
You are currently browsing the tag archive for the ‘Freiman’s theorem’ tag.
Tim Gowers, Ben Green, Freddie Manners, and I have just uploaded to the arXiv our paper “On a conjecture of Marton“. This paper establishes a version of the notorious Polynomial Freiman–Ruzsa conjecture (first proposed by Katalin Marton):
Theorem 1 (Polynomial Freiman–Ruzsa conjecture) Letbe such that
. Then
can be covered by at most
translates of a subspace
of
of cardinality at most
The previous best known result towards this conjecture was by Konyagin (as communicated in this paper of Sanders), who obtained a similar result but with 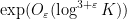

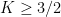


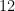

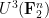
The exponent 
In this paper we will focus exclusively on the characteristic 
Much of the prior progress on this sort of result has proceeded via Fourier analysis. Perhaps surprisingly, our approach uses no Fourier analysis whatsoever, being conducted instead entirely in “physical space”. Broadly speaking, it follows a natural strategy, which is to induct on the doubling constant 

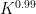
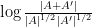

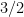
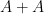
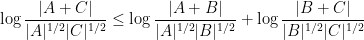 to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).
to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).
There are a number of possible ways to try to “improve” a set
- (i) Replacing
) of a large subspace
- (ii) Replacing
for a “typical”
. For instance, if
Unfortunately, there are sets 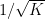
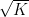
This begins to suggest a potential strategy: show that at least one of the operations (i) or (ii) will improve the doubling constant, or at least not worsen it too much; and in the latter case, perform some more complicated operation to locate the desired doubling constant improvement.
A sign that this strategy might have a chance of working is provided by the following heuristic argument. If 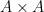
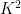
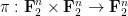

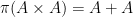

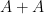

Unfortunately, this argument does not seem to be easily made rigorous using the traditional doubling constant; even the significantly weaker statement that 


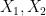

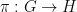
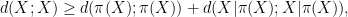
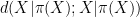 is defined as
is defined as 
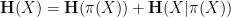

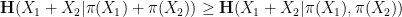
Applying this inequality with 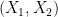


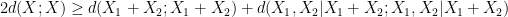
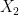 is determined by
is determined by 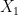 once one fixes
once one fixes 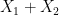 )
) 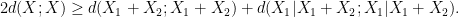
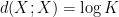 , then at least one of
, then at least one of 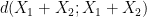 or
or 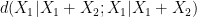 will be less than or equal to
will be less than or equal to 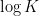 . This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events
. This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events 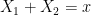 ,
, 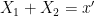 , and “depolarise” the induction hypothesis to deal with distances
, and “depolarise” the induction hypothesis to deal with distances 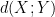 between pairs of random variables
between pairs of random variables  that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that
that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that 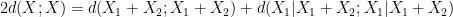
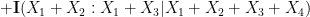
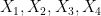 . This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and
. This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and  are conditionally independent relative to
are conditionally independent relative to  . This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.
. This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.
A version of this endgame conclusion is in fact valid in any characteristic. But in characteristic
 , and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of
, and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of 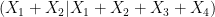 has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.
has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.
To deal with the situation where the conditional mutual information is small but not completely zero, we have to use an entropic version of the Balog-Szemeredi-Gowers lemma, but fortunately this was already worked out in an old paper of mine (although in order to optimise the final constant, we ended up using a slight variant of that lemma).
I am planning to formalize this paper in the Lean4 language. Further discussion of this project will take place on this Zulip stream, and the project itself will be held at this Github repository.
This fall (starting Monday, September 26), I will be teaching a graduate topics course which I have entitled “Hilbert’s fifth problem and related topics.” The course is going to focus on three related topics:
- Hilbert’s fifth problem on the topological description of Lie groups, as well as the closely related (local) classification of locally compact groups (the Gleason-Yamabe theorem).
- Approximate groups in nonabelian groups, and their classification via the Gleason-Yamabe theorem (this is very recent work of Emmanuel Breuillard, Ben Green, Tom Sanders, and myself, building upon earlier work of Hrushovski);
- Gromov’s theorem on groups of polynomial growth, as proven via the classification of approximate groups (as well as some consequences to fundamental groups of Riemannian manifolds).
I have already blogged about these topics repeatedly in the past (particularly with regard to Hilbert’s fifth problem), and I intend to recycle some of that material in the lecture notes for this course.
The above three families of results exemplify two broad principles (part of what I like to call “the dichotomy between structure and randomness“):
- (Rigidity) If a group-like object exhibits a weak amount of regularity, then it (or a large portion thereof) often automatically exhibits a strong amount of regularity as well;
- (Structure) This strong regularity manifests itself either as Lie type structure (in continuous settings) or nilpotent type structure (in discrete settings). (In some cases, “nilpotent” should be replaced by sister properties such as “abelian“, “solvable“, or “polycyclic“.)
Let me illustrate what I mean by these two principles with two simple examples, one in the continuous setting and one in the discrete setting. We begin with a continuous example. Given an 

