson-Vershynin Littlewood-Offord theorem isn’t quite applicable, but by working carefully through the approach based on the Nguyen-Vu theorem we can almost recover (1), except for a loss of 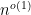
As a sample applications of the eigenvalue separation results, we can now obtain some information about eigenvectors; for instance, we can show that the components of the eigenvectors all have magnitude at least
Van Vu and I have just uploaded to the arXiv our paper “Random matrices have simple spectrum“. Recall that an
For discrete random matrix ensembles, though, the above argument breaks down, even though general universality heuristics predict that the statistics of discrete ensembles should behave similarly to those of continuous ensembles. A model case here is the adjacency matrix 
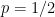
Our argument works for more general Wigner-type matrix ensembles, but for sake of illustration we will stick with the Erdös-Renyi case. Previous work on local universality for such matrix models (e.g. the work of Erdos, Knowles, Yau, and Yin) was able to show that any individual eigenvalue gap 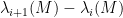
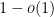
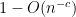
Our argument in fact gives simplicity of the spectrum with probability 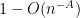
The basic idea of argument can be sketched as follows. Suppose that 

for a random 
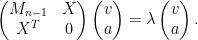
Extracting the top
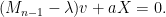
If we let 
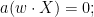
we typically expect
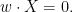
In other words, in order for
Perhaps the most important structural result about general large dense graphs is the Szemerédi regularity lemma. Here is a standard formulation of that lemma:
Lemma 1 (Szemerédi regularity lemma) Let
be a graph on
. Then there exists a partition
for some
with the property that for all but at most
of the pairs
, the pair
is
-regular in the sense that
whenever
are such that
and
, and
is the edge density between
for all

There are many proofs of this lemma, which is actually not that difficult to establish; see for instance these previous blog posts for some examples. In this post I would like to record one further proof, based on the spectral decomposition of the adjacency matrix of 
For reasons of exposition, it is convenient to first establish a slightly weaker form of the lemma, in which one drops the hypothesis of equitability (but then has to weight the cells 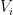
Lemma 2 (Szemerédi regularity lemma, weakened variant) . Let
outside of an exceptional set
, one has
whenever
, where
is the number of edges between
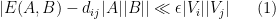

Let us now prove Lemma 2. We enumerate 



for some orthonormal basis 
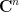
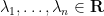

We can compute the trace of 

 , so
, so 
Among other things, this implies that

for all 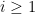
Let 
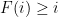
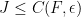
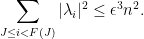
(Indeed, the bound on 



where 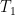
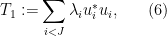
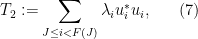
and 
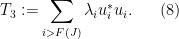
We now design a vertex partition to make 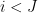




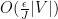

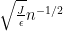

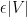



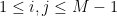
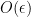
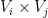

for any 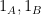
Next, we observe from (3) and (7) that 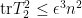
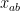
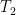
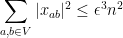
and hence by Markov’s inequality we have

for all pairs 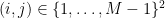
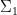
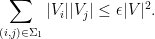

for any
Finally, to control 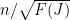
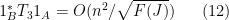
for any 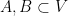
Let 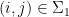
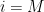

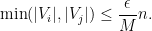
One easily verifies that (2) holds. If

for all 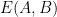
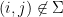
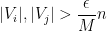
and so (since
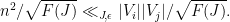
If we let
To prove Lemma 1, one argues similarly (after modifying 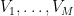
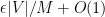
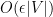
Remark 1 It is easy to verify that
essentially gives the weak regularity lemma of Frieze and Kannan.
Remark 2 If we specialise to a Cayley graph, in which
is a finite abelian group and
for some (symmetric) subset
of
Remark 3 The use of spectral theory here is parallel to the use of Fourier analysis to establish results such as Roth’s theorem on arithmetic progressions of length three. In analogy with this, one could view hypergraph regularity as being a sort of “higher order spectral theory”, although this spectral perspective is not as convenient as it is in the graph case.
Van Vu and I have just uploaded to the arXiv our paper Random matrices: Sharp concentration of eigenvalues, submitted to the Electronic Journal of Probability. As with many of our previous papers, this paper is concerned with the distribution of the eigenvalues 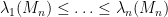
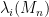


If we normalise the entries of the matrix 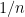

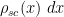
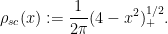
An essentially equivalent way of saying this is that for large ![{\gamma_i \in [-2,2]}](https://s0.wp.com/latex.php?latex=%7B%5Cgamma_i+%5Cin+%5B-2%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

In particular, from the Wigner semicircle law it can be shown that asymptotically almost surely, one has
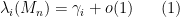
for all 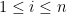
In the modern study of the spectrum of Wigner matrices (and in particular as a key tool in establishing universality results), it has become of interest to improve the error term in (1) as much as possible. A typical early result in this direction was by Bai, who used the Stieltjes transform method to obtain polynomial convergence rates of the shape 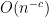
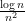
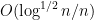

