
You are currently browsing the category archive for the ‘math.RA’ category.
As someone who had a relatively light graduate education in algebra, the import of Yoneda’s lemma in category theory has always eluded me somewhat; the statement and proof are simple enough, but definitely have the “abstract nonsense” flavor that one often ascribes to this part of mathematics, and I struggled to connect it to the more grounded forms of intuition, such as those based on concrete examples, that I was more comfortable with. There is a popular MathOverflow post devoted to this question, with many answers that were helpful to me, but I still felt vaguely dissatisfied. However, recently when pondering the very concrete concept of a polynomial, I managed to accidentally stumble upon a special case of Yoneda’s lemma in action, which clarified this lemma conceptually for me. In the end it was a very simple observation (and would be extremely pedestrian to anyone who works in an algebraic field of mathematics), but as I found this helpful to a non-algebraist such as myself, and I thought I would share it here in case others similarly find it helpful.
In algebra we see a distinction between a polynomial form (also known as a formal polynomial), and a polynomial function, although this distinction is often elided in more concrete applications. A polynomial form in, say, one variable with integer coefficients, is a formal expression 
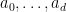


![{{\bf Z}[{\mathrm n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%7B%5Cmathrm+n%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

A polynomial form 

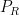
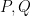




- (i) The linear forms
are distinct as polynomial forms, but agree when interpreted in the ring
, since
for all
.
- (ii) Similarly, if
is a prime, then the degree one form
are distinct as polynomial forms (and in particular have distinct degrees), but agree when interpreted in the ring
, thanks to Fermat’s little theorem.
- (iii) The polynomial form
has no roots when interpreted in the reals
, but has roots when interpreted in the complex numbers
. Similarly, the linear form
has no roots when interpreted in the integers
, but has roots when interpreted in the rationals
.
The above examples show that if one only interprets polynomial forms in a specific ring
If 
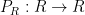
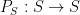

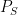


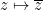
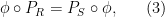

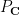 on the complex numbers, and any complex number .
on the complex numbers, and any complex number .
What was surprising to me (as someone who had not internalized the Yoneda lemma) was that the converse statement was true: if one had a function 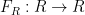
![{P \in {\bf Z}[\mathrm{n}]}](https://s0.wp.com/latex.php?latex=%7BP+%5Cin+%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


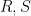
![{{\bf Z}[\mathrm{n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\phi_{R,n}: {\bf Z}[\mathrm{n}] \rightarrow R}](https://s0.wp.com/latex.php?latex=%7B%5Cphi_%7BR%2Cn%7D%3A+%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D+%5Crightarrow+R%7D&bg=ffffff&fg=000000&s=0&c=20201002)

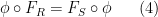
 . Applying (4) to this ring homomorphism, and specializing to the element of , we conclude that
. Applying (4) to this ring homomorphism, and specializing to the element of , we conclude that ![\displaystyle \phi_{R,n}( F_{{\bf Z}[\mathrm{n}]}(\mathrm{n}) ) = F_R( n )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cphi_%7BR%2Cn%7D%28+F_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29+%29+%3D+F_R%28+n+%29&bg=ffffff&fg=000000&s=0&c=20201002) and any . If we then define to be the formal polynomial
and any . If we then define to be the formal polynomial ![\displaystyle P := F_{{\bf Z}[\mathrm{n}]}(\mathrm{n}),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P+%3A%3D+F_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29%2C&bg=ffffff&fg=000000&s=0&c=20201002)

 arises from a polynomial form . Conversely, from the identity
arises from a polynomial form . Conversely, from the identity ![\displaystyle P = P_{{\bf Z}[\mathrm{n}]}(\mathrm{n})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P+%3D+P_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29&bg=ffffff&fg=000000&s=0&c=20201002) , we see that two polynomial forms
, we see that two polynomial forms 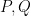 can only generate the same polynomial functions
can only generate the same polynomial functions  for all rings if they are identical as polynomial forms. So the polynomial form associated to the family is unique.
for all rings if they are identical as polynomial forms. So the polynomial form associated to the family is unique.
We have thus created an identification of form and function: polynomial forms 
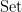

