
You are currently browsing the monthly archive for January 2018.
This is the first official “research” thread of the Polymath15 project to upper bound the de Bruijn-Newman constant 
The proposal naturally splits into at least three separate (but loosely related) topics:
- Numerical computation of the entire functions
, with the ultimate aim of establishing zero-free regions of the form
for various
.
- Improved understanding of the dynamics of the zeroes
of
.
- Establishing the zero-free nature of
when
and
is sufficiently large depending on
and
.
Below the fold, I will present each of these topics in turn, to initiate further discussion in each of them. (I thought about splitting this post into three to have three separate discussions, but given the current volume of comments, I think we should be able to manage for now having all the comments in a single post. If this changes then of course we can split up some of the discussion later.)
To begin with, let me present some formulae for computing

where

is a variant of the Jacobi theta function. We observe that 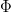

as 


In my previous paper with Brad, we used this representation, combined with Fubini’s theorem to swap the sum and integral, to obtain a useful series representation for 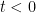
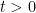



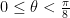
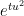
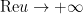



Splitting the horizontal line from 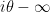
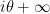
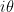
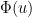

Using the functional equation 

where

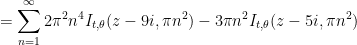
where 
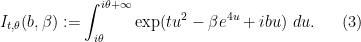
The formula (2) is valid for any 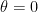
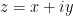


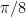



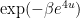

Building on the interest expressed in the comments to this previous post, I am now formally proposing to initiate a “Polymath project” on the topic of obtaining new upper bounds on the de Bruijn-Newman constant
De Bruijn introduced a family 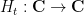

where

As discussed in this previous post, the Riemann hypothesis is equivalent to the assertion that all the zeroes of 
De Bruijn and Newman showed that there existed a real constant 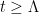
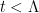
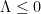
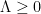
As for upper bounds, de Bruijn showed back in 1950 that 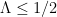


In addition to the primary goal, one could envisage some related secondary goals of the project, such as a better understanding (both analytic and numerical) of the functions
I think there is a plausible plan of attack on this project that proceeds as follows. Firstly, there are results going back to the original work of de Bruijn that demonstrate that the zeroes of 
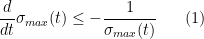
whenever 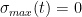
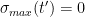
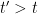
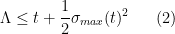
for any real number 
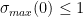




Secondly, the work of Ki, Kim and Lee (based on an analysis of the various terms appearing in the expression for 


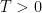

If so, this suggests a possible strategy to get a new upper bound on
- Select a good choice of parameters
.
- By refining the Ki-Kim-Lee analysis, find an explicit
- By a numerical computation (e.g. using the argument principle), also verify that zeroes of
- Combining these facts, we obtain that
; hopefully, one can insert this into (2) and get a new upper bound for
Of course, there may also be alternate strategies to upper bound
One appealing thing about the above strategy for the purposes of a polymath project is that it naturally splits the project into several interacting but reasonably independent parts: an analytic part in which one tries to refine the Ki-Kim-Lee analysis (based on explicitly upper and lower bounding various terms in a certain series expansion for
The project also resembles Polymath8 in another aspect: that there is an obvious way to numerically measure progress, by seeing how the upper bound for 
Some Polymath projects have been known for a breakneck pace, making it hard for some participants to keep up. It’s hard to control these things, but I am envisaging a relatively leisurely project here, perhaps taking the full year mentioned above. It may well be that as the project matures we will largely be waiting for the results of lengthy numerical calculations to come in, for instance. Of course, as with previous projects, we would maintain some wiki pages (and possibly some other resources, such as a code repository) to keep track of progress and also to summarise what we have learned so far. For instance, as was done with some previous Polymath projects, we could begin with some “online reading seminars” where we go through some relevant piece of literature (most obviously the Ki-Kim-Lee paper, but there may be other resources that become relevant, e.g. one could imagine the literature on numerical verification of RH to be of value).
One could also imagine some incidental outcomes of this project, such as a more efficient way to numerically establish zero free regions for various analytic functions of interest; in particular, the project may well end up focusing on some other aspect of mathematics than the specific questions posed here.
Anyway, I would be interested to hear in the comments below from others who might be interested in participating, or at least observing, this project, particularly if they have suggestions regarding the scope and direction of the project, and on organisational structure (e.g. if one should start with reading seminars, or some initial numerical exploration of the functions
In this post we assume the Riemann hypothesis and the simplicity of zeroes, thus the zeroes of 

