
Over two years ago, Emmanuel Candés and I submitted the paper “The Dantzig selector: Statistical estimation when 
larger than 
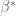

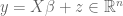

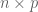



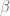
Our selection algorithm, inspired by our previous work on compressed sensing, chooses the estimated parameters 
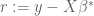

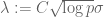
(one can check that such a condition is obeyed with high probability in the case that 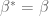

A simple model case arises when n=p and X is the identity matrix, thus the observations are given by a simple additive noise model 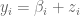

The mean square error 
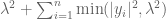
and one can show that this is basically best possible (except for constants and logarithmic factors) amongst all selectors in this model. More generally, the main result of our paper was that under the assumption that the predictor matrix obeys the RIP, the mean square error of the Dantzig selector is essentially equal to (2) and thus close to best possible.
After accepting our paper, the Annals of Statistics took the (somewhat uncommon) step of soliciting responses to the paper from various experts in the field, and then soliciting a rejoinder to these responses from Emmanuel and I. Recently, the Annals posted these responses and rejoinder on the arXiv:
- Bickel compared these results with recent results on the lasso selector by Bunea-Tsybakov-Wegcamp and Meinshausen-Yu, commented on the naturality of the constraint (1), raised the issue of collinearity (which is precluded by the RIP hypothesis, but can of course occur in practice), and proposed the use of tools such as cross-validation to estimate the quantity
appearing in the constraint (1).
- Efron, Hastie, and Tibshirani performed numerics to compare the accuracy of the Dantzig selector and the lasso selector, the performance was broadly rather similar, but the Dantzig selector appeared to have some artefacts arising from the constraint (1).
- Cai and Lv asked whether the
factor in (1) was too conservative in the case when p was extremely large compared to n, leading to an overly sparse model
- Ritov raised a more philosophical point, as to whether the prediction error (which is essentially
in this model) is a better indicator of accuracy than the loss
.
- Meinshausen, Rocha, and Yu compared our results with similar (though not perfectly analogous) existing results for the lasso selector, as well as an comparative analysis in low-dimensional situations. Their numerical experiments also suggest that the
- Friedlander and Saunders focused on the speed of implementation of the Dantzig selector, concluding that using general-purpose linear algebra solvers (e.g. the simplex method) was moderately computationally intensive in practice.
Finally, Candès and myself gave a rejoinder to these responses. Our main points were:
- Regarding collinearity (which in particular implies breakdown of the RIP), an accurate estimation of the parameters
instead, but our selector is focused on applications (such as imaging, ADC conversion, or genomics) in which
- We agree with the points made that the parameters in (1) need to be tuned further to optimise performance, and in particular that cross-validation is an eminently sensible idea for this purpose. Note that in many applications (e.g. imaging), the variance
- The mean-square error for the Dantzig selector does tend to underperform that for the the lasso selector slightly in many cases, but (as noted in our original paper) this can be compensated for by using a slightly more complicated Gauss-Dantzig selector in which the Dantzig selector is used to locate the “active” parameters, to which one then applies a classical least-squares regression method.
- Running time of off-the-shelf implementations of the Dantzig selector are indeed somewhat of a concern for large data sets (e.g.
measurements). But the same could have been said of the lasso selector when it was first introduced, and we expect to see faster ways to implement the algorithm in the future.
It was an interesting and challenging new experience for Emmanuel and myself to engage in a formal discussion over one of my papers in a journal venue; I suppose this sort of thing is more common in the applied sciences such as statistics, but seems to be rather rare in pure mathematics.
Incidentally, after this rejoinder was submitted, more recent work has appeared showing that the lasso selector enjoys similar performance guarantees to the Dantzig selector: see this paper of Bickel, Ritov, and Tsybakov. Also, a nice way to perform cross-validation for general compressed sensing problems via the Johnson-Lindenstrauss lemma was noted very recently by Ward.
[Update, Mar 22: The journal issue (Vol. 35, No. 6, 2007) in which all these articles appear can be found here.]
[Update, Mar 29: I have learned also of the recent paper of James, Radchenko, and Lv, which introduces a new “DASSO” algorithm for computing the Dantzig selector in time comparable to that of the best known Lasso algorithms, and provides further theoretical connections between the two selectors.]

