I’ve just uploaded to the arXiv my paper “Almost all Collatz orbits attain almost bounded values“, submitted to the proceedings of the Forum of Mathematics, Pi. In this paper I returned to the topic of the notorious Collatz conjecture (also known as the  conjecture), which I previously discussed in this blog post. This conjecture can be phrased as follows. Let
conjecture), which I previously discussed in this blog post. This conjecture can be phrased as follows. Let 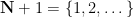 denote the positive integers (with
denote the positive integers (with 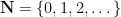 the natural numbers), and let
the natural numbers), and let 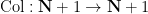 be the map defined by setting
be the map defined by setting 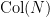 equal to
equal to 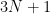 when
when  is odd and
is odd and 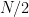 when is even. Let
when is even. Let 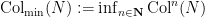 be the minimal element of the Collatz orbit
be the minimal element of the Collatz orbit 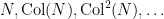 . Then we have
. Then we have
Conjecture 1 (Collatz conjecture) One has  for all
for all 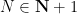 .
.
Establishing the conjecture for all remains out of reach of current techniques (for instance, as discussed in the previous blog post, it is basically at least as difficult as Baker’s theorem, all known proofs of which are quite difficult). However, the situation is more promising if one is willing to settle for results which only hold for “most” in some sense. For instance, it is a result of Krasikov and Lagarias that
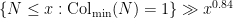
for all sufficiently large  . In another direction, it was shown by Terras that for almost all (in the sense of natural density), one has
. In another direction, it was shown by Terras that for almost all (in the sense of natural density), one has 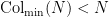 . This was then improved by Allouche to
. This was then improved by Allouche to 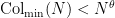 for almost all and any fixed
for almost all and any fixed 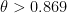 , and extended later by Korec to cover all
, and extended later by Korec to cover all  . In this paper we obtain the following further improvement (at the cost of weakening natural density to logarithmic density):
. In this paper we obtain the following further improvement (at the cost of weakening natural density to logarithmic density):
Theorem 2 Let  be any function with
be any function with 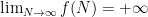 . Then we have
. Then we have  for almost all (in the sense of logarithmic density).
for almost all (in the sense of logarithmic density).
Thus for instance one has 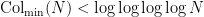 for almost all (in the sense of logarithmic density).
for almost all (in the sense of logarithmic density).
The difficulty here is one usually only expects to establish “local-in-time” results that control the evolution 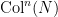 for times
for times  that only get as large as a small multiple
that only get as large as a small multiple 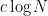 of
of 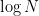 ; the aforementioned results of Terras, Allouche, and Korec, for instance, are of this type. However, to get all the way down to
; the aforementioned results of Terras, Allouche, and Korec, for instance, are of this type. However, to get all the way down to 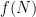 one needs something more like an “(almost) global-in-time” result, where the evolution remains under control for so long that the orbit has nearly reached the bounded state
one needs something more like an “(almost) global-in-time” result, where the evolution remains under control for so long that the orbit has nearly reached the bounded state  .
.
However, as observed by Bourgain in the context of nonlinear Schrödinger equations, one can iterate “almost sure local wellposedness” type results (which give local control for almost all initial data from a given distribution) into “almost sure (almost) global wellposedness” type results if one is fortunate enough to draw one’s data from an invariant measure for the dynamics. To illustrate the idea, let us take Korec’s aforementioned result that if 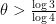 one picks at random an integer from a large interval
one picks at random an integer from a large interval ![{[1,x]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , then in most cases, the orbit of will eventually move into the interval
, then in most cases, the orbit of will eventually move into the interval ![{[1,x^{\theta}]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cx%5E%7B%5Ctheta%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Similarly, if one picks an integer
. Similarly, if one picks an integer  at random from
at random from ![{[1,x^\theta]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cx%5E%5Ctheta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , then in most cases, the orbit of will eventually move into
, then in most cases, the orbit of will eventually move into ![{[1,x^{\theta^2}]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cx%5E%7B%5Ctheta%5E2%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . It is then tempting to concatenate the two statements and conclude that for most in , the orbit will eventually move . Unfortunately, this argument does not quite work, because by the time the orbit from a randomly drawn
. It is then tempting to concatenate the two statements and conclude that for most in , the orbit will eventually move . Unfortunately, this argument does not quite work, because by the time the orbit from a randomly drawn ![{N \in [1,x]}](https://s0.wp.com/latex.php?latex=%7BN+%5Cin+%5B1%2Cx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) reaches , the distribution of the final value is unlikely to be close to being uniformly distributed on , and in particular could potentially concentrate almost entirely in the exceptional set of
reaches , the distribution of the final value is unlikely to be close to being uniformly distributed on , and in particular could potentially concentrate almost entirely in the exceptional set of ![{M \in [1,x^\theta]}](https://s0.wp.com/latex.php?latex=%7BM+%5Cin+%5B1%2Cx%5E%5Ctheta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) that do not make it into . The point here is the uniform measure on is not transported by Collatz dynamics to anything resembling the uniform measure on .
that do not make it into . The point here is the uniform measure on is not transported by Collatz dynamics to anything resembling the uniform measure on .
