
You are currently browsing the monthly archive for September 2012.
One of the first non-trivial theorems one encounters in classical algebraic geometry is Bézout’s theorem, which we will phrase as follows:
Theorem 1 (Bézout’s theorem) Let
be a field, and let
be non-zero polynomials in two variables
with no common factor. Then the two curves
and
have no common components, and intersect in at most
points.
This theorem can be proven by a number of means, for instance by using the classical tool of resultants. It has many strengthenings, generalisations, and variants; see for instance this previous blog post on Bézout’s inequality. Bézout’s theorem asserts a fundamental algebraic dichotomy, of importance in combinatorial incidence geometry: any two algebraic curves either share a common component, or else have a bounded finite intersection; there is no intermediate case in which the intersection is unbounded in cardinality, but falls short of a common component. This dichotomy is closely related to the integrality gap in algebraic dimension: an algebraic set can have an integer dimension such as 


Bézout’s inequality tells us, roughly speaking, that the intersection of a curve of degree 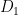
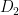



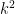


A model example that supports the possibility of such a converse is a grid 

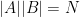
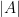

Unfortunately, the naive converse to Bézout’s theorem is false. A counterexample can be given by considering a set 
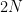
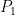
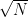
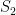


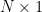
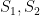
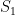
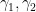
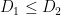

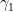

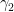


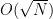
But the above counterexample suggests that even if an arbitrary set of 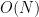
Theorem 2 (Partial converse to Bézout’s theorem) Let
. Then one can find
and pairs
of coprime non-zero polynomials for
such that