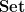
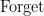
![{{\bf Z}[\mathbf{n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget}({\bf Z}[\mathbf{n}]) \equiv \mathrm{Hom}( \mathrm{Forget}, \mathrm{Forget} ). \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D%28%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%29+%5Cequiv+%5Cmathrm%7BHom%7D%28+%5Cmathrm%7BForget%7D%2C+%5Cmathrm%7BForget%7D+%29.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
What does this have to do with Yoneda’s lemma? Well, remember that every element 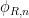
![{\mathrm{Hom}({\bf Z}[\mathrm{n}], R)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+R%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget} \equiv \mathrm{Hom}({\bf Z}[\mathrm{n}], -).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D+%5Cequiv+%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+-%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget}({\bf Z}[\mathbf{n}]) \equiv \mathrm{Hom}( \mathrm{Hom}({\bf Z}[\mathrm{n}], -), \mathrm{Forget} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D%28%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%29+%5Cequiv+%5Cmathrm%7BHom%7D%28+%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+-%29%2C+%5Cmathrm%7BForget%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
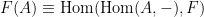
 from a (locally small) category
from a (locally small) category 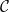 and any object
and any object  in . And indeed if one inspects the standard proof of this lemma, it is essentially the same argument as the argument we used above to establish the identification (5). More generally, it seems to me that the Yoneda lemma is often used to identify “formal” objects with their “functional” interpretations, as long as one simultaneously considers interpretations across an entire category (such as the category of rings), as opposed to just a single interpretation in a single object of the category in which there may be some loss of information due to the peculiarities of that specific object. Grothendieck’s “functor of points” interpretation of a scheme, discussed in this previous blog post, is one typical example of this.
in . And indeed if one inspects the standard proof of this lemma, it is essentially the same argument as the argument we used above to establish the identification (5). More generally, it seems to me that the Yoneda lemma is often used to identify “formal” objects with their “functional” interpretations, as long as one simultaneously considers interpretations across an entire category (such as the category of rings), as opposed to just a single interpretation in a single object of the category in which there may be some loss of information due to the peculiarities of that specific object. Grothendieck’s “functor of points” interpretation of a scheme, discussed in this previous blog post, is one typical example of this.
Hariharan Narayanan, Scott Sheffield, and I have just uploaded to the arXiv our paper “Sums of GUE matrices and concentration of hives from correlation decay of eigengaps“. This is a personally satisfying paper for me, as it connects the work I did as a graduate student (with Allen Knutson and Chris Woodward) on sums of Hermitian matrices, with more recent work I did (with Van Vu) on random matrix theory, as well as several other results by other authors scattered across various mathematical subfields.
Suppose 

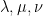
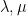


One of my favourite open problems is to come up with a theory of “free hives” that allows one to explain the latter fact from the former. This is still unresolved, but we are now beginning to make a bit of progress towards this goal. We know (for instance from the calculations of Coquereaux and Zuber) that if 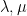
In this paper, we are able to accomplish the first half of this goal, assuming that the spectra 

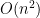
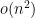
Augmented hives seem tricky to work with directly, but by adapting the octahedron recurrence introduced for this problem by Knutson, Woodward, and myself some time ago (which is related to the associativity 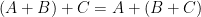
On the other hand, the piecewise linear map, initially defined by iterating the octahedron relation 
It would be more convenient to study the concentration of each linear map separately, rather than their supremum. By the Cheeger inequality, it turns out that one can relate the latter to the former provided that one has good control on the Cheeger constant of the underlying measure on the Gelfand-Tsetlin cones. Fortunately, the measure is log-concave, so one can use the very recent work of Klartag on the KLS conjecture to eliminate the supremum (up to a logarithmic loss which is only moderately annoying to deal with).
It remains to obtain concentration on the linear map associated to a given lozenge tiling. After stripping away some contributions coming from lozenges near the edge (using some eigenvalue rigidity results of Van Vu and myself), one is left with some bulk contributions which ultimately involve eigenvalue interlacing gaps such as
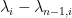
 is the
is the  eigenvalue of the top left
eigenvalue of the top left 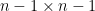 minor of , and
minor of , and  is in the bulk region
is in the bulk region  for some fixed
for some fixed  . To get the desired result, one needs some non-trivial correlation decay in for these statistics. If one was working with eigenvalue gaps
. To get the desired result, one needs some non-trivial correlation decay in for these statistics. If one was working with eigenvalue gaps 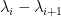 rather than interlacing results, then such correlation decay was conveniently obtained for us by recent work of Cippoloni, Erdös, and Schröder. So the last remaining challenge is to understand the relation between eigenvalue gaps and interlacing gaps.
rather than interlacing results, then such correlation decay was conveniently obtained for us by recent work of Cippoloni, Erdös, and Schröder. So the last remaining challenge is to understand the relation between eigenvalue gaps and interlacing gaps.
For this we turned to the work of Metcalfe, who uncovered a determinantal process structure to this problem, with a kernel associated to Lagrange interpolation polynomials. It is possible to satisfactorily estimate various integrals of these kernels using the residue theorem and eigenvalue rigidity estimates, thus completing the required analysis.
Let 
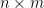
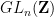
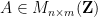




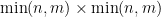
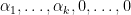



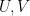
In this post I would like to record how to use the Smith normal form to computationally manipulate two closely related classes of objects:
- Subgroups
of a standard lattice
(or lattice subgroups for short);
- Closed subgroups
of a standard torus
(or closed torus subgroups for short).
The above two classes of objects are isomorphic to each other by Pontryagin duality: if
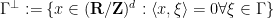
 the usual Fourier pairing); conversely, if is a closed torus subgroup, then
the usual Fourier pairing); conversely, if is a closed torus subgroup, then 
 and
and  .
.
Example 1 The orthogonal complement of the lattice subgroupis the closed torus subgroup
and conversely.


