
You are currently browsing the tag archive for the ‘compressed sensing’ tag.
[This post should have appeared several months ago, but I didn’t have a link to the newsletter at the time, and I subsequently forgot about it until now. -T.]
Last year, Emmanuel Candés and I were two of the recipients of the 2008 IEEE Information Theory Society Paper Award, for our paper “Near-optimal signal recovery from random projections: universal encoding strategies?” published in IEEE Inf. Thy.. (The other recipient is David Donoho, for the closely related paper “Compressed sensing” in the same journal.) These papers helped initiate the modern subject of compressed sensing, which I have talked about earlier on this blog, although of course they also built upon a number of important precursor results in signal recovery, high-dimensional geometry, Fourier analysis, linear programming, and probability. As part of our response to this award, Emmanuel and I wrote a short piece commenting on these developments, entitled “Reflections on compressed sensing“, which appears in the Dec 2008 issue of the IEEE Information Theory newsletter. In it we place our results in the context of these precursor results, and also mention some of the many active directions (theoretical, numerical, and applied) that compressed sensing is now developing in.
Emmanuel Candés and I have just uploaded to the arXiv our paper “The power of convex relaxation: near-optimal matrix completion“, submitted to IEEE Inf. Theory. In this paper we study the matrix completion problem, which one can view as a sort of “non-commutative” analogue of the sparse recovery problem studied in the field of compressed sensing, although there are also some other significant differences between the two problems. The sparse recovery problem seeks to recover a sparse vector 

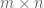
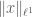
Now we turn to the matrix completion problem. Instead of an unknown vector ![M = (m_{ij})_{i \in [n_1], j \in [n_2]} \in {\Bbb R}^{n_1 \times n_2}](https://s0.wp.com/latex.php?latex=M+%3D+%28m_%7Bij%7D%29_%7Bi+%5Cin+%5Bn_1%5D%2C+j+%5Cin+%5Bn_2%5D%7D+%5Cin+%7B%5CBbb+R%7D%5E%7Bn_1+%5Ctimes+n_2%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![[n] := \{1,\ldots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3A%3D+%5C%7B1%2C%5Cldots%2Cn%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![\Omega \subset [n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5COmega+%5Csubset+%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![[n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002)


Of course, with no further information on M, it is impossible to complete the matrix M from the partial information 



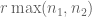
This type of problem comes up in several real-world applications, most famously in the Netflix prize. The Netflix prize problem is to be able to predict a very large ratings matrix M, whose rows are the customers, whose columns are the movies, and the entries are the rating that each customer would hypothetically assign to each movie. Of course, not every customer has rented every movie from Netflix, and so only a small fraction
Actually, one expects to need to oversample the matrix by a logarithm or two in order to have a good chance of exact recovery, if one is sampling randomly. This can be seen even in the rank one case r=1, in which 




On the other hand, one cannot hope to complete the matrix if some of the singular vectors of the matrix are extremely sparse. For instance, in the Netflix problem, a singularly idiosyncratic customer (or dually, a singularly unclassifiable movie) may give rise to a row or column of M that has no relation to the rest of the matrix, occupying its own separate component of the singular value decomposition of M; such a row or column is then impossible to complete exactly without sampling the entirety of that row or column. Thus, to get exact matrix completion from a small fraction of entries, one needs some sort of incoherence assumption on the singular vectors, which spreads them out across all coordinates in a roughly even manner, as opposed to being concentrated on just a few values.
In a recent paper, Candés and Recht proposed solving the matrix completion problem by minimising the nuclear norm (or trace norm)

amongst all matrices consistent with the observed data 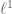
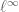
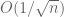

This differs from the presumably optimal threshold of 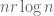

The main result of our paper is to mostly eliminate this gap, at the cost of a stronger hypothesis on the matrix being measured:
Main theorem. (Informal statement) Suppose the
matrix M has rank r and obeys a certain “strong incoherence property”. Then with high probability, nuclear norm minimisation will recover M from a random sample
, where
.
A result of a broadly similar nature, but with a rather different recovery algorithm and with a somewhat different range of applicability, was recently established by Keshavan, Oh, and Montanari. The strong incoherence property is somewhat technical, but is related to the Candés-Recht incoherence property and is satisfied by a number of reasonable random matrix models. The exponent O(1) here is reasonably civilised (ranging between 2 and 9, depending on the specific model and parameters being used).
This week I am in Seville, Spain, for a conference in harmonic analysis and related topics. My talk is titled “the uniform uncertainty principle and compressed sensing“. The content of this talk overlaps substantially with my Ostrowski lecture on the same topic; the slides I prepared for the Seville lecture can be found here.
[Update, Dec 6: Some people have asked about my other lecture given in Seville, on structure and randomness in the prime numbers. This lecture is largely equivalent to the one posted here.]
Over two years ago, Emmanuel Candés and I submitted the paper “The Dantzig selector: Statistical estimation when 
larger than 
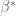

