
You are currently browsing the monthly archive for November 2009.
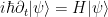
is the fundamental equation of motion for (non-relativistic) quantum mechanics, modeling both one-particle systems and 

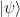


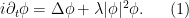
I recently attended a talk by Natasa Pavlovic on the rigorous derivation of this type of limiting behaviour, which was initiated by the pioneering work of Hepp and Spohn, and has now attracted a vast recent literature. The rigorous details here are rather sophisticated; but the heuristic explanation of the phenomenon is fairly simple, and actually rather pretty in my opinion, involving the foundational quantum mechanics of
This discussion will be purely formal, in the sense that (important) analytic issues such as differentiability, existence and uniqueness, etc. will be largely ignored.
After a one-week hiatus, we are resuming our reading seminar of the Hrushovski paper. This week, we are taking a break from the paper proper, and are instead focusing on the subject of stable theories (or more precisely, 
Roughly speaking, stable theories are those in which there are “few” definable sets; a classic example is the theory of algebraically closed fields (of characteristic zero, say), in which the only definable sets are boolean combinations of algebraic varieties. Because of this paucity of definable sets, it becomes possible to define the notion of the Morley rank of a definable set (analogous to the dimension of an algebraic set), together with the more refined notion of Morley degree of such sets (analogous to the number of top-dimensional irreducible components of an algebraic set). Stable theories can also be characterised by their inability to order infinite collections of elements in a definable fashion.
The material here was presented by Anush Tserunyan; her notes on the subject can be found here. Let me also repeat the previous list of resources on this paper (updated slightly):
- Henry Towsner’s notes (which most of Notes 2-4 have been based on; updated to remove references to homogeneity, using only countable saturation);
- Alex Usvyatsov’s notes on the derivation of Corollary 1.2 (broadly parallel to the notes here);
- Lou van den Dries’ notes (covering most of what we have done so far, and also material on stable theories); and
- Anand Pillay’s sketch of a simplified proof of Theorem 1.1.
[A little bit of advertising on behalf of my maths dept. Unfortunately funding for this scholarship was secured only very recently, so the application deadline is extremely near, which is why I am publicising it here, in case someone here may know of a suitable applicant. – T.]
UCLA Mathematics has launched a new scholarship to be granted to an entering freshman who has an exceptional background and promise in mathematics. The UCLA Math Undergraduate Merit Scholarship provides for full tuition, and a room and board allowance. To be considered for fall 2010, candidates must apply on or before November 30, 2009. Details and online application for the scholarship are available here.
Eligibility Requirements:
- 12th grader applying to UCLA for admission in Fall of 2010.
- Outstanding academic record and standardized test scores.
- Evidence of exceptional background and promise in mathematics, such as: placing in the top 25% in the U.S.A. Mathematics Olympiad (USAMO) or comparable (International Mathematics Olympiad level) performance on a similar national competition.
- Strong preference will be given to International Mathematics Olympiad medalists.
In the course of the ongoing logic reading seminar at UCLA, I learned about the property of countable saturation. A model 




Update, Nov 19: I have learned that the above terminology is not quite accurate; countable saturation allows for an uncountable sequence of formulae, as long as the constants used remain finite. So, the discussion here involves a weaker property than countable saturation, which I do not know the official term for. If one chooses a special type of ultrafilter, namely a “countably incomplete” ultrafilter, one can recover the full strength of countable saturation, though it is not needed for the remarks here. Most models are not countably saturated. Consider for instance the standard natural numbers 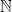
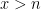

However, if one takes a model 
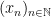


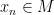

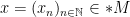
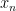
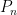
In particular, non-standard models of mathematics, such as the non-standard model 
This has some cute consequences. For instance, suppose one has a non-standard metric space 


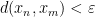
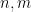



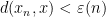
This leads to a non-standard structure theorem for Hilbert spaces, analogous to the orthogonal decomposition in Hilbert spaces:
Theorem 1 (Non-standard structure theorem for Hilbert spaces) Let
be a non-standard Hilbert space, let
be a bounded (external) subset of
. Then there exists a decomposition
, where
is “almost standard-generated by
of
is “standard-orthogonal to
for all
.
Proof: Let 
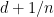
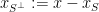