Let us focus first on lattice subgroups 


 is the matrix whose columns are
is the matrix whose columns are 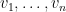 . Applying the Smith normal form , we conclude that
. Applying the Smith normal form , we conclude that  is isomorphic (with respect to the automorphism group
is isomorphic (with respect to the automorphism group  of ) to
of ) to  . In particular, we see that is a free abelian group of rank
. In particular, we see that is a free abelian group of rank  , where is the rank of (or ). This representation also allows one to trim the representation
, where is the rank of (or ). This representation also allows one to trim the representation  down to
down to  , where
, where 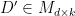 is the matrix formed from the left columns of ; the columns of
is the matrix formed from the left columns of ; the columns of 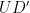 then give a basis for . Let us call this a trimmed representation of
then give a basis for . Let us call this a trimmed representation of  .
.
Example 2 Letbe the lattice subgroup generated by
,
,
, thus
with
. A Smith normal form for
so
is a rank two lattice with a basis of
and
(and the invariant factors are
and
). The trimmed representation is
There are other Smith normal forms for


By the above discussion we can represent a lattice subgroup
- (Applying a linear transformation) if
, so that
is also a linear transformation from
, then
for any
- (Sum) Given two lattice subgroups
for some
,
, the sum
is equal to the lattice subgroup
, where
is the matrix formed by concatenating the columns of
with the columns of
.
- (Direct sum) Given two lattice subgroups
,
, the direct sum
is equal to the lattice subgroup
is the block matrix formed by taking the direct sum of
One can also use Smith normal form to detect when one lattice subgroup 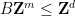

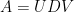
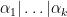


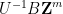 is generated by the columns of
is generated by the columns of 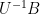 , so this gives a test to determine whether
, so this gives a test to determine whether  : the row of must be divisible by
: the row of must be divisible by 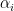 for
for 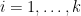 , and all other rows must vanish.
, and all other rows must vanish.
Example 3 To test whether the lattice subgroupgenerated by
and
is contained in the lattice subgroup
from Example 2, we write
with
, and observe that
The first row is of course divisible by
is); also a similar computation verifies that

One can now test whether 

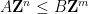
Next, we consider the question of representing the intersection 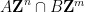
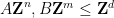

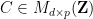


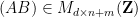 is the matrix formed by concatenating and , and similarly for
is the matrix formed by concatenating and , and similarly for 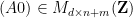 (here we use the change of variable
(here we use the change of variable 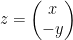 ). We apply the Smith normal form to
). We apply the Smith normal form to 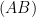 to write
to write 
 ,
,  ,
,  with of rank . We can then write
with of rank . We can then write 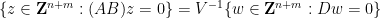

 ). Thus we can write
). Thus we can write 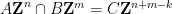 where
where 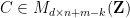 consists of the right
consists of the right  columns of
columns of  .
.
Example 4 With the lattice, which one can also write as
with
. We obtain a Smith normal form
so
. We have
and so we can write
where
One can trim this representation if desired, for instance by deleting the first column of
(and replacing
with
.
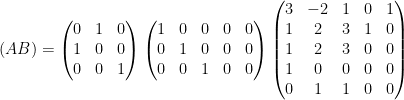
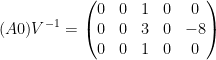
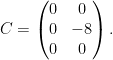
A similar calculation allows one to represent the pullback 



