
You are currently browsing the category archive for the ‘paper’ category.
The purpose of this post is to report an erratum to the 2012 paper “An inverse theorem for the Gowers ![{U^{s+1}[N]}](https://s0.wp.com/latex.php?latex=%7BU%5E%7Bs%2B1%7D%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Excluding some minor (mostly typographical) issues which we also have reported in this erratum, the main issues stemmed from a conflation of two notions of a degree 
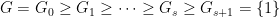
 , which is a nested sequence of subgroups that obey the relation
, which is a nested sequence of subgroups that obey the relation ![{[G_i,G_j] \leq G_{i+j}}](https://s0.wp.com/latex.php?latex=%7B%5BG_i%2CG_j%5D+%5Cleq+G_%7Bi%2Bj%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all  . The weaker notion (sometimes known as a prefiltration) permits the group
. The weaker notion (sometimes known as a prefiltration) permits the group  to be strictly smaller than
to be strictly smaller than  , while the stronger notion requires and to equal. In practice, one can often move between the two concepts, as is always normal in , and a prefiltration behaves like a filtration on every coset of (after applying a translation and perhaps also a conjugation). However, we did not clarify this issue sufficiently in the paper, and there are some places in the text where results that were only proven for filtrations were applied for prefiltrations. The erratum fixes this issues, mostly by clarifying that we work with filtrations throughout (which requires some decomposition into cosets in places where prefiltrations are generated). Similar adjustments need to be made for multidegree filtrations and degree-rank filtrations, which we also use heavily on our paper.
, while the stronger notion requires and to equal. In practice, one can often move between the two concepts, as is always normal in , and a prefiltration behaves like a filtration on every coset of (after applying a translation and perhaps also a conjugation). However, we did not clarify this issue sufficiently in the paper, and there are some places in the text where results that were only proven for filtrations were applied for prefiltrations. The erratum fixes this issues, mostly by clarifying that we work with filtrations throughout (which requires some decomposition into cosets in places where prefiltrations are generated). Similar adjustments need to be made for multidegree filtrations and degree-rank filtrations, which we also use heavily on our paper.
In most cases, fixing this issue only required minor changes to the text, but there is one place (Section 8) where there was a non-trivial problem: we used the claim that the final group 

Again, we stress that these issues do not impact the paper of Leng, Sah, and Sawhney, as they adapted the methods in our paper in a fashion that avoids these errors.
Tim Gowers, Ben Green, Freddie Manners, and I have just uploaded to the arXiv our paper “Marton’s conjecture in abelian groups with bounded torsion“. This paper fully resolves a conjecture of Katalin Marton (the bounded torsion case of the Polynomial Freiman–Ruzsa conjecture (first proposed by Katalin Marton):
Theorem 1 (Marton’s conjecture) Let
be an abelian
-torsion group (thus,
for all
), and let
be such that
. Then
can be covered by at most
translates of a subgroup
of
. Moreover,
for some
.
We had previously established the 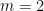
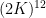




Our proof techniques are a modification of those in our previous paper, and in particular continue to be based on the theory of Shannon entropy. For inductive purposes, it turns out to be convenient to work with the following version of the conjecture (which, up to
Theorem 2 (Marton’s conjecture, entropy form) Let
be independent finitely supported random variables on
where
denotes Shannon entropy. Then there is a uniform random variable
on a subgroup
where
denotes the entropic Ruzsa distance (see previous blog post for a definition); furthermore, if all the
take values in some symmetric set
, then
for some
.
![\displaystyle {\bf H}[X_1+\dots+X_m] - \frac{1}{m} \sum_{i=1}^m {\bf H}[X_i] \leq \log K,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cbf+H%7D%5BX_1%2B%5Cdots%2BX_m%5D+-+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+%7B%5Cbf+H%7D%5BX_i%5D+%5Cleq+%5Clog+K%2C&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \frac{1}{m} \sum_{i=1}^m d[X_i; U_H] \ll m^3 \log K,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+d%5BX_i%3B+U_H%5D+%5Cll+m%5E3+%5Clog+K%2C&bg=ffffff&fg=000000&s=0&c=20201002)
As a first approximation, one should think of all the
The strategy, as with the previous paper, is to attempt an entropy decrement argument: to try to locate modifications 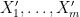
![\displaystyle {\bf H}[X_1+\dots+X_m] - \frac{1}{m} \sum_{i=1}^m {\bf H}[X_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cbf+H%7D%5BX_1%2B%5Cdots%2BX_m%5D+-+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+%7B%5Cbf+H%7D%5BX_i%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
which turns out to be a convenient metric for progress (for instance, this quantity is non-negative, and vanishes if and only if the 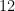
As before, we search for such improved random variables 

