
You are currently browsing the tag archive for the ‘finite fields’ tag.
In analytic number theory, there is a well known analogy between the prime factorisation of a large integer, and the cycle decomposition of a large permutation; this analogy is central to the topic of “anatomy of the integers”, as discussed for instance in this survey article of Granville. Consider for instance the following two parallel lists of facts (stated somewhat informally). Firstly, some facts about the prime factorisation of large integers:
- Every positive integer
has a prime factorisation
into (not necessarily distinct) primes
, which is unique up to rearrangement. Taking logarithms, we obtain a partition
of
.
- (Prime number theorem) A randomly selected integer
will be prime with probability
when
is large.
- If
is a randomly selected prime factor of
(with each index
being chosen with probability
), then
is approximately uniformly distributed between
and
. (See Proposition 9 of this previous blog post.)
- The set of real numbers
arising from the prime factorisation
. (See the previously mentioned blog post for a definition of the Poisson-Dirichlet process, and a proof of this claim.)


Now for the facts about the cycle decomposition of large permutations:
- Every permutation
has a cycle decomposition
into disjoint cycles
, which is unique up to rearrangement, and where we count each fixed point of
as a cycle of length
. If
is the length of the cycle
, we obtain a partition
of
.
- (Prime number theorem for permutations) A randomly selected permutation of
will be an
. (This was noted in this previous blog post.)
- If
), then
. (See Proposition 8 of this blog post.)
- The set of real numbers
arising from the cycle decomposition
of a random permutation
. (Again, see this previous blog post for details.)


See this previous blog post (or the aforementioned article of Granville, or the Notices article of Arratia, Barbour, and Tavaré) for further exploration of the analogy between prime factorisation of integers and cycle decomposition of permutations.
There is however something unsatisfying about the analogy, in that it is not clear why there should be such a kinship between integer prime factorisation and permutation cycle decomposition. It turns out that the situation is clarified if one uses another fundamental analogy in number theory, namely the analogy between integers and polynomials ![{P \in {\mathbf F}_q[T]}](https://s0.wp.com/latex.php?latex=%7BP+%5Cin+%7B%5Cmathbf+F%7D_q%5BT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
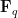

- Every monic polynomial
has a factorisation
into irreducible monic polynomials
, which is unique up to rearrangement. Taking degrees, we obtain a partition
of
.
- (Prime number theorem for polynomials) A randomly selected monic polynomial
when
is fixed and
- If
is a random irreducible factor of
(with each
), then
is approximately uniformly distributed in
- The set of real numbers
arising from the factorisation


The above list of facts addressed the large ![{{\mathbf F}_q[T]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbf+F%7D_q%5BT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


The large
Theorem 1 (Prime number theorem) The probability that a random monic polynomial
in the limit where
Proof: There are 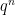

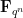

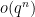


Remark 2 The above argument and inclusion-exclusion in fact gives the well known exact formula
for the number of irreducible monic polynomials of degree
Now we can give a precise connection between the cycle distribution of a random permutation, and (the large
Theorem 3 The partition
of a random monic polynomial
of degree
of a random permutation
of length
We can quickly prove this theorem as follows. We first need a basic fact:
Lemma 4 (Most polynomials square-free in large
when
of degree
will be coprime with probability
Proof: For any polynomial 
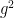

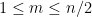
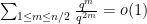

Now we can prove the theorem. Elementary combinatorics tells us that the probability of a random permutation 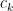


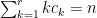
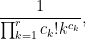
since there are 

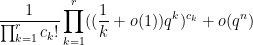
which simplifies to

and the claim follows.
This was a fairly short calculation, but it still doesn’t quite explain why there is such a link between the cycle decomposition 

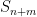
I recently found (after some discussions with Ben Green) what I feel to be a satisfying conceptual (as opposed to computational) explanation of this link, which I will place below the fold.
Let 
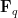

where 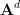


![{V[{\bf F}_q]}](https://s0.wp.com/latex.php?latex=%7BV%5B%7B%5Cbf+F%7D_q%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{V[{\bf F}_{q^n}]}](https://s0.wp.com/latex.php?latex=%7BV%5B%7B%5Cbf+F%7D_%7Bq%5En%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
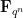