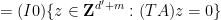
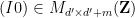 is the concatenation of the
is the concatenation of the  identity matrix
identity matrix  and the
and the 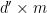 zero matrix. Applying the Smith normal form to write
zero matrix. Applying the Smith normal form to write  with of rank , the same argument as before allows us to write
with of rank , the same argument as before allows us to write  where
where 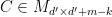 consists of the right
consists of the right 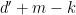 columns of
columns of 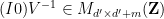 .
.
Among other things, this allows one to describe lattices given by systems of linear equations and congruences in the 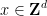
 , some natural numbers , and some lattice vectors
, some natural numbers , and some lattice vectors 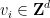 , together with an additional system of equations
, together with an additional system of equations 
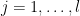 and some lattice vectors
and some lattice vectors  , can be written as
, can be written as 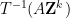 where
where  is the matrix with rows
is the matrix with rows 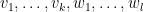 , and
, and 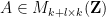 is the diagonal matrix with diagonal entries . Conversely, any subgroup can be described in this form by first using the trimmed representation
is the diagonal matrix with diagonal entries . Conversely, any subgroup can be described in this form by first using the trimmed representation 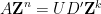 , at which point membership of a lattice vector in is seen to be equivalent to the congruences
, at which point membership of a lattice vector in is seen to be equivalent to the congruences 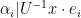 (where is the rank, are the invariant factors, and
(where is the rank, are the invariant factors, and  is the standard basis of ) together with the equations
is the standard basis of ) together with the equations 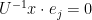
 . Thus one can obtain a representation in the form (1), (2) with
. Thus one can obtain a representation in the form (1), (2) with  , and
, and 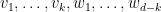 to be the rows of
to be the rows of 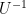 in order.
in order.
Example 5 With the lattice subgroup, and so
which obey the (redundant) congruence
the congruence
and the identity
Conversely, one can use the above procedure to convert the above system of congruences and identities back into a form
(though depending on which Smith normal form one chooses, the end result may be a different representation of the same lattice group
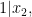

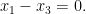
Now we apply Pontryagin duality. We claim the identity
 (where
(where 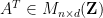 induces a homomorphism from to
induces a homomorphism from to 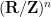 in the obvious fashion). This can be verified by direct computation when is a (rectangular) diagonal matrix, and the general case then easily follows from a Smith normal form computation (one can presumably also derive it from the category-theoretic properties of Pontryagin duality, although I will not do so here). So closed torus subgroups that are defined by a system of linear equations (over
in the obvious fashion). This can be verified by direct computation when is a (rectangular) diagonal matrix, and the general case then easily follows from a Smith normal form computation (one can presumably also derive it from the category-theoretic properties of Pontryagin duality, although I will not do so here). So closed torus subgroups that are defined by a system of linear equations (over 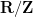 , with integer coefficients) are represented in the form
, with integer coefficients) are represented in the form  of an orthogonal complement of a lattice subgroup. Using the trimmed form
of an orthogonal complement of a lattice subgroup. Using the trimmed form  , we see that
, we see that 
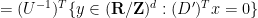

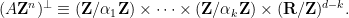
Example 6 The orthogonal complement of the lattice subgroup
using the trimmed representation of
, one can simplify this a little to
and one can also write this as the image of the group
under the torus isomorphism
In other words, one can write
so that
.

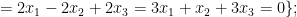


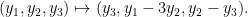

We can now dualize all of the previous computable operations on subgroups of
- To form the intersection or sum of two closed torus subgroups
, use the identities
and
and then calculate the sum or intersection of the lattice subgroupsby the previous methods. Similarly, the operation of direct sum of two closed torus subgroups dualises to the operation of direct sum of two lattice subgroups.
- To determine whether one closed torus subgroup
is contained in (or equal to) another closed torus subgroup
, simply use the preceding methods to check whether the lattice subgroup
is contained in (or equal to) the lattice subgroup
.
- To compute the pull back
of a closed torus subgroup
via a linear transformation
Similarly, to compute the imageof a closed torus subgroup
, use the identity

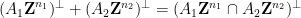
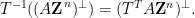