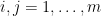
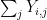
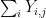


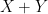
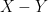
Up until now, the argument does not use the 

In the endgame, the any pair of these three random variables are close to independent (after conditioning on the total sum 
Besides the polynomial Bogolyubov conjecture mentioned above (which we do not know how to address by entropy methods), the other natural question is to try to develop a characteristic zero version of this theory in order to establish the polynomial Freiman–Ruzsa conjecture over torsion-free groups, which in our language asserts (roughly speaking) that random variables of small entropic doubling are close (in Ruzsa distance) to a discrete Gaussian random variable, with good bounds. The above machinery is consistent with this conjecture, in that it produces lots of independent variables related to the original variable, various linear combinations of which obey the same sort of entropy estimates that gaussian random variables would exhibit, but what we are missing is a way to get back from these entropy estimates to an assertion that the random variables really are close to Gaussian in some sense. In continuous settings, Gaussians are known to extremize the entropy for a given variance, and of course we have the central limit theorem that shows that averages of random variables typically converge to a Gaussian, but it is not clear how to adapt these phenomena to the discrete Gaussian setting (without the circular reasoning of assuming the polynoimal Freiman–Ruzsa conjecture to begin with).
Tim Gowers, Ben Green, Freddie Manners, and I have just uploaded to the arXiv our paper “On a conjecture of Marton“. This paper establishes a version of the notorious Polynomial Freiman–Ruzsa conjecture (first proposed by Katalin Marton):
Theorem 1 (Polynomial Freiman–Ruzsa conjecture) Letbe such that
translates of a subspace
of cardinality at most
The previous best known result towards this conjecture was by Konyagin (as communicated in this paper of Sanders), who obtained a similar result but with 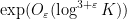

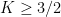



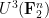
The exponent 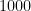
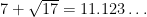
In this paper we will focus exclusively on the characteristic
Much of the prior progress on this sort of result has proceeded via Fourier analysis. Perhaps surprisingly, our approach uses no Fourier analysis whatsoever, being conducted instead entirely in “physical space”. Broadly speaking, it follows a natural strategy, which is to induct on the doubling constant 

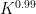
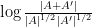

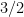
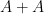
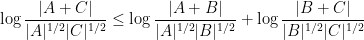 to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).
to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).
There are a number of possible ways to try to “improve” a set
- (i) Replacing
) of a large subspace
- (ii) Replacing
for a “typical”
. For instance, if
Unfortunately, there are sets 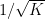
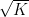
This begins to suggest a potential strategy: show that at least one of the operations (i) or (ii) will improve the doubling constant, or at least not worsen it too much; and in the latter case, perform some more complicated operation to locate the desired doubling constant improvement.
A sign that this strategy might have a chance of working is provided by the following heuristic argument. If 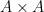
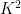
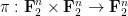

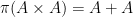

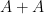

Unfortunately, this argument does not seem to be easily made rigorous using the traditional doubling constant; even the significantly weaker statement that 


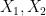
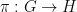
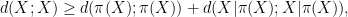
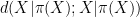 is defined as
is defined as 
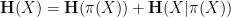

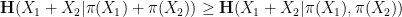
Applying this inequality with 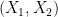


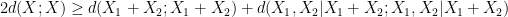
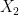 is determined by
is determined by 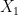 once one fixes
once one fixes 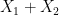 )
) 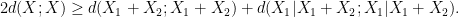
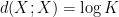 , then at least one of
, then at least one of 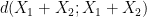 or
or 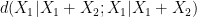 will be less than or equal to
will be less than or equal to 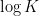 . This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events
. This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events 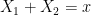 ,
, 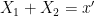 , and “depolarise” the induction hypothesis to deal with distances
, and “depolarise” the induction hypothesis to deal with distances 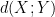 between pairs of random variables that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that
between pairs of random variables that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that 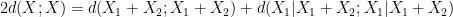
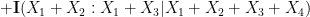
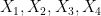 . This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and
. This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and  are conditionally independent relative to
are conditionally independent relative to  . This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.
. This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.
A version of this endgame conclusion is in fact valid in any characteristic. But in characteristic
 , and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of
, and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of 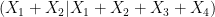 has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.
has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.
To deal with the situation where the conditional mutual information is small but not completely zero, we have to use an entropic version of the Balog-Szemeredi-Gowers lemma, but fortunately this was already worked out in an old paper of mine (although in order to optimise the final constant, we ended up using a slight variant of that lemma).
I am planning to formalize this paper in the Lean4 language. Further discussion of this project will take place on this Zulip stream, and the project itself will be held at this Github repository.
I have just uploaded to the arXiv my paper “A Maclaurin type inequality“. This paper concerns a variant of the Maclaurin inequality for the elementary symmetric means