Informally, every finite set in the plane is (a dense subset of) the union of logarithmically many nonlinear grids. The presence of the logarithm is necessary, as can be seen by modifying the 
Unfortunately I do not know of any application of this converse, but I thought it was cute anyways. The proof is given below the fold.
There has been a lot of recent interest in the abc conjecture, since the release a few weeks ago of the last of a series of papers by Shinichi Mochizuki which, as one of its major applications, claims to establish this conjecture. It’s still far too early to judge whether this proof is likely to be correct or not (the entire argument encompasses several hundred pages of argument, mostly in the area of anabelian geometry, which very few mathematicians are expert in, to the extent that we still do not even have a full outline of the proof strategy yet), and I don’t have anything substantial to add to the existing discussion around that conjecture. (But, for those that are interested, the Polymath wiki page on the ABC conjecture has collected most of the links to that discussion, and to various background materials.)
In the meantime, though, I thought I might give the standard probabilistic heuristic argument that explains why we expect the ABC conjecture to be true. The underlying heuristic is a common one, used throughout number theory, and it can be summarised as follows:
Heuristic 1 (Probabilistic heuristic) Even though number theory is a deterministic subject (one does not need to roll any dice to factorise a number, or figure out if a number is prime), one expects to get a good asymptotic prediction for the answers to many number-theoretic questions by pretending that various number-theoretic assertions
(e.g. that a given number
is prime) are probabilistic events (with a probability
that can vary between
- (Basic heuristic) If two or more of these heuristically probabilistic events have no obvious reason to be strongly correlated to each other, then we should expect them to behave as if they were (jointly) independent.
- (Advanced heuristic) If two or more of these heuristically probabilistic events have some obvious correlation between them, but no further correlations are suspected, then we should expect them to behave as if they were conditionally independent, relative to whatever data is causing the correlation.
This is, of course, an extremely vague and completely non-rigorous heuristic, requiring (among other things) a subjective and ad hoc determination of what an “obvious reason” is, but in practice it tends to give remarkably plausible predictions, some fraction of which can in fact be backed up by rigorous argument (although in many cases, the actual argument has almost nothing in common with the probabilistic heuristic). A famous special case of this heuristic is the Cramér random model for the primes, but this is not the only such instance for that heuristic.
To give the most precise predictions, one should use the advanced heuristic in Heuristic 1, but this can be somewhat complicated to execute, and so we shall focus instead on the predictions given by the basic heuristic (thus ignoring the presence of some number-theoretic correlations), which tends to give predictions that are quantitatively inaccurate but still reasonably good at the qualitative level.
Here is a basic “corollary” of Heuristic 1:
Heuristic 2 (Heuristic Borel-Cantelli) Suppose one has a sequence
of number-theoretic statements, which we heuristically interpet as probabilistic events with probabilities
. Suppose also that we know of no obvious reason for these events to have much of a correlation with each other. Then:
- If
, we expect only finitely many of the statements
to be true. (And if
is much smaller than
- If
, we expect infinitely many of the statements
This heuristic is motivated both by the Borel-Cantelli lemma, and by the standard probabilistic computation that if one is given jointly independent, and genuinely probabilistic, events 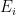
