
You are currently browsing the tag archive for the ‘quasirandom groups’ tag.
Suppose that 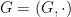



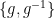
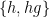
The classical Brauer-Fowler theorem asserts that if a group
Theorem 1 (Brauer-Fowler theorem) Let
involutions for some
. Then
of index at most
.
This theorem (which is Theorem 2F in the original paper of Brauer and Fowler, who in fact manage to sharpen 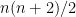
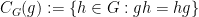




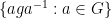
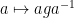
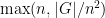
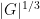
Another corollary is that the size of a simple group of even order can be controlled by the size of a centraliser of one of its involutions:
Corollary 2 (Brauer-Fowler theorem) Let
.
Indeed, by the previous discussion 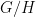
If one assumes the Feit-Thompson theorem that all groups of odd order are solvable, then Corollary 2 suggests a strategy (first proposed by Brauer himself in 1954) to prove the classification of finite simple groups (CFSG) by induction on the order of the group. Namely, assume for contradiction that the CFSG failed, so that there is a counterexample 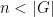
Needless to say, this program turns out to be far more difficult than the above summary suggests, and the actual proof of the CFSG does not quite proceed along these lines. However, a significant portion of the argument is based on a generalisation of this strategy, in which the concept of a centraliser of an involution is replaced by the more general notion of a normaliser of a 
The Brauer-Fowler theorem can be proven by a nice application of character theory, of the type discussed in this recent blog post, ultimately based on analysing the alternating tensor power of representations; I reproduce a version of this argument (taken from this text of Isaacs) below the fold. (The original argument of Brauer and Fowler is more combinatorial in nature.) However, I wanted to record a variant of the argument that relies not on the fine properties of characters, but on the cruder theory of quasirandomness for groups, the modern study of which was initiated by Gowers, and is discussed for instance in this previous post. It gives the following slightly weaker version of Corollary 2:
Corollary 3 (Weak Brauer-Fowler theorem) Let
.
One can get an upper bound on
Proof: Let 
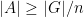
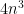
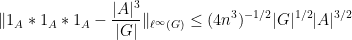
(see Exercise 10 from this previous blog post). In particular,
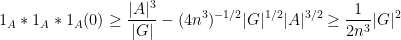
and so there are at least 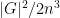
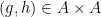
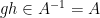


Thus there are at least 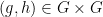
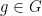

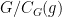
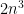

I’ve just uploaded to the arXiv my paper “Mixing for progressions in non-abelian groups“, submitted to Forum of Mathematics, Sigma (which, along with sister publication Forum of Mathematics, Pi, has just opened up its online submission system). This paper is loosely related in subject topic to my two previous papers on polynomial expansion and on recurrence in quasirandom groups (with Vitaly Bergelson), although the methods here are rather different from those in those two papers. The starting motivation for this paper was a question posed in this foundational paper of Tim Gowers on quasirandom groups. In that paper, Gowers showed (among other things) that if 



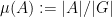


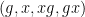




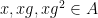
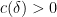

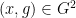


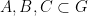



For non-quasirandom groups, such mixing properties can certainly fail. For instance, if 
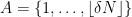
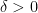
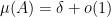




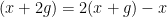




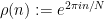
However, by definition, quasirandom groups do not have low-dimensional representations, and Gowers asked whether mixing for 






I was also able to obtain a partial result for the length four progression 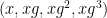

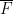
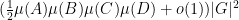


For the length three argument, the main tools used are the Cauchy-Schwarz inequality, the quasirandomness of 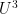
I give some details of these arguments below the fold.
I’ve just uploaded to the arXiv my joint paper with Vitaly Bergelson, “Multiple recurrence in quasirandom groups“, which is submitted to Geom. Func. Anal.. This paper builds upon a paper of Gowers in which he introduced the concept of a quasirandom group, and established some mixing (or recurrence) properties of such groups. A 
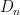
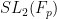


where 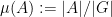


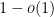

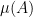
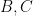

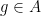
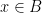
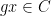



