
You are currently browsing the monthly archive for July 2015.
This week I have been at a Banff workshop “Combinatorics meets Ergodic theory“, focused on the combinatorics surrounding Szemerédi’s theorem and the Gowers uniformity norms on one hand, and the ergodic theory surrounding Furstenberg’s multiple recurrence theorem and the Host-Kra structure theory on the other. This was quite a fruitful workshop, and directly inspired the various posts this week on this blog. Incidentally, BIRS being as efficient as it is, videos for this week’s talks are already online.
As mentioned in the previous two posts, Ben Green, Tamar Ziegler, and myself proved the following inverse theorem for the Gowers norms:
Theorem 1 (Inverse theorem for Gowers norms) Let
and
be integers, and let
. Suppose that
is a function supported on
such that
Then there exists a filtered nilmanifold
of degree
and complexity
, a polynomial sequence
, and a Lipschitz function
of Lipschitz constant


There is a higher dimensional generalisation, which first appeared explicitly (in a more general form) in this preprint of Szegedy (which used a slightly different argument than the one of Ben, Tammy, and myself; see also this previous preprint of Szegedy with related results):
Theorem 2 (Inverse theorem for multidimensional Gowers norms) Let
be integers, and let
is a function supported on
such that
Then there exists a filtered nilmanifold
, a polynomial sequence
, and a Lipschitz function


The 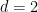
In this post I would like to record a very neat and simple observation of Ben Green and Nikos Frantzikinakis, that uses the tool of Freiman isomorphisms to derive Theorem 2 as a corollary of the one-dimensional theorem. Namely, consider the linear map 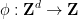
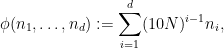
that is to say 
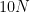
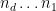
![{[d 10^d N^d]}](https://s0.wp.com/latex.php?latex=%7B%5Bd+10%5Ed+N%5Ed%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



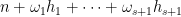
![{\phi( [N]^d )}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28+%5BN%5D%5Ed+%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)

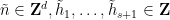
![\displaystyle \tilde n + \omega_1 \tilde h_1 + \dots + \omega_{s+1} \tilde h_{s+1} \in [N]^d](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctilde+n+%2B+%5Comega_1+%5Ctilde+h_1+%2B+%5Cdots+%2B+%5Comega_%7Bs%2B1%7D+%5Ctilde+h_%7Bs%2B1%7D+%5Cin+%5BN%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002)
and
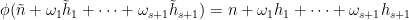
for all 

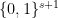
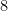
Now let ![{\tilde f: {\bf Z} \rightarrow [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Ctilde+f%3A+%7B%5Cbf+Z%7D+%5Crightarrow+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
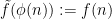
![{n \in [N]^d}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5BN%5D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)
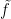
![{\phi([N]^d)}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28%5BN%5D%5Ed%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Applying the one-dimensional inverse theorem (Theorem 1), with 
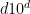

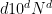
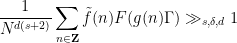
which by the Freiman isomorphism property again implies that
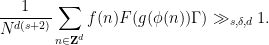
But the map 
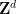