 real numbers
real numbers 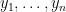 . This inequality asserts that
. This inequality asserts that 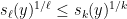
 and are non-negative. It can be proven as a consequence of the Newton inequality
and are non-negative. It can be proven as a consequence of the Newton inequality 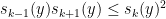
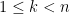 and arbitrary real (in particular, here the
and arbitrary real (in particular, here the 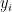 are allowed to be negative). Note that the
are allowed to be negative). Note that the 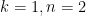 case of this inequality is just the arithmetic mean-geometric mean inequality
case of this inequality is just the arithmetic mean-geometric mean inequality 
 to obtain another real-rooted polynomial, thanks to Rolle’s theorem; the key point is that this operation preserves all the elementary symmetric means up to
to obtain another real-rooted polynomial, thanks to Rolle’s theorem; the key point is that this operation preserves all the elementary symmetric means up to  ). One can think of Maclaurin’s inequality as providing a refined version of the arithmetic mean-geometric mean inequality on variables (which corresponds to the case
). One can think of Maclaurin’s inequality as providing a refined version of the arithmetic mean-geometric mean inequality on variables (which corresponds to the case  ,
,  ).
).
Whereas Newton’s inequality works for arbitrary real 



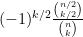

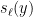

On the other hand, it was observed by Gopalan and Yehudayoff that if two consecutive values 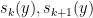



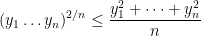

However, if one inspects the bound (2) against the bounds (1) given by the key example, we see a mismatch – the right-hand side of (2) is larger than the left-hand side by a factor of about 

Unlike the previous arguments, we do not rely primarily on the arithmetic mean-geometric mean inequality. Instead, our primary tool is a new inequality 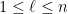
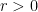

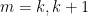


We sketch the proof of the inequality (4) as follows. One can use some standard manipulations reduce to the case where 

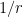
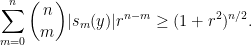 equal to and the other half equal to , thanks to the binomial theorem.
equal to and the other half equal to , thanks to the binomial theorem.
To prove this identity, we consider the polynomial
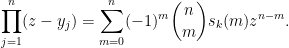
 , taking absolute values, using the triangle inequality, and then taking logarithms, we conclude that
, taking absolute values, using the triangle inequality, and then taking logarithms, we conclude that 
 gives
gives 
Rachel Greenfeld and I have just uploaded to the arXiv our paper “Undecidability of translational monotilings“. This is a sequel to our previous paper in which we constructed a translational monotiling 

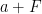
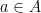


One of the motivations of this conjecture was the observation of Hao Wang that if the periodic tiling conjecture were true, then the translational monotiling problem is (algorithmically) decidable: there is a Turing machine which, when given a dimension
On the other hand, Wang’s argument is not known to be reversible: the failure of the periodic tiling conjecture does not automatically imply the undecidability of the translational monotiling problem, as it does not rule out the existence of some other algorithm to determine tiling that does not rely on the existence of a periodic tiling. (For instance, even with the newly discovered hat and spectre tiles, it remains an open question whether the isometric monotiling problem for (say) polygons with rational coefficients in
The main result of this paper settles this question (with one caveat):
Theorem 1 There does not exist any algorithm which, given a dimension
of
of
The caveat is that we have to work with periodic subsets 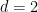