This is the non-standard analogue of a combinatorial structure theorem for Hilbert spaces (see e.g. Theorem 2.6 of my FOCS paper). There is an analogous non-standard structure theorem for 
Theorem 2 (Non-standard arithmetic regularity lemma) Let
be a non-standardly finite abelian group, and let
be a function. Then one can split
, where
is standard-uniform in the sense that all Fourier coefficients are (uniformly)
, and
is standard-almost periodic in the sense that for every standard
to error
norm by a standard linear combination of characters (which is also bounded).
This can be used for instance to give a non-standard proof of Roth’s theorem (which is not much different from the “finitary ergodic” proof of Roth’s theorem, given for instance in Section 10.5 of my book with Van Vu). There is also a non-standard version of the Szemerédi regularity lemma which can be used, among other things, to prove the hypergraph removal lemma (the proof then becomes rather close to the infinitary proof of this lemma in this paper of mine). More generally, the above structure theorem can be used as a substitute for various “energy increment arguments” in the combinatorial literature, though it does not seem that there is a significant saving in complexity in doing so unless one is performing quite a large number of these arguments.
One can also cast density increment arguments in a nonstandard framework. Here is a typical example. Call a non-standard subset 


Theorem 3 Suppose Szemerédi’s theorem (every set of integers of positive upper density contains an arithmetic progression of length
) fails for some
of
with no progressions of length
for any subprogression
of
of unbounded size (thus there is no sizeable density increment on any large progression).
![\displaystyle \frac{|A \cap P|}{|P|} \leq \frac{|A \cap [N]|}{N} + o(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B%7CA+%5Ccap+P%7C%7D%7B%7CP%7C%7D+%5Cleq+%5Cfrac%7B%7CA+%5Ccap+%5BN%5D%7C%7D%7BN%7D+%2B+o%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Let 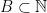


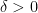
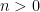

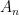
![{[N_n]}](https://s0.wp.com/latex.php?latex=%7B%5BN_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




This can be used as the starting point for any density-increment based proof of Szemerédi’s theorem for a fixed 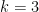
I’m also hoping that the recent results of Hrushovski on the noncommutative Freiman problem require only countable saturation, as this makes it more likely that they can be translated to a non-standard setting and thence to a purely finitary framework.
Let 

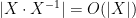
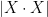
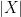
Proposition 1 If
, then
and
are both finite groups, which are conjugate to each other. In particular,
.
Remark 1 The constant
is completely sharp; consider the case when
where
is the identity and
. This is a small example, but one can make it as large as one pleases by taking the direct product of
(resp. left-coset
) of a group of order less than
, then
Proof: We begin by showing that 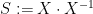
Let 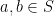


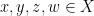



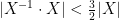



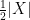






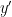




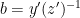

In the course of the above argument we showed that every element of the group 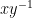
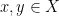
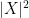
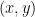
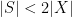
Now let 

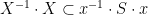

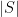


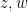
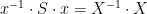
To relate this to the classical doubling constants 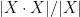
 , then
, then  .
.Again, this is sharp; consider 

Proof: Suppose that 





Proposition 3 If
, then
for some
The factor
Proof: Let 
Pick any 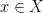


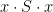

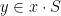

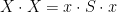

The intersection of the groups 


Because the arguments here are so elementary, they extend easily to the infinitary setting in which 
This week, Henry Towsner concluded his portion of reading seminar of the Hrushovski paper, by discussing (a weaker, simplified version of) main model-theoretic theorem (Theorem 3.4 of Hrushovski), and described how this theorem implied the combinatorial application in Corollary 1.2 of Hrushovski. The presentation here differs slightly from that in Hrushovski’s paper, for instance by avoiding mention of the more general notions of S1 ideals and forking.
Here is a collection of resources so far on the Hrushovski paper:
- Henry Towsner’s notes (which most of Notes 2-4 have been based on);
- Alex Usvyatsov’s notes on the derivation of Corollary 1.2 (broadly parallel to the notes here);
- Lou van den Dries’ notes (covering most of what we have done so far, and also material on stable theories); and
- Anand Pillay’s sketch of a simplified proof of Theorem 1.1.
A fundamental tool in any mathematician’s toolkit is that of reductio ad absurdum: showing that a statement
In mathematics, perhaps the first example of a self-defeating object one encounters is that of a largest natural number:
Proposition 1 (No largest natural number) There does not exist a natural number
Proof: Suppose for contradiction that there was such a largest natural number 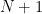
Note the argument does not apply to the extended natural number system in which one adjoins an additional object 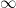