![\displaystyle V[{\bf F}_{q^n}] := \{ x \in {\bf F}_{q^n}^d: P_1(x) = \dots = P_m(x) = 0\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5B%7B%5Cbf+F%7D_%7Bq%5En%7D%5D+%3A%3D+%5C%7B+x+%5Cin+%7B%5Cbf+F%7D_%7Bq%5En%7D%5Ed%3A+P_1%28x%29+%3D+%5Cdots+%3D+P_m%28x%29+%3D+0%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
The Weil conjectures are concerned with understanding the number
![\displaystyle S_n := |V[{\bf F}_{q^n}]| \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++S_n+%3A%3D+%7CV%5B%7B%5Cbf+F%7D_%7Bq%5En%7D%5D%7C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
of
Theorem 1 (Rationality of the zeta function) Let
(known as characteristic values of
for all

After cancelling, we may of course assume that 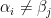
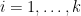



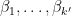










An equivalent way of phrasing Dwork’s theorem is that the (
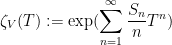
associated to 
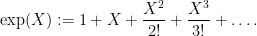
Equivalently, the (


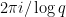
Dwork’s argument relies primarily on 



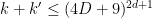

These
Theorem 2 (Riemann hypothesis) Let
be a characteristic value of
such that
for every embedding
denotes the usual absolute value on the complex numbers
and all of its Galois conjugates have complex magnitude
.)
To put it another way that closely resembles the classical Riemann hypothesis, all the zeroes and poles of the 

In this post, I would like to record my notes on Dwork’s proof of Theorem 1, drawing heavily on the expositions of Serre, Hooley, Koblitz, and others.
The basic strategy is to control the rational integers 
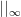


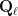
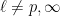
Proposition 3 (Archimedean control of
for all
independent of

Proof: Since 


Another way of thinking about this Archimedean control is that it guarantees that the zeta function 

The
Proposition 4 (
(defined later) with
a finite number of elements
such that
for all

Another way of thinking about this
Proposition 4 is ostensibly much weaker than Theorem 1 because of (a) the error term of 


The proof of Proposition 4 can be split into two pieces. The first piece, which can be viewed as the number-theoretic component of the proof, uses external descriptions of
Proposition 5 (Decomposition of
and
as a finite linear combination (over the integers) of sequences
, such that for each such sequence
, the zeta functions
are entire in
as


This proposition will ultimately be a consequence of the properties of the Teichmuller lifting 
The second piece, which can be viewed as the “
Proposition 6 (
is entire in
such that
for all
.
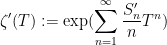
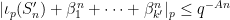
Clearly, the combination of Proposition 5 and Proposition 6 (and the non-Archimedean nature of the
Let 


![\displaystyle C = \{ [x,y,z]: y^2 z = x^3 + ax z^2 + b z^3 \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C+%3D+%5C%7B+%5Bx%2Cy%2Cz%5D%3A+y%5E2+z+%3D+x%5E3+%2B+ax+z%5E2+%2B+b+z%5E3+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
in the projective plane ![{{\bf P}^2 = \{ [x,y,z]: (x,y,z) \neq (0,0,0) \}}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+P%7D%5E2+%3D+%5C%7B+%5Bx%2Cy%2Cz%5D%3A+%28x%2Cy%2Cz%29+%5Cneq+%280%2C0%2C0%29+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
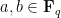

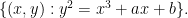
To each such curve 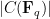
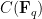
 .
.The usual proofs of this bound proceed by first establishing a trace formula of the form

for some complex numbers 
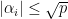

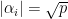
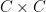
In 1969, Stepanov introduced an elementary method (a version of what is now known as the polynomial method) to count (or at least to upper bound) the quantity
Theorem 2 (Weak Hasse-Weil bound) If
, then
.
In fact, the bound on
Theorem 2 is only an upper bound on 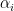
I’ve discussed Bombieri’s proof of Theorem 2 in this previous post (in the special case of hyperelliptic curves), but now wish to present the full proof, with some minor simplifications from Bombieri’s original presentation; it is mostly elementary, with the deepest fact from algebraic geometry needed being Riemann’s inequality (a weak form of the Riemann-Roch theorem).
The first step is to reinterpret 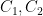

![\displaystyle \hbox{Frob}_q( [x_0,\dots,x_n] ) := [x_0^q, \dots, x_n^q]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chbox%7BFrob%7D_q%28+%5Bx_0%2C%5Cdots%2Cx_n%5D+%29+%3A%3D+%5Bx_0%5Eq%2C+%5Cdots%2C+x_n%5Eq%5D&bg=ffffff&fg=000000&s=0&c=20201002)
then this map preserves the curve
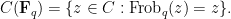
Thus one can interpret

and the Frobenius graph

which are copies of
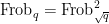
with 

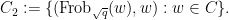
Let 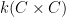
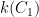