Remark 3 This trick appears to be largely restricted to the case of boundedly generated groups such as
from the
Remark 4 By combining this argument with the one in the previous post, one can obtain a weak ergodic inverse theorem for
Note: this post is of a particularly technical nature, in particular presuming familiarity with nilsequences, nilsystems, characteristic factors, etc., and is primarily intended for experts.
As mentioned in the previous post, Ben Green, Tamar Ziegler, and myself proved the following inverse theorem for the Gowers norms:
Theorem 1 (Inverse theorem for Gowers norms) Let
Then there exists a filtered nilmanifold
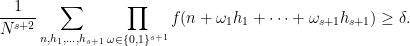
This result was conjectured earlier by Ben Green and myself; this conjecture was strongly motivated by an analogous inverse theorem in ergodic theory by Host and Kra, which we formulate here in a form designed to resemble Theorem 1 as closely as possible:
Theorem 2 (Inverse theorem for Gowers-Host-Kra seminorms) Let
be an ergodic, countably generated measure-preserving system. Suppose that one has
for all non-zero
(all
spaces are real-valued in this post). Then
is an inverse limit (in the category of measure-preserving systems, up to almost everywhere equivalence) of ergodic degree
for some degree
that acts ergodically on
![\displaystyle \lim_{N \rightarrow \infty} \frac{1}{N^{s+1}} \sum_{h_1,\dots,h_{s+1} \in [N]} \int_X \prod_{\omega \in \{0,1\}^{s+1}} f(T^{\omega_1 h_1 + \dots + \omega_{s+1} h_{s+1}}x)\ d\mu(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B1%7D%7BN%5E%7Bs%2B1%7D%7D+%5Csum_%7Bh_1%2C%5Cdots%2Ch_%7Bs%2B1%7D+%5Cin+%5BN%5D%7D+%5Cint_X+%5Cprod_%7B%5Comega+%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bs%2B1%7D%7D+f%28T%5E%7B%5Comega_1+h_1+%2B+%5Cdots+%2B+%5Comega_%7Bs%2B1%7D+h_%7Bs%2B1%7D%7Dx%29%5C+d%5Cmu%28x%29+&bg=ffffff&fg=000000&s=0&c=20201002)

It is a natural question to ask if there is any logical relationship between the two theorems. In the finite field category, one can deduce the combinatorial inverse theorem from the ergodic inverse theorem by a variant of the Furstenberg correspondence principle, as worked out by Tamar Ziegler and myself, however in the current context of
One can split Theorem 2 into two components:
Theorem 3 (Weak inverse theorem for Gowers-Host-Kra seminorms) Let
for all non-zero
. Then
![\displaystyle \lim_{N \rightarrow \infty} \frac{1}{N^{s+1}} \sum_{h_1,\dots,h_{s+1} \in [N]} \int_X \prod_{\omega \in \{0,1\}^{s+1}} T^{\omega_1 h_1 + \dots + \omega_{s+1} h_{s+1}} f\ d\mu](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7BN+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B1%7D%7BN%5E%7Bs%2B1%7D%7D+%5Csum_%7Bh_1%2C%5Cdots%2Ch_%7Bs%2B1%7D+%5Cin+%5BN%5D%7D+%5Cint_X+%5Cprod_%7B%5Comega+%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bs%2B1%7D%7D+T%5E%7B%5Comega_1+h_1+%2B+%5Cdots+%2B+%5Comega_%7Bs%2B1%7D+h_%7Bs%2B1%7D%7D+f%5C+d%5Cmu&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 4 (Pro-nilsystems closed under factors) Let
Indeed, it is clear that Theorem 2 implies both Theorem 3 and Theorem 4, and conversely that the two latter theorems jointly imply the former. Theorem 4 is, in principle, purely a fact about nilsystems, and should have an independent proof, but this is not known; the only known proofs go through the full machinery needed to prove Theorem 2 (or the closely related theorem of Ziegler). (However, the fact that a factor of a nilsystem is again a nilsystem was established previously by Parry.)
The purpose of this post is to record a partial implication in reverse direction to the correspondence principle:
As mentioned at the start of the post, a fair amount of familiarity with the area is presumed here, and some routine steps will be presented with only a fairly brief explanation.
A few years ago, Ben Green, Tamar Ziegler, and myself proved the following (rather technical-looking) inverse theorem for the Gowers norms:
Theorem 1 (Discrete inverse theorem for Gowers norms) Let
Then there exists a filtered nilmanifold
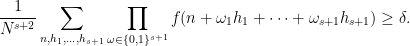