So, one now needs to locate a measure which has better invariance properties under the Collatz dynamics. It turns out to be technically convenient to work with a standard acceleration of the Collatz map known as the Syracuse map 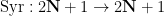 , defined on the odd numbers
, defined on the odd numbers 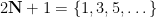 by setting
by setting  , where
, where 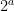 is the largest power of
is the largest power of  that divides . (The advantage of using the Syracuse map over the Collatz map is that it performs precisely one multiplication of
that divides . (The advantage of using the Syracuse map over the Collatz map is that it performs precisely one multiplication of  at each iteration step, which makes the map better behaved when performing “-adic” analysis.)
at each iteration step, which makes the map better behaved when performing “-adic” analysis.)
When viewed -adically, we soon see that iterations of the Syracuse map become somewhat irregular. Most obviously, 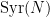 is never divisible by . A little less obviously, is twice as likely to equal mod as it is to equal
is never divisible by . A little less obviously, is twice as likely to equal mod as it is to equal  mod . This is because for a randomly chosen odd
mod . This is because for a randomly chosen odd 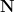 , the number of times
, the number of times 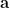 that divides
that divides 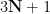 can be seen to have a geometric distribution of mean – it equals any given value
can be seen to have a geometric distribution of mean – it equals any given value 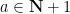 with probability
with probability 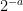 . Such a geometric random variable is twice as likely to be odd as to be even, which is what gives the above irregularity. There are similar irregularities modulo higher powers of . For instance, one can compute that for large random odd ,
. Such a geometric random variable is twice as likely to be odd as to be even, which is what gives the above irregularity. There are similar irregularities modulo higher powers of . For instance, one can compute that for large random odd , 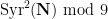 will take the residue classes
will take the residue classes  with probabilities
with probabilities
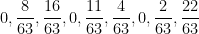
respectively. More generally, for any , 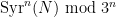 will be distributed according to the law of a random variable
will be distributed according to the law of a random variable 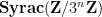 on
on 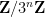 that we call a Syracuse random variable, and can be described explicitly as
that we call a Syracuse random variable, and can be described explicitly as
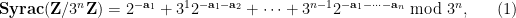
where 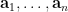 are iid copies of a geometric random variable of mean .
are iid copies of a geometric random variable of mean .
In view of this, any proposed “invariant” (or approximately invariant) measure (or family of measures) for the Syracuse dynamics should take this -adic irregularity of distribution into account. It turns out that one can use the Syracuse random variables to construct such a measure, but only if these random variables stabilise in the limit  in a certain total variation sense. More precisely, in the paper we establish the estimate
in a certain total variation sense. More precisely, in the paper we establish the estimate

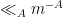
for any  and any
and any 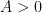 . This type of stabilisation is plausible from entropy heuristics – the tuple
. This type of stabilisation is plausible from entropy heuristics – the tuple 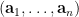 of geometric random variables that generates has Shannon entropy
of geometric random variables that generates has Shannon entropy 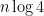 , which is significantly larger than the total entropy
, which is significantly larger than the total entropy 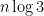 of the uniform distribution on , so we expect a lot of “mixing” and “collision” to occur when converting the tuple to ; these heuristics can be supported by numerics (which I was able to work out up to about
of the uniform distribution on , so we expect a lot of “mixing” and “collision” to occur when converting the tuple to ; these heuristics can be supported by numerics (which I was able to work out up to about 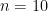 before running into memory and CPU issues), but it turns out to be surprisingly delicate to make this precise.
before running into memory and CPU issues), but it turns out to be surprisingly delicate to make this precise.