Before we get to the ABC conjecture, let us give two simpler (and well known) demonstrations of these heuristics in action:
Example 1 (Twin prime conjecture) One can heuristically justify the twin prime conjecture as follows. Using the prime number theorem, one can heuristically assign a probability of
to the event that any given large integer
is prime will then be
. Making the assumption that there are no strong correlations between these events, we are led to the prediction that the probability that
. Since
, the Borel-Cantelli heuristic then predicts that there should be infinitely many twin primes.
Note that the above argument is a bit too naive, because there are some non-trivial correlations between the primality of
, which means that
, which ends up decreasing the probability that
Example 2 (Fermat’s last theorem) Let us now heuristically count the number of solutions to
for various
(which we can reduce to be coprime if desired). We recast this (in the spirit of the ABC conjecture) as
, where
are
powers. The number of
, so heuristically any given natural number
has a probability about
of being an
is an
being an
, the probability that
are all simultaneously
. For fixed
(Strictly speaking, we need to restrict to the coprime case, but given that a positive density of pairs of integers are coprime, it should not affect the qualitative conclusion significantly if we now omit this restriction.) It might not be immediately obvious as to whether this sum converges or diverges, but (as is often the case with these sorts of unsigned sums) one can clarify the situation by dyadic decomposition. Suppose for instance that we consider the portion of the sum where
lies between
and
. Then this portion of the sum can be controlled by
which simplifies to
Summing in
, only finitely many solutions for
(indeed, a refinement of this argument shows that one expects only finitely many solutions even if one considers all
. Here is of course a place where a naive application of the probabilistic heuristic breaks down; there is enough arithmetic structure in the equation
that the naive probabilistic prediction ends up being an inaccurate model. Indeed, while this heuristic suggests that a typical homogeneous cubic should have a logarithmic number of integer solutions of a given height


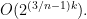
Below the fold, we apply similar heuristics to suggest the truth of the ABC conjecture.
Much as group theory is the study of groups, or graph theory is the study of graphs, model theory is the study of models (also known as structures) of some language 

We will observe the common abuse of notation of using the set 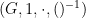

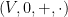


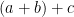



Once one has a structure 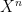


for some formula 
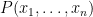



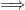
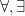

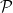
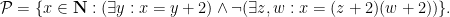
In the theory of the field of reals 
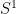
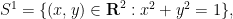
but so is the the complement of the circle,
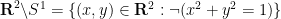
and the interval ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [-1,1] = \{ x \in {\bf R}: \exists y: x^2+y^2 = 1\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B-1%2C1%5D+%3D+%5C%7B+x+%5Cin+%7B%5Cbf+R%7D%3A+%5Cexists+y%3A+x%5E2%2By%5E2+%3D+1%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Due to the unlimited use of constants, any finite subset of a power
We can isolate some special subclasses of definable sets:
- An atomic definable set is a set of the form (1) in which
is an atomic formula (i.e. it does not contain any logical connectives or quantifiers).
- A quantifier-free definable set is a set of the form (1) in which
Example 1 In the theory of a field such as
.
A quantifier-free definable set in 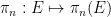
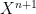
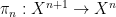