For the definitions of “filtered nilmanifold”, “degree”, “complexity”, and “polynomial sequence”, see the paper of Ben, Tammy, and myself. (I should caution the reader that this blog post will presume a fair amount of familiarity with this subfield of additive combinatorics.) This result has a number of applications, for instance to establishing asymptotics for linear equations in the primes, but this will not be the focus of discussion here.
The purpose of this post is to record the observation that this “discrete” inverse theorem, together with an equidistribution theorem for nilsequences that Ben and I worked out in a separate paper, implies a continuous version:
Theorem 2 (Continuous inverse theorem for Gowers norms) Let
. Suppose that
is a measurable function supported on
such that
Then there exists a filtered nilmanifold
, and a Lipschitz function


The interval 


It is likely that one could prove Theorem 2 by carefully going through the proof of Theorem 1 and replacing all instances of 
![{\frac{1}{N} \cdot [N]}](https://s0.wp.com/latex.php?latex=%7B%5Cfrac%7B1%7D%7BN%7D+%5Ccdot+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Szemerédi’s theorem asserts that any subset of the integers of positive upper density contains arbitrarily large arithmetic progressions. Here is an equivalent quantitative form of this theorem:
Theorem 1 (Szemerédi’s theorem) Let
be a function with
for some
,
, etc.. Then for
we have
for some
depending only on
.

The equivalence is basically thanks to an averaging argument of Varnavides; see for instance Chapter 11 of my book with Van Vu or this previous blog post for a discussion. We have removed the cases 
There are now many proofs of this theorem. Some time ago, I took an ergodic-theoretic proof of Furstenberg and converted it to a purely finitary proof of the theorem. The argument used some simplifying innovations that had been developed since the original work of Furstenberg (in particular, deployment of the Gowers uniformity norms, as well as a “dual” norm that I called the uniformly almost periodic norm, and an emphasis on van der Waerden’s theorem for handling the “compact extension” component of the argument). But the proof was still quite messy. However, as discussed in this previous blog post, messy finitary proofs can often be cleaned up using nonstandard analysis. Thus, there should be a nonstandard version of the Furstenberg ergodic theory argument that is relatively clean. I decided (after some encouragement from Ben Green and Isaac Goldbring) to write down most of the details of this argument in this blog post, though for sake of brevity I will skim rather quickly over arguments that were already discussed at length in other blog posts. In particular, I will presume familiarity with nonstandard analysis (in particular, the notion of a standard part of a bounded real number, and the Loeb measure construction), see for instance this previous blog post for a discussion.
In analytic number theory, there is a well known analogy between the prime factorisation of a large integer, and the cycle decomposition of a large permutation; this analogy is central to the topic of “anatomy of the integers”, as discussed for instance in this survey article of Granville. Consider for instance the following two parallel lists of facts (stated somewhat informally). Firstly, some facts about the prime factorisation of large integers:
- Every positive integer
has a prime factorisation
into (not necessarily distinct) primes
, which is unique up to rearrangement. Taking logarithms, we obtain a partition
of
.
- (Prime number theorem) A randomly selected integer
will be prime with probability
when
- If
is a randomly selected prime factor of
(with each index
being chosen with probability
), then
is approximately uniformly distributed between
and
. (See Proposition 9 of this previous blog post.)
- The set of real numbers
arising from the prime factorisation


Now for the facts about the cycle decomposition of large permutations:
- Every permutation
has a cycle decomposition
into disjoint cycles
, which is unique up to rearrangement, and where we count each fixed point of
as a cycle of length
. If
is the length of the cycle
, we obtain a partition
of
.
- (Prime number theorem for permutations) A randomly selected permutation of
will be an
. (This was noted in this previous blog post.)
- If
), then
. (See Proposition 8 of this blog post.)
- The set of real numbers
arising from the cycle decomposition
of a random permutation
. (Again, see this previous blog post for details.)