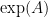

which can easily be verified to be an absolutely convergent series.
Exercise 1 Show that the map
is a real analytic (and even complex analytic) map from
to
for all
.

Proposition 1 (Rigidity and structure of matrix homomorphisms) Let
be a natural number. Let
be the group of invertible
be a map obeying two properties:
- (Group-like object)
is a homomorphism, thus
for all
.
- (Weak regularity) The map
is continuous.
Then:
- (Strong regularity) The map
- (Lie-type structure) There exists a (unique) complex
for all
.
Proof: Let 


![{t \in [-t_0,t_0]}](https://s0.wp.com/latex.php?latex=%7Bt+%5Cin+%5B-t_0%2Ct_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The map 


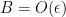

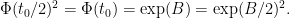
On the other hand, by another application of the inverse function theorem we see that the squaring map 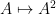
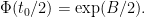
We may iterate this argument (for a fixed, but small, value of

for all 
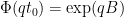
whenever 




for all real 
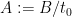
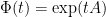
for all real 
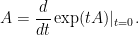

Exercise 2 Generalise Proposition 1 by replacing the hypothesis that
Note how one needs both the group-like structure and the weak regularity in combination in order to ensure the strong regularity; neither is sufficient on its own. We will see variants of the above basic argument throughout the course. Here, the task of obtaining smooth (or real analytic structure) was relatively easy, because we could borrow the smooth (or real analytic) structure of the domain 
Now we turn to a second illustration of the above principles, namely Jordan’s theorem, which uses a discreteness hypothesis to upgrade Lie type structure to nilpotent (and in this case, abelian) structure. We shall formulate Jordan’s theorem in a slightly stilted fashion in order to emphasise the adherence to the above-mentioned principles.
Theorem 2 (Jordan’s theorem) Let
- (Group-like object)
- (Discreteness)
- (Lie-type structure)
(the group of unitary
Then there is a subgroup
of
- (
of
(i.e. bounded by
for some quantity
- (Nilpotent-type structure)
A key observation in the proof of Jordan’s theorem is that if two unitary elements 
![{[g,h] = g^{-1}h^{-1}gh}](https://s0.wp.com/latex.php?latex=%7B%5Bg%2Ch%5D+%3D+g%5E%7B-1%7Dh%5E%7B-1%7Dgh%7D&bg=ffffff&fg=000000&s=0&c=20201002)
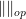
![\displaystyle \| [g,h] - 1 \|_{op} = \| gh - hg \|_{op}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Bg%2Ch%5D+-+1+%5C%7C_%7Bop%7D+%3D+%5C%7C+gh+-+hg+%5C%7C_%7Bop%7D&bg=ffffff&fg=000000&s=0&c=20201002)
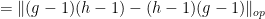
and so by the triangle inequality
![\displaystyle \| [g,h] - 1 \|_{op} \leq 2 \|g-1\|_{op} \|h-1\|_{op}. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Bg%2Ch%5D+-+1+%5C%7C_%7Bop%7D+%5Cleq+2+%5C%7Cg-1%5C%7C_%7Bop%7D+%5C%7Ch-1%5C%7C_%7Bop%7D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
Now we can prove Jordan’s theorem.
Proof: We induct on 


