
You are currently browsing the monthly archive for November 2007.
In the previous post, I discussed how an induction on dimension approach could establish Hilbert’s nullstellensatz, which we interpreted as a result describing all the obstructions to solving a system of polynomial equations and inequations over an algebraically closed field. Today, I want to point out that exactly the same approach also gives the Hahn-Banach theorem (at least in finite dimensions), which we interpret as a result describing all the obstructions to solving a system of linear inequalities over the reals (or in other words, a linear programming problem); this formulation of the Hahn-Banach theorem is sometimes known as Farkas’ lemma. Then I would like to discuss some standard applications of the Hahn-Banach theorem, such as the separation theorem of Dieudonné, the minimax theorem of von Neumann, Menger’s theorem, and Helly’s theorem (which was mentioned recently in an earlier post).
I had occasion recently to look up the proof of Hilbert’s nullstellensatz, which I haven’t studied since cramming for my algebra qualifying exam as a graduate student. I was a little unsatisfied with the proofs I was able to locate – they were fairly abstract and used a certain amount of algebraic machinery, which I was terribly rusty on – so, as an exercise, I tried to find a more computational proof that avoided as much abstract machinery as possible. I found a proof which used only the extended Euclidean algorithm and high school algebra, together with an induction on dimension and the obvious observation that any non-zero polynomial of one variable on an algebraically closed field has at least one non-root. It probably isn’t new (in particular, it might be related to the standard model-theoretic proof of the nullstellensatz, with the Euclidean algorithm and high school algebra taking the place of quantifier elimination), but I thought I’d share it here anyway.
Throughout this post, F is going to be a fixed algebraically closed field (e.g. the complex numbers 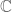
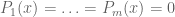
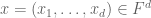
![P_1,\ldots,P_m \in F[x]](https://s0.wp.com/latex.php?latex=P_1%2C%5Cldots%2CP_m+%5Cin+F%5Bx%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![Q_1,\ldots,Q_m \in F[x]](https://s0.wp.com/latex.php?latex=Q_1%2C%5Cldots%2CQ_m+%5Cin+F%5Bx%5D&bg=ffffff&fg=545454&s=0&c=20201002)

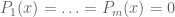
Weak nullstellensatz. Let
- The system of equations
.
- There exist polynomials
Note that the hypothesis that F is algebraically closed is crucial; for instance, if F is the reals, then the equation 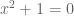
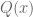

Like many results of the “The only obstructions are the obvious obstructions” type, the power of the nullstellensatz lies in the ability to take a hypothesis about non-existence (in this case, non-existence of solutions to 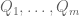
Now suppose one is trying to solve the more complicated system 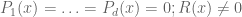

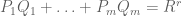
Strong nullstellensatz. Let
be polynomials. Then exactly one of the following statements holds:
- The system of equations
has a solution
- There exist polynomials
Of course, the weak nullstellensatz corresponds to the special case in which R=1. The strong nullstellensatz is usually phrased instead in terms of ideals and radicals, but the above formulation is easily shown to be equivalent to the usual version (modulo Hilbert’s basis theorem).
One could consider generalising the nullstellensatz a little further by considering systems of the form 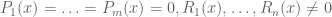