Some structures have the property of enjoying quantifier elimination, which means that every definable set is in fact a quantifier-free definable set, or equivalently that the projection of a quantifier-free definable set is again quantifier-free. For instance, an algebraically closed field 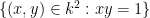
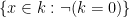
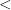
On the other hand, many important structures do not have quantifier elimination; typically, the projection of a quantifier-free definable set is not, in general, quantifier-free definable. This failure of the projection property also shows up in many contexts outside of model theory; for instance, Lebesgue famously made the error of thinking that the projection of a Borel measurable set remained Borel measurable (it is merely an analytic set instead). Turing’s halting theorem can be viewed as an assertion that the projection of a decidable set (also known as a computable or recursive set) is not necessarily decidable (it is merely semi-decidable (or recursively enumerable) instead). The notorious P=NP problem can also be essentially viewed in this spirit; roughly speaking (and glossing over the placement of some quantifiers), it asks whether the projection of a polynomial-time decidable set is again polynomial-time decidable. And so forth. (See this blog post of Dick Lipton for further discussion of the subtleties of projections.)
Now we consider the status of quantifier elimination for the theory of a finite field 
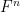
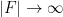


Another way to proceed is to work not with a single finite field 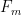
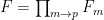
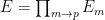
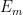



The ultraproduct
As mentioned before, quantifier elimination trivially holds for finite fields. But for infinite pseudo-finite fields, such as the ultraproduct 
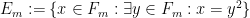

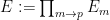
Nevertheless, there is a very nice almost quantifier elimination result for these fields, in characteristic zero at least, which we phrase here as follows:
Theorem 1 (Almost quantifier elimination) Let
be a definable set over
where
is an atomic definable subset of
is a polynomial.

Results of this type were first obtained essentially due to Catarina Kiefe, although the formulation here is closer to that of Chatzidakis-van den Dries-Macintyre.
Informally, this theorem says that while we cannot quite eliminate all quantifiers from a definable set over a nonstandard finite field, we can eliminate all but one existential quantifier. Note that negation has also been eliminated in this theorem; for instance, the definable set 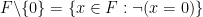


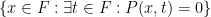
There is an equivalent formulation of this theorem for standard finite fields, namely that if 
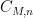
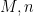
The theorem gives quite a satisfactory description of definable sets in either standard or nonstandard finite fields (at least if one does not care about effective bounds in some of the constants, and if one is willing to exclude the small characteristic case); for instance, in conjunction with the Lang-Weil bound discussed in this recent blog post, it shows that any non-empty definable subset of a nonstandard finite field has a nonstandard cardinality of 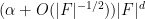


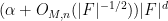
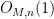
Below the fold I give a proof of Theorem 1, which relies primarily on the Lang-Weil bound mentioned above.
[Note: the idea for this post originated before the recent preprint of Mochizuki on the abc conjecture was released, and is not intended as a commentary on that work, which offers a much more non-trivial perspective on scheme theory. -T.]
In classical algebraic geometry, the central object of study is an algebraic variety
- (Algebraic geometry) One can view a variety through the set
of points (over
- (Commutative algebra) One can view a variety through the field of rational functions
on that variety, or the subring
of polynomial functions in that field.
- (Dual algebraic geometry) One can view a variety through a collection of polynomials
that cut out that variety.
- (Dual commutative algebra) One can view a variety through the ideal
of polynomials that vanish on that variety.
For instance, the unit circle over the reals can be thought of in each of these four different ways:
- (Algebraic geometry) The set of points
.
- (Commutative algebra) The quotient
of the polynomial ring
by the ideal generated by
(or equivalently, the algebra generated by
), or the fraction field of that quotient.
- (Dual algebraic geometry) The polynomial
- (Dual commutative algebra) The ideal
generated by
The four viewpoints are almost equivalent to each other (particularly if the underlying field
Because of the connections between these viewpoints, there are extensive “dictionaries” (most notably the ideal-variety dictionary) that convert basic concepts in one of these four perspectives into any of the other three. For instance, passing from a variety to a subvariety shrinks the set of points and the function field, but enlarges the set of polynomials needed to cut out the variety, as well as the associated ideal. Taking the intersection or union of two varieties corresponds to adding or multiplying together the two ideals respectively. The dimension of an (irreducible) algebraic variety can be defined as the transcendence degree of the function field, the maximal length of chains of subvarieties, or the Krull dimension of the ring of polynomials. And so on and so forth. Thanks to these dictionaries, it is now commonplace to think of commutative algebras geometrically, or conversely to approach algebraic geometry from the perspective of abstract algebra. There are however some very well known defects to these dictionaries, at least when viewed in the classical setting of algebraic varieties. The main one is that two different ideals (or two inequivalent sets of polynomials) can cut out the same set of points, particularly if the underlying field 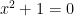
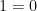
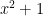
![{{\bf R}[x]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+R%7D%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


