
You are currently browsing the monthly archive for April 2017.
A sequence 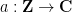
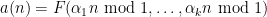
for some real numbers 

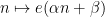
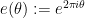





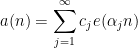
with 
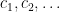
These sequences arise in various “complexity one” problems in arithmetic combinatorics and ergodic theory. For instance, if 
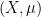

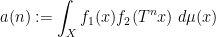
can be shown to be an almost periodic sequence, plus an error term 

This can be established in a number of ways, for instance by writing 


In the last two decades or so, it has become clear that there are natural higher order versions of these concepts, in which linear polynomials such as 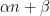


For technical reasons (having to do with the non-trivial topological structure on nilmanifolds), it will be convenient to work with vector-valued sequences, that take values in a finite-dimensional complex vector space 

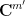


This product is associative and bilinear, and also commutative up to permutation of the indices. It also interacts well with the Hermitian norm

since we have 
The traditional definition of a basic nilsequence (as defined for instance by Bergelson, Host, and Kra) is as follows:
Definition 1 (Basic nilsequence, first definition) A nilmanifold of step at most
is a quotient
, where
is a connected, simply connected nilpotent Lie group of step at most
-fold commutators vanish) and
is a discrete cocompact lattice in
, where
,
, and
is a continuous function.
For instance, it is not difficult using this definition to show that a sequence is a basic nilsequence of degree at most 

Nowadays, and particularly when one needs to understand the “single-scale” equidistribution properties of nilsequences, it is more convenient (as is for instance done in this ICM paper of Green) to use an alternate definition of a nilsequence as follows.
Definition 2 Let
. A filtered group of degree at most
of subgroups
with
and
for
. A polynomial sequence
into a filtered group is a function such that
for all
and
, where
is the difference operator. A filtered nilmanifold of degree at most
is a quotient
are connected, simply connected nilpotent filtered Lie group, and
is a discrete cocompact subgroup of
, where
is a continuous function which is
for all
.
One can easily identify a 

It is easy to see that any sequence that is a basic nilsequence of degree at most 

where 

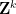

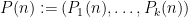
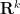


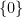

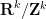
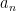

The other key example is a sequence of the form
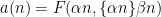
where 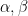

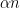

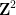


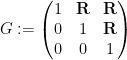
with the lower central series filtration 
![{G_2= [G,G] = \begin{pmatrix} 1 &0 & {\bf R} \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix}}](https://s0.wp.com/latex.php?latex=%7BG_2%3D+%5BG%2CG%5D+%3D+%5Cbegin%7Bpmatrix%7D+1+%260+%26+%7B%5Cbf+R%7D+%5C%5C+0+%26+1+%26+0+%5C%5C+0+%26+0+%26+1+%5Cend%7Bpmatrix%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


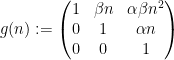
and 

one easily verifies that this function is indeed 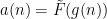




will be a basic nilsequence if 
A nilsequence of degree at most 


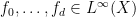

is equal to a nilsequence of degree at most 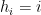

It is easy to see that a sequence 


Now we turn to the notion of a nilcharacter, as defined in this paper of Ben Green, Tamar Ziegler, and myself:
Definition 3 (Nilcharacters) Let
. A sub-nilcharacter of degree
of degree at most
for all
, where
is a continuous homomorphism
. (Note from (1) and
must map
to
.) If in addition one has
for all
a nilcharacter of degree
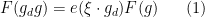
In the degree one case 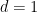





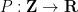



where 

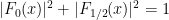
for all 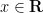
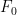

We claim that every degree 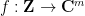


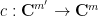






and then

becomes a degree 
As we shall show below, nilsequences can be approximated uniformly by linear combinations of nilcharacters, in much the same way that quasiperiodic or almost periodic sequences can be approximated uniformly by linear combinations of linear phases. In particular, nilcharacters can be used as “obstructions to uniformity” in the sense of the inverse theory of the Gowers uniformity norms.
The space of degree
Definition 4 Let
,
are equivalent if
is equal (as a sequence) to a basic nilsequence of degree at most
of such a nilcharacter will be called the symbol of that nilcharacter (in analogy to the symbol of a differential or pseudodifferential operator), and the collection of such symbols will be denoted
.
As we shall see below the fold, 
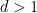

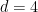
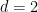
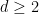

How many groups of order four are there? Technically, there are an enormous number, so much so, in fact, that the class of groups of order four is not even a set, but merely a proper class. This is because any four objects 

A much better question is to ask how many groups of order four there are up to isomorphism, counting each isomorphism class of groups exactly once. Now, as one learns in undergraduate group theory classes, the answer is just “two”: the cyclic group 
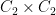
More generally, given a class of objects 
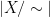
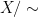
![{[x]:=\{y\in X:x \sim {}y \}}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5D%3A%3D%5C%7By%5Cin+X%3Ax+%5Csim+%7B%7Dy+%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle |X/\sim| = \sum_{x \in X} \frac{1}{|[x]|}, \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7CX%2F%5Csim%7C+%3D+%5Csum_%7Bx+%5Cin+X%7D+%5Cfrac%7B1%7D%7B%7C%5Bx%5D%7C%7D%2C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
thus one counts elements in
Example 1 Let
of integers between
and
of
. Then the quotient space
,
, and
. Thus there are three objects in
Thus, to count elements in
are given a weight of
because they are each isomorphic to two elements in
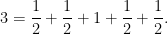
Given a finite probability set 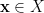