[Update, Nov 26: It turns out that my approach is more complicated than I first thought, and so I had to revise the proof quite a bit to fix a certain gap, in particular making it significantly messier than my first version. On the plus side, I was able to at least eliminate any appeal to Hilbert’s basis theorem, so in particular the proof is now manifestly effective (but with terrible bounds). In any case, I am keeping the argument here in case it has some interest.]
Ben Green and I have just uploaded our joint paper, “The distribution of polynomials over finite fields, with applications to the Gowers norms“, to the arXiv, and submitted to Contributions to Discrete Mathematics. This paper, which we first announced at the recent FOCS meeting, and then gave an update on two weeks ago on this blog, is now in final form. It is being made available simultaneously with a closely related paper of Lovett, Meshulam, and Samorodnitsky.
In the previous post on this topic, I focused on the negative results in the paper, and in particular the fact that the inverse conjecture for the Gowers norm fails for certain degrees in low characteristic. Today, I’d like to focus instead on the positive results, which assert that for polynomials in many variables over finite fields whose degree is less than the characteristic of the field, one has a satisfactory theory for the distribution of these polynomials. Very roughly speaking, the main technical results are:
- A regularity lemma: Any polynomial can be expressed as a combination of a bounded number of other polynomials which are regular, in the sense that no non-trivial linear combination of these polynomials can be expressed efficiently in terms of lower degree polynomials.
- A counting lemma: A regular collection of polynomials behaves as if the polynomials were selected randomly. In particular, the polynomials are jointly equidistributed.
I’m continuing my series of articles for the Princeton Companion to Mathematics with my article on compactness and compactification. This is a fairly recent article for the PCM, which is now at the stage in which most of the specialised articles have been written, and now it is the general articles on topics such as compactness which are being finished up. The topic of this article is self-explanatory; it is a brief and non-technical introduction as to the incredibly useful concept of compactness in topology, analysis, geometry, and other areas mathematics, and the closely related concept of a compactification, which allows one to rigorously take limits of what would otherwise be divergent sequences.
The PCM has an extremely broad scope, covering not just mathematics itself, but the context that mathematics is placed in. To illustrate this, I will mention Michael Harris‘s essay for the Companion, ““Why mathematics?”, you may ask“.
Today, Charlie wrapped up several loose ends in his lectures, including the connection with the classical Whitney extension theorem, the role of convex bodies and Whitney convexity, and a glimpse as to how one obtains the remarkably fast (almost linear time) algorithms in which one actually computes interpolation of functions from finite amounts of data.
On Thursday, Charlie Fefferman continued his lecture series on interpolation of functions. Here, he stated the main technical theorem about bundles that underlies all the results, answering the “cliffhanger” question from the last lecture, and broadly outlined the proof, except for a major technical wrinkle about “Whitney convexity” which he will discuss on Friday. Read the rest of this entry »
The first Distinguished Lecture Series at UCLA of this academic year is being given this week by my good friend and fellow Medalist Charlie Fefferman, who also happens to be my “older brother” (we were both students of Elias Stein). The theme of Charlie’s lectures is “Interpolation of functions on 
The general topic of extracting quantitative bounds from classical qualitative theorems is a subject that I am personally very fond of, and Charlie gave a wonderfully accessible presentation of the main results, though the actual details of the proofs were left to the next two lectures.
As usual, all errors and omissions here are my responsibility, and are not due to Charlie.
I’ve joined the inaugural editorial board for a new mathematical journal, Analysis & PDE. This journal is owned by Mathematical Sciences Publishers, a non-profit organisation dedicated to high-quality, low-cost, and broad-availability mathematical publishing, and run primarily by professional mathematicians. The scope of the journal is, of course, self-explanatory; MSP’s other journals have titles such as Geometry & Topology, Algebra & Number Theory, and Algebraic & Geometric Topology.
We’re just starting out (and haven’t even filled up our first issue yet), so we are looking for strong and significant submissions in all areas of analysis and PDE (broadly defined). If you have a good paper in these areas and are deciding on which journal to submit to, you might want to take a look at the submission guidelines for our journal. Of course, the papers are subject to the usual peer review process and will be held to high standards in order to be accepted.
[Update, Nov 11: Link fixed.]
Recently, I had tentatively announced a forthcoming result with Ben Green establishing the “Gowers inverse conjecture” (or more accurately, the “inverse conjecture for the Gowers uniformity norm”) for vector spaces 
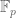

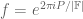
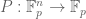
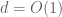
This conjecture can be informally stated as follows. By iterating the obvious fact that the derivative of a polynomial of degree at most d is a polynomial of degree at most d-1, we see that a function

for all 
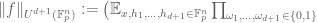

is equal to its maximal value of 1. The inverse conjecture for the Gowers norm, in its usual formulation, says that, more generally, if a function 

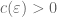
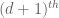
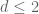
At the time of the announcement, our paper had not quite been fully written up. This turned out to be a little unfortunate, because soon afterwards we discovered that our arguments at one point had to go through a version of Newton’s interpolation formula, which involves a factor of d! in the denominator and so is only valid when the characteristic p of the field exceeds the degree. So our arguments in fact are only valid in the range 
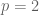

Recent Comments