I’ve just uploaded to the arXiv my paper “Mixing for progressions in non-abelian groups“, submitted to Forum of Mathematics, Sigma (which, along with sister publication Forum of Mathematics, Pi, has just opened up its online submission system). This paper is loosely related in subject topic to my two previous papers on polynomial expansion and on recurrence in quasirandom groups (with Vitaly Bergelson), although the methods here are rather different from those in those two papers. The starting motivation for this paper was a question posed in this foundational paper of Tim Gowers on quasirandom groups. In that paper, Gowers showed (among other things) that if  was a quasirandom group, patterns such as
was a quasirandom group, patterns such as  were mixing in the sense that, for any four sets
were mixing in the sense that, for any four sets  , the number of such quadruples in
, the number of such quadruples in  was equal to
was equal to  , where
, where 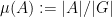 , and
, and  denotes a quantity that goes to zero as the quasirandomness of the group goes to infinity. In my recent paper with Vitaly, we also considered mixing properties of some other patterns, namely
denotes a quantity that goes to zero as the quasirandomness of the group goes to infinity. In my recent paper with Vitaly, we also considered mixing properties of some other patterns, namely  and
and 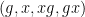 . This paper is concerned instead with the pattern
. This paper is concerned instead with the pattern  , that is to say a geometric progression of length three. As observed by Gowers, by applying (a suitably quantitative version of) Roth’s theorem in (cosets of) a cyclic group, one can obtain a recurrence theorem for this pattern without much effort: if is an arbitrary finite group, and
, that is to say a geometric progression of length three. As observed by Gowers, by applying (a suitably quantitative version of) Roth’s theorem in (cosets of) a cyclic group, one can obtain a recurrence theorem for this pattern without much effort: if is an arbitrary finite group, and  is a subset of with
is a subset of with  , then there are at least
, then there are at least  pairs
pairs  such that
such that 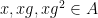 , where
, where 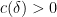 is a quantity depending only on
is a quantity depending only on  . However, this argument does not settle the question of whether there is a stronger mixing property, in that the number of pairs
. However, this argument does not settle the question of whether there is a stronger mixing property, in that the number of pairs 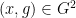 such that
such that  should be
should be  for any
for any 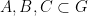 . Informally, this would assert that for
. Informally, this would assert that for  chosen uniformly at random from , the triplet
chosen uniformly at random from , the triplet  should resemble a uniformly selected element of
should resemble a uniformly selected element of  in some weak sense.
in some weak sense.
For non-quasirandom groups, such mixing properties can certainly fail. For instance, if is the cyclic group  (which is abelian and thus highly non-quasirandom) with the additive group operation, and
(which is abelian and thus highly non-quasirandom) with the additive group operation, and 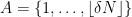 for some small but fixed
for some small but fixed 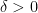 , then
, then 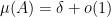 in the limit
in the limit  , but the number of pairs with
, but the number of pairs with  is
is  rather than
rather than  . The problem here is that the identity
. The problem here is that the identity 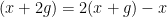 ensures that if
ensures that if  and
and  both lie in , then
both lie in , then  has a highly elevated likelihood of also falling in . One can view as the preimage of a small ball under the one-dimensional representation
has a highly elevated likelihood of also falling in . One can view as the preimage of a small ball under the one-dimensional representation  defined by
defined by 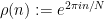 ; similar obstructions to mixing can also be constructed from other low-dimensional representations.
; similar obstructions to mixing can also be constructed from other low-dimensional representations.
However, by definition, quasirandom groups do not have low-dimensional representations, and Gowers asked whether mixing for could hold for quasirandom groups. I do not know if this is the case for arbitrary quasirandom groups, but I was able to settle the question for a specific class of quasirandom groups, namely the special linear groups  over a finite field
over a finite field  in the regime where the dimension
in the regime where the dimension  is bounded (but is at least two) and is large. Indeed, for such groups I can obtain a count of
is bounded (but is at least two) and is large. Indeed, for such groups I can obtain a count of  for the number of pairs with
for the number of pairs with  . In fact, I have the somewhat stronger statement that there are
. In fact, I have the somewhat stronger statement that there are  pairs with
pairs with  for any .
for any .
I was also able to obtain a partial result for the length four progression 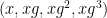 in the simpler two-dimensional case
in the simpler two-dimensional case  , but I had to make the unusual restriction that the group element
, but I had to make the unusual restriction that the group element 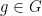 was hyperbolic in the sense that it was diagonalisable over the finite field (as opposed to diagonalisable over the algebraic closure
was hyperbolic in the sense that it was diagonalisable over the finite field (as opposed to diagonalisable over the algebraic closure 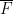 of that field); this amounts to the discriminant of the matrix being a quadratic residue, and this holds for approximately half of the elements of . The result is then that for any , one has
of that field); this amounts to the discriminant of the matrix being a quadratic residue, and this holds for approximately half of the elements of . The result is then that for any , one has 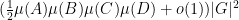 pairs with
pairs with  hyperbolic and
hyperbolic and  . (Again, I actually show a slightly stronger statement in which is restricted to an arbitrary subset
. (Again, I actually show a slightly stronger statement in which is restricted to an arbitrary subset  of hyperbolic elements.)
of hyperbolic elements.)
For the length three argument, the main tools used are the Cauchy-Schwarz inequality, the quasirandomness of , and some algebraic geometry to ensure that a certain family of probability measures on that are defined algebraically are approximately uniformly distributed. The length four argument is significantly more difficult and relies on a rather ad hoc argument involving, among other things, expander properties related to the work of Bourgain and Gamburd, and also a “twisted” version of an argument of Gowers that is used (among other things) to establish an inverse theorem for the 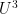 norm.
norm.
I give some details of these arguments below the fold.
— 1. Length three progressions —
One can view the mixing property of length three progressions as an assertion about the unbiased nature of sums of the form