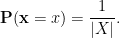
Given a notion ![{[\mathbf{x}] \in X/\sim}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cmathbf%7Bx%7D%5D+%5Cin+X%2F%5Csim%7D&bg=ffffff&fg=000000&s=0&c=20201002)
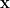
![{[\mathbf{x}]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cmathbf%7Bx%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
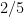

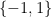
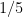
However, it is possible to remove this bias by changing the weighting in (1), and thus changing the notion of what cardinality means. To do this, we generalise the previous situation. Instead of considering sets
Definition 2 A groupoid is a set (or proper class)
of “isomorphisms” between any pair
of elements of
from isomorphisms
,
to isomorphisms in
for every
, obeying the following group-like axioms:
- (Identity) For every
, there is an identity isomorphism
, such that
for all
.
- (Associativity) If
for some
, then
.
- (Inverse) If
such that
and
.
We say that two elements
, if there is at least one isomorphism from
.
Example 3 Any category gives a groupoid by taking
of sets,
of linear vector spaces over some given base field
,
Every set 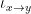
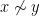
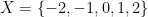

However, one can also form multiply-connected groupoids in which there can be multiple isomorphisms from one element of 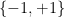


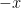

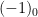
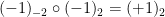
For a finite multiply-connected groupoid, it turns out that the natural notion of “cardinality” (or as I prefer to call it, “cardinality up to isomorphism”) is given by the variant

of (1). That is to say, in the multiply connected case, the denominator is no longer the number of objects ![{[x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \sum_{[x] \in X/\sim} \frac{1}{|\mathrm{Aut}(x)|} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7B%5Bx%5D+%5Cin+X%2F%5Csim%7D+%5Cfrac%7B1%7D%7B%7C%5Cmathrm%7BAut%7D%28x%29%7C%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 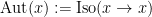
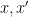


For instance, if we take
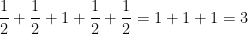
exactly as before. If however we take the multiply connected groupoid on

the equivalence class ![{[0]}](https://s0.wp.com/latex.php?latex=%7B%5B0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[1], [2]}](https://s0.wp.com/latex.php?latex=%7B%5B1%5D%2C+%5B2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
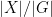

The definition (2) can also make sense for some infinite groupoids; to my knowledge this was first explicitly done in this paper of Baez and Dolan. Consider for instance the category 
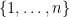
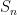

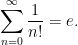
(This fact is sometimes loosely stated as “the number of finite sets is 
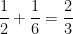
because the cyclic group
In the case that the cardinality of a groupoid
![\displaystyle {\mathbf P}([\mathbf{x}] = [x]) = \frac{1 / |\mathrm{Aut}(x)|}{\sum_{[y] \in X/\sim} 1/|\mathrm{Aut}(y)|},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7B%5Cmathbf+P%7D%28%5B%5Cmathbf%7Bx%7D%5D+%3D+%5Bx%5D%29+%3D+%5Cfrac%7B1+%2F+%7C%5Cmathrm%7BAut%7D%28x%29%7C%7D%7B%5Csum_%7B%5By%5D+%5Cin+X%2F%5Csim%7D+1%2F%7C%5Cmathrm%7BAut%7D%28y%29%7C%7D%2C&bg=ffffff&fg=000000&s=0&c=20201002)
thus the probability of being isomorphic to a given element ![{[0], [1], [2]}](https://s0.wp.com/latex.php?latex=%7B%5B0%5D%2C+%5B1%5D%2C+%5B2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[1]}](https://s0.wp.com/latex.php?latex=%7B%5B1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[2]}](https://s0.wp.com/latex.php?latex=%7B%5B2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
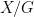
Using the groupoid of finite sets, we see that a finite set chosen uniformly up to isomorphism will have a cardinality that is distributed according to the Poisson distribution of parameter 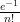
One important source of groupoids are the fundamental groupoids 

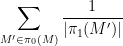
where 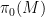
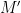
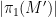
This notion of cardinality up to isomorphism of a groupoid behaves well with respect to various basic notions. For instance, suppose one has an 


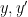
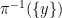
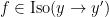


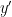
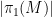
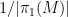
![{[\mathrm{x}]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cmathrm%7Bx%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\pi([\mathrm{x}])}](https://s0.wp.com/latex.php?latex=%7B%5Cpi%28%5B%5Cmathrm%7Bx%7D%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Indeed, one can show that this notion of cardinality up to isomorphism for groupoids is uniquely determined by a small number of axioms such as these (similar to the axioms that determine Euler characteristic); see this blog post of Qiaochu Yuan for details.
The probability distributions on isomorphism classes described by the above recipe seem to arise naturally in many applications. For instance, if one draws a profinite abelian group up to isomorphism at random in this fashion (so that each isomorphism class ![{[G]}](https://s0.wp.com/latex.php?latex=%7B%5BG%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Recent Comments