Example 7 Suppose one wants to compute the sum of the closed torus subgroup. This latter group is the orthogonal complement of the lattice subgroup
where
As I have mentioned in some recent posts, I am interested in exploring unconventional modalities for presenting mathematics, for instance using media with high production value. One such recent example of this I saw was a presentation of the fundamental zero product property (or domain property) of the real numbers – namely, that 
EDIT: and here is a lesson on fractions, expressed through the medium of a burger chain advertisement:
I’d be interested to know what further examples of this type are out there.
SECOND EDIT: The following two examples from Wired magazine are slightly more conventional in nature, but still worth mentioning, I think. Firstly, my colleague at UCLA, Amit Sahai, presents the concept of zero knowledge proofs at various levels of technicality:
Secondly, Moon Duchin answers math questions of all sorts from Twitter:
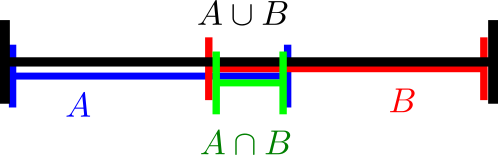
A popular way to visualise relationships between some finite number of sets is via Venn diagrams, or more generally Euler diagrams. In these diagrams, a set is depicted as a two-dimensional shape such as a disk or a rectangle, and the various Boolean relationships between these sets (e.g., that one set is contained in another, or that the intersection of two of the sets is equal to a third) is represented by the Boolean algebra of these shapes; Venn diagrams correspond to the case where the sets are in “general position” in the sense that all non-trivial Boolean combinations of the sets are non-empty. For instance to depict the general situation of two sets 
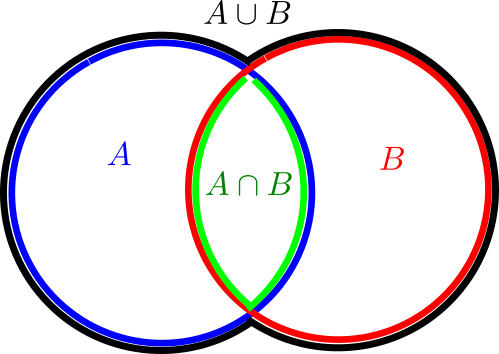
(where we have given each region depicted a different color, and moved the edges of each region a little away from each other in order to make them all visible separately), but if one wanted to instead depict a situation in which the intersection
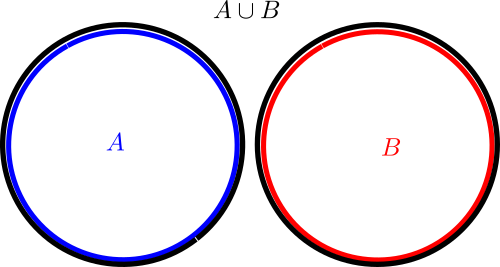
One can use the area of various regions in a Venn or Euler diagram as a heuristic proxy for the cardinality 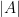
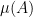
 , while the above Euler diagram similarly justifies the special case
, while the above Euler diagram similarly justifies the special case 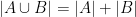 .
.
While Venn and Euler diagrams are traditionally two-dimensional in nature, there is nothing preventing one from using one-dimensional diagrams such as
or even three-dimensional diagrams such as this one from Wikipedia:
Of course, in such cases one would use length or volume as a heuristic proxy for cardinality or measure, rather than area.
With the addition of arrows, Venn and Euler diagrams can also accommodate (to some extent) functions between sets. Here for instance is a depiction of a function 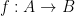



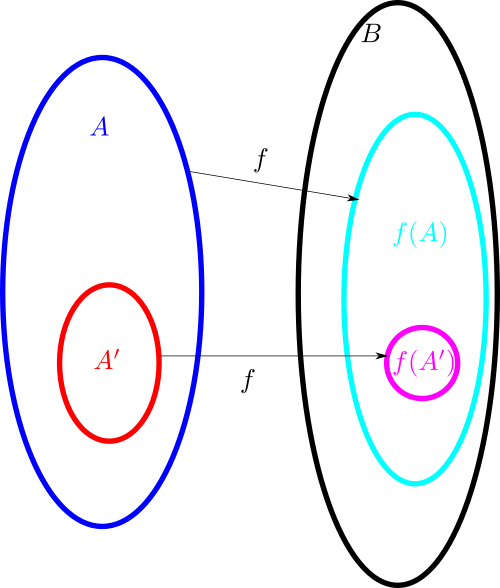
Here one can illustrate surjectivity of 

Cartesian product operations can be incorporated into these diagrams by appropriate combinations of one-dimensional and two-dimensional diagrams. Here for instance is a diagram that illustrates the identity 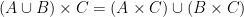
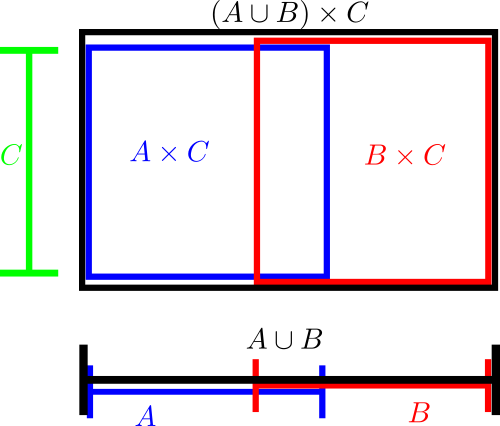
In this blog post I would like to propose a similar family of diagrams to illustrate relationships between vector spaces (over a fixed base field
The (classical) Möbius function 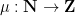
Proposition 1 (Classical Möbius inversion) Letbe functions from the natural numbers to an additive group
- (i)
for all
.
- (ii)
for all
There is a generalisation of this formula to (finite) posets, due to Hall, in which one sums over chains 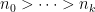
Proposition 2 (Poset Möbius inversion) Letbe a finite poset, and let
be functions from that poset to an additive group
(Note from the finite nature of
- (i)
for all
, where
is understood to range in
- (ii)
for all
are understood to range in
Comparing Proposition 2 with Proposition 1, it is natural to refer to the function 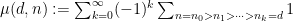
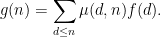
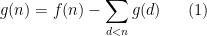 . Iterating this we obtain (ii). Conversely, from (ii) and separating out the
. Iterating this we obtain (ii). Conversely, from (ii) and separating out the  term, and grouping all the other terms based on the value of
term, and grouping all the other terms based on the value of  , we obtain (1), and hence (i).
, we obtain (1), and hence (i). 
In fact it is not completely necessary that the poset 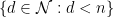
It is not difficult to see that Proposition 2 includes Proposition 1 as a special case, after verifying the combinatorial fact that the quantity