Because of a well known link between algorithmic undecidability and logical undecidability (also known as logical independence), the main theorem also implies the existence of an (in principle explicitly describable) dimension
As a consequence of our method, we can also replace 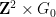
We now describe some of the main ideas of the proof. It is a common technique to show that a given problem is undecidable by demonstrating that some other problem that was already known to be undecidable can be “encoded” within the original problem, so that any algorithm for deciding the original problem would also decide the embedded problem. Accordingly, we will encode the Wang tiling problem as a monotiling problem in
Problem 2 (Wang tiling problem) Given a finite collection
of Wang tiles (unit squares with each side assigned some color from a finite palette), is it possible to tile the plane with translates of these tiles along the standard lattice
, such that adjacent tiles have matching colors along their common edge?
It is a famous result of Berger that this problem is undecidable. The embedding of this problem into the higher-dimensional translational monotiling problem proceeds through some intermediate problems. Firstly, it is an easy matter to embed the Wang tiling problem into a similar problem which we call the domino problem:
Problem 3 (Domino problem) Given a finite collection
(resp.
) of horizontal (resp. vertical) dominoes – pairs of adjacent unit squares, each of which is decorated with an element of a finite set
Indeed, one just has to interpet each Wang tile as a separate “pip”, and define the domino sets
Next, we embed the domino problem into a Sudoku problem:
Problem 4 (Sudoku problem) Given a column width
, a digit set
, a collection
of functions
, and an “initial condition”
(which we will not detail here, as it is a little technical), is it possible to assign a digit
to each cell
in the “Sudoku board”
such that for any slope
and intercept
, the digits
along the line
lie in
The most novel part of the paper is the demonstration that the domino problem can indeed be embedded into the Sudoku problem. The embedding of the Sudoku problem into the monotiling problem follows from a modification of the methods in our previous papers, which had also introduced versions of the Sudoku problem, and created a “tiling language” which could be used to “program” various problems, including the Sudoku problem, as monotiling problems.
To encode the domino problem into the Sudoku problem, we need to take a domino function 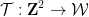





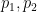



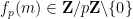
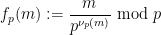




and a typical instance of the final component 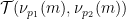

Amusingly, the decoration here is essentially following the rules of the children’s game “Fizz buzz“.
To demonstrate the embedding, we thus need to produce a specific Sudoku rule 
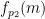

I have just uploaded to the arXiv my paper “Monotone non-decreasing sequences of the Euler totient function“. This paper concerns the quantity 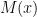

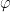

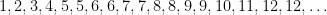
 because the totient function is non-decreasing on the set
because the totient function is non-decreasing on the set  or
or 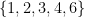 , but not on the set
, but not on the set  .
.
Since 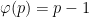
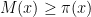
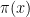
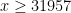
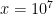

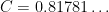
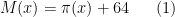
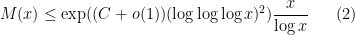

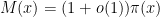 . This answers a question of Erdős, as well as a closely related question of Pollack, Pomerance, and Treviño.
. This answers a question of Erdős, as well as a closely related question of Pollack, Pomerance, and Treviño.
The methods of proof turn out to be mostly elementary (the most advanced result from analytic number theory we need is the prime number theorem with classical error term). The basic idea is to isolate one key prime factor 
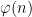

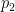 is a medium sized prime,
is a medium sized prime, 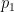 is a significantly larger prime, and is a number with all prime factors less than . This leads to an approximation
is a significantly larger prime, and is a number with all prime factors less than . This leads to an approximation 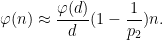 fixed, and also localize to a relatively short interval, then can only be non-decreasing in if is also non-decreasing at the same time. This turns out to significantly cut down on the possible length of a non-decreasing sequence in this regime, particularly if is large; this can be formalized by partitioning the range of into various subintervals and inspecting how this (and the monotonicity hypothesis on ) constrains the values of associated to each subinterval. When is small, we instead use a factorization
fixed, and also localize to a relatively short interval, then can only be non-decreasing in if is also non-decreasing at the same time. This turns out to significantly cut down on the possible length of a non-decreasing sequence in this regime, particularly if is large; this can be formalized by partitioning the range of into various subintervals and inspecting how this (and the monotonicity hypothesis on ) constrains the values of associated to each subinterval. When is small, we instead use a factorization 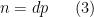 is very smooth (i.e., has no large prime factors), and is a large prime. Now we have the approximation
is very smooth (i.e., has no large prime factors), and is a large prime. Now we have the approximation 
 will have to basically be piecewise constant in order for to be non-decreasing. Pursuing this analysis more carefully (in particular controlling the size of various exceptional sets in which the above analysis breaks down), we end up achieving the main theorem so long as we can prove the preliminary inequality
will have to basically be piecewise constant in order for to be non-decreasing. Pursuing this analysis more carefully (in particular controlling the size of various exceptional sets in which the above analysis breaks down), we end up achieving the main theorem so long as we can prove the preliminary inequality 
 . This is in fact also a necessary condition; any failure of this inequality can be easily converted to a counterexample to the bound (2), by considering numbers of the form (3) with equal to a fixed constant (and omitting a few rare values of where the approximation (4) is bad enough that is temporarily decreasing). Fortunately, there is a minor miracle, relating to the fact that the largest prime factor of denominator of in lowest terms necessarily equals the largest prime factor of , that allows one to evaluate the left-hand side of (5) almost exactly (this expression either vanishes, or is the product of
. This is in fact also a necessary condition; any failure of this inequality can be easily converted to a counterexample to the bound (2), by considering numbers of the form (3) with equal to a fixed constant (and omitting a few rare values of where the approximation (4) is bad enough that is temporarily decreasing). Fortunately, there is a minor miracle, relating to the fact that the largest prime factor of denominator of in lowest terms necessarily equals the largest prime factor of , that allows one to evaluate the left-hand side of (5) almost exactly (this expression either vanishes, or is the product of 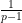 for some primes ranging up to the largest prime factor of ) that allows one to easily establish (5). If one were to try to prove an analogue of our main result for the sum-of-divisors function
for some primes ranging up to the largest prime factor of ) that allows one to easily establish (5). If one were to try to prove an analogue of our main result for the sum-of-divisors function 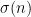 , one would need the analogue
, one would need the analogue 
In the final section of the paper we discuss some near counterexamples to the strong conjecture (1) that indicate that it is likely going to be difficult to get close to proving this conjecture without assuming some rather strong hypotheses. Firstly, we show that failure of Legendre’s conjecture on the existence of a prime between any two consecutive squares can lead to a counterexample to (1). Secondly, we show that failure of the Dickson-Hardy-Littlewood conjecture can lead to a separate (and more dramatic) failure of (1), in which the primes are no longer the dominant sequence on which the totient function is non-decreasing, but rather the numbers which are a power of two times a prime become the dominant sequence. This suggests that any significant improvement to (2) would require assuming something comparable to the prime tuples conjecture, and perhaps also some unproven hypotheses on prime gaps.
Kevin Ford, Dimitris Koukoulopoulos and I have just uploaded to the arXiv our paper “A lower bound on the mean value of the Erdős-Hooley delta function“. This paper complements the recent paper of Dimitris and myself obtaining the upper bound