for various bounded functions  . (To obtain the stronger statement in which is also restricted to some set
. (To obtain the stronger statement in which is also restricted to some set  , one would throw in an additional function
, one would throw in an additional function  , but let us ignore that generalisation here for sake of simplicity.) Roughly speaking, mixing means that the sum (1) should be small if at least one of the
, but let us ignore that generalisation here for sake of simplicity.) Roughly speaking, mixing means that the sum (1) should be small if at least one of the  have small mean.
have small mean.
One way in which mixing fails would be if there was an unexpected constraint between  , for instance if there was a constraint of the form
, for instance if there was a constraint of the form

for all  and some non-trivial functions
and some non-trivial functions  (not necessarily homomorphisms). Then one could make the sum (1) for
(not necessarily homomorphisms). Then one could make the sum (1) for  exhibit no cancellation whatsoever, even though one would expect to have small mean if the
exhibit no cancellation whatsoever, even though one would expect to have small mean if the  were sufficiently non-trivial. (This observation is basically what underlies the failure of mixing in the abelian case.) Thus, this suggests the toy problem of ruling out constraints of the form (2) when is a special linear group
were sufficiently non-trivial. (This observation is basically what underlies the failure of mixing in the abelian case.) Thus, this suggests the toy problem of ruling out constraints of the form (2) when is a special linear group  . This toy problem (which can be viewed as ruling out the “
. This toy problem (which can be viewed as ruling out the “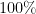 structured” version of the mixing problem, which is about excluding a more general “
structured” version of the mixing problem, which is about excluding a more general “ structured” situation) is significantly weaker than the general result, but it turns out that the proof strategy for the toy problem can be adapted to the general case (basically by replacing many of the algebraic manipulations below with a suitable analogue involving the Cauchy-Schwarz inequality).
structured” situation) is significantly weaker than the general result, but it turns out that the proof strategy for the toy problem can be adapted to the general case (basically by replacing many of the algebraic manipulations below with a suitable analogue involving the Cauchy-Schwarz inequality).
Let’s see how this works. Suppose for contradiction that we had a constraint of the form (2). In the abelian case, standard “double differencing” arguments let one conclude that  are affine homomorphisms; see e.g. Section 2 of these lecture notes. It turns out that essentially the same argument can be applied in the nonabelian case, but one acquires a nonabelian “twist” which can be exploited to give additional mixing. Shifting by , we conclude that
are affine homomorphisms; see e.g. Section 2 of these lecture notes. It turns out that essentially the same argument can be applied in the nonabelian case, but one acquires a nonabelian “twist” which can be exploited to give additional mixing. Shifting by , we conclude that