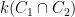
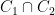
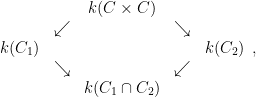
if we ignore the issue that a rational function on, say, 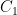
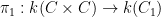


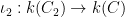
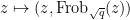

The idea now is to find a rational function 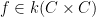

To find this
Now we build 
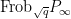
For any natural number 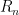

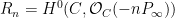
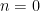
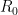
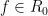
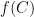
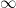
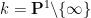

For higher
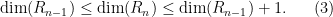
The former inequality just comes from the trivial inclusion 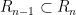
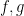


From (3) and induction we see that each of the

Riemann’s inequality complements this with the lower bound

thus one has 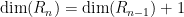

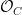
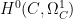
At any rate, now that we have these vector spaces 
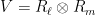
for some natural numbers 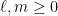
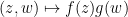
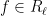
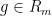
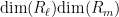


Observe that 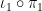
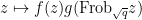
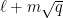
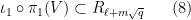
and in particular by (4)

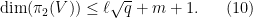
We will choose 
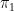

(together with (7)) then
On the other hand, we have the following basic fact:

 is injective.
is injective.Proof: From (3), we can find a linear basis 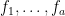
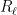

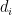

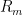
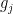
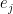
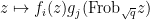
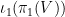
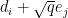

This gives us the following bound:
Proposition 4 Let
be natural numbers such that (7), (11), (12) hold. Then
.
Proof: As 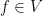
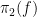
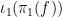
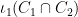
If
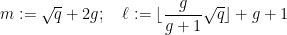
and a brief calculation then gives Theorem 2. In some cases one can optimise things a bit further. For instance, in the genus zero case 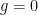


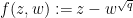
Remark 1 When
is not a perfect square, one can try to run the above argument using the factorisation
instead of
. This gives a weaker version of the above bound, of the shape
. In the hyperelliptic case at least, one can erase this loss by working with a variant of the argument in which one requires
Vitaly Bergelson, Tamar Ziegler, and I have just uploaded to the arXiv our joint paper “Multiple recurrence and convergence results associated to 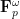
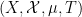
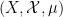
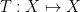
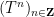
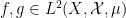

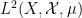
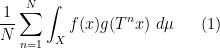
converges as

see e.g. this previous blog post. Informally, one can interpret this limit formula as an equidistribution result: if 

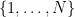


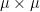
If we allow 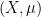
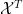
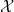
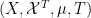
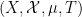



where 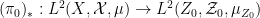
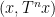



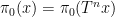
Limit formulae are known for multiple ergodic averages as well, although the statement becomes more complicated. For instance, consider the expression

for three functions 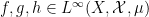
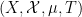

which would roughly speaking correspond to an assertion that the triplet 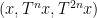


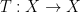
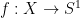

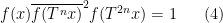
tying together 
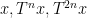

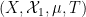
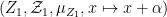
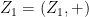
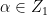
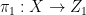
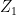
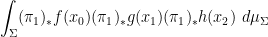
where 
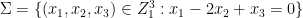
and 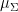

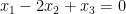
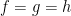
If one considers a quadruple average
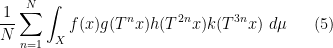
(analogous to counting length four progressions) then the situation becomes more complicated still, even in the ergodic case. In addition to the (linear) eigenfunctions that already showed up in the computation of the triple average (3), a new type of constraint also arises from quadratic eigenfunctions 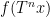
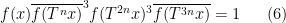
between 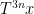
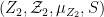
The above discussion was concerned with 
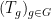
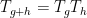

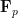
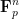
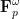
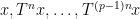
As a consequence, we can recover finite field analogues of most of the results of Bergelson-Host-Kra, though interestingly some of the counterexamples demonstrating sharpness of their results for 

for a syndetic set of 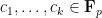




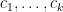
Much as group theory is the study of groups, or graph theory is the study of graphs, model theory is the study of models (also known as structures) of some language 
We will observe the common abuse of notation of using the set 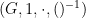
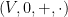



Once one has a structure 


for some formula 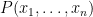



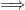
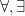