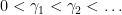
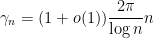
as 
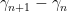
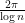
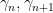
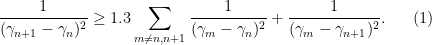
The specific value of constant 
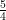

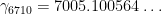
discovered by Lehmer. It follows easily from the main results of Csordas, Smith, and Varga that if an infinite number of Lehmer pairs (in the above sense) existed, then the de Bruijn-Newman constant
In this post, I sketch an argument that Brad and I came up with (as initially suggested by Odlyzko) the GUE hypothesis implies the existence of infinitely many Lehmer pairs. We argue probabilistically: pick a sufficiently large number 
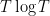

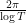
Introduce the renormalised ordinates 
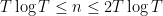


![\displaystyle 1.3 \sum_{m \in [T \log T, 2T \log T]: m \neq n,n+1} \frac{1}{(x_m - x_n)^2} + \frac{1}{(x_m - x_{n+1})^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+1.3+%5Csum_%7Bm+%5Cin+%5BT+%5Clog+T%2C+2T+%5Clog+T%5D%3A+m+%5Cneq+n%2Cn%2B1%7D+%5Cfrac%7B1%7D%7B%28x_m+-+x_n%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7B%28x_m+-+x_%7Bn%2B1%7D%29%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
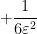
(say) with probability 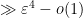

![{[T \log T, 2T \log T]}](https://s0.wp.com/latex.php?latex=%7B%5BT+%5Clog+T%2C+2T+%5Clog+T%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
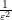

As one consequence of the GUE hypothesis, we have 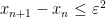
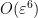
![{E := \{ m \in [T \log T, 2T \log T]: x_{m+1} - x_m \leq \varepsilon^2 \}}](https://s0.wp.com/latex.php?latex=%7BE+%3A%3D+%5C%7B+m+%5Cin+%5BT+%5Clog+T%2C+2T+%5Clog+T%5D%3A+x_%7Bm%2B1%7D+-+x_m+%5Cleq+%5Cvarepsilon%5E2+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

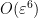
![\displaystyle \sup_{h \geq 1} | \# E \cap [n+h, n-h] | \leq \frac{1}{10}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%7Bh+%5Cgeq+1%7D+%7C+%5C%23+E+%5Ccap+%5Bn%2Bh%2C+n-h%5D+%7C+%5Cleq+%5Cfrac%7B1%7D%7B10%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
which implies in particular that
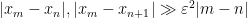
for all ![{m \in [T \log T, 2 T \log T] \backslash \{ n, n+1\}}](https://s0.wp.com/latex.php?latex=%7Bm+%5Cin+%5BT+%5Clog+T%2C+2+T+%5Clog+T%5D+%5Cbackslash+%5C%7B+n%2C+n%2B1%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \sum_{m \in [T \log T, 2T \log T]: |m-n| \geq \varepsilon^{-3}} \frac{1}{(x_m - x_n)^2} + \frac{1}{(x_m - x_{n+1})^2} \ll \varepsilon^{-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bm+%5Cin+%5BT+%5Clog+T%2C+2T+%5Clog+T%5D%3A+%7Cm-n%7C+%5Cgeq+%5Cvarepsilon%5E%7B-3%7D%7D+%5Cfrac%7B1%7D%7B%28x_m+-+x_n%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7B%28x_m+-+x_%7Bn%2B1%7D%29%5E2%7D+%5Cll+%5Cvarepsilon%5E%7B-1%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and so it will suffice to show that
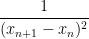
![\displaystyle \geq 1.3 \sum_{m \in [T \log T, 2T \log T]: m \neq n,n+1; |m-n| < \varepsilon^{-3}} \frac{1}{(x_m - x_n)^2} + \frac{1}{(x_m - x_{n+1})^2} + \frac{1}{5\varepsilon^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cgeq+1.3+%5Csum_%7Bm+%5Cin+%5BT+%5Clog+T%2C+2T+%5Clog+T%5D%3A+m+%5Cneq+n%2Cn%2B1%3B+%7Cm-n%7C+%3C+%5Cvarepsilon%5E%7B-3%7D%7D+%5Cfrac%7B1%7D%7B%28x_m+-+x_n%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7B%28x_m+-+x_%7Bn%2B1%7D%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7B5%5Cvarepsilon%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
(say) with probability
By the GUE hypothesis (and the fact that 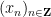