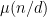 when divides , and vanishes otherwise.
when divides , and vanishes otherwise.
I recently discovered that Proposition 2 can also lead to a useful variant of the inclusion-exclusion principle. The classical version of this principle can be phrased in terms of indicator functions: if 

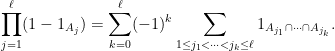 on for which are all measurable, we have
on for which are all measurable, we have 
One drawback of this formula is that there are exponentially many terms on the right-hand side: 
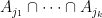
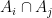
Proposition 3 (Hall-type inclusion-exclusion principle) Let(with the convention that
, one has
where
are understood to range in
to be the empty intersection) if the
are all proper subsets of
In particular, if there is a finite measure



Using the Möbius function 
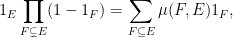


Proof: It suffices to establish (2) (to derive (3) from (2) observe that all the 
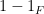
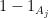
 . But this amounts to the assertion that for each
. But this amounts to the assertion that for each 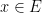 , there is precisely one
, there is precisely one  in
in 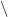 with the property that
with the property that  and
and  for any
for any 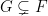 in , namely one can take to be the intersection of all
in , namely one can take to be the intersection of all 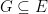 in such that
in such that  contains
contains  .
.
Example 4 Ifwith
, and
are all distinct, then we have for any finite measure
measurable that
due to the four chains
,
,
,
of length one, and the three chains
,
,
of length two. Note that this expansion just has six terms in it, as opposed to the
given by the usual inclusion-exclusion formula, though of course one can reduce the number of terms by combining the
factors. This may not seem particularly impressive, especially if one views the term
as really being three terms instead of one, but if we add a fourth set
with
for all
, the formula now becomes
and we begin to see more cancellation as we now have just seven terms (or ten if we count
as four terms) instead of
terms.


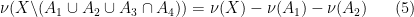
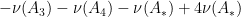
Example 5 (Variant of Legendre sieve) Ifare natural numbers, and
is some sequence of complex numbers with only finitely many terms non-zero, then by applying the above proposition to the sets
and with
we obtain a variant of the Legendre sieve
where
range over the set
(with the understanding that the empty least common multiple is
denotes the assertion that
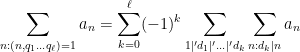
If the poset 

Actually in our application we need an abstraction of the above formula, in which the indicator functions are replaced by more abstract idempotents:
Proposition 6 (Hall-type inclusion-exclusion principle for idempotents) Letfor
). Let
when
(note that all the elements of
where
) if all the


Morally speaking this proposition is equivalent to the previous one after applying a “spectral theorem” to simultaneously diagonalise all of the
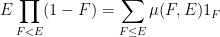
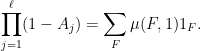
Proof: Again it suffices to verify (6). Using Proposition 2 as before, it suffices to show that 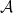


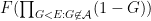
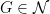
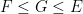
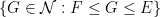