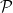
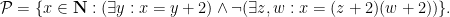
In the theory of the field of reals 
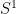
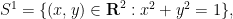
but so is the the complement of the circle,
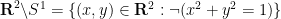
and the interval ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [-1,1] = \{ x \in {\bf R}: \exists y: x^2+y^2 = 1\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B-1%2C1%5D+%3D+%5C%7B+x+%5Cin+%7B%5Cbf+R%7D%3A+%5Cexists+y%3A+x%5E2%2By%5E2+%3D+1%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Due to the unlimited use of constants, any finite subset of a power
We can isolate some special subclasses of definable sets:
- An atomic definable set is a set of the form (1) in which
is an atomic formula (i.e. it does not contain any logical connectives or quantifiers).
- A quantifier-free definable set is a set of the form (1) in which
Example 1 In the theory of a field such as
.
A quantifier-free definable set in 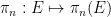
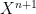
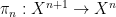

Some structures have the property of enjoying quantifier elimination, which means that every definable set is in fact a quantifier-free definable set, or equivalently that the projection of a quantifier-free definable set is again quantifier-free. For instance, an algebraically closed field 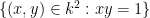
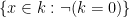
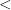
On the other hand, many important structures do not have quantifier elimination; typically, the projection of a quantifier-free definable set is not, in general, quantifier-free definable. This failure of the projection property also shows up in many contexts outside of model theory; for instance, Lebesgue famously made the error of thinking that the projection of a Borel measurable set remained Borel measurable (it is merely an analytic set instead). Turing’s halting theorem can be viewed as an assertion that the projection of a decidable set (also known as a computable or recursive set) is not necessarily decidable (it is merely semi-decidable (or recursively enumerable) instead). The notorious P=NP problem can also be essentially viewed in this spirit; roughly speaking (and glossing over the placement of some quantifiers), it asks whether the projection of a polynomial-time decidable set is again polynomial-time decidable. And so forth. (See this blog post of Dick Lipton for further discussion of the subtleties of projections.)
Now we consider the status of quantifier elimination for the theory of a finite field 
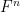
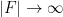


Another way to proceed is to work not with a single finite field 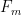
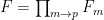

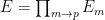
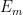

The ultraproduct
As mentioned before, quantifier elimination trivially holds for finite fields. But for infinite pseudo-finite fields, such as the ultraproduct 
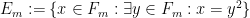

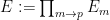

Nevertheless, there is a very nice almost quantifier elimination result for these fields, in characteristic zero at least, which we phrase here as follows:
Theorem 1 (Almost quantifier elimination) Let
be a definable set over
where
is an atomic definable subset of
is a polynomial.

Results of this type were first obtained essentially due to Catarina Kiefe, although the formulation here is closer to that of Chatzidakis-van den Dries-Macintyre.
Informally, this theorem says that while we cannot quite eliminate all quantifiers from a definable set over a nonstandard finite field, we can eliminate all but one existential quantifier. Note that negation has also been eliminated in this theorem; for instance, the definable set 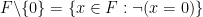


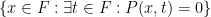
There is an equivalent formulation of this theorem for standard finite fields, namely that if 
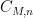
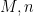
The theorem gives quite a satisfactory description of definable sets in either standard or nonstandard finite fields (at least if one does not care about effective bounds in some of the constants, and if one is willing to exclude the small characteristic case); for instance, in conjunction with the Lang-Weil bound discussed in this recent blog post, it shows that any non-empty definable subset of a nonstandard finite field has a nonstandard cardinality of 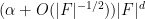
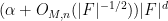
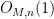
Below the fold I give a proof of Theorem 1, which relies primarily on the Lang-Weil bound mentioned above.
Let 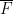

for some ambient dimension 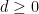

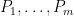
One can consider two crude measures of how “big” the variety 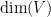





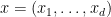
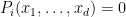
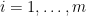
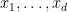
These two measures are linked together in a number of ways. For instance, we have the basic Schwarz-Zippel type bound (which, in this qualitative form, goes back at least to Lemma 1 of the work of Lang and Weil in 1954).
Lemma 1 (Schwarz-Zippel type bound) Let
.
Proof: (Sketch) For the purposes of exposition, we will not carefully track the dependencies of implied constants on the complexity
We argue by induction on the ambient dimension 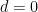
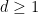


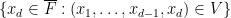
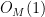
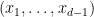
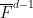
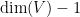