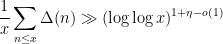
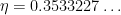 is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that
is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that 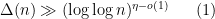 outside of a set of density zero. The previous best known lower bound for the mean value was
outside of a set of density zero. The previous best known lower bound for the mean value was 
The point is the main contributions to the mean value of 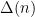
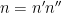
 is the product of primes between some intermediate threshold
is the product of primes between some intermediate threshold 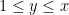 and and behaves “typically” (so in particular, it has about
and and behaves “typically” (so in particular, it has about  prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but
prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but 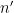 is the product of primes up to and has double the number of typical prime factors –
is the product of primes up to and has double the number of typical prime factors –  , rather than
, rather than  – thus is the type of number that would make a significant contribution to the mean value of the divisor function
– thus is the type of number that would make a significant contribution to the mean value of the divisor function  . Here is such that
. Here is such that  is an integer in the range
is an integer in the range 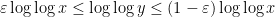 there are basically
there are basically 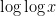 different values of give essentially disjoint contributions. From the easy inequalities
different values of give essentially disjoint contributions. From the easy inequalities 
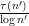 has mean about one, one would expect to get the above result provided that one could get a lower bound of the form
has mean about one, one would expect to get the above result provided that one could get a lower bound of the form 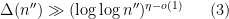 with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality
with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality 

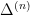 when
when 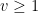 . This inequality is easily proven by applying the pigeonhole principle to the factors of of the form
. This inequality is easily proven by applying the pigeonhole principle to the factors of of the form 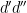 , where
, where 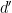 is one of the
is one of the  factors of , and
factors of , and  is one of the
is one of the 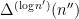 factors of in the optimal interval
factors of in the optimal interval ![{[e^u, e^{u+\log n'}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B%5Clog+n%27%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The extra room provided by the enlargement of the range
. The extra room provided by the enlargement of the range ![{[e^u, e^{u+1}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset of
to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset of ![{[D^c, D]}](https://s0.wp.com/latex.php?latex=%7B%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some small
for some small  and sufficiently large
and sufficiently large  with each
with each ![{n \in [D^c, D]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) lying in with an independent probability
lying in with an independent probability 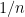 , then with high probability there should be
, then with high probability there should be  subset sums of that attain the same value. (Initially, what “high probability” means is just “close to “, but one can reduce the failure probability significantly as
subset sums of that attain the same value. (Initially, what “high probability” means is just “close to “, but one can reduce the failure probability significantly as  by a “tensor power trick” taking advantage of Bennett’s inequality.)
by a “tensor power trick” taking advantage of Bennett’s inequality.)
I have just uploaded to the arXiv my paper “The convergence of an alternating series of Erdős, assuming the Hardy–Littlewood prime tuples conjecture“. This paper concerns an old problem of Erdős concerning whether the alternating series 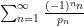