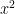

![{{\bf C}[x]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+C%7D%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Nowadays, the standard way to deal with these issues is to replace the notion of an algebraic variety with the more general notion of a scheme. Roughly speaking, the way schemes are defined is to focus on the commutative algebra perspective as the primary one, and to allow the base field
Thus, for instance, in scheme theory the rings ![{{\bf R}[x]/(x^2)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+R%7D%5Bx%5D%2F%28x%5E2%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\bf R}[x]/(x)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+R%7D%5Bx%5D%2F%28x%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
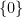

Because of this, it seems that the link between the commutative algebra perspective and the algebraic geometry perspective is still not quite perfect in scheme theory, unless one is willing to start “fattening” various varieties to correctly model multiplicity or singularity. But – and this is the trivial remark I wanted to make in this blog post – one can recover a tight connection between the two perspectives as long as one allows the freedom to arbitrarily extend the underlying base ring.
Here’s what I mean by this. Consider classical algebraic geometry over some commutative ring 
![{P_1,\ldots,P_m \in R[x_1,\ldots,x_d]}](https://s0.wp.com/latex.php?latex=%7BP_1%2C%5Cldots%2CP_m+%5Cin+R%5Bx_1%2C%5Cldots%2Cx_d%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
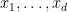

![\displaystyle = \{P_1Q_1+\ldots+P_mQ_m: Q_1,\ldots,Q_m \in R[x_1,\ldots,x_d]\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%5C%7BP_1Q_1%2B%5Cldots%2BP_mQ_m%3A+Q_1%2C%5Cldots%2CQ_m+%5Cin+R%5Bx_1%2C%5Cldots%2Cx_d%5D%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
in ![{R[x_1,\ldots,x_d]}](https://s0.wp.com/latex.php?latex=%7BR%5Bx_1%2C%5Cldots%2Cx_d%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle V[R] := \{ (y_1,\ldots,y_d) \in R^d: P_1(y_1,\ldots,y_d) = \ldots = P_m(y_1,\ldots,y_d) = 0 \},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%5D+%3A%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+R%5Ed%3A+P_1%28y_1%2C%5Cldots%2Cy_d%29+%3D+%5Cldots+%3D+P_m%28y_1%2C%5Cldots%2Cy_d%29+%3D+0+%5C%7D%2C&bg=ffffff&fg=000000&s=0&c=20201002)
since each of the polynomials 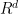
![{V[R]}](https://s0.wp.com/latex.php?latex=%7BV%5BR%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle V[R] := \{ (y_1,\ldots,y_d) \in R^d: P(y_1,\ldots,y_d) = 0 \hbox{ for all } P \in I \}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%5D+%3A%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+R%5Ed%3A+P%28y_1%2C%5Cldots%2Cy_d%29+%3D+0+%5Chbox%7B+for+all+%7D+P+%5Cin+I+%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Thus the ideal ![{V_I[R]}](https://s0.wp.com/latex.php?latex=%7BV_I%5BR%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
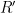
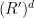
![\displaystyle V[R'] := \{ (y_1,\ldots,y_d) \in (R')^d:](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%27%5D+%3A%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+%28R%27%29%5Ed%3A+&bg=ffffff&fg=000000&s=0&c=20201002)
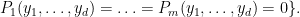
As before, ![{V[R']}](https://s0.wp.com/latex.php?latex=%7BV%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle V[R'] = V_I[R'] := \{ (y_1,\ldots,y_d) \in (R')^d:](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%27%5D+%3D+V_I%5BR%27%5D+%3A%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+%28R%27%29%5Ed%3A+&bg=ffffff&fg=000000&s=0&c=20201002)
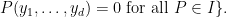
The trivial remark is then that while a single zero locus ![{V_I[R']}](https://s0.wp.com/latex.php?latex=%7BV_I%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{R' \mapsto V_I[R']}](https://s0.wp.com/latex.php?latex=%7BR%27+%5Cmapsto+V_I%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
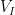
![{V_I[R_0]}](https://s0.wp.com/latex.php?latex=%7BV_I%5BR_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
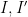
![\displaystyle V_I[R'] = V_{I'}[R'] \neq \emptyset](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V_I%5BR%27%5D+%3D+V_%7BI%27%7D%5BR%27%5D+%5Cneq+%5Cemptyset&bg=ffffff&fg=000000&s=0&c=20201002)
for all extensions ![{R' := R_0[x_1,\ldots,x_d]/I}](https://s0.wp.com/latex.php?latex=%7BR%27+%3A%3D+R_0%5Bx_1%2C%5Cldots%2Cx_d%5D%2FI%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{R_0[x_1,\ldots,x_d]/I}](https://s0.wp.com/latex.php?latex=%7BR_0%5Bx_1%2C%5Cldots%2Cx_d%5D%2FI%7D&bg=ffffff&fg=000000&s=0&c=20201002)
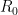
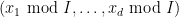
![{V_{I'}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7BI%27%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

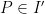


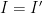
![{V_{(2)}[R'] = V_{(3)}[R'] = \emptyset}](https://s0.wp.com/latex.php?latex=%7BV_%7B%282%29%7D%5BR%27%5D+%3D+V_%7B%283%29%7D%5BR%27%5D+%3D+%5Cemptyset%7D&bg=ffffff&fg=000000&s=0&c=20201002)

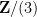
![{V_{(2)}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7B%282%29%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{V_{(3)}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7B%283%29%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Thus, as long as one thinks of a variety or scheme as cutting out points not just in the original base ring or field, but in all extensions of that base ring or field, one recovers an exact correspondence between the algebraic geometry perspective and the commutative algebra perspective. This is similar to the classical algebraic geometry position of viewing an algebraic variety as being defined simultaneously over all fields that contain the coefficients of the defining polynomials, but the crucial difference between scheme theory and classical algebraic geometry is that one also allows definition over commutative rings, and not just fields. In particular, one needs to allow extensions to rings that may contain nilpotent elements, otherwise one cannot distinguish an ideal from its radical.
There are of course many ways to extend a field into a ring, but as an analyst, one way to do so that appeals particularly to me is to introduce an epsilon parameter and work modulo errors of 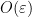
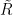
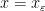
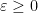
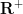


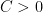
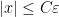
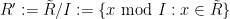