A significant advance in this direction was achieved by Erdos, Schlein, and Yau in a series of papers where they used a combination of Stieltjes transform and concentration of measure methods to obtain local semicircle laws which showed, among other things, that one had asymptotics of the form
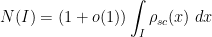
with exponentially high probability for intervals 


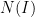
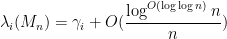
in the bulk with exponentially high probability, for Wigner matrices obeying some exponential decay conditions on the entries. This was achieved by a rather delicate high moment calculation, in which the contribution of the diagonal entries of the resolvent (whose average forms the Stieltjes transform) was shown to mostly cancel each other out.
As the GUE computations show, this concentration result is sharp up to the quasilogarithmic factor 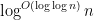
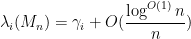
with exponentially high probability (see the paper for a more precise statement of results). The one catch is that an additional hypothesis is required, namely that the entries of the Wigner matrix have vanishing third moment. We also obtain similar results for the edge of the spectrum (but with a different scaling).
Our arguments are rather different from those of Erdos, Yau, and Yin, and thus provide an alternate approach to establishing eigenvalue concentration. The main tool is the Lindeberg exchange strategy, which is also used to prove the Four Moment Theorem (although we do not directly invoke the Four Moment Theorem in our analysis). The main novelty is that this exchange strategy is now used to establish large deviation estimates (i.e. exponentially small tail probabilities) rather than universality of the limiting distribution. Roughly speaking, the basic point is as follows. The Lindeberg exchange strategy seeks to compare a function 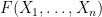
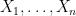
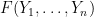
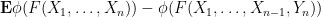
for various smooth test functions 
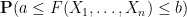
for various thresholds 
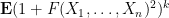
for various moderately large 
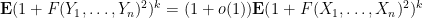
after performing all the relevant exchanges. As such, one can then use large deviation estimates on
In this paper we also take advantage of a simplification, first noted by Erdos, Yau, and Yin, that Four Moment Theorems become somewhat easier to prove if one works with resolvents 

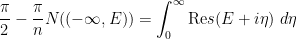
for any energy level 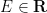


Van Vu and I have just uploaded to the arXiv our paper “Random matrices: Localization of the eigenvalues and the necessity of four moments“, submitted to Probability Theory and Related Fields. This paper concerns the distribution of the eigenvalues

of a Wigner random matrix 
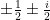
The most fundamental theorem about the distribution of these eigenvalues is the Wigner semi-circular law, which asserts that (almost surely) one has
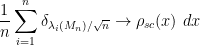
(in the vague topology) where 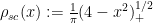
One can phrase this law in a number of equivalent ways. For instance, in the bulk region 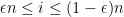
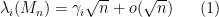
uniformly for in 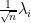

The bound (1) also holds in the edge case (by using the operator norm bound 
From (1) we see that the semicircular law controls the eigenvalues at the coarse scale of 
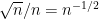

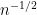


It is natural to ask whether these moment conditions are necessary. From the result of Erdos, Ramirez, Schlein, Vu, Yau, and myself, it is known that to control the eigenvalue spacing 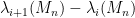
The main result of this paper is to show that this is not the case; that at the critical scale
Heuristically, the reason for this is easy to explain. One begins with an inspection of the expected fourth moment
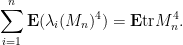
A standard moment method computation shows that the right hand side is equal to
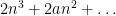
where 

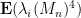

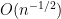
To make this rigorous, one needs a sufficiently strong concentration of measure result for 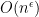
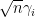
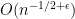
As it turns out, the first two concentration results are not sufficient to justify the previous heuristic argument. The Erdos-Yau-Yin argument suffices, but requires a log-Sobolev hypothesis. In our paper, we argue differently, using the three moment theorem (together with the theory of the eigenvalues of GUE, which is extremely well developed) to show that the variance of each individual 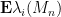
One curious feature of the analysis is how differently the median and the mean of the eigenvalue 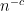
Van Vu and I have just uploaded to the arXiv our paper “Random matrices: universality of local eigenvalue statistics“, submitted to Acta Math.. This paper concerns the eigenvalues 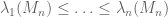


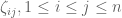
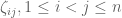
- The Gaussian Unitary Ensemble (GUE), in which the upper-triangular entries
are complex gaussian, and the diagonal entries
are real gaussians;
- The Gaussian Orthogonal Ensemble (GOE), in which all entries are real gaussian;
- The Bernoulli Ensemble, in which all entries take values
(with equal probability of each).
We will make a further distinction into Wigner real symmetric matrices (which are Wigner matrices with real coefficients, such as GOE and the Bernoulli ensemble) and Wigner Hermitian matrices (which are Wigner matrices whose upper-triangular coefficients have real and imaginary parts iid, such as GUE).
The GUE and GOE ensembles have a rich algebraic structure (for instance, the GUE distribution is invariant under conjugation by unitary matrices, while the GOE distribution is similarly invariant under conjugation by orthogonal matrices, hence the terminology), and as a consequence their eigenvalue distribution can be computed explicitly. For instance, the joint distribution of the eigenvalues 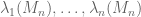
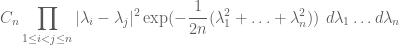
for some explicitly computable constant 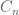
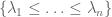