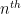
The alternating series test does not apply here because the ratios 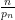
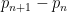
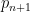
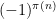
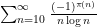
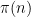
The prime tuples conjecture does not directly say much about the value of 
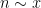
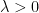


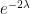

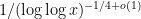
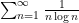
To get around this obstacle, we take advantage of the random sifted model 
![{[n, n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2C+n%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x,2x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C2x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
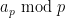
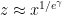

For this problem, the main advantage of working with the random sifted model, rather than with the primes or the singular series arising from the prime tuples conjecture, is that the sifted model can be studied iteratively from the partially sifted sets 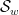
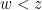


![{[n,n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2Cn%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


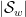
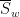


Jon Bennett and I have just uploaded to the arXiv our paper “Adjoint Brascamp-Lieb inequalities“. In this paper, we observe that the family of multilinear inequalities known as the Brascamp-Lieb inequalities (or Holder-Brascamp-Lieb inequalities) admit an adjoint formulation, and explore the theory of these adjoint inequalities and some of their consequences.
To motivate matters let us review the classical theory of adjoints for linear operators. If one has a bounded linear operator 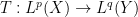
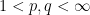
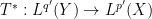

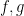
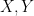
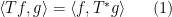
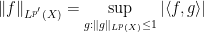
 (and similarly for
(and similarly for  ), one can show that
), one can show that  has the same operator norm as
has the same operator norm as  .
.
There is a slightly different way to proceed using Hölder’s inequality. For sake of exposition let us make the simplifying assumption that 

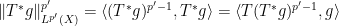
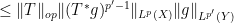
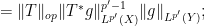
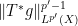 we obtain
we obtain  , and a similar argument also recovers the reverse inequality.
, and a similar argument also recovers the reverse inequality.
The first argument also extends to some extent to multilinear operators. For instance if one has a bounded bilinear operator 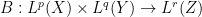

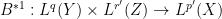
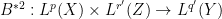

 . It is also possible, formally at least, to adapt the Hölder inequality argument to reach the same conclusion.
. It is also possible, formally at least, to adapt the Hölder inequality argument to reach the same conclusion.
In this paper we observe that the Hölder inequality argument can be modified in the case of Brascamp-Lieb inequalities to obtain a different type of adjoint inequality. (Continuous) Brascamp-Lieb inequalities take the form

 and surjective linear maps
and surjective linear maps 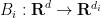 , where
, where 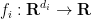 are arbitrary non-negative measurable functions and
are arbitrary non-negative measurable functions and  is the best constant for which this inequality holds for all such
is the best constant for which this inequality holds for all such  . [There is also another inequality involving variances with respect to log-concave distributions that is also due to Brascamp and Lieb, but it is not related to the inequalities discussed here.] Well known examples of such inequalities include Hölder’s inequality and the sharp Young convolution inequality; another is the Loomis-Whitney inequality, the first non-trivial example of which is
. [There is also another inequality involving variances with respect to log-concave distributions that is also due to Brascamp and Lieb, but it is not related to the inequalities discussed here.] Well known examples of such inequalities include Hölder’s inequality and the sharp Young convolution inequality; another is the Loomis-Whitney inequality, the first non-trivial example of which is 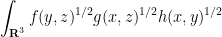

 . There are also discrete analogues of these inequalities, in which the Euclidean spaces
. There are also discrete analogues of these inequalities, in which the Euclidean spaces 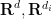 are replaced by discrete abelian groups, and the surjective linear maps
are replaced by discrete abelian groups, and the surjective linear maps  are replaced by discrete homomorphisms.
are replaced by discrete homomorphisms.
The operation 
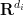

