
The purpose of this post is to report an erratum to the 2012 paper “An inverse theorem for the Gowers ![{U^{s+1}[N]}](https://s0.wp.com/latex.php?latex=%7BU%5E%7Bs%2B1%7D%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Excluding some minor (mostly typographical) issues which we also have reported in this erratum, the main issues stemmed from a conflation of two notions of a degree 
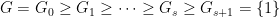
 , which is a nested sequence of subgroups that obey the relation
, which is a nested sequence of subgroups that obey the relation ![{[G_i,G_j] \leq G_{i+j}}](https://s0.wp.com/latex.php?latex=%7B%5BG_i%2CG_j%5D+%5Cleq+G_%7Bi%2Bj%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for all
for all  . The weaker notion (sometimes known as a prefiltration) permits the group
. The weaker notion (sometimes known as a prefiltration) permits the group  to be strictly smaller than
to be strictly smaller than  , while the stronger notion requires and to equal. In practice, one can often move between the two concepts, as is always normal in , and a prefiltration behaves like a filtration on every coset of (after applying a translation and perhaps also a conjugation). However, we did not clarify this issue sufficiently in the paper, and there are some places in the text where results that were only proven for filtrations were applied for prefiltrations. The erratum fixes this issues, mostly by clarifying that we work with filtrations throughout (which requires some decomposition into cosets in places where prefiltrations are generated). Similar adjustments need to be made for multidegree filtrations and degree-rank filtrations, which we also use heavily on our paper.
, while the stronger notion requires and to equal. In practice, one can often move between the two concepts, as is always normal in , and a prefiltration behaves like a filtration on every coset of (after applying a translation and perhaps also a conjugation). However, we did not clarify this issue sufficiently in the paper, and there are some places in the text where results that were only proven for filtrations were applied for prefiltrations. The erratum fixes this issues, mostly by clarifying that we work with filtrations throughout (which requires some decomposition into cosets in places where prefiltrations are generated). Similar adjustments need to be made for multidegree filtrations and degree-rank filtrations, which we also use heavily on our paper.
In most cases, fixing this issue only required minor changes to the text, but there is one place (Section 8) where there was a non-trivial problem: we used the claim that the final group 

Again, we stress that these issues do not impact the paper of Leng, Sah, and Sawhney, as they adapted the methods in our paper in a fashion that avoids these errors.

13 comments
Comments feed for this article
25 April, 2024 at 7:46 am
Anonymous
Possible to check this in Lean?
25 April, 2024 at 3:13 pm
Terence Tao
In principle I believe all of the theory required to prove the inverse theory for the Gowers norms is formalizable, but it would require significant amounts of time and effort at our current level of proof formalization technology; even the equidistribution theory of nilsequences, which is a relatively small component of the theory, would require quite a bit of setup. (However, the U^3 theory is significantly simpler, particularly over finite fields and may potentially be within reach of current additive combinatorics formalization projects.)
Given that there are now multiple proofs of this theorem, I think that having the result formalized is not an urgent priority for the field; also, I can imagine that simpler proofs could emerge in the future, and that formalizing one of the current proofs with current tools may not be the most efficient strategy. Sometimes it makes sense simply to wait…
30 April, 2024 at 8:43 am
Anonymous
If it requires significant effort and the underlying theory is not coded in Lean already makes it an interesting challenge of Lean’s expressiveness. That the error was uncorrected for around 10+ years makes it a canonical example for the practical application of mechanical proof checking to the working mathematician’s toolkit: crowdsourced acceptance of a proof is evidently unreliable. Would it merit a BS, MS or PHD for a student in search of a topic to say demonstrate both that the erroneous proof doesnt check, and that the simplest recent proof does check, putting the work in to code the theory of equidistribution theory of nilsequences and so on? Framing it as a suitable thesis topic should motivate someone to take it on.
10 May, 2024 at 8:27 pm
Terence Tao
Pure formalization projects are not ideal for thesis projects, as they may not provide sufficient broader mathematical training, and may also not allow the student to achieve sufficient recognition in an active mathematical field that would advance their career prospects. (In the future, it is conceivable that mathematical formalization itself becomes a mainstream academic profession, but we aren’t quite at that point yet.) Also, such a single-author approach negates one of the most compelling advantages of a formalization project, which is that it can be parallelized and crowdsourced to a far greater extent than most other mathematical projects.
There are beginning to be examples of formalization “hackathons” during summer schools or workshops in which students work together to formalize various small components of a larger task in a specialized field, allowing them to practice both the mathematics of that field and the language of the proof assistant. This to me is a more promising model; if for instance a workshop in additive combinatorics was interested, then the formalization of various components of the theory of inverse theorems and nilsequences could indeed be feasible. (I think there may be a group at Bonn that may already be working somewhat in this direction, though.)