for all 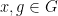 . Now we use some algebraic manipulation to eliminate
. Now we use some algebraic manipulation to eliminate 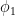 . If we replace by
. If we replace by  for some
for some 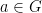 , we also have
, we also have

subtracting, we conclude that

where  is the “derivative” of
is the “derivative” of  in the
in the  direction. Setting
direction. Setting  , we conclude that
, we conclude that

for all  .
.
We can now perform a similar manipulation to eliminate 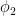 . Replacing by
. Replacing by  for some
for some 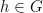 , we have
, we have

Subtracting, we conclude that

for all  . We can clean this up a bit by setting
. We can clean this up a bit by setting  and
and  , leading to
, leading to

for all  .
.
Next, we exploit the fact that the quantity  appearing on the right-hand side does not change if one replaces
appearing on the right-hand side does not change if one replaces  by
by  for any
for any  in the centraliser
in the centraliser  of
of  . If we then replace by in the above equation, we conclude that
. If we then replace by in the above equation, we conclude that

for all and  .
.
Let us now fix  , and let
, and let  denote the set
denote the set

The above identity then tells us that for  and
and  , the quantity
, the quantity  is in fact independent of . So if one can show that
is in fact independent of . So if one can show that  is “large” (e.g. has positive density in ), then this suggests that the function
is “large” (e.g. has positive density in ), then this suggests that the function  has to be basically constant (and with quasirandomness, one can make this statement precise). Further application of quasirandomness then lets one conclude that
has to be basically constant (and with quasirandomness, one can make this statement precise). Further application of quasirandomness then lets one conclude that 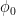 is itself constant, at which point it is not difficult to ensure that and are constant as well, rendering the entire constraint (2) trivial.
is itself constant, at which point it is not difficult to ensure that and are constant as well, rendering the entire constraint (2) trivial.
In the 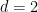 case, one can establish this by explicit (but ad hoc) computations (taking advantage of the special role of the trace in the case, for instance it is the case that two (non-central) matrices in
case, one can establish this by explicit (but ad hoc) computations (taking advantage of the special role of the trace in the case, for instance it is the case that two (non-central) matrices in 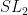 are conjugate iff they have the same trace, and there is also the nice fact that a matrix in and its inverse have the same trace). For general , this largeness of can be established by algebraic geometry methods; the key is to show that the map
are conjugate iff they have the same trace, and there is also the nice fact that a matrix in and its inverse have the same trace). For general , this largeness of can be established by algebraic geometry methods; the key is to show that the map  from
from  to is dominant in the sense that its image is Zariski-dense in . In the case of
to is dominant in the sense that its image is Zariski-dense in . In the case of 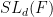 , this can be accomplished by an inspection of the derivative of this map at the identity. (I expect that similar things can be done in other almost simple algebraic groups, but did not attempt to do so in this paper.)
, this can be accomplished by an inspection of the derivative of this map at the identity. (I expect that similar things can be done in other almost simple algebraic groups, but did not attempt to do so in this paper.)
— 2. Length four progressions —
It is remarkably difficult to extend the Cauchy-Schwarz based length three arguments to length four or higher in the nonabelian setting. In the abelian case, every application of the Cauchy-Schwarz inequality reduces a certain “complexity” of the average being studied; in terms of raw length, the average may look much more fearsome after Cauchy-Schwarz, but after making some changes of variable and collecting terms, one can arrive at an average that is actually simpler in certain key respects than the original average. But it turns out that in the nonabelian setting, the process of making changes of variable and collecting terms introduces additional complexity into the average that counteracts the abelian phenomenon of complexity reduction. This was already apparent in the length three setting, when one started to see messy looking expressions such as  emerge, but the argument was short enough that one could conclude before these expressions spiraled out of control. In the case of length four progressions, the nonabelian complications seem to outrun the simplifying process, and I was not able to end up with a tractable average after a finite number of applications of the Cauchy-Schwarz inequality.
emerge, but the argument was short enough that one could conclude before these expressions spiraled out of control. In the case of length four progressions, the nonabelian complications seem to outrun the simplifying process, and I was not able to end up with a tractable average after a finite number of applications of the Cauchy-Schwarz inequality.
Instead, we leverage the abelian additive combinatorics theory by working primarily with a metabelian subgroup of 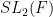 , namely the Borel subgroup
, namely the Borel subgroup  of upper-triangular elements of . Note that every hyperbolic element of can be conjugated into , which explains our restriction to the hyperbolic elements. By using the conjugates of to trace out all the hyperbolic elements of more or less evenly, matters soon reduce to establishing a “relative mixing” property for the pattern
of upper-triangular elements of . Note that every hyperbolic element of can be conjugated into , which explains our restriction to the hyperbolic elements. By using the conjugates of to trace out all the hyperbolic elements of more or less evenly, matters soon reduce to establishing a “relative mixing” property for the pattern  on . To explain this relative mixing, first observe that one does not have complete mixing for this pattern in , due to the presence of an abelian quotient
on . To explain this relative mixing, first observe that one does not have complete mixing for this pattern in , due to the presence of an abelian quotient 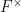 of , formed by mapping
of , formed by mapping  to
to  , and one can then pull back the failure of mixing on (e.g. by counting length four progressions inside a single fixed geometric progression) to demonstrate failure of mixing of . However, one can hope to show that this is the only obstruction to mixing, in the sense that we can get sums such as
, and one can then pull back the failure of mixing on (e.g. by counting length four progressions inside a single fixed geometric progression) to demonstrate failure of mixing of . However, one can hope to show that this is the only obstruction to mixing, in the sense that we can get sums such as