with probability 
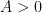



![\displaystyle {\bf E} N_{[-\varepsilon,0]} N_{[0,\varepsilon]} \gg \varepsilon^4](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+%5Cgg+%5Cvarepsilon%5E4+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf E} N_{[-\varepsilon,0]} \binom{N_{[0,\varepsilon]}}{2} \ll \varepsilon^7](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+%5Cbinom%7BN_%7B%5B0%2C%5Cvarepsilon%5D%7D%7D%7B2%7D+%5Cll+%5Cvarepsilon%5E7+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf E} \binom{N_{[-\varepsilon,0]}}{2} N_{[0,\varepsilon]} \ll \varepsilon^7](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+%5Cbinom%7BN_%7B%5B-%5Cvarepsilon%2C0%5D%7D%7D%7B2%7D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+%5Cll+%5Cvarepsilon%5E7+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf E} N_{[-\varepsilon,0]} N_{[0,\varepsilon]} N_{[\varepsilon,A^{-1}]} \ll A^{-3} \varepsilon^4](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+N_%7B%5B%5Cvarepsilon%2CA%5E%7B-1%7D%5D%7D+%5Cll+A%5E%7B-3%7D+%5Cvarepsilon%5E4+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf E} N_{[-\varepsilon,0]} N_{[0,\varepsilon]} N_{[-A^{-1}, -\varepsilon]} \ll A^{-3} \varepsilon^4](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+N_%7B%5B-A%5E%7B-1%7D%2C+-%5Cvarepsilon%5D%7D+%5Cll+A%5E%7B-3%7D+%5Cvarepsilon%5E4+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf E} N_{[-\varepsilon,0]} N_{[0,\varepsilon]} N_{[-k, k]}^2 \ll k^2 \varepsilon^4 \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+N_%7B%5B-k%2C+k%5D%7D%5E2+%5Cll+k%5E2+%5Cvarepsilon%5E4+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
for any natural number 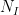

![{{\bf E} N_{[-\varepsilon,0]} \binom{N_{[0,\varepsilon]}}{2} }](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+E%7D+N_%7B%5B-%5Cvarepsilon%2C0%5D%7D+%5Cbinom%7BN_%7B%5B0%2C%5Cvarepsilon%5D%7D%7D%7B2%7D+%7D&bg=ffffff&fg=000000&s=0&c=20201002)
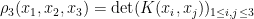