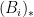
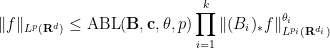
 and various exponents
and various exponents  , where
, where 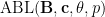 is the optimal constant for which the above inequality holds for all such
is the optimal constant for which the above inequality holds for all such  ; informally, such inequalities control the
; informally, such inequalities control the  norm of a non-negative function in terms of its marginals. It turns out that every Brascamp-Lieb inequality generates a family of adjoint Brascamp-Lieb inequalities (with the exponent being less than or equal to ). For instance, the adjoints of the Loomis-Whitney inequality (2) are the inequalities
norm of a non-negative function in terms of its marginals. It turns out that every Brascamp-Lieb inequality generates a family of adjoint Brascamp-Lieb inequalities (with the exponent being less than or equal to ). For instance, the adjoints of the Loomis-Whitney inequality (2) are the inequalities 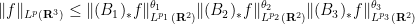
 , all
, all  summing to , and all
summing to , and all 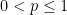 , where the
, where the 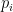 exponents are defined by the formula
exponents are defined by the formula 
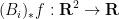 are the marginals of :
are the marginals of : 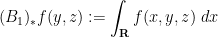
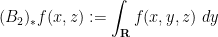
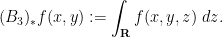
One can derive these adjoint Brascamp-Lieb inequalities from their forward counterparts by a version of the Hölder inequality argument mentioned previously, in conjunction with the observation that the pushforward maps 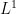
We have located a modest number of applications of the adjoint Brascamp-Lieb inequality (but hope that there will be more in the future):
- The inequalities become equalities at
; taking a derivative at this value (in the spirit of the replica trick in physics) we recover the entropic Brascamp-Lieb inequalities of Carlen and Cordero-Erausquin. For instance, the derivative of the adjoint Loomis-Whitney inequalities at
- The adjoint Loomis-Whitney inequalities, together with a few more applications of Hölder’s inequality, implies the log-concavity of the Gowers uniformity norms on non-negative functions, which was previously observed by Shkredov and by Manners.
- Averaging the adjoint Loomis-Whitney inequalities over coordinate systems gives reverse
norms or entropies of the
are chosen in a dimensionally consistent fashion).
We also record a number of variants of the adjoint Brascamp-Lieb inequalities, including discrete variants, and a reverse inequality involving 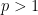
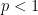
Ben Green, Freddie Manners and I have just uploaded to the arXiv our preprint “Sumsets and entropy revisited“. This paper uses entropy methods to attack the Polynomial Freiman-Ruzsa (PFR) conjecture, which we study in the following two forms:
Conjecture 1 (Weak PFR over) Let
be a finite non-empty set whose doubling constant
is at most
that has affine dimension
Conjecture 2 (PFR over) Let
be a non-empty set whose doubling constant
is at most
cosets of a subspace of cardinality at most
Our main results are then as follows.
Theorem 3 If, then
- (i) There is a subset
- (ii) There is a subset
of affine dimension
goes to zero as
).
- (iii) If Conjecture 2 holds, then there is a subset
The skew-dimension of a set is a quantity smaller than the affine dimension which is defined recursively; the precise definition is given in the paper, but suffice to say that singleton sets have dimension 
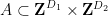
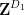
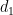
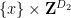
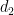

Part (i) of this theorem was implicitly proven by Pálvölgi and Zhelezov by a different method. Part (ii) with 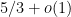
Our proof strategy is to establish these combinatorial additive combinatorics results by using entropic additive combinatorics, in which we replace sets
For instance, the analogue of the combinatorial doubling constant
![\displaystyle \sigma_{\mathrm{ent}}[X] := {\exp( \bf H}(X_1+X_2) - {\bf H}(X) )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D+%3A%3D+%7B%5Cexp%28+%5Cbf+H%7D%28X_1%2BX_2%29+-+%7B%5Cbf+H%7D%28X%29+%29&bg=ffffff&fg=000000&s=0&c=20201002) in , where are independent copies of and denotes Shannon entropy. There is also an analogue of the Ruzsa distance
in , where are independent copies of and denotes Shannon entropy. There is also an analogue of the Ruzsa distance 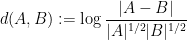
 of , namely the entropic Ruzsa distance
of , namely the entropic Ruzsa distance 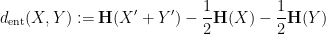
 are independent copies of respectively. (Actually, one thing we show in our paper is that the independence hypothesis can be dropped, and this only affects the entropic Ruzsa distance by a factor of three at worst.) Many of the results about sumsets and Ruzsa distance have entropic analogues, but the entropic versions are slightly better behaved; for instance, we have a contraction property
are independent copies of respectively. (Actually, one thing we show in our paper is that the independence hypothesis can be dropped, and this only affects the entropic Ruzsa distance by a factor of three at worst.) Many of the results about sumsets and Ruzsa distance have entropic analogues, but the entropic versions are slightly better behaved; for instance, we have a contraction property 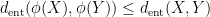
 is a homomorphism. In fact we have a refinement of this inequality in which the gap between these two quantities can be used to control the entropic distance between “fibers” of (in which one conditions
is a homomorphism. In fact we have a refinement of this inequality in which the gap between these two quantities can be used to control the entropic distance between “fibers” of (in which one conditions 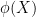 and
and 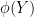 to be fixed). On the other hand, there are direct connections between the combinatorial and entropic sumset quantities. For instance, if
to be fixed). On the other hand, there are direct connections between the combinatorial and entropic sumset quantities. For instance, if 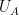 is a random variable drawn uniformly from , then
is a random variable drawn uniformly from , then ![\displaystyle \sigma_{\mathrm{ent}}[U_A] \leq \sigma[A].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BU_A%5D+%5Cleq+%5Csigma%5BA%5D.&bg=ffffff&fg=000000&s=0&c=20201002) has small doubling, then has small entropic doubling. In the converse direction, if has small entropic doubling, then is close (in entropic Ruzsa distance) to a uniform random variable
has small doubling, then has small entropic doubling. In the converse direction, if has small entropic doubling, then is close (in entropic Ruzsa distance) to a uniform random variable 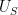 drawn from a set of small doubling; a version of this statement was proven in an old paper of myself, but we establish here a quantitatively efficient version, established by rewriting the entropic Ruzsa distance in terms of certain Kullback-Liebler divergences.
drawn from a set of small doubling; a version of this statement was proven in an old paper of myself, but we establish here a quantitatively efficient version, established by rewriting the entropic Ruzsa distance in terms of certain Kullback-Liebler divergences.
Our first main result is a “99% inverse theorem” for entropic Ruzsa distance: if 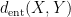