to be small if at least one of  pushes down to zero on , or equivalently if it has mean zero on every coset of the kernel of this quotient, which is the group
pushes down to zero on , or equivalently if it has mean zero on every coset of the kernel of this quotient, which is the group  of unipotent matrices in .
of unipotent matrices in .
In order to upgrade relative mixing on and its conjugates back to full mixing on , we need a certain expansion property of a given conjugacy class 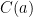 of a non-central element . This property asserts that if
of a non-central element . This property asserts that if  has mean zero, then after convolving
has mean zero, then after convolving  with the uniform probability measure on such a conjugacy class, the
with the uniform probability measure on such a conjugacy class, the  norm drops by a positive power of
norm drops by a positive power of  . This type of expansion is related to the work of Bourgain and Gamburd (in which the conjugacy class is replaced by a set of bounded cardinality, and the drop in
. This type of expansion is related to the work of Bourgain and Gamburd (in which the conjugacy class is replaced by a set of bounded cardinality, and the drop in  norm is proportionally smaller as a result), and uses some of the same tools in the proof (in particular the “escape from subvarieties” phenomenon of Eskin, Mozes, and Oh)). (On the other hand, the \href{combinatorial product theory of Helfgott}, which plays a central role in the work of Bourgain and Gamburd, is not needed here, because in this setting one only needs to understand products of algebraic sets, such as conjugacy classes, rather than arbitrary subsets.)
norm is proportionally smaller as a result), and uses some of the same tools in the proof (in particular the “escape from subvarieties” phenomenon of Eskin, Mozes, and Oh)). (On the other hand, the \href{combinatorial product theory of Helfgott}, which plays a central role in the work of Bourgain and Gamburd, is not needed here, because in this setting one only needs to understand products of algebraic sets, such as conjugacy classes, rather than arbitrary subsets.)
By foliating into cosets of (which is isomorphic to ), one can after some straightforward calculations rewrite the sum into a sum which is basically of the form