Clearly,
![\displaystyle V[{\bf R}] = \{ (y_1,\ldots,y_d) \in {\bf R}^d: P_1(y_1,\ldots,y_d) = \ldots = P_m(y_1,\ldots,y_d) = 0 \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5B%7B%5Cbf+R%7D%5D+%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+%7B%5Cbf+R%7D%5Ed%3A+P_1%28y_1%2C%5Cldots%2Cy_d%29+%3D+%5Cldots+%3D+P_m%28y_1%2C%5Cldots%2Cy_d%29+%3D+0+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
defined over the reals
![\displaystyle V[R'] = \{ (y_1,\ldots,y_d) \in (R')^d:](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%27%5D+%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+%28R%27%29%5Ed%3A+&bg=ffffff&fg=000000&s=0&c=20201002)
In language that more closely resembles analysis, we have
![\displaystyle V[R'] = \{ (y_1,\ldots,y_d) \in \tilde R^d: P_1(y_1,\ldots,y_d), \ldots, P_m(y_1,\ldots,y_d) = O(\varepsilon) \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V%5BR%27%5D+%3D+%5C%7B+%28y_1%2C%5Cldots%2Cy_d%29+%5Cin+%5Ctilde+R%5Ed%3A+P_1%28y_1%2C%5Cldots%2Cy_d%29%2C+%5Cldots%2C+P_m%28y_1%2C%5Cldots%2Cy_d%29+%3D+O%28%5Cvarepsilon%29+%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

Thus we see that ![{V[{\bf R}]}](https://s0.wp.com/latex.php?latex=%7BV%5B%7B%5Cbf+R%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
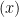
![\displaystyle V_{(x)}[R'] = \{ y \in \tilde R: y = O(\varepsilon) \} \hbox{ mod } I,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V_%7B%28x%29%7D%5BR%27%5D+%3D+%5C%7B+y+%5Cin+%5Ctilde+R%3A+y+%3D+O%28%5Cvarepsilon%29+%5C%7D+%5Chbox%7B+mod+%7D+I%2C&bg=ffffff&fg=000000&s=0&c=20201002)
but the scheme associated to the smaller ideal 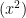
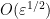
![\displaystyle V_{(x^2)}[R'] = \{ y \in \tilde R: y^2 = O(\varepsilon) \} \hbox{ mod } I](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V_%7B%28x%5E2%29%7D%5BR%27%5D+%3D+%5C%7B+y+%5Cin+%5Ctilde+R%3A+y%5E2+%3D+O%28%5Cvarepsilon%29+%5C%7D+%5Chbox%7B+mod+%7D+I&bg=ffffff&fg=000000&s=0&c=20201002)
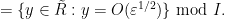
Once one introduces the analyst’s epsilon, one can see quite clearly that ![{V_{(x^2)}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7B%28x%5E2%29%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{V_{(x)}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7B%28x%29%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
By working with this analyst’s extension of 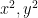
![\displaystyle V_{(x^2,y^2)}[R'] = \{ (x,y) \in \tilde R^2: x^2, y^2 = O(\varepsilon) \} \hbox{ mod } I^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++V_%7B%28x%5E2%2Cy%5E2%29%7D%5BR%27%5D+%3D+%5C%7B+%28x%2Cy%29+%5Cin+%5Ctilde+R%5E2%3A+x%5E2%2C+y%5E2+%3D+O%28%5Cvarepsilon%29+%5C%7D+%5Chbox%7B+mod+%7D+I%5E2+&bg=ffffff&fg=000000&s=0&c=20201002)
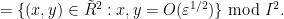
Note that the polynomial 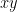
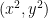
![{V_{(x^2,y^2)}[R'] = V_{(x^2,y^2,xy)}[R']}](https://s0.wp.com/latex.php?latex=%7BV_%7B%28x%5E2%2Cy%5E2%29%7D%5BR%27%5D+%3D+V_%7B%28x%5E2%2Cy%5E2%2Cxy%29%7D%5BR%27%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
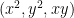
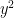
One can also view ideals (and hence, schemes), from a model-theoretic perspective. Let 
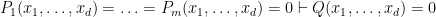
(since

for any assignment of indeterminates 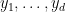

for all 
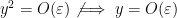
we no longer have a counterexample to the converse coming from
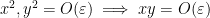
so the extension

Recent Comments