One can improve the bound on the implied constant to be linear in the degree of
Without further hypotheses on

where 
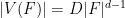
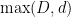



clearly has no 

which is the union of two hyperplanes, still has no
Theorem 2 (Lang-Weil bound) Let
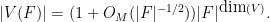
Again, more explicit bounds on the implied constant here are known, but will not be the focus of this post. As the previous examples show, the hypotheses of definability over
The Lang-Weil bound is already non-trivial in the model case 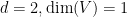
Theorem 3 (Hasse-Weil bound) Let
be an irreducible polynomial of degree
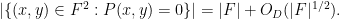
Thus, for instance, if 


The hypotheses of definability over
Corollary 4 (Lang-Weil bound, alternate form) Let
where
is the number of top-dimensional components of
that defines

Proof: By breaking up a general variety 

Note that if 
Example 1 Consider the variety
for some non-zero parameter
. Geometrically (by which we basically mean “when viewed over the algebraically closed field
in this case. If
in this case.

Corollary 4 effectively computes (at least to leading order) the number-theoretic size 




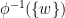

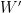


Now suppose that 


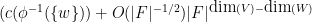


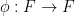

Now we describe the asymptotic distribution of the 
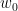




Theorem 5 (Lang-Weil with parameters) Let
be varieties of complexity at most
for
values of
, where
that are invariant under
, where
) and
This theorem generalises Corollary 4 (which is the case when
Example 2 Let
for some fixed
; to avoid some technical issues let us suppose that
, and for a base point
we can take
. The fibre
– the
roots of unity – can be identified with the cyclic group
by using a primitive root of unity. The étale fundamental group
is (I think) isomorphic to the profinite closure
of the integers
of
by a power of the characteristic, the etale fundamental group is more complicated than just a profinite closure of the ordinary fundamental group, due to the presence of Artin-Schreier covers that are only ramified at infinity.) The action of this fundamental group on the fibres
on
chosen uniformly at random from
of
and
, and when this occurs, the number of
Example 3 (Thanks to Jordan Ellenberg for this example.) Consider a random elliptic curve
, where
are chosen uniformly at random, and let
be the
with
using the elliptic curve addition law); as a group, this is isomorphic to
(assuming that
. In this case, the base variety
, and the covering variety
. The generic fibre here can be identified with
, and the action of Frobenius on this fibre can be shown to be given by a
matrix with determinant
Theorem 5 seems to be well known “folklore” among arithmetic geometers, though I do not know of an explicit reference for it. I enjoyed deriving it for myself (though my derivation is somewhat incomplete due to my lack of understanding of étale cohomology) from the ordinary Lang-Weil theorem and the moment method. I’m recording this derivation later in this post, mostly for my own benefit (as I am still in the process of learning this material), though perhaps some other readers may also be interested in it.
Caveat: not all details are fully fleshed out in this writeup, particularly those involving the finer points of algebraic geometry and étale cohomology, as my understanding of these topics is not as complete as I would like it to be.
Many thanks to Brian Conrad and Jordan Ellenberg for helpful discussions on these topics.
Ben Green and I have just uploaded to the arXiv our paper “New bounds for Szemeredi’s theorem, Ia: Progressions of length 4 in finite field geometries revisited“, submitted to Proc. Lond. Math. Soc.. This is both an erratum to, and a replacement for, our previous paper “New bounds for Szemeredi’s theorem. I. Progressions of length 4 in finite field geometries“. The main objective in both papers is to bound the quantity 


and the more complicated “expensive” argument gave the improvement

for some constant 
Unfortunately, while the cheap argument is correct, we discovered a subtle but serious gap in our expensive argument in the original paper. Roughly speaking, the strategy in that argument is to employ the density increment method: one begins with a large subset 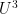
The error in the paper was to conclude from this that the original function 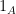
After trying unsuccessfully to repair this error, we eventually found an alternate argument, based on earlier papers of ourselves and of Bergelson-Host-Kra, that avoided the density increment method entirely and ended up giving a simpler proof of a stronger result than (1), and also gives the explicit value of 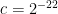

Theorem 1 Let
such that the number of (possibly degenerate) progressions
in
is at least
.
The bound (1) is an easy consequence of this theorem after choosing 
The main new idea is to work with a local Koopman-von Neumann theorem rather than a global one, trading a relatively weak global approximation to 
Tamar Ziegler and I have just uploaded to the arXiv our paper “The inverse conjecture for the Gowers norm over finite fields in low characteristic“, submitted to Annals of Combinatorics. This paper completes another case of the inverse conjecture for the Gowers norm, this time for vector spaces 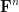