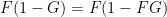

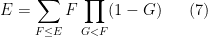
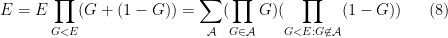
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv a completely rewritten version of our previous paper, now titled “Eigenvectors from Eigenvalues: a survey of a basic identity in linear algebra“. This paper is now a survey of the various literature surrounding the following basic identity in linear algebra, which we propose to call the eigenvector-eigenvalue identity:
Theorem 1 (Eigenvector-eigenvalue identity) Let
. Let
be a unit eigenvector corresponding to the eigenvalue
, and let
be the
component of
where
is the
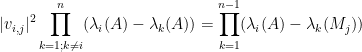
When we posted the first version of this paper, we were unaware of previous appearances of this identity in the literature; a related identity had been used by Erdos-Schlein-Yau and by myself and Van Vu for applications to random matrix theory, but to our knowledge this specific identity appeared to be new. Even two months after our preprint first appeared on the arXiv in August, we had only learned of one other place in the literature where the identity showed up (by Forrester and Zhang, who also cite an earlier paper of Baryshnikov).
The situation changed rather dramatically with the publication of a popular science article in Quanta on this identity in November, which gave this result significantly more exposure. Within a few weeks we became informed (through private communication, online discussion, and exploration of the citation tree around the references we were alerted to) of over three dozen places where the identity, or some other closely related identity, had previously appeared in the literature, in such areas as numerical linear algebra, various aspects of graph theory (graph reconstruction, chemical graph theory, and walks on graphs), inverse eigenvalue problems, random matrix theory, and neutrino physics. As a consequence, we have decided to completely rewrite our article in order to collate this crowdsourced information, and survey the history of this identity, all the known proofs (we collect seven distinct ways to prove the identity (or generalisations thereof)), and all the applications of it that we are currently aware of. The citation graph of the literature that this ad hoc crowdsourcing effort produced is only very weakly connected, which we found surprising:
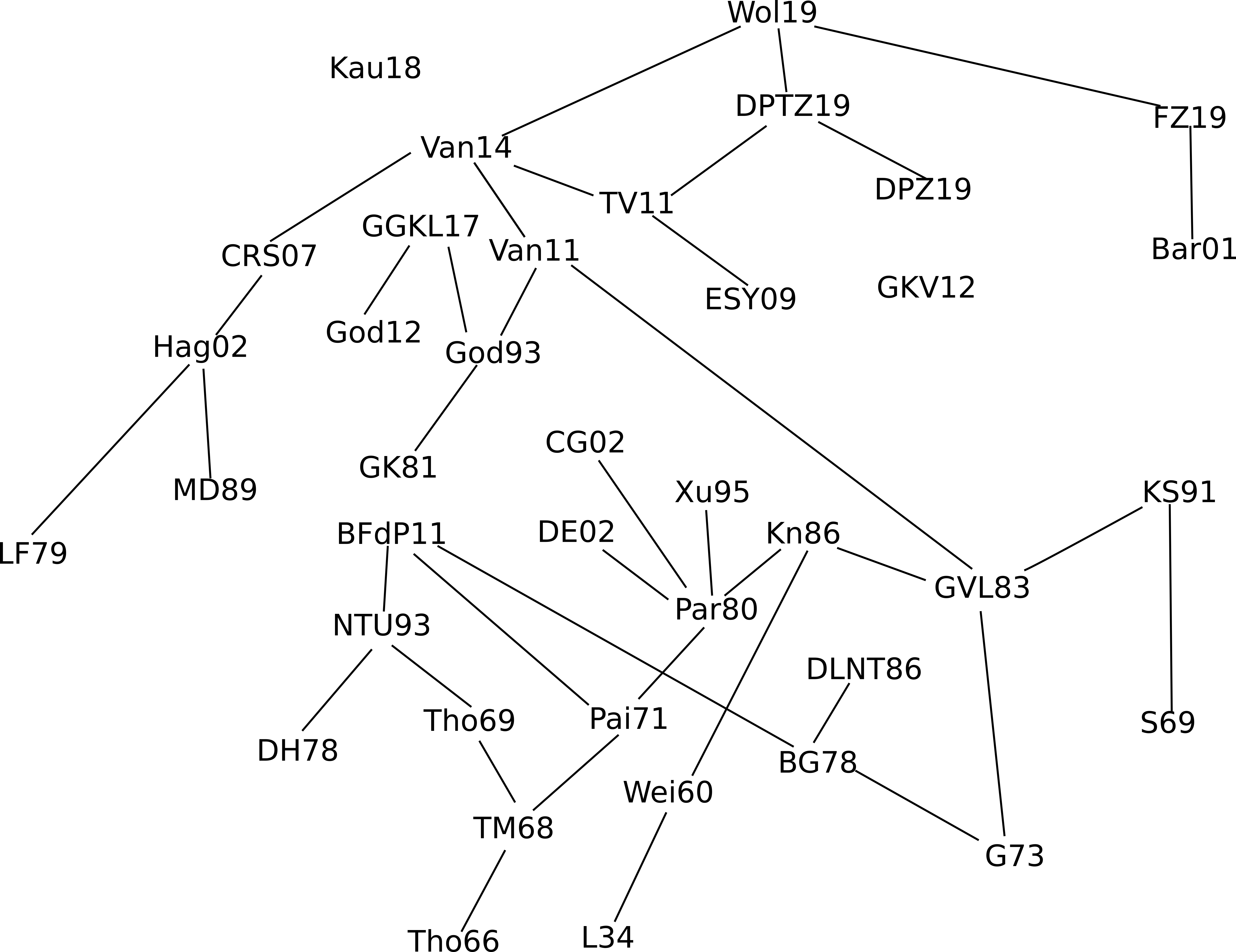
The earliest explicit appearance of the eigenvector-eigenvalue identity we are now aware of is in a 1966 paper of Thompson, although this paper is only cited (directly or indirectly) by a fraction of the known literature, and also there is a precursor identity of Löwner from 1934 that can be shown to imply the identity as a limiting case. At the end of the paper we speculate on some possible reasons why this identity only achieved a modest amount of recognition and dissemination prior to the November 2019 Quanta article.
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv the short unpublished note “Eigenvectors from eigenvalues“. This note gives two proofs of a general eigenvector identity observed recently by Denton, Parke and Zhang in the course of some quantum mechanical calculations. The identity is as follows:
Theorem 1 Let
where
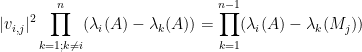
For instance, if we have
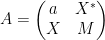
for some real number 