A first hint of how to proceed comes from the elementary number theory observation (easily proven by induction) that the rational numbers
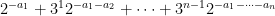
are all distinct as 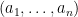 vary over tuples in
vary over tuples in 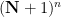 . Unfortunately, the process of reducing mod
. Unfortunately, the process of reducing mod  creates a lot of collisions (as must happen from the pigeonhole principle); however, by a simple “Lefschetz principle” type argument one can at least show that the reductions
creates a lot of collisions (as must happen from the pigeonhole principle); however, by a simple “Lefschetz principle” type argument one can at least show that the reductions
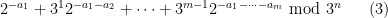
are mostly distinct for “typical” 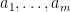 (as drawn using the geometric distribution) as long as
(as drawn using the geometric distribution) as long as  is a bit smaller than
is a bit smaller than  (basically because the rational number appearing in (3) then typically takes a form like
(basically because the rational number appearing in (3) then typically takes a form like 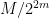 with an integer between
with an integer between  and ). This analysis of the component (3) of (1) is already enough to get quite a bit of spreading on
and ). This analysis of the component (3) of (1) is already enough to get quite a bit of spreading on 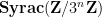 (roughly speaking, when the argument is optimised, it shows that this random variable cannot concentrate in any subset of of density less than
(roughly speaking, when the argument is optimised, it shows that this random variable cannot concentrate in any subset of of density less than 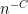 for some large absolute constant
for some large absolute constant 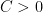 ). To get from this to a stabilisation property (2) we have to exploit the mixing effects of the remaining portion of (1) that does not come from (3). After some standard Fourier-analytic manipulations, matters then boil down to obtaining non-trivial decay of the characteristic function of , and more precisely in showing that
). To get from this to a stabilisation property (2) we have to exploit the mixing effects of the remaining portion of (1) that does not come from (3). After some standard Fourier-analytic manipulations, matters then boil down to obtaining non-trivial decay of the characteristic function of , and more precisely in showing that
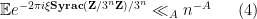
for any and any  that is not divisible by .
that is not divisible by .
If the random variable (1) was the sum of independent terms, one could express this characteristic function as something like a Riesz product, which would be straightforward to estimate well. Unfortunately, the terms in (1) are loosely coupled together, and so the characteristic factor does not immediately factor into a Riesz product. However, if one groups adjacent terms in (1) together, one can rewrite it (assuming is even for sake of discussion) as
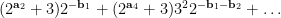
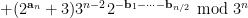
where 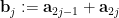 . The point here is that after conditioning on the
. The point here is that after conditioning on the 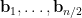 to be fixed, the random variables
to be fixed, the random variables 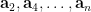 remain independent (though the distribution of each
remain independent (though the distribution of each 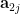 depends on the value that we conditioned
depends on the value that we conditioned 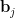 to), and so the above expression is a conditional sum of independent random variables. This lets one express the characeteristic function of (1) as an averaged Riesz product. One can use this to establish the bound (4) as long as one can show that the expression
to), and so the above expression is a conditional sum of independent random variables. This lets one express the characeteristic function of (1) as an averaged Riesz product. One can use this to establish the bound (4) as long as one can show that the expression

is not close to an integer for a moderately large number (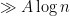 , to be precise) of indices
, to be precise) of indices 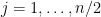 . (Actually, for technical reasons we have to also restrict to those
. (Actually, for technical reasons we have to also restrict to those  for which
for which 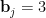 , but let us ignore this detail here.) To put it another way, if we let
, but let us ignore this detail here.) To put it another way, if we let  denote the set of pairs
denote the set of pairs  for which
for which
![\displaystyle \frac{\xi 3^{2j-2} (2^{-l+1} \mod 3^n)}{3^n} \in [-\varepsilon,\varepsilon] + {\bf Z},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B%5Cxi+3%5E%7B2j-2%7D+%282%5E%7B-l%2B1%7D+%5Cmod+3%5En%29%7D%7B3%5En%7D+%5Cin+%5B-%5Cvarepsilon%2C%5Cvarepsilon%5D+%2B+%7B%5Cbf+Z%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
we have to show that (with overwhelming probability) the random walk
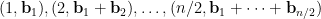
(which we view as a two-dimensional renewal process) contains at least a few points lying outside of .
A little bit of elementary number theory and combinatorics allows one to describe the set as the union of “triangles” with a certain non-zero separation between them. If the triangles were all fairly small, then one expects the renewal process to visit at least one point outside of after passing through any given such triangle, and it then becomes relatively easy to then show that the renewal process usually has the required number of points outside of . The most difficult case is when the renewal process passes through a particularly large triangle in . However, it turns out that large triangles enjoy particularly good separation properties, and in particular afer passing through a large triangle one is likely to only encounter nothing but small triangles for a while. After making these heuristics more precise, one is finally able to get enough points on the renewal process outside of that one can finish the proof of (4), and thus Theorem 2.


Recent Comments