
You are currently browsing the monthly archive for August 2019.
William Banks, Kevin Ford, and I have just uploaded to the arXiv our paper “Large prime gaps and probabilistic models“. In this paper we introduce a random model to help understand the connection between two well known conjectures regarding the primes 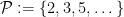
Conjecture 1 (Cramér conjecture) If
is a large number, then the largest prime gap
in
is of size
. (Granville refines this conjecture to
, where
. Here we use the asymptotic notation
for
,
for
,
for
, and
for
.)
Conjecture 2 (Hardy-Littlewood conjecture) If
are fixed distinct integers, then the number of numbers
with
all prime is
as
, where the singular series
is defined by the formula

(One can view these conjectures as modern versions of two of the classical Landau problems, namely Legendre’s conjecture and the twin prime conjecture respectively.)
A well known connection between the Hardy-Littlewood conjecture and prime gaps was made by Gallagher. Among other things, Gallagher showed that if the Hardy-Littlewood conjecture was true, then the prime gaps 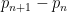
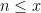
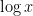
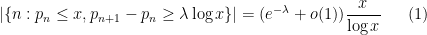
as 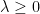
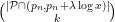
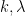

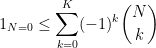
when 
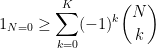
when 

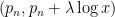
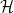

![{[0, \lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C+%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Heuristically, if one extrapolates the asymptotic (1) to the regime 


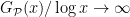


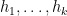
Theorem 3 (Large gaps from Hardy-Littlewood, rough statement)
- If the Hardy-Littlewood conjecture is uniformly true for
, and with shifts
, with a power savings in the error term, then
.
- If the Hardy-Littlewood conjecture is “true on average” for
and shifts
for all
, with a power savings in the error term, then
.
In particular, we can recover Cramer’s conjecture given a sufficiently powerful version of the Hardy-Littlewood conjecture “on the average”.
Our proof of this theorem proceeds more or less along the same lines as Gallagher’s calculation, but now with 

of the singular series, for a suitable cutoff 


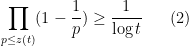
(this is well defined for 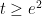
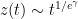
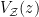

where 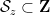
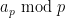
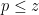
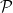
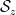
The proof of Theorem 3 ended up not using any properties of the set of primes
This line of inquiry was started by Cramér, who introduced what we now call the Cramér random model 
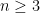
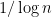
![\displaystyle | {\mathcal C} \cap [1,x] | = \int_2^x \frac{dt}{\log t} + O( x^{1/2+o(1)})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C+%7B%5Cmathcal+C%7D+%5Ccap+%5B1%2Cx%5D+%7C+%3D+%5Cint_2%5Ex+%5Cfrac%7Bdt%7D%7B%5Clog+t%7D+%2B+O%28+x%5E%7B1%2F2%2Bo%281%29%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
and Cramér also showed that the largest gap 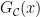


Granville proposed a refinement 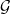
![{[x,2x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C2x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
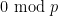

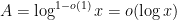

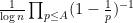
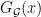

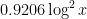
However, Granville’s model does not produce a power savings in the error term of the Hardy-Littlewood conjectures, mostly due to the need to truncate the singular series at the logarithmic cutoff 
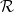
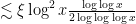


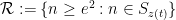
with
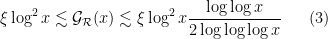
and that the Hardy-Littlewood conjectures hold with power savings for 

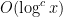
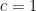
![{[0,y]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The probabilistic analysis of 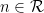
![{n \in [0,y]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5B0%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
I’ve just uploaded to the arXiv my paper “Quantitative bounds for critically bounded solutions to the Navier-Stokes equations“, submitted to the proceedings of the Linde Hall Inaugural Math Symposium. (I unfortunately had to cancel my physical attendance at this symposium for personal reasons, but was still able to contribute to the proceedings.) In recent years I have been interested in working towards establishing the existence of classical solutions for the Navier-Stokes equations


that blow up in finite time, but this time for a change I took a look at the other side of the theory, namely the conditional regularity results for this equation. There are several such results that assert that if a certain norm of the solution stays bounded (or grows at a controlled rate), then the solution stays regular; taken in the contrapositive, they assert that if a solution blows up at a certain finite time 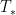
- (Leray blowup criterion, 1934) If
blows up at a finite time
, then
for an absolute constant
.
- (Prodi–Serrin–Ladyzhenskaya blowup criterion, 1959-1967) If
, where
.
- (Beale-Kato-Majda blowup criterion, 1984) If
, where
is the vorticity.
- (Kato blowup criterion, 1984) If
for some absolute constant
- (Escauriaza-Seregin-Sverak blowup criterion, 2003) If
.
- (Seregin blowup criterion, 2012) If
.
- (Phuc blowup criterion, 2015) If
for any
.
- (Gallagher-Koch-Planchon blowup criterion, 2016) If
for any
.
- (Albritton blowup criterion, 2016) If
for any
My current paper is most closely related to the Escauriaza-Seregin-Sverak blowup criterion, which was the first to show a critical (i.e., scale-invariant, or dimensionless) spatial norm, namely 
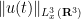
On the other hand, it is a general principle that qualitative arguments established using compactness methods ought to have quantitative analogues that replace the use of compactness by more complicated substitutes that give effective bounds; see for instance these previous blog posts for more discussion. I therefore was interested in trying to obtain a quantitative version of this blowup criterion that gave reasonably good effective bounds (in particular, my objective was to avoid truly enormous bounds such as tower-exponential or Ackermann function bounds, which often arise if one “naively” tries to make a compactness argument effective). In particular, I obtained the following triple-exponential quantitative regularity bounds:
Theorem 1 If
with
and
for
and
.