Thus we may assume that 
If 
![{[g,h]}](https://s0.wp.com/latex.php?latex=%7B%5Bg%2Ch%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Commutator estimates such as (2) will play a fundamental role in many of the arguments we will see in this course; as we saw above, such estimates combine very well with a discreteness hypothesis, but will also be very useful in the continuous setting.
Exercise 3 Generalise Jordan’s theorem to the case when
. However, if one averages that inner product by the finite group
Exercise 4 (Inability to discretise nonabelian Lie groups) Show that if
, then the orthogonal group
cannot contain arbitrarily dense finite subgroups, in the sense that there exists an
depending only on
case?
Remark 1 More precise classifications of the finite subgroups of
(which
is a double cover of) are isomorphic to either a cyclic group, a dihedral group, or the symmetry group of one of the Platonic solids.
A few days ago, I received the sad news that Yahya Ould Hamidoune had recently died. Hamidoune worked in additive combinatorics, and had recently solved a question on noncommutative Freiman-Kneser theorems posed by myself on this blog last year. Namely, Hamidoune showed
Theorem 1 (Noncommutative Freiman-Kneser theorem for small doubling) Let
, and let
be a finite non-empty subset of a multiplicative group
for some finite set
at least
, where
is the product set of
. Then there exists a finite subgroup
, such that
right-cosets
of
depend only on
One can of course specialise here to the case 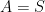

In fact Hamidoune’s argument, which is completely elementary, gives the very nice explicit constants 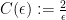
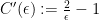

This type of result had previously been known when 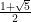
Theorem 1 is not, strictly speaking, contained in Hamidoune’s paper, but can be extracted from his arguments, which share some similarity with the recent simple proof of the Ruzsa-Plünnecke inequality by Petridis (as discussed by Tim Gowers here), and this is what I would like to do below the fold. I also include (with permission) Sanders’ unpublished argument, which proceeds instead by Fourier-analytic methods. Read the rest of this entry »
Let 
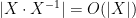
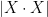
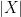
Proposition 1 If
, then
and
are both finite groups, which are conjugate to each other. In particular,
.
Remark 1 The constant
is completely sharp; consider the case when
where
is the identity and
is an element of order larger than
(resp. left-coset
) of a group of order less than
, then
Proof: We begin by showing that 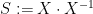
Let 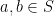


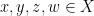



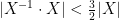



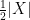






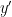




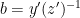

In the course of the above argument we showed that every element of the group 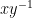
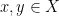
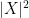
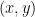
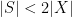
Now let 

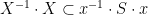



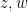
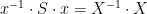
To relate this to the classical doubling constants 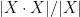
 , then
, then  .
.Again, this is sharp; consider 

Proof: Suppose that 





Proposition 3 If
, then
for some
The factor
Proof: Let 
Pick any 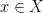


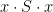

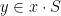

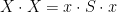

The intersection of the groups 


Because the arguments here are so elementary, they extend easily to the infinitary setting in which 
One of my favorite open problems, which I have blogged about in the past, is that of establishing (or even correctly formulating) a non-commutative analogue of Freiman’s theorem. Roughly speaking, the question is this: given a finite set 


