
Van Vu and I have just uploaded to the arXiv our paper “Random matrices: A general approach for the least singular value problem“, submitted to Israel J. Math.. This paper continues a recent series of papers by ourselves and also by Rudelson and by Rudelson–Vershynin on understanding the least singular value 


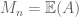


In the model mean zero case 



![{}[0, 2\sqrt{n}]](https://s0.wp.com/latex.php?latex=%7B%7D%5B0%2C+2%5Csqrt%7Bn%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002)



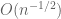

There have been several papers establishing lower tail bounds on the least singular value consistent with the above conjecture of varying degrees of strength, under various hypotheses on the matrix 
- In 1988, Edelman showed that
for any
when
and x is Gaussian (there is also a matching lower bound when
).
- Some non-trivial bounds on
for very small
(polynomially small in size) are established implicitly in the case when
- In 2005, Rudelson showed that
when
- In 2005, Van Vu and I showed that for every
there existed
such that
, when
- In 2006, Senkar, Teng, and Spielman extended Edelman’s result to the case when
- In 2007, Rudelson-Vershynin showed that
for
for all
- In 2007, Van Vu and I showed that our earlier result extends to the case when
- In 2007, Van Vu and I removed the integrality assumptions on our previous results, thus establishing the bound
- In 2008, Rudelson and Vershynin obtained generalisations of their previous results to rectangular matrices (thus also generalising some previous work of Litvak, Pajor, Rudelson, and Tomczak-Jaegermann), but still for the case
These recent results are largely based on entropy (or “epsilon-net”) arguments, combined with conditioning arguments, with the entropy bounds in turn originating from inverse Littlewood-Offord theorems; see my Lewis lectures for further discussion.
The current paper is a partial unification of the results of Rudelson and Vershynin (which give very sharp tail estimates, but under strong hypotheses on M and x) and ourselves (which have very general assumptions on M and x, but a weak tail estimate). A little more precisely, we obtain an estimate of the form

for any fixed 


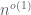


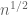



We also give a simple example that show that the deterioration of these bounds when 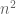

Our methods here are based on those of earlier papers, particularly our circular law paper; the key innovation is to run a certain scale pigeonholing argument as efficiently as possible, so that one only loses factors of
[Update, May 22: some typos corrected.]

5 comments
Comments feed for this article
22 May, 2008 at 11:47 pm
Robert
I know this is quite a different question but maybe you know the answer: What happens over a finite field F, with N elements, say. If I pick the matrix elements independently with a flat distribution, what is the probability that the matrix A is not invertible? My guess would be 1/N, since one could imagine all elements but the last (a11 say) have been drawn already and det(A)= c1 + c2 a11 with some constants c1 and c2. If c2 does not vanish the determinant takes all N different values when a11 is varied but the case of c2=0 (some minor) it depends on the distribution of c1’s…
This problem came up in an encoding problem: There (imagine for example a RAID system) you want to spread information between a number of different people. For example the data are many (say L) vectors in F^k and everybody in a room has access to those vectors. However they cannot remember kL numbers. But if everybody picks one random vector and projects all the L vectors on that random vector and just remebers the random vector and the L scalar products. Then the full information can likely be reconstructed by any choice of k people (namely if their random vectors are linearly independent). So I am asking what is the probability that this fails?
23 May, 2008 at 1:07 am
enric
wow, you can also prove theorems in the future!
(e.g., item 9)
23 May, 2008 at 7:01 am
Emmanuel Kowalski
For the question in Comment 1 (if I understand it right) for matrrices of size , the probability you want seems to be simply one minus the ratio of the order of the group of invertible matrices divided by
, the probability you want seems to be simply one minus the ratio of the order of the group of invertible matrices divided by  . The order of the group of invertible matrices is well-known, and one finds this probability is
. The order of the group of invertible matrices is well-known, and one finds this probability is
which has a limit (for fixed ) as
) as  goes to infinity (one minus the inverse of the generating series of the partition function, evaluated at
goes to infinity (one minus the inverse of the generating series of the partition function, evaluated at  ). This is indeed asymptotic to
). This is indeed asymptotic to  by Taylor expansion, when
by Taylor expansion, when  is large.
is large.
Because the answer is explicit, one can also understand the behavior in many mixed situations when both and the size
and the size  of the matrices are fixed.
of the matrices are fixed.
23 May, 2008 at 9:40 am
Terence Tao
Dear Enric: Oops, thanks for the correction!
Dear Robert: Emmanuel is correct. One way to see the fact that the probability of being invertible is is to expose one row at a time. After k-1 rows have been exposed, and conditioning on the event that they are already linearly independent, the probability that the k^th row is going to be linearly independent of all previous rows is
is to expose one row at a time. After k-1 rows have been exposed, and conditioning on the event that they are already linearly independent, the probability that the k^th row is going to be linearly independent of all previous rows is  . Multiplying all these conditional probabilities together gives the claim.
. Multiplying all these conditional probabilities together gives the claim.
There is also a paper of Kahn and Komlos that investigates this problem for slightly different matrix models (e.g. random +1/-1 matrices over finite fields):
http://www.ams.org/mathscinet-getitem?mr=1833067
26 May, 2008 at 1:33 am
Robert
Thanks for the help!
I guess, the question I really wanted to ask is: What is the best strategy to come up with many vectors in F^k such that the the probability that a random selection of k of those is linearly independent? Again my guess would be that you cannot do better than picking (non-zero) random vectors and then the probability is what you write.