We now sketch how these tools are used to prove our main theorem. For (i), we reduce matters to establishing the following bilinear entropic analogue: given two non-empty finite subsets 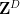
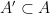
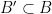
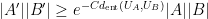
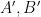 have skew-dimension at most
have skew-dimension at most  , for some absolute constant . This can be shown by an induction on
, for some absolute constant . This can be shown by an induction on 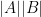 (say). One applies a non-trivial coordinate projection
(say). One applies a non-trivial coordinate projection 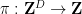 to . If
to . If 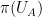 and
and 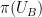 are very close in entropic Ruzsa distance, then the 99% inverse theorem shows that these random variables must each concentrate at a point (because
are very close in entropic Ruzsa distance, then the 99% inverse theorem shows that these random variables must each concentrate at a point (because  has no non-trivial finite subgroups), and can pass to a fiber of these points and use the induction hypothesis. If instead and are far apart, then by the behavior of entropy under projections one can show that the fibers of and under are closer on average in entropic Ruzsa distance of and themselves, and one can again proceed using the induction hypothesis.
has no non-trivial finite subgroups), and can pass to a fiber of these points and use the induction hypothesis. If instead and are far apart, then by the behavior of entropy under projections one can show that the fibers of and under are closer on average in entropic Ruzsa distance of and themselves, and one can again proceed using the induction hypothesis.
For parts (ii) and (iii), we first use an entropic version of an observation of Manners that sets of small doubling in
 take values in a torsion-free abelian group such as ; this turns out to follow from two applications of the entropy submodularity inequality. One corollary of this (and the behavior of entropy under projections) is that
take values in a torsion-free abelian group such as ; this turns out to follow from two applications of the entropy submodularity inequality. One corollary of this (and the behavior of entropy under projections) is that  and
and  worlds that is used to prove (ii), (iii): while (iii) relies on the still unproven PFR conjecture over , (ii) uses the unconditional progress on PFR by Konyagin, as detailed in this survey of Sanders. The argument has a similar inductive structure to that used to establish (i) (and if one is willing to replace by then the argument is in fact relatively straightforward and does not need any deep partial results on the PFR).
worlds that is used to prove (ii), (iii): while (iii) relies on the still unproven PFR conjecture over , (ii) uses the unconditional progress on PFR by Konyagin, as detailed in this survey of Sanders. The argument has a similar inductive structure to that used to establish (i) (and if one is willing to replace by then the argument is in fact relatively straightforward and does not need any deep partial results on the PFR).
As one byproduct of our analysis we also obtain an appealing entropic reformulation of Conjecture 2, namely that if
![\displaystyle d_{\mathrm{ent}}(X, U_H) \ll \sigma_{\mathrm{ent}}[X].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d_%7B%5Cmathrm%7Bent%7D%7D%28X%2C+U_H%29+%5Cll+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle d_{\mathrm{ent}}(X, U_H) \ll_\varepsilon \sigma_{\mathrm{ent}}[X] + \sigma_{\mathrm{ent}}^{3+\varepsilon}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d_%7B%5Cmathrm%7Bent%7D%7D%28X%2C+U_H%29+%5Cll_%5Cvarepsilon+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D+%2B+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5E%7B3%2B%5Cvarepsilon%7D%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , by using Konyagin’s partial result towards the PFR.
, by using Konyagin’s partial result towards the PFR.

Recent Comments