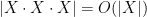
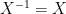
Sets of small doubling (or tripling), etc. can be thought of as “approximate groups”, since groups themselves have a doubling constant 
A weaker conjecture along the same lines is that if 
Recently, using some powerful tools from model theory combined with the theory of topological groups, Ehud Hrushovski has apparently achieved some breakthroughs on this problem, obtaining new structural control on sets of small doubling in arbitrary groups that was not previously accessible to the known combinatorial methods. The precise results are technical to state, but here are informal versions of two typical theorems. The first applies to sets of small tripling in an arbitrary group:
Theorem 1 (Rough version of Hrushovski Theorem 1.1) Let
, all of size comparable to
, which are somewhat closed under multiplication in the sense that
for all
, and which are fairly well closed under commutation in the sense that
. (There are also some additional statements to the effect that the
efficiently cover each other, and also cover
This nested sequence is somewhat analogous to a Bourgain system, though it is not quite the same notion.
If one assumes that
Theorem 2 (Rough version of Hrushovski Corollary 1.2) Let
be a set of small tripling, let
, and suppose that for almost all
-tuples
(where
), the conjugacy classes
generate most of
. Then a large part of
Note that if one quotiented out by the commutator ![{[X,X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2CX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Here at UCLA, a group of logicians and I (consisting of Matthias Aschenbrenner, Isaac Goldbring, Greg Hjorth, Henry Towsner, Anush Tserunyan, and possibly others) have just started a weekly reading seminar to come to grips with the various combinatorial, logical, and group-theoretic notions in Hrushovski’s paper, of which we only have a partial understanding at present. The seminar is a physical one, rather than an online one, but I am going to try to put some notes on the seminar on this blog as it progresses, as I know that there are a couple of other mathematicians who are interested in these developments.
So far there have been two meetings of the seminar. In the first, I surveyed the state of knowledge of the noncommutative Freiman theorem, covering broadly the material in my previous blog post. In the second meeting, Isaac reviewed some key notions of model theory used in Hrushovski’s paper, in particular the notions of definability and type, which I will review below. It is not yet clear how these are going to be connected with the combinatorial side of things, but this is something which we will hopefully develop in future seminars. The near-term objective is to understand the statement of the main theorem on the model-theoretic side (Theorem 3.4 of Hrushovski), and then understand some of its easier combinatorial consequences, before going back and trying to understand the proof of that theorem.
[Update, Oct 19: Given the level of interest in this paper, readers are encouraged to discuss any aspect of that paper in the comments below, even if they are not currently being covered by the UCLA seminar.]
It turns out to be a favourable week or two for me to finally finish a number of papers that had been at a nearly completed stage for a while. I have just uploaded to the arXiv my article “Sumset and inverse sumset theorems for Shannon entropy“, submitted to Combinatorics, Probability, and Computing. This paper evolved from a “deleted scene” in my book with Van Vu entitled “Entropy sumset estimates“. In those notes, we developed analogues of the standard Plünnecke-Ruzsa sumset estimates (which relate quantities such as the cardinalities 
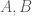

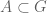

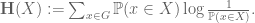
This quantity measures the information content of X; for instance, if 
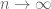
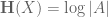
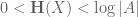
It turns out that many estimates on sumsets have entropy analogues, which resemble the “logarithm” of the sumset estimates. For instance, the trivial bounds

have the entropy analogue
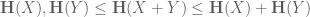
whenever X, Y are independent discrete random variables in an additive group; this is not difficult to deduce from standard entropy inequalities. Slightly more non-trivially, the sum set estimate
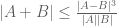
established by Ruzsa, has an entropy analogue

and similarly for a number of other standard sumset inequalities in the literature (e.g. the Rusza triangle inequality, the Plünnecke-Rusza inequality, and the Balog-Szemeredi-Gowers theorem, though the entropy analogue of the latter requires a little bit of care to state). These inequalities can actually be deduced fairly easily from elementary arithmetic identities, together with standard entropy inequalities, most notably the submodularity inequality
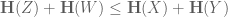
whenever X,Y,Z,W are discrete random variables such that X and Y each determine W separately (thus 


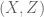

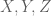
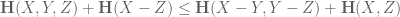
which soon leads to the entropy Rusza triangle inequality

which is an analogue of the combinatorial Ruzsa triangle inequality

All of this was already in the unpublished notes with Van, though I include it in this paper in order to place it in the literature. The main novelty of the paper, though, is to consider the entropy analogue of Freiman’s theorem, which classifies those sets A for which 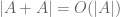