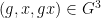
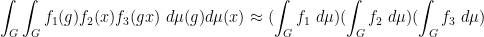
for any bounded functions 
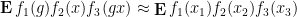
where 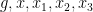
As observed in Gowers’ paper, one can iterate this observation to find “parallelopipeds” of any given dimension in dense subsets of 



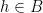
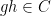
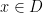
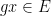
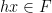
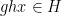

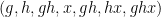

However, there are other tuples for which the above iteration argument does not seem to apply. One of the simplest tuples in this vein is the tuple 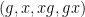

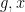
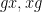


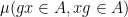

Theorem 1 Let
, we have
where
,
are drawn uniformly and independently at random from
is drawn uniformly at random from the conjugates of
for each fixed choice of
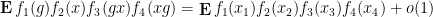
This is the probabilistic formulation of the above theorem; one can also phrase the theorem in other formulations (such as an integral formulation), and this is detailed in the paper. This theorem leads to a number of recurrence results; for instance, as a corollary of this result, we have

for almost all 
To me, the more interesting thing here is not the result itself, but how it is proven. Vitaly and I were not able to find a purely finitary way to establish this mixing theorem. Instead, we had to first use the machinery of ultraproducts (as discussed in this previous post) to convert the finitary statement about a quasirandom group to an infinitary statement about a type of infinite group which we call an ultra quasirandom group (basically, an ultraproduct of increasingly quasirandom finite groups). This is analogous to how the Furstenberg correspondence principle is used to convert a finitary combinatorial problem into an infinitary ergodic theory problem.
Ultra quasirandom groups come equipped with a finite, countably additive measure known as Loeb measure 


for “almost all” 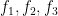
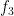
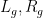

To establish this mixing theorem, we use the machinery of idempotent ultrafilters, which is a particularly useful tool for understanding the ergodic theory of actions of countable groups 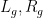
Idempotent ultrafilters are an extremely infinitary type of mathematical object (one has to use Zorn’s lemma no fewer than three times just to construct one of these objects!). So it is quite remarkable that they can be used to establish a finitary theorem such as Theorem 1, though as is often the case with such infinitary arguments, one gets absolutely no quantitative control whatsoever on the error terms
We also have some miscellaneous other results in the paper. It turns out that by using the triangle removal lemma from graph theory, one can obtain a recurrence result that asserts that whenever 



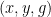
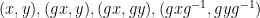
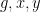
We also give some properties of a model example of an ultra quasirandom group, namely the ultraproduct 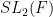
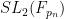

In the previous set of notes we saw how a representation-theoretic property of groups, namely Kazhdan’s property (T), could be used to demonstrate expansion in Cayley graphs. In this set of notes we discuss a different representation-theoretic property of groups, namely quasirandomness, which is also useful for demonstrating expansion in Cayley graphs, though in a somewhat different way to property (T). For instance, whereas property (T), being qualitative in nature, is only interesting for infinite groups such as 
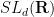
The definition of quasirandomness is easy enough to state:
Definition 1 (Quasirandom groups) Let
. We say that
of
is the identity for all
Exercise 1 Let
and
Remark 1 The terminology “quasirandom group” was introduced explicitly (though with slightly different notational conventions) by Gowers in 2008 in his detailed study of the concept; the name arises because dense Cayley graphs in quasirandom groups are quasirandom graphs in the sense of Chung, Graham, and Wilson, as we shall see below. This property had already been used implicitly to construct expander graphs by Sarnak and Xue in 1991, and more recently by Gamburd in 2002 and by Bourgain and Gamburd in 2008. One can of course define quasirandomness for more general locally compact groups than the finite ones, but we will only need this concept in the finite case. (A paper of Kunze and Stein from 1960, for instance, exploits the quasirandomness properties of the locally compact group
to obtain mixing estimates in that group.)
Quasirandomness behaves fairly well with respect to quotients and short exact sequences:
Exercise 2 Let
be a short exact sequence of finite groups
.
- (i) If
is
- (ii) Conversely, if
Informally, we will call 