for some family  of bounded functions for
of bounded functions for  and
and  . The inner sum resembles a count of four term progressions, a statistic which has been studied by higher order Fourier-analytic methods since the work of Gowers on Szemerédi’s theorem for length four progressions. In principle one could analyse these expressions using the inverse theorem of Ben Green and myself, but this would require a large amount of manipulation of two-step nilsequences, which would lead to a number of technical complications. Instead, we take a “softer” approach, in which we set up some of the quadratic Fourier analysis of Gowers that goes into the proof of the inverse theorem, but stop well before the nilsequences come in. More precisely, we use a variant of the basic fact in quadratic Fourier analysis (already present in the previously mentioned paper of Gowers) that if a function has large norm, then for many shifts , the derivative
. The inner sum resembles a count of four term progressions, a statistic which has been studied by higher order Fourier-analytic methods since the work of Gowers on Szemerédi’s theorem for length four progressions. In principle one could analyse these expressions using the inverse theorem of Ben Green and myself, but this would require a large amount of manipulation of two-step nilsequences, which would lead to a number of technical complications. Instead, we take a “softer” approach, in which we set up some of the quadratic Fourier analysis of Gowers that goes into the proof of the inverse theorem, but stop well before the nilsequences come in. More precisely, we use a variant of the basic fact in quadratic Fourier analysis (already present in the previously mentioned paper of Gowers) that if a function has large norm, then for many shifts , the derivative 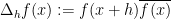 correlates with a linear phase
correlates with a linear phase  , and furthermore that this phase
, and furthermore that this phase  is approximately linear in the sense that there are many quadruples
is approximately linear in the sense that there are many quadruples 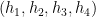 with
with  and
and  . Applying this analysis to the above sum, we see that if that sum is large, then one obtains a number of approximate linearity relationships between the frequencies for which
. Applying this analysis to the above sum, we see that if that sum is large, then one obtains a number of approximate linearity relationships between the frequencies for which  correlates with
correlates with  . On the other hand, for each fixed
. On the other hand, for each fixed  , Plancherel’s theorem tells us that there can only be a bounded number of frequencies for which the correlation between and is large. Varying
, Plancherel’s theorem tells us that there can only be a bounded number of frequencies for which the correlation between and is large. Varying  suitably, this eventually creates so many linear constraints between these frequencies (with coefficients that vary in a sufficiently nonlinear fashion to ensure a high rank) that a contradiction can be derived, unless all the frequencies involved vanish. But this case can be handled by a variant of the above arguments, though in this case one needs to vary inside a moderately large two-dimensional arithmetic progression before one can finally reduce to a contradiction, which requires invoking the multidimensional Szemereédi theorem in order to ensure that all the pairs
suitably, this eventually creates so many linear constraints between these frequencies (with coefficients that vary in a sufficiently nonlinear fashion to ensure a high rank) that a contradiction can be derived, unless all the frequencies involved vanish. But this case can be handled by a variant of the above arguments, though in this case one needs to vary inside a moderately large two-dimensional arithmetic progression before one can finally reduce to a contradiction, which requires invoking the multidimensional Szemereédi theorem in order to ensure that all the pairs 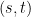 used are “good” in a certain technical sense. It is this last step which makes the error terms in the length four progression results to be qualitative (of order ) rather than quantitative (of order
used are “good” in a certain technical sense. It is this last step which makes the error terms in the length four progression results to be qualitative (of order ) rather than quantitative (of order  ). I feel that there should be a better approach than the rather ad hoc approach employed here which should lead to better bounds (and which would more easily extend to other groups than ).
). I feel that there should be a better approach than the rather ad hoc approach employed here which should lead to better bounds (and which would more easily extend to other groups than ).


2 comments
Comments feed for this article
13 December, 2012 at 6:34 am
jeff ezearn
Is it the situation that in the case of the four term progression for which a group element g is non-hyperbolic, that there might probably be a constraint such as (2) above for all x?
13 December, 2012 at 8:01 am
Terence Tao
That’s a great question, and resolving it in a sufficiently “robust” fashion would likely lead to the removal of the hyperbolicity restriction in my length four progression results. I did try my hand at this for a while, but could not algebraically simplify the four-term version of (2) by the techniques of changing variable and cancelling (which, roughly speaking, is to the 100% world as Cauchy-Schwarz type methods are to the 1% world). But perhaps another approach is possible (though if the approach is too “global” in nature, it may be restricted to the 100% or 99% worlds, and not to the 1% world which is the world in which the actual problem is set).