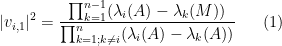
assuming that the denominator is non-zero.
Once one is aware of the identity, it is not so difficult to prove it; we give two proofs, each about half a page long, one of which is based on a variant of the Cauchy-Binet formula, and the other based on properties of the adjugate matrix. But perhaps it is surprising that such a formula exists at all; one does not normally expect to learn much information about eigenvectors purely from knowledge of eigenvalues. In the random matrix theory literature, for instance in this paper of Erdos, Schlein, and Yau, or this later paper of Van Vu and myself, a related identity has been used, namely
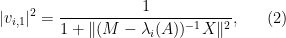
but it is not immediately obvious that one can derive the former identity from the latter. (I do so below the fold; we ended up not putting this proof in the note as it was longer than the two other proofs we found. I also give two other proofs below the fold, one from a more geometric perspective and one proceeding via Cramer’s rule.) It was certainly something of a surprise to me that there is no explicit appearance of the 
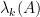

One can get some feeling of the identity (1) by considering some special cases. Suppose for instance that 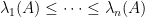
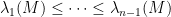
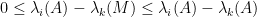
for 
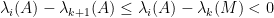
for 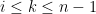

(This post is mostly intended for my own reference, as I found myself repeatedly looking up several conversions between polynomial bases on various occasions.)
Let 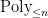


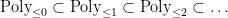
A standard basis for these vector spaces are given by the monomials 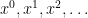
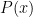

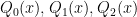
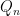

In particular, if we have two such sequences 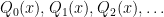

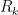


for some change of basis coefficients 
Many standard combinatorial quantities 
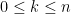
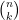
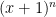
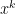

thus for instance

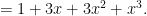
More generally, for any shift 
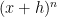
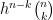
But there are other bases of interest too. For instance if one uses the falling factorial basis

then the conversion from falling factorials to monomials is given by the Stirling numbers of the first kind 
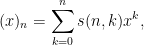
thus for instance
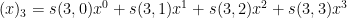

and the conversion back is given by the Stirling numbers of the second kind 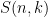

thus for instance


If one uses the binomial functions 

and
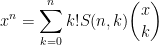
thus for instance

and

As a slight variant, if one instead uses rising factorials

then the conversion to monomials yields the unsigned Stirling numbers 
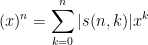
thus for instance
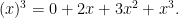
One final basis comes from the polylogarithm functions

For instance one has






and more generally one has
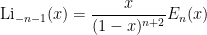
for all natural numbers 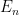

For instance


These particular coefficients also have useful combinatorial interpretations. For instance:
- The binomial coefficient
.
- The unsigned Stirling numbers
.
- The Stirling numbers
- The Eulerian numbers
are the number of permutations of
These coefficients behave similarly to each other in several ways. For instance, the binomial coefficients

(with the convention that

and the signed counterparts
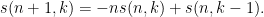
The Stirling numbers of the second kind
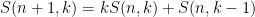
and the Eulerian numbers
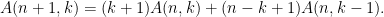
While talking mathematics with a postdoc here at UCLA (March Boedihardjo) we came across the following matrix problem which we managed to solve, but the proof was cute and the process of discovering it was fun, so I thought I would present the problem here as a puzzle without revealing the solution for now.
The problem involves word maps on a matrix group, which for sake of discussion we will take to be the special orthogonal group 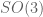
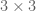

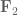


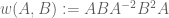
for 
Anyway, here is the problem:
Problem. Does there exist a sequence
of non-trivial word maps
that converge uniformly to the identity map?
To put it another way, given any 
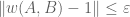


As I said, I don’t want to spoil the fun of working out this problem, so I will leave it as a challenge. Readers are welcome to share their thoughts, partial solutions, or full solutions in the comments below.

Recent Comments