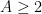 , then
, then
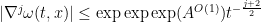
As a corollary, one can now improve the Escauriaza-Seregin-Sverak blowup criterion to
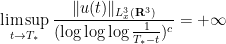
for some absolute constant
The proof uses many of the same quantitative inputs as previous arguments, most notably the Carleman inequalities used to establish unique continuation and backwards uniqueness theorems for backwards heat equations, but also some additional techniques that make the quantitative bounds more efficient. The proof focuses initially on points of concentration of the solution, which we define as points 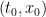
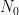
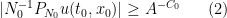
for a large absolute constant 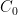
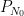
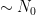
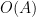
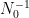

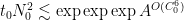
from which the above theorem ends up following from a routine adaptation of the local well-posedness and regularity theory for Navier-Stokes.
The strategy is to show that any concentration such as (2) when 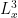

- Firstly, by using Duhamel’s formula, one can show that a concentration (2) can only occur (with
at some slightly previous point
in spacetime, with
also close to
,
, and
). This can be viewed as a sort of contrapositive of a “local regularity theorem”, such as the ones established by Caffarelli, Kohn, and Nirenberg. A key point here is that the lower bound
in the conclusion (3) is precisely the same as the lower bound in (2), so that this backwards propagation of concentration can be iterated.
- Iterating the previous step, one can find a sequence of concentration points
with the
propagating backwards in time; by using estimates ultimately resulting from the dissipative term in the energy identity, one can extract such a sequence in which the
increase geometrically with time, the
are comparable (up to polynomial factors in
, and one has
. Using the “epochs of regularity” theory that ultimately dates back to Leray, and tweaking the
slightly, one can also place the times
(of length comparable to a small multiple of
) in which the solution is quite regular (in particular,
enjoy good
bounds on
).
- The concentration (4) can be used to establish a lower bound for the
norm of the vorticity
near
In the epoch of regularity
of this equation obey good
bounds, allowing the machinery of Carleman estimates to come into play. Using a Carleman estimate that is used to establish unique continuation results for backwards heat equations, one can propagate this lower bound to also give lower
bounds on the vorticity (and its first derivative) in annuli of the form
for various radii
, although the lower bounds decay at a gaussian rate with
.
- Meanwhile, using an energy pigeonholing argument of Bourgain (which, in this Navier-Stokes context, is actually an enstrophy pigeonholing argument), one can locate some annuli
where (a slightly normalised form of) the entrosphy is small at time
; using a version of the localised enstrophy estimates from a previous paper of mine, one can then propagate this sort of control forward in time, obtaining an “annulus of regularity” of the form
in which one has good estimates; in particular, one has
- By intersecting the previous epoch of regularity
, establishing a lower bound for the vorticity on the spatial annulus
. By some basic Littlewood-Paley theory one can parlay this lower bound to a lower bound on the
norm of the velocity
- If


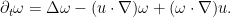
The chain of causality is summarised in the following image:

It seems natural to conjecture that similar triply logarithmic improvements can be made to several of the other blowup criteria listed above, but I have not attempted to pursue this question. It seems difficult to improve the triple logarithmic factor using only the techniques here; the Bourgain pigeonholing argument inevitably costs one exponential, the Carleman inequalities cost a second, and the stacking of scales at the end to contradict the
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv the short unpublished note “Eigenvectors from eigenvalues“. This note gives two proofs of a general eigenvector identity observed recently by Denton, Parke and Zhang in the course of some quantum mechanical calculations. The identity is as follows:
Theorem 1 Let
Hermitian matrix, with eigenvalues
. Let
be a unit eigenvector corresponding to the eigenvalue
, and let
be the
component of
where
is the
Hermitian matrix formed by deleting the
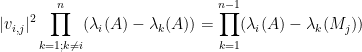
For instance, if we have
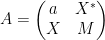
for some real number 



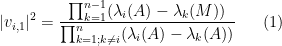
assuming that the denominator is non-zero.
Once one is aware of the identity, it is not so difficult to prove it; we give two proofs, each about half a page long, one of which is based on a variant of the Cauchy-Binet formula, and the other based on properties of the adjugate matrix. But perhaps it is surprising that such a formula exists at all; one does not normally expect to learn much information about eigenvectors purely from knowledge of eigenvalues. In the random matrix theory literature, for instance in this paper of Erdos, Schlein, and Yau, or this later paper of Van Vu and myself, a related identity has been used, namely
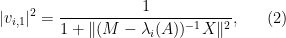
but it is not immediately obvious that one can derive the former identity from the latter. (I do so below the fold; we ended up not putting this proof in the note as it was longer than the two other proofs we found. I also give two other proofs below the fold, one from a more geometric perspective and one proceeding via Cramer’s rule.) It was certainly something of a surprise to me that there is no explicit appearance of the 
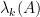

One can get some feeling of the identity (1) by considering some special cases. Suppose for instance that 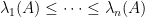
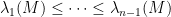
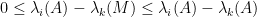
for 
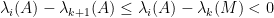
for 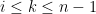


Recent Comments