which can easily be estimated to be 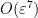
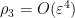
Since for natural numbers 
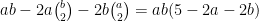
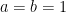
![{N_{[-\varepsilon,0]} = N_{[0,\varepsilon]} = 1}](https://s0.wp.com/latex.php?latex=%7BN_%7B%5B-%5Cvarepsilon%2C0%5D%7D+%3D+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+%3D+1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf P} ( N_{[\varepsilon,A^{-1}]} \geq 1 | E ) \ll A^{-3}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+P%7D+%28+N_%7B%5B%5Cvarepsilon%2CA%5E%7B-1%7D%5D%7D+%5Cgeq+1+%7C+E+%29+%5Cll+A%5E%7B-3%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf P} ( N_{[-A^{-1}, -\varepsilon]} \geq 1 | E ) \ll A^{-3}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+P%7D+%28+N_%7B%5B-A%5E%7B-1%7D%2C+-%5Cvarepsilon%5D%7D+%5Cgeq+1+%7C+E+%29+%5Cll+A%5E%7B-3%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\bf P} ( N_{[-k, k]} \geq A k^{5/3} | E ) \ll A^{-4} k^{-4/3}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+P%7D+%28+N_%7B%5B-k%2C+k%5D%7D+%5Cgeq+A+k%5E%7B5%2F3%7D+%7C+E+%29+%5Cll+A%5E%7B-4%7D+k%5E%7B-4%2F3%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and thus, if
![\displaystyle N_{[-\varepsilon,0]}, N_{[0,\varepsilon]} = 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++N_%7B%5B-%5Cvarepsilon%2C0%5D%7D%2C+N_%7B%5B0%2C%5Cvarepsilon%5D%7D+%3D+1&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle N_{[A^{-1}, \varepsilon]} = N_{[\varepsilon, A^{-1}]} = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++N_%7B%5BA%5E%7B-1%7D%2C+%5Cvarepsilon%5D%7D+%3D+N_%7B%5B%5Cvarepsilon%2C+A%5E%7B-1%7D%5D%7D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)
and simultaneously that
![\displaystyle N_{[-k,k]} \leq A k^{5/3}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++N_%7B%5B-k%2Ck%5D%7D+%5Cleq+A+k%5E%7B5%2F3%7D&bg=ffffff&fg=000000&s=0&c=20201002)
for all natural numbers
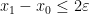
and
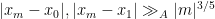
for all 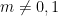
Remark 1 The above argument needed the GUE hypothesis for correlations up to fourth order (in order to establish (3)). It might be possible to reduce the number of correlations needed, but I do not see how to obtain the claim just using pair correlations only.
Brad Rodgers and I have uploaded to the arXiv our paper “The De Bruijn-Newman constant is non-negative“. This paper affirms a conjecture of Newman regarding to the extent to which the Riemann hypothesis, if true, is only “barely so”. To describe the conjecture, let us begin with the Riemann xi function
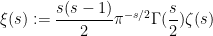
where 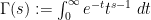
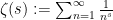
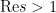
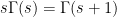

and hence
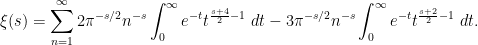
By a rescaling, one may write
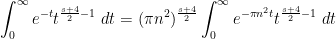
and similarly
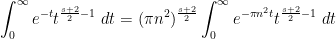
and thus (after applying Fubini’s theorem)
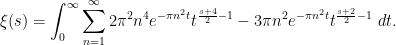
We’ll make the change of variables 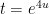

If we introduce the mild renormalisation

of 
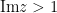
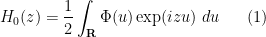
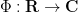 is the function
is the function 
which one can verify to be rapidly decreasing both as 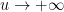

If we normalize the Fourier transform 

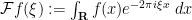
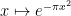
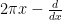
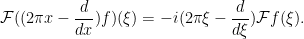
Since 

is its own Fourier transform. (One can view the polynomial 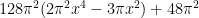

is also its own Fourier transform. Rescaling 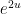

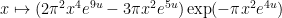
is

and hence by the Poisson summation formula (using symmetry and vanishing at 
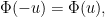
which implies that
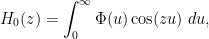
which now gives a convergent expression for the entire function 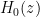



De Bruijn introduced the family 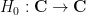

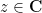
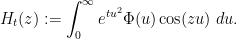
From a PDE perspective, one can view 



