
You are currently browsing the monthly archive for November 2013.
This is the second thread for the Polymath8b project to obtain new bounds for the quantity
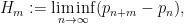
either for small values of 
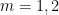
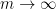
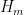
- (Maynard)
.
- (Polymath8b, tentative)
.
- (Polymath8b, tentative)
for sufficiently large
- (Maynard) Assuming the Elliott-Halberstam conjecture,
,
, and
.
Following the strategy of Maynard, the bounds on
- Distribution estimates
or
for the primes (or related objects);
- Bounds for the minimal diameter
of an admissible
-tuple;
- Lower bounds for the optimal value
to a certain variational problem;
- Sieve-theoretic arguments to convert the previous three ingredients into a bound on
Accordingly, the most natural routes to improve the bounds on
Ingredient 1 was studied intensively in Polymath8a. The following results are known or conjectured (see the Polymath8a paper for notation and proofs):
- (Bombieri-Vinogradov)
.
- (Polymath8a)
.
- (Polymath8a, tentative)
.
- (Elliott-Halberstam conjecture)
.
Ingredient 2 was also studied intensively in Polymath8a, and is more or less a solved problem for the values of 

For Ingredient 3, the basic variational problem is to understand the quantity

for 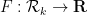
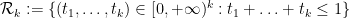
with 

and

Equivalently, one has

where 

so 

![{[0,1]^k}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5Ek%7D&bg=ffffff&fg=000000&s=0&c=20201002)
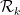

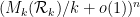
We now have a fairly good asymptotic understanding of

holding for sufficiently large
For Ingredient 4, the basic tool is this:
 , then
, then 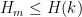 .
.
Thus, for instance, it is known that 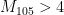


We have a number of ways to relax the hypotheses of this result, which we also summarise below the fold.
For each natural number
where 

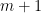
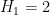
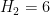
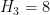


In 2004, Goldston, Pintz, and Yildirim established the bound 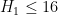
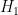
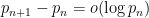
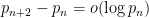
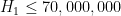

With the very recent preprint of James Maynard, we have the following further substantial improvements:
Theorem 1 (Maynard’s theorem) Unconditionally, we have the following bounds:
for an absolute constant
and any
.
If one assumes the Elliott-Halberstam conjecture, we have the following improved bounds:
for an absolute constant
The final conclusion 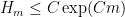


The arguments of Maynard avoid using the difficult partial results on (weakened forms of) the Elliott-Halberstam conjecture that were established by Zhang and then refined by Polymath8; instead, the main input is the classical Bombieri-Vinogradov theorem, combined with a sieve that is closer in spirit to an older sieve of Goldston and Yildirim, than to the sieve used later by Goldston, Pintz, and Yildirim on which almost all subsequent work is based.
The aim of the Polymath8b project is to obtain improved bounds on 
It’s time to (somewhat belatedly) roll over the previous thread on writing the first paper from the Polymath8 project, as this thread is overflowing with comments. We are getting near the end of writing this large (173 pages!) paper, establishing a bound of 4,680 on the gap between primes, with only a few sections left to thoroughly proofread (and the last section should probably be removed, with appropriate changes elsewhere, in view of the more recent progress by Maynard). As before, one can access the working copy of the paper at this subdirectory, as well as the rest of the directory, and the plan is to submit the paper to Algebra and Number theory (and the arXiv) once there is consensus to do so. Even before this paper was submitted, it already has had some impact; Andrew Granville’s exposition of the bounded gaps between primes story for the Bulletin of the AMS follows several of the Polymath8 arguments in deriving the result.
After this paper is done, there is interest in continuing onwards with other Polymath8 – related topics, and perhaps it is time to start planning for them. First of all, we have an invitation from the Newsletter of the European Mathematical Society to discuss our experiences and impressions with the project. I think it would be interesting to collect some impressions or thoughts (both positive and negative) from people who were highly active in the research and/or writing aspects of the project, as well as from more casual participants who were following the progress more quietly. This project seemed to attract a bit more attention than most other polymath projects (with the possible exception of the very first project, Polymath1). I think there are several reasons for this; the project builds upon a recent breakthrough (Zhang’s paper) that attracted an impressive amount of attention and publicity; the objective is quite easy to describe, when compared against other mathematical research objectives; and one could summarise the current state of progress by a single natural number H, which implied by infinite descent that the project was guaranteed to terminate at some point, but also made it possible to set up a “scoreboard” that could be quickly and easily updated. From the research side, another appealing feature of the project was that – in the early stages of the project, at least – it was quite easy to grab a new world record by means of making a small observation, which made it fit very well with the polymath spirit (in which the emphasis is on lots of small contributions by many people, rather than a few big contributions by a small number of people). Indeed, when the project first arose spontaneously as a blog post of Scott Morrrison over at the Secret Blogging Seminar, I was initially hesitant to get involved, but soon found the “game” of shaving a few thousands or so off of 
Then of course there is the “Polymath 8b” project in which we build upon the recent breakthroughs of James Maynard, which have simplified the route to bounded gaps between primes considerably, bypassing the need for any Elliott-Halberstam type distribution results beyond the Bombieri-Vinogradov theorem. James has kindly shown me an advance copy of the preprint, which should be available on the arXiv in a matter of days; it looks like he has made a modest improvement to the previously announced results, improving 
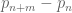