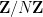
![{[N]}](https://s0.wp.com/latex.php?latex=%7B%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The statement of the main theorem is as follows. Given a finite-dimensional vector space 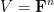
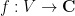
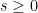
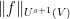
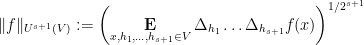
where 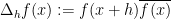

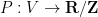
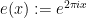
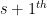
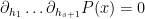
for all 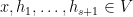

Theorem 1 (Inverse conjecture) Let
for some
, where
is a positive quantity depending only on the indicated parameters.
This theorem is trivial for 
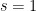


In our previous paper with Bergelson, a “weak” version of the above theorem was proven, in which the polynomial 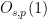
Theorem 2 (Inverse conjecture for polynomials) Let
be a non-classical polynomial of degree at most
such that
. Then
polynomials of degree at most
This type of inverse theorem was first introduced by Bogdanov and Viola. The deduction of Theorem 1 from Theorem 2 and the weak inverse Gowers conjecture is fairly standard, so the main difficulty is to show Theorem 2.
The quantity 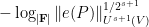
We tried a number of ways to show that bounded analytic rank implied bounded rank, in particular spending a lot of time on ergodic-theoretic approaches, but eventually we settled on a “brute force” approach that relies on classifying those polynomials of bounded analytic rank as precisely as possible. The argument splits up into establishing three separate facts:
- (Classical case) If a classical polynomial has bounded analytic rank, then it has bounded rank.
- (Multiplication by
(which can be shown to have degree at most
) also has bounded analytic rank.
- (Division by
is a non-clsasical polynomial of degree
.
The multiplication by 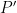
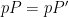
Of the three claims, the multiplication-by-
The next easiest claim is the classical case. Here, the idea is to analyse a degree 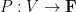
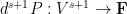

for any 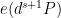

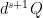
The trickiest thing to establish is the division by 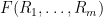
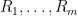
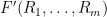


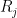
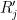
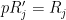
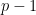

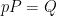
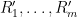
In the previous lectures, we have focused mostly on the equidistribution or linear patterns on a subset of the integers 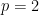
The additive combinatorics of the integers 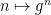
The starting point for this course (Notes 1) was the study of equidistribution of polynomials 
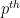
Jean-Pierre Serre (whose papers are, of course, always worth reading) recently posted a lovely lecture on the arXiv entitled “How to use finite fields for problems concerning infinite fields“. In it, he describes several ways in which algebraic statements over fields of zero characteristic, such as 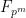
One deduction of this type is based on the idea that positive characteristic fields can partially model zero characteristic fields, and proceeds like this: if a certain algebraic statement failed over (say)
Algebra is definitely not my own field of expertise, but it is interesting to note that similar themes have also come up in my own area of additive combinatorics (and more generally arithmetic combinatorics), because the combinatorics of addition and multiplication on finite sets is definitely of a “finitary algebraic” nature. For instance, a recent paper of Vu, Wood, and Wood establishes a finitary “Freiman-type” homomorphism from (finite subsets of) the complex numbers to large finite fields that allows them to pull back many results in arithmetic combinatorics in finite fields (e.g. the sum-product theorem) to the complex plane. (Van Vu and I also used a similar trick to control the singularity property of random sign matrices by first mapping them into finite fields in which cardinality arguments became available.) And I have a particular fondness for correspondences between finitary and infinitary mathematics; the correspondence Serre discusses is slightly different from the one I discuss for instance in here or here, although there seems to be a common theme of “compactness” (or of model theory) tying these correspondences together.
As one of his examples, Serre cites one of my own favourite results in algebra, discovered independently by Ax and by Grothendieck (and then rediscovered many times since). Here is a special case of that theorem:
Theorem 1 (Ax-Grothendieck theorem, special case) Let
be a polynomial map from a complex vector space to itself. If
The full version of the theorem allows one to replace 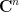
In this post I would like to give the proof of Theorem 1 based on finite fields as mentioned by Serre, as well as another elegant proof of Rudin that combines algebra with some elementary complex variable methods. (There are several other proofs of this theorem and its generalisations, for instance a topological proof by Borel, which I will not discuss here.)
Update, March 8: Some corrections to the finite field proof. Thanks to Matthias Aschenbrenner also for clarifying the relationship with Tarski’s theorem and some further references.
Read the rest of this entry »

Recent Comments