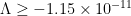
In this paper we finish off the proof of Newman’s conjecture, that is we show that 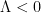
Very roughly, the argument proceeds as follows. As observed by Csordas, Smith, and Varga (and also discussed in this previous blog post, the backwards heat evolution of the 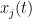
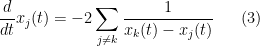
for all 
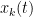
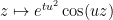
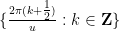
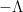
How does one obtain this convergence to local equilibrium? We proceed by broad analogy with the “local relaxation flow” method of Erdos, Schlein, and Yau in random matrix theory, in which one combines some initial control on zeroes (which, in the case of the Erdos-Schlein-Yau method, is referred to with terms such as “local semicircular law”) with convexity properties of a relevant Hamiltonian that can be used to force the zeroes towards equilibrium.
We first discuss the initial control on zeroes. For ![{[0,T]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2CT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
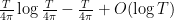
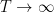
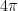
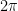

![{[T, T+\alpha]}](https://s0.wp.com/latex.php?latex=%7B%5BT%2C+T%2B%5Calpha%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
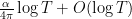
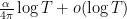

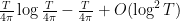
![{[T, T+\alpha \log T]}](https://s0.wp.com/latex.php?latex=%7B%5BT%2C+T%2B%5Calpha+%5Clog+T%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

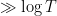
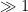

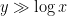
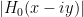

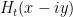
Once one has the initial control on zeroes, we now need to force convergence to local equilibrium by exploiting convexity of a Hamiltonian. Here, the relevant Hamiltonian is

ignoring for now the rather important technical issue that this sum is not actually absolutely convergent. (Because of this, we will need to truncate and renormalise the Hamiltonian in a number of ways which we will not detail here.) The ODE (3) is formally the gradient flow for this Hamiltonian. Furthermore, this Hamiltonian is a convex function of the 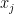
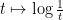
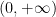
Formally, the derivative of the above Hamiltonian is
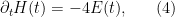
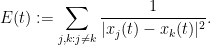
Again, there is the important technical issue that this quantity is infinite; but it turns out that if we renormalise the Hamiltonian appropriately, then the energy will also become suitably renormalised, and in particular will vanish when the 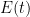
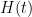
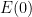
There are a number of technicalities involved in making the above sketch of argument rigorous (for instance, justifying interchanges of derivatives and infinite sums turns out to be a little bit delicate). I will highlight here one particular technical point. One of the ways in which we make expressions such as the energy 
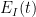
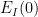
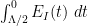


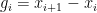
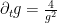
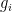
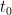
![{t \in [t_0-\delta, t_0]}](https://s0.wp.com/latex.php?latex=%7Bt+%5Cin+%5Bt_0-%5Cdelta%2C+t_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[t_0-\delta, t_0]}](https://s0.wp.com/latex.php?latex=%7B%5Bt_0-%5Cdelta%2C+t_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[\Lambda/2,0]}](https://s0.wp.com/latex.php?latex=%7B%5B%5CLambda%2F2%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

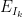
![{[t_k - \delta, t_k]}](https://s0.wp.com/latex.php?latex=%7B%5Bt_k+-+%5Cdelta%2C+t_k%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
ADDED LATER: the following analogy (involving functions with just two zeroes, rather than an infinite number of zeroes) may help clarify the relation between this result and the Riemann hypothesis (and in particular why this result does not make the Riemann hypothesis any easier to prove, in fact it confirms the delicate nature of that hypothesis). Suppose one had a quadratic polynomial 
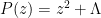
- (Riemann hypothesis false)
, and
off the real axis.
- (Riemann hypothesis true, but barely so)
, and both zeroes of
- (Riemann hypothesis true, with room to spare)
The analogue of our result in this case is that
The Polymath14 online collaboration has uploaded to the arXiv its paper “Homogeneous length functions on groups“, submitted to Algebra & Number Theory. The paper completely classifies homogeneous length functions 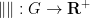




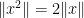

The proof is based on repeated use of the homogeneous length function axioms, combined with elementary identities of commutators, to obtain increasingly good bounds on quantities such as ![{\|[x,y]\|}](https://s0.wp.com/latex.php?latex=%7B%5C%7C%5Bx%2Cy%5D%5C%7C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As there are now a large number of comments on the previous post on this project, this post will also serve as the new thread for any final discussion of this project as it winds down.

Recent Comments