This argument, by the way, is perhaps the only mathematical argument I know of which is routinely taught to primary school children by other primary school children, thanks to the schoolyard game of naming the largest number. It is arguably one’s first exposure to a mathematical non-existence result, which seems innocuous at first but can be surprisingly deep, as such results preclude in advance all future attempts to establish existence of that object, no matter how much effort or ingenuity is poured into this task. One sees this in a typical instance of the above schoolyard game; one player tries furiously to cleverly construct some impressively huge number
It is not only individual objects (such as natural numbers) which can be self-defeating; structures (such as orderings or enumerations) can also be self-defeating. (In modern set theory, one considers structures to themselves be a kind of object, and so the distinction between the two concepts is often blurred.) Here is one example (related to, but subtly different from, the previous one):
Proposition 2 (The natural numbers cannot be finitely enumerated) The natural numbers
cannot be written as
for any finite collection
of natural numbers.
Proof: Suppose for contradiction that such an enumeration 
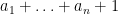
Here it is the enumeration which is self-defeating, rather than any individual natural number such as 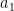
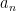
The above argument may seem trivial, but a slight modification of it already gives an important result, namely Euclid’s theorem:
Proposition 3 (The primes cannot be finitely enumerated) The prime numbers
cannot be written as
for any finite collection of prime numbers.
Proof: Suppose for contradiction that such an enumeration 
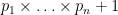


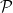
Remark 1 Continuing the number-theoretic theme, the “dueling conspiracies” arguments in a previous blog post can also be viewed as an instance of this type of “no-self-defeating-object”; for instance, a zero of the Riemann zeta function at
implies that the primes anti-correlate almost completely with the multiplicative function
, which is self-defeating because it also implies complete anti-correlation with
, and the two are incompatible. Thus we see that the prime number theorem (a much stronger version of Proposition 3) also emerges from this type of argument.
In this post I would like to collect several other well-known examples of this type of “no self-defeating object” argument. Each of these is well studied, and probably quite familiar to many of you, but I feel that by collecting them all in one place, the commonality of theme between these arguments becomes more apparent. (For instance, as we shall see, many well-known “paradoxes” in logic and philosophy can be interpreted mathematically as a rigorous “no self-defeating object” argument.)
As the previous discussion on displaying mathematics on the web has become quite lengthy, I am opening a fresh post to continue the topic. I’m leaving the previous thread open for those who wish to respond directly to some specific comments in that thread, but otherwise it would be preferable to start afresh on this thread to make it easier to follow the discussion.
It’s not easy to summarise the discussion so far, but the comments have identified several existing formats for displaying (and marking up) mathematics on the web (mathML, jsMath, MathJax, OpenMath), as well as a surprisingly large number of tools for converting mathematics into web friendly formats (e.g. LaTeX2HTML, LaTeXMathML, LaTeX2WP, Windows 7 Math Input, itex2MML, Ritex, Gellmu, mathTeX, WP-LaTeX, TeX4ht, blahtex, plastex, TtH, WebEQ, techexplorer, etc.). Some of the formats are not widely supported by current software, and by current browsers in particular, but it seems that the situation will improve with the next generation of these browsers.
It seems that the tools that already exist are enough to improvise a passable way of displaying mathematics in various formats online, though there are still significant issues with accessibility, browser support, and ease of use. Even if all these issues are resolved, though, I still feel that something is still missing. Currently, if I want to transfer some mathematical content from one location to another (e.g. from a LaTeX file to a blog, or from a wiki to a PDF, or from email to an online document, or whatever), or to input some new piece of mathematics, I have to think about exactly what format I need for the task at hand, and what conversion tool may be needed. In contrast, if one looks at non-mathematical content such as text, links, fonts, non-Latin alphabets, colours, tables, images, or even video, the formats here have been standardised, and one can manipulate this type of content in both online and offline formats more or less seamlessly (in principle, at least – there is still room for improvement), without the need for any particularly advanced technical expertise. It doesn’t look like we’re anywhere near that level currently with regards to mathematical content, though presumably things will improve when a single mathematics presentation standard, such as mathML, becomes universally adopted and supported in browsers, in operating systems, and in other various pieces of auxiliary software.
Anyway, it has been a very interesting and educational discussion for me, and hopefully for others also; I look forward to any further thoughts that readers have on these topics. (Also, feel free to recapitulate some of the points from the previous thread; the discussion has been far too multifaceted for me to attempt a coherent summary by myself.)

Recent Comments