See this previous blog post (or the aforementioned article of Granville, or the Notices article of Arratia, Barbour, and Tavaré) for further exploration of the analogy between prime factorisation of integers and cycle decomposition of permutations.
There is however something unsatisfying about the analogy, in that it is not clear why there should be such a kinship between integer prime factorisation and permutation cycle decomposition. It turns out that the situation is clarified if one uses another fundamental analogy in number theory, namely the analogy between integers and polynomials ![{P \in {\mathbf F}_q[T]}](https://s0.wp.com/latex.php?latex=%7BP+%5Cin+%7B%5Cmathbf+F%7D_q%5BT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
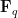

- Every monic polynomial
has a factorisation
into irreducible monic polynomials
, which is unique up to rearrangement. Taking degrees, we obtain a partition
of
.
- (Prime number theorem for polynomials) A randomly selected monic polynomial
when
is fixed and
- If
is a random irreducible factor of
(with each
), then
is approximately uniformly distributed in
- The set of real numbers
arising from the factorisation


The above list of facts addressed the large ![{{\mathbf F}_q[T]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbf+F%7D_q%5BT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The large
Theorem 1 (Prime number theorem) The probability that a random monic polynomial
in the limit where
Proof: There are 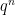
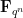

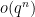


Remark 2 The above argument and inclusion-exclusion in fact gives the well known exact formula
for the number of irreducible monic polynomials of degree
Now we can give a precise connection between the cycle distribution of a random permutation, and (the large
Theorem 3 The partition
of a random monic polynomial
of degree
of a random permutation
of length
We can quickly prove this theorem as follows. We first need a basic fact:
Lemma 4 (Most polynomials square-free in large
when
of degree
will be coprime with probability
Proof: For any polynomial 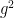

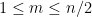
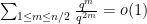

Now we can prove the theorem. Elementary combinatorics tells us that the probability of a random permutation 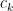


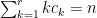
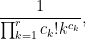
since there are 

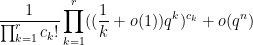
which simplifies to

and the claim follows.
This was a fairly short calculation, but it still doesn’t quite explain why there is such a link between the cycle decomposition 

I recently found (after some discussions with Ben Green) what I feel to be a satisfying conceptual (as opposed to computational) explanation of this link, which I will place below the fold.
I’ve just uploaded to the arXiv my paper “Inverse theorems for sets and measures of polynomial growth“. This paper was motivated by two related questions. The first question was to obtain a qualitatively precise description of the sets of polynomial growth that arise in Gromov’s theorem, in much the same way that Freiman’s theorem (and its generalisations) provide a qualitatively precise description of sets of small doubling. The other question was to obtain a non-abelian analogue of inverse Littlewood-Offord theory.
Let me discuss the former question first. Gromov’s theorem tells us that if a finite subset 
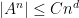


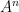

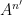
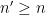

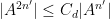
In this paper we are able to refine this analysis a bit further; under the same hypotheses, we can show an estimate of the form

for all 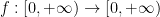



One could ask whether the function 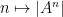
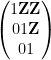
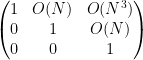
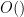
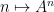
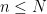
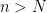
To prove this proposition, it turns out (after using a somewhat difficult inverse theorem proven previously by Breuillard, Green, and myself) that one has to analyse the volume growth 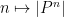
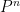
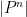
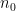
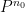
The arguments also give a precise description of the location of a set 
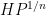

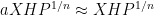
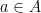

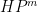
The main tool used to prove these results is the structure theorem for approximate groups established by Breuillard, Green, and myself, which roughly speaking asserts that approximate groups are always commensurate with coset nilprogressions. A key additional trick is a pigeonholing argument of Sanders, which in this context is the assertion that if 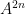
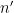

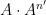
Similar arguments apply when discussing iterated convolutions 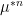
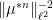


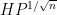

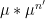
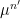
A special case of this theory occurs when 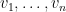







Just a short post here to note that the cover story of this month’s Notices of the AMS, by John Friedlander, is about the recent work on bounded gaps between primes by Zhang, Maynard, our own Polymath project, and others.
I may as well take this opportunity to upload some slides of my own talks on this subject: here are my slides on small and large gaps between the primes that I gave at the “Latinos in the Mathematical Sciences” back in April, and here are my slides on the Polymath project for the Schock Prize symposium last October. (I also gave an abridged version of the latter talk at an AAAS Symposium in February, as well as the Breakthrough Symposium from last November.)

Recent Comments