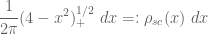
as 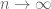
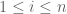
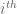
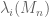
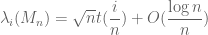
with probability 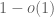
![t(a) \in [-2,2]](https://s0.wp.com/latex.php?latex=t%28a%29+%5Cin+%5B-2%2C2%5D&bg=ffffff&fg=545454&s=0&c=20201002)

Furthermore, the distribution of the normalised eigenvalue spacing 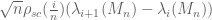



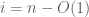
It has been widely believed that these GUE facts enjoy a universality property, in the sense that they should also hold for wide classes of other matrix models. In particular, Wigner matrices should enjoy the same bulk distribution (1), the same asymptotic law (2) for individual eigenvalues, and the same sine kernel statistics as GUE. (The statistics for Wigner symmetric matrices are slightly different, and should obey GOE statistics rather than GUE ones.)
There has been a fair body of evidence to support this belief. The bulk distribution (1) is in fact valid for all Wigner matrices (a result of Pastur, building on the original work of Wigner of course). The Tracy-Widom statistics on the edge were established for all Wigner Hermitian matrices (assuming that the coefficients had a distribution which was symmetric and decayed exponentially) by Soshnikov (with some further refinements by Soshnikov and Peche). Soshnikov’s arguments were based on an advanced version of the moment method.
The sine kernel statistics were established by Johansson for Wigner Hermitian matrices which were gaussian divisible, which means that they could be expressed as a non-trivial linear combination of another Wigner Hermitian matrix and an independent GUE. (Basically, this means that distribution of the coefficients is a convolution of some other distribution with a gaussian. There were some additional technical decay conditions in Johansson’s work which were removed in subsequent work of Ben Arous and Peche.) Johansson’s work was based on an explicit formula for the joint distribution for gauss divisible matrices that generalises (0) (but is significantly more complicated).
Just last week, Erdos, Ramirez, Schlein, and Yau established sine kernel statistics for Wigner Hermitian matrices with exponential decay and a high degree of smoothness (roughly speaking, they require control of up to six derivatives of the Radon-Nikodym derivative of the distribution). Their method is based on an analysis of the dynamics of the eigenvalues under a smooth transition from a general Wigner Hermitian matrix to GUE, essentially a matrix version of the Ornstein-Uhlenbeck process, whose eigenvalue dynamics are governed by Dyson Brownian motion.
In my paper with Van, we establish similar results to that of Erdos et al. under slightly different hypotheses, and by a somewhat different method. Informally, our main result is as follows:
Theorem 1. (Informal version) Suppose
is a Wigner Hermitian matrix whose coefficients have an exponentially decaying distribution, and whose real and imaginary parts are supported on at least three points (basically, this excludes Bernoulli-type distributions only) and have vanishing third moment (which is for instance the case for symmetric distributions). Then one has the local statistics (2) (but with an error term of
for any
rather than
) and the sine kernel statistics for individual eigenvalue spacings
If one removes the vanishing third moment hypothesis, one still has the sine kernel statistics provided one averages over all i.
There are analogous results for Wigner real symmetric matrices (see paper for details). There are also some related results, such as a universal distribution for the least singular value of matrices of the form in Theorem 1, and a crude asymptotic for the determinant (in particular, 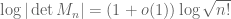
The arguments are based primarily on the Lindeberg replacement strategy, which Van and I also used to obtain universality for the circular law for iid matrices, and for the least singular value for iid matrices, but also rely on other tools, such as some recent arguments of Erdos, Schlein, and Yau, as well as a very useful concentration inequality of Talagrand which lets us tackle both discrete and continuous matrix ensembles in a unified manner. (I plan to talk about Talagrand’s inequality in my next blog post.)
I was asked recently (in relation to my recent work with Van Vu on the spectral theory of random matrices) to explain some standard heuristics regarding how the eigenvalues 
- For normal matrices (and in particular, unitary or self-adjoint matrices), eigenvalues are very stable under small perturbations. For more general matrices, eigenvalues can become unstable if there is pseudospectrum present.
- For self-adjoint (Hermitian) matrices, eigenvalues that are too close together tend to repel quickly from each other under such perturbations. For more general matrices, eigenvalues can either be repelled or be attracted to each other, depending on the type of perturbation.
In this post I would like to briefly explain why these heuristics are plausible.

Recent Comments