For instance, the uniform distribution U on a finite subgroup H of G has small doubling (in fact 
Theorem 1. (Informal statement) X has small doubling if and only if
for some uniform distribution U on a coset progression (of bounded rank), and Y has bounded entropy.
For instance, suppose that X was the uniform distribution on a dense subset A of a finite group G. Then Theorem 1 asserts that X is close in a “transport metric” sense to the uniform distribution U on G, in the sense that it is possible to rearrange or transport the probability distribution of X to the probability distribution of U (or vice versa) by shifting each component of the mass of X by an amount Y which has bounded entropy (which basically means that it primarily ranges inside a set of bounded cardinality). The way one shows this is by randomly translating the mass of X around by a few random shifts to approximately uniformise the distribution, and then deal with the residual fluctuation in the distribution by hand. Theorem 1 as a whole is established by using the Freiman theorem in the combinatorial setting combined with various elementary convexity and entropy inequality arguments to reduce matters to the above model case when X is supported inside a finite group G and has near-maximal entropy.
I also show a variant of the above statement: if X, Y are independent and 

In the last part of the paper I relate these discrete entropies to their continuous counterparts
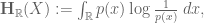
where X is now a continuous random variable on the real line with density function 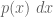
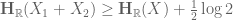
for independent copies

whenever 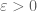

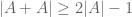
though notice that we have a gain of just 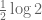
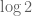

I also conjecture more generally that the entropy monotonicity inequalities established by Artstein, Barthe, Ball, and Naor in the continuous case also hold in the above sense in the discrete case, though my method of proof breaks down because I no longer can assume small doubling.
I’m continuing the stream of uploaded papers this week with my paper “Freiman’s theorem for solvable groups“, submitted to Contrib. Disc. Math.. This paper concerns the problem (discussed in this earlier blog post) of determining the correct analogue of Freiman’s theorem in a general non-abelian group 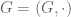
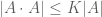
When G is the integers (with the additive group operation), Freiman’s theorem then tells us that A is controlled by a generalised arithmetic progression P, where I say that one set A is controlled by another P if they have comparable size, and the former can be covered by a finite number of translates of the latter. (One can view generalised arithmetic progressions as an approximate version of a subgroup, in which one only uses the generators of the progression for a finite amount of time before stopping, as opposed to groups which allow words of unbounded length in the generators.) For more general abelian groups, the Freiman theorem of Green and Ruzsa tells us that a set of bounded doubling is controlled by a generalised coset progression 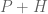
In this paper we address the case when G is a solvable group of bounded derived length. The main result is that if a subset of G has small doubing, then it is controlled by an object which I call a “coset nilprogression”, which is a certain technical generalisation of a coset progression, in which the generators do not quite commute, but have commutator expressible in terms of “higher order” generators. This is essentially a sharp characterisation of such sets, except for the fact that one would like a more explicit description of these coset nilprogressions. In the torsion-free case, a more explicit description (analogous to the Mal’cev basis description of nilpotent groups) has appeared in a very recent paper of Breulliard and Green; in the case of monomial groups (a class of groups that overlaps to a large extent with solvable groups), and assuming a polynomial growth condition rather than a doubling condition, a related result controlling A by balls in a suitable type of metric has appeared in very recent work of Sanders. In the nilpotent case there is also a nice recent argument of Fisher, Peng, and Katz which shows that sets of small doubling remain of small doubling with respect to the Lie algebra operations of addition and Lie bracket, and thus are amenable to the abelian Freiman theorems.
The conclusion of my paper is easiest to state (and easiest to prove) in the model case of the lamplighter group 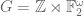