16 comments
Comments feed for this article
22 March, 2008 at 2:56 pm
Jed Harris
I’d like to read the articles you reference at arXiv, but all the commentary and your own response are embargoed. I don’t know if there is anything you can do about that.
22 March, 2008 at 3:03 pm
Terence Tao
Oops… these articles should be available within about 24 hours (Sun 8pm EST, to be precise). I guess I posted too soon…
On the other hand, the articles are available from Project Euclid (if your institution has a subscription), at
http://projecteuclid.org/DPubS?service=UI&version=1.0&verb=Display&handle=euclid.aos/1201012955
24 March, 2008 at 6:21 am
John Sidles
Many of the topics on the (wonder-full) weblog — like parameter estimation, compressive sampling, and even Ricci flow — share the common theme of order reduction (the reduction or approximation of complex systems as simpler systems). That is why this is one of my favorite blogs … order reduction is the essence of engineering.
It can happen, however, the underlying mathematical state-space seems either too restrictive (the linear framework of compressive sampling) or too general (the coordinate-free manifolds of Ricci flow).
In practice, the state-spaces that we engineers *really* like tend to be the the nonlinear yet computationally tractable state-spaces of algebraic geometry. For us, these state-spaces are “the porridge that is not too hot and not too cold.”
Speaking only for myself, it is quite challenging to develop an appreciation for what is known, and what is not yet known, in this mathematical area. That is why posts in this area are always *very* welcome.
And, thanks to all who contribute to this fine weblog.
24 March, 2008 at 4:01 pm
Gabriel Peyré
Small typo : “Hard thresholding” should be replaced by “Soft thresholding”.
24 March, 2008 at 4:29 pm
Terence Tao
Thanks for the correction!
29 March, 2008 at 2:05 pm
Zhou Fang
Are you aware of the work by Gareth James on his ‘DASSO’ algorithm? It’s a LARS modification, so substantially faster for full-solution path calculation. (e.g . for CV) Though it’s somewhat slower than lasso/lars (since the Dantzig path seems to have more break points), it looks pretty close to optimal.
29 March, 2008 at 6:00 pm
Terence Tao
Thanks for the reference, which I was unaware of! It now seems, in view of recent literature, that the Dantzig selector and LASSO selector are in fact extremely close cousins of each other in many respects.
7 May, 2008 at 9:56 am
David Molnar
Gareth James also has a more recent paper with P. Radchenko on “A Generalized Dantzig Selector with Shrinkage Tuning” listed on his web page. He also includes code for the method in R, in case anyone wants to try it:
http://www-rcf.usc.edu/~gareth/research/gdscode
4 July, 2008 at 6:24 am
Anonymous
“The journal issue (Vol. 35, No. 6, 1997)” you mean 2007, of course.
4 July, 2008 at 7:51 am
Terence Tao
Dear anonymous: thanks for the correction!
27 July, 2010 at 6:40 am
sounak
Dear Prof. Tao,
Do you think a Bayesian Dantzig selector based on the “loss likelihood duality” principle will be an interesting study. I know directly constructing the likelihood from L-infinity loss may be not very reasonable, but how about some continuous approximations of the L-infinity norm.
warm regards
sounak
4 May, 2013 at 6:21 am
Connie Leung
Hi there, I am a student at the University of Southampton, UK. I chose to study subset selection and shrinkage methods techniques in order to see which of the 13 covariates are best to model property values. Of these methods, one of the methods I have chosen to look at is the Dantzig Selector but cannot find the codes for this method. Is there any chance that you could send me what the code would be? (I will acknowledge you in my report! :) ) Many thanks! Connie
4 May, 2013 at 10:52 am
Terence Tao
My co-authors developed the l1-Magic package at http://users.ece.gatech.edu/~justin/l1magic/ to do these sorts of computations, though my understanding is that nowadays there are significantly faster methods available than this one.
4 May, 2013 at 2:01 pm
Connie Leung
Many thanks! I understand there are probably faster methods but my study is on this method so this would be useful – thank you!
25 April, 2017 at 4:44 am
Rajesh
Prof Terence Tao : Could you please comment on this fundamental problem : https://math.stackexchange.com/q/2249528/2987
17 June, 2018 at 8:21 am
Alexander Davis
I don’t think you should jump from “X is colinear” to “estimation of β is essentially hopeless”. It depends on the loss function.
Consider the changepoint problem. A piecewise constant vector Y is equal to Lβ, where L is a lower triangular matrix of 1’s and β is sparse. In the presence of noise you can’t find an estimate β* which will perfectly recover β. But you consider it a job well-done if the non-zero entries of β* are near the non-zero entries of β.
This suggests a loss function something like
$$\sum_{i=1}^p (\beta^*_i – a_i)^2 + \|\beta\|_0$$
where
$$a_i = \frac{1}{11}\sum_{k=i-5}^{i+5} \beta_i$$
This problem has a sequential structure, and there are similar problems with more complex structures. For example, here’s a similar problem with a tree structure. You are given a phylogenetic tree of $n$ species, and for each species $i$, you are given $y_i$, the copy number of a certain gene in the genome of that species. Where, on the phylogenetic tree, did this gene undergo duplications and deletions?
My own statistical work involves a sort of hybrid between these two problems, where we have a sequence of identical trees, and each node is linked to the corresponding node in the next tree.
So, here’s a general problem that might appeal to you as a mathematician. It includes the case of estimating β, the case of estimating Xβ, and all the cases above.
Given a system Xβ+ε = y, with unknown sparse β, find an estimate β* to minimize the loss function ||Aβ – Αβ||*.
(And if you know anyone that has studied this, please link me to the papers.)