The way we have set things up, the trivial group 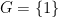
Exercise 3 Let
- (i) Show that if
. (Hint: use the mean zero component
of the regular representation
.) In particular, non-trivial finite groups cannot be infinitely quasirandom.
- (ii) Show that any proper subgroup
. (Hint: use the mean zero component of the quasiregular representation.)
The following exercise shows that quasirandom groups have to be quite non-abelian, and in particular perfect:
Exercise 4 (Quasirandomness, abelianness, and perfection) Let
- (i) If
-quasirandom. (Hint: use Fourier analysis or the classification of finite abelian groups.)
- (ii) Show that
is equal to
Later on we shall see that there is a converse to the above two exercises; any non-trivial perfect finite group with no large subgroups will be quasirandom.
Exercise 5 Let
of
-quasirandom, where
is the index of
Now we give an example of a more quasirandom group.
Lemma 2 (Frobenius lemma) If
is a field of some prime order
-quasirandom.
This should be compared with the cardinality 
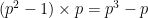
Proof: We may of course take 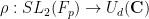
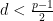

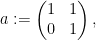
and suppose first that 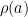


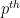

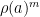

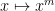


Exercise 6 Show that for any prime
for
ranging over

Exercise 7 Let
of
Exercise 8 Show that
is
and any prime
, which follows from the results of Landazuri and Seitz.)
As a corollary of the above results and Exercise 2, we see that the projective special linear group 
Remark 2 One can ask whether the bound
, we see that it also acts projectively on the projective line
, which has
elements. Thus
, and also on the
; this latter representation (known as the Steinberg representation) is irreducible. This shows that the
,
of functions
that obey the twisted dilation invariance
for all
and
; these are known as the principal series representations. When
is the trivial character, this is the quasiregular representation discussed earlier. For most other characters, this is an irreducible representation, but it turns out that when
while being non-trivial), the principal series representation splits into the direct sum of two
-dimensional representations, which comes very close to matching the bound in Lemma 2. There is a parallel series of representations to the principal series (known as the discrete series) which is more complicated to describe (roughly speaking, one has to embed
and then use a rotated version of the above construction, to change a split torus into a non-split torus), but can generate irreducible representations of dimension
Exercise 9 Let
, the alternating group
is
-quasirandom. (Hint: show that all cycles of order
); in particular, a cycle is conjugate to its
power for all
. Also, as
,
Remark 3 By using more precise information on the representations of the alternating group (using the theory of Specht modules and Young tableaux), one can show the slightly sharper statement that
-quasirandom for
(but is only
-quasirandom for
due to icosahedral symmetry, and
due to lack of perfectness). Using Exercise 3 with the index
, we see that the bound
If one replaces the alternating group
, is not perfect); indeed,
Remark 4 Thanks to the monumental achievement of the classification of finite simple groups, we know that apart from a finite number (26, to be precise) of sporadic exceptions, all finite simple groups (up to isomorphism) are either a cyclic group
, an alternating group
in characteristic
, it is known from the work of Landazuri and Seitz that such groups are
-quasirandom for some
-quasirandom for some
, then
. It would be of interest to see if there was an alternate way to establish this fact that did not rely on the classification, as it may lead to an alternate approach to proving the classification (or perhaps a weakened version thereof).
A key reason why quasirandomness is desirable for the purposes of demonstrating expansion is that quasirandom groups happen to be rapidly mixing at large scales, as we shall see below the fold. As such, quasirandomness is an important tool for demonstrating expansion in Cayley graphs, though because expansion is a phenomenon that must hold at all scales, one needs to supplement quasirandomness with some additional input that creates mixing at small or medium scales also before one can deduce expansion. As an example of this technique of combining quasirandomness with mixing at small and medium scales, we present a proof (due to Sarnak-Xue, and simplified by Gamburd) of a weak version of the famous “3/16 theorem” of Selberg on the least non-trivial eigenvalue of the Laplacian on a modular curve, which among other things can be used to construct a family of expander Cayley graphs in 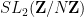
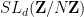

Recent Comments