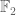
Theorem 1. (Freiman’s theorem for the lamplighter group) If
has bounded doubling, then A is controlled either by a finite subspace of the “vertical” group
, or else by a set of the form
, where
is a generalised arithmetic progression, and
obeys the Freiman isomorphism property
whenever
and
.
This result, incidentally, recovers an earlier result of Lindenstrauss that the lamplighter group does not contain a Følner sequence of sets of uniformly bounded doubling. It is a good exercise to establish the “exact” version of this theorem, in which one classifies subgroups of the lamplighter group rather than sets of small doubling; indeed, the proof of this the above theorem follows fairly closely the natural proof of the exact version.
One application of the solvable Freiman theorem is the following quantitative version of a classical result of Milnor and of Wolf, which asserts that any solvable group of polynomial growth is virtually nilpotent:
Theorem 2. (Quantitative Milnor-Wolf theorem) Let G be a solvable group of derived length O(1), let S be a set of generators for G, and suppose one has the polynomial growth condition
for some d = O(1), where
is the set of all words generated by S of length at most R. If R is sufficiently large, then this implies that G is virtually nilpotent; more precisely, G contains a nilpotent subgroup of step O(1) and index
.
The key points here are that one only needs polynomial growth at a single scale R, rather than on many scales, and that the index of the nilpotent subgroup has polynomial size.
The proofs are based on an induction on the derived length. After some standard manipulations (basically, splitting A by an approximate version of a short exact sequence), the problem boils down to that of understanding the action 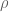
In the course of the proof we need two new additive combinatorial results which may be of independent interest. The first is a variant of a well-known theorem of Sárközy, which asserts that if A is a large subset of an arithmetic progression P, then an iterated sumset kA of A for some 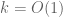
For a number of reasons, including the start of the summer break for me and my coauthors, a number of papers that we have been working on are being released this week. For instance, Ben Green and I have just uploaded to the arXiv our paper “An equivalence between inverse sumset theorems and inverse conjectures for the 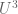
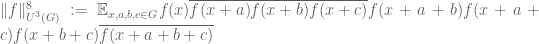
on finite additive group G, where 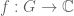
As usual, the connection is easiest to state in a finite field model such as 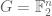
Theorem 1. If
is such that
, then A can be covered by a translate of a subspace of
of cardinality at most
.
The constant 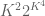

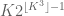
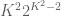

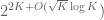
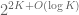
Conjecture 1. (Polynomial Freiman-Ruzsa conjecture for
translates of subspaces of
This conjecture was verified for downsets by Green and myself, but is open in general. This conjecture has a number of equivalent formulations; see this paper of Green for more discussion. In this previous post we show that a stronger version of this conjecture fails.
Meanwhile, for the Gowers norm, we have the following inverse theorem, due to Samorodnitsky:
Theorem 2. Let
be a function whose
such that
.
Note that the quadratic phases 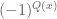
It is conjectured that the exponentially weak correlation here can be strengthened to a polynomial one:
Conjecture 2. (Polynomial inverse conjecture for the
norm). Let
.
The first main result of this paper is
Theorem 3. Conjecture 1 and Conjecture 2 are equivalent.
This result was also independently observed by Shachar Lovett (private communication). We also establish an analogous result for the cyclic group 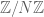
Below the fold, we sketch the proof of Theorem 3.
[This post is authored by Ben Green, who has kindly “guest blogged” this week’s “open problem of the week”. – T.]
In an earlier blog post Terry discussed Freiman’s theorem. The name of Freiman is attached to a growing body of theorems which take some rather “combinatorial” hypothesis, such that the sumset |A+A| of some set A is small, and deduce from it rather “algebraic” information (such that A is contained in a subspace or a grid).
The easiest place to talk about Freiman’s theorem is in the finite field model 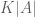
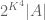


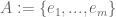

This result has an air of finality (except for the true nature of the o(K) term, which represents an interesting open problem). This is something of an illusion, however. Even using this theorem, one loses an exponential every time one tries to transition between “combinatorial” structure and “algebraic” structure and back again. Indeed if one knows that A is contained in a subspace of size 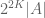
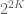
The Polynomial Freiman-Ruzsa conjecture (PFR), in
conjecture, one may flit back and forth between combinatorial and algebraic structure with only polynomial losses. Ruzsa attributes the conjecture to
Marton: it states that if A has doubling at most K then A is contained in the union of 
This is another one of my favourite open problems, falling under the heading of inverse theorems in arithmetic combinatorics. “Direct” theorems in arithmetic combinatorics take a finite set A in a group or ring and study things like the size of its sum set 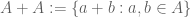




for some 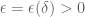
In contrast, inverse theorems in this subject start with a hypothesis that, say, the sum set A+A of an unknown set A is small, and try to deduce structural information about A. A typical goal is to completely classify all sets A for which A+A has comparable size with A. In the case of finite subsets of integers, this is Freiman’s theorem, which roughly speaking asserts that if 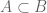
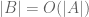

Recent Comments