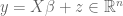

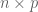



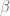
Our selection algorithm, inspired by our previous work on compressed sensing, chooses the estimated parameters 
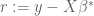

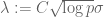
(one can check that such a condition is obeyed with high probability in the case that 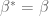

A simple model case arises when n=p and X is the identity matrix, thus the observations are given by a simple additive noise model 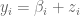

The mean square error 
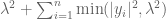
and one can show that this is basically best possible (except for constants and logarithmic factors) amongst all selectors in this model. More generally, the main result of our paper was that under the assumption that the predictor matrix obeys the RIP, the mean square error of the Dantzig selector is essentially equal to (2) and thus close to best possible.
After accepting our paper, the Annals of Statistics took the (somewhat uncommon) step of soliciting responses to the paper from various experts in the field, and then soliciting a rejoinder to these responses from Emmanuel and I. Recently, the Annals posted these responses and rejoinder on the arXiv:
This week I am in Australia, attending the ANZIAM annual meeting in Katoomba, New South Wales (in the picturesque Blue Mountains). I gave an overview talk on some recent developments in compressed sensing, particularly with regards to the basis pursuit approach to recovering sparse (or compressible) signals from incomplete measurements. The slides for my talk can be found here, with some accompanying pictures here. (There are of course by now many other presentations of compressed sensing on-line; see for instance this page at Rice.)
There was an interesting discussion after the talk. Some members of the audience asked the very good question as to whether any a priori information about a signal (e.g. some restriction about the support) could be incorporated to improve the performance of compressed sensing; a related question was whether one could perform an adaptive sequence of measurements to similarly improve performance. I don’t have good answers to these questions. Another pointed out that the restricted isometry property was like a local “well-conditioning” property for the matrix, which only applied when one viewed a few columns at a time.
This problem in compressed sensing is an example of a derandomisation problem: take an object which, currently, can only be constructed efficiently by a probabilistic method, and figure out a deterministic construction of comparable strength and practicality. (For a general comparison of probabilistic and deterministic algorithms, I can point you to these slides by Avi Wigderson).
I will define exactly what UUP matrices (the UUP stands for “uniform uncertainty principle“) are later in this post. For now, let us just say that they are a generalisation of (rectangular) orthogonal matrices, in which the columns are locally almost orthogonal rather than globally perfectly orthogonal. Because of this, it turns out that one can pack significantly more columns into a UUP matrix than an orthogonal matrix, while still capturing many of the desirable features of orthogonal matrices, such as stable and computable invertibility (as long as one restricts attention to sparse or compressible vectors). Thus UUP matrices can “squash” sparse vectors from high-dimensional space into a low-dimensional while still being able to reconstruct those vectors; this property underlies many of the recent results on compressed sensing today.
There are several constructions of UUP matrices known today (e.g. random normalised Gaussian matrices, random normalised Bernoulli matrices, or random normalised minors of a discrete Fourier transform matrix) but (if one wants the sparsity parameter to be large) they are all probabilistic in nature; in particular, these constructions are not 100% guaranteed to actually produce a UUP matrix, although in many cases the failure rate can be proven to be exponentially small in the size of the matrix. Furthermore, there is no fast (e.g. sub-exponential time) algorithm known to test whether any given matrix is UUP or not. The failure rate is small enough that this is not a problem for most applications (especially since many compressed sensing applications are for environments which are already expected to be noisy in many other ways), but is slightly dissatisfying from a theoretical point of view. One is thus interested in finding a deterministic construction which can locate UUP matrices in a reasonably rapid manner. (One could of course simply search through all matrices in a given class and test each one for the UUP property, but this is an exponential-time algorithm, and thus totally impractical for applications.) In analogy with error-correcting codes, it may be that algebraic or number-theoretic constructions may hold the most promise for such deterministic UUP matrices (possibly assuming some unproven conjectures on exponential sums); this has already been accomplished by de Vore for UUP matrices with small sparsity parameter.
For much of last week I was in Leiden, Holland, giving one of the Ostrowski prize lectures at the annual meeting of the Netherlands mathematical congress. My talk was not on the subject of the prize (arithmetic progressions in primes), as this was covered by a talk of Ben Green there, but rather on a certain “uniform uncertainty principle” in Fourier analysis, and its relation to compressed sensing; this is work which is joint with Emmanuel Candes and also partly with Justin Romberg.
I’ve had a number of people ask me (especially in light of some recent publicity) exactly what “compressed sensing” means, and how a “single pixel camera” could possibly work (and how it might be advantageous over traditional cameras in certain circumstances). There is a large literature on the subject, but as the field is relatively recent, there does not yet appear to be a good non-technical introduction to the subject. So here’s my stab at the topic, which should hopefully be accessible to a non-mathematical audience.
For sake of concreteness I’ll primarily discuss the camera application, although compressed sensing is a more general measurement paradigm which is applicable to other contexts than imaging (e.g. astronomy, MRI, statistical selection, etc.), as I’ll briefly remark upon at the end of this post.

Recent Comments