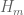
The classical foundations of probability theory (discussed for instance in this previous blog post) is founded on the notion of a probability space 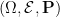


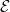
![{{\bf P}: {\cal E} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+P%7D%3A+%7B%5Ccal+E%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
One can generalise the concept of a probability space to a finitely additive probability space, in which the event space 
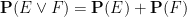
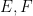
In this post I would like to describe a further weakening of probability theory, which I will call qualitative probability theory, in which one does not assign a precise numerical probability value 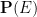
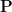
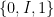


The main reason I want to introduce this weak notion of probability theory is that it becomes suited to talk about random variables living inside algebraic varieties, even if these varieties are defined over fields other than 




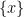
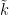
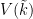

It turns out that just as qualitative random variables may be used to interpret the concept of a generic point, they can also be used to interpret the concept of a type in model theory; the type of a random variable 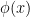
One of the basic tools in modern combinatorics is the probabilistic method, introduced by Erdos, in which a deterministic solution to a given problem is shown to exist by constructing a random candidate for a solution, and showing that this candidate solves all the requirements of the problem with positive probability. When the problem requires a real-valued statistic 
Proposition 1 (Comparison with mean) Let
is finite. Then
with positive probability, and
with positive probability.
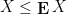
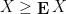
This proposition is usually applied in conjunction with a computation of the first moment
As a typical example in random matrix theory, if one wanted to understand how small or how large the operator norm 

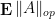

Recently, in their proof of the Kadison-Singer conjecture (and also in their earlier paper on Ramanujan graphs), Marcus, Spielman, and Srivastava introduced an striking new variant of the first moment method, suited in particular for controlling the operator norm 



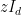


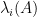

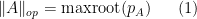
where 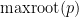

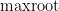
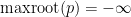
Prior to the work of Marcus, Spielman, and Srivastava, I think it is safe to say that the conventional wisdom in random matrix theory was that the representation (1) of the operator norm 

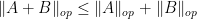
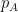
Proposition 2 (Comparison with mean) Let
. Let
of independent Hermitian rank one
, each taking a finite number of values. Then
with positive probability, and
with positive probability.
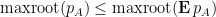
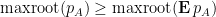
We prove this proposition below the fold. The hypothesis that each 
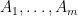
Proposition 3 (Deterministic multilinearisation formula) Let
for all
, where the mixed characteristic polynomial
of any
 \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++p_A%28z%29+%3D+%5Cmu%5BA_1%2C%5Cldots%2CA_m%5D%28z%29+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
 \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmu%5BA_1%2C%5Cldots%2CA_m%5D%28z%29+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
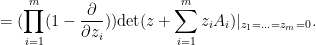
Among other things, this formula gives a useful representation of the mean characteristic polynomial 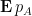
Corollary 4 (Random multilinearisation formula) Let
for all
.
 \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D+p_A%28z%29+%3D+%5Cmu%5B+%5Cmathop%7B%5Cbf+E%7D+A_1%2C+%5Cldots%2C+%5Cmathop%7B%5Cbf+E%7D+A_m+%5D%28z%29+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: For fixed 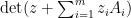

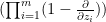

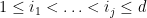
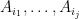

In view of Proposition 2, we can now hope to control the operator norm
Theorem 5 (Marcus-Spielman-Srivastava theorem) Let
be jointly independent random vectors in
, with each
taking a finite number of values. Suppose that we have the normalisation
where we are using the convention that
is the
for some
and all
. Then one has
with positive probability.
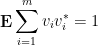
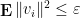
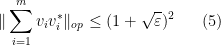
Note that the upper bound in (5) must be at least 

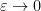
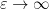
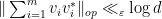
In the paper of Marcus, Spielman and Srivastava, Theorem 5 is used to deduce a conjecture 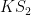
Let us now summarise how Theorem 5 is proven. In the spirit of semi-definite programming, we rephrase the above theorem in terms of the rank one Hermitian positive semi-definite matrices 
Theorem 6 (Marcus-Spielman-Srivastava theorem again) Let
has mean
and such that
for some
with positive probability.

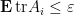
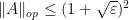
In view of (1) and Proposition 2, this theorem follows from the following control on the mean characteristic polynomial:
Theorem 7 (Control of mean characteristic polynomial) Let
and such that
for some

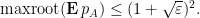
This result is proven using the multilinearisation formula (Corollary 4) and some convexity properties of real stable polynomials; we give the proof below the fold.
Thanks to Adam Marcus, Assaf Naor and Sorin Popa for many useful explanations on various aspects of the Kadison-Singer problem.

Recent Comments