11 May, 2024 at 6:38 am
Anonymous
There is a town/gown gap between what is considered valuable and meaty in pure math and what is actually pretty hard and ought to be considered valuable and meaty in applied computational symbolic logic and the formal representation of mathematical ideas. This is reflected in considerable and constant frustration that I see on the Lean chat website in the matter of funding for work on proof checking. A lot of effort and attention has lately gone into whether LLMs can make it easier to automate what is apparently a boring task. For some people it is interesting and exciting to find ways to encode these theories. The Lean chat website is buzzing 24/7 and you can get almost instant help for very obscure technical questions. I’ve never seen anything like it. The real problem seems to be the prevailing value system that gives low marks and recognition to the encoding task. Would it help if we called it “computer science” or something like that? But wouldn’t that also create a status and communication gap between people who like to do the encoding and people who are apt to create the (occasionally flawed) content to be encoded?
11 May, 2024 at 6:38 pm
Anonymous
how accurate is this professor?
Mapping the twin primes using group theory concepts can be approached by analyzing their properties in terms of the multiplicative group of integers modulo 6, denoted by U(6), which consists of the elements {1, 5, 7, 11}, where the operation is multiplication modulo 6.
The twin primes (p, p+2) can be mapped to this group by considering the residue classes of p and p+2 modulo 6. This allows us to study the distribution of twin primes and their properties in terms of the structure and properties of U(6).
For example, a prime number p is congruent to 1 modulo 6 if and only if p = 1 + 6k for some integer k. In group-theoretic terms, this means that p is congruent to the identity element of U(6).
Similarly, a prime number p is congruent to 5 modulo 6 if and only if p = 5 + 6k for some integer k. In group-theoretic terms, this means that p is congruent to the element 5 of U(6).
By mapping primes and prime powers to the elements of U(6) in this way, we can understand their behavior and distribution modulo 6 using group theory concepts. This approach can be generalized to other moduli and can provide insights into the structure of the set of primes and prime powers.
11 May, 2024 at 8:19 am
Anonymous
In fact, according to this article, 3 out of 4 AI models agree that the town/gown gap is a serious issue: https://www.linkedin.com/pulse/towngown-gap-between-pure-mathematics-automated-proof-ericson-nx7oe/
11 May, 2024 at 5:53 pm
Anonymous
Hey Terry, are you going to say anything about the 15k+ dead Palestinian children or is your sympathy only reserved for Israeli captives (half of whom were soldiers)? I noticed you signed a petition about the Israeli captives, but have said nothing about the thousands of dead Palestinian children.
16 May, 2024 at 1:28 am
Anonymous
What petition and why does it matter? Not like there is anything we can do to change the situation…
16 May, 2024 at 1:33 am
Anonymous
Not to dismiss the suffering of the Palestinian people, but yeah, nothing we can do
13 May, 2024 at 1:24 am
Anonymous
$sqrt{2}$
14 May, 2024 at 11:58 am
Anonymous
not sure if it’s the same, and it’s j”ust algebra,” but with 7¹¹x-99, it gives a nice little inverse. Every 10 returns for the inverse and the function return that’s 01&99 pattern.
x = -30, f(1/x) = -124002900000000099
x = -29, f(1/x) = -85403568359940902
x = -28, f(1/x) = -58054566272303203
x = -27, f(1/x) = -38913423965888760
x = -26, f(1/x) = -25692411408914531
x = -25, f(1/x) = -16689300537109474
x = -24, f(1/x) = -10651768002183267
x = -23, f(1/x) = -6669668305397588
x = -22, f(1/x) = -4090228109879395
x = -21, f(1/x) = -2451942503795646
x = -20, f(1/x) = -1433600000000099
x = -19, f(1/x) = -815431812287632
x = -18, f(1/x) = -449878870554723
x = -17, f(1/x) = -239903274153530
x = -16, f(1/x) = -123145302311011
x = -15, f(1/x) = -60548291015724
x = -14, f(1/x) = -28346956187747
x = -13, f(1/x) = -12545122758358
x = -12, f(1/x) = -5201058594915
x = -11, f(1/x) = -1997181694376
x = -10, f(1/x) = -700000000099
x = -9, f(1/x) = -219667417362
x = -8, f(1/x) = -60129542243
x = -7, f(1/x) = -13841287300
x = -6, f(1/x) = -2539579491
x = -5, f(1/x) = -341796974
x = -4, f(1/x) = -29360227
x = -3, f(1/x) = -1240128
x = -2, f(1/x) = -14435
x = -1, f(1/x) = -106
x = 0, f(1/x) = -99
x = 1, f(1/x) = -92
x = 2, f(1/x) = 14237
x = 3, f(1/x) = 1239930
x = 4, f(1/x) = 29360029
x = 5, f(1/x) = 341796776
x = 6, f(1/x) = 2539579293
x = 7, f(1/x) = 13841287102
x = 8, f(1/x) = 60129542045
x = 9, f(1/x) = 219667417164
x = 10, f(1/x) = 699999999901
x = 11, f(1/x) = 1997181694178
x = 12, f(1/x) = 5201058594717
x = 13, f(1/x) = 12545122758160
x = 14, f(1/x) = 28346956187549
x = 15, f(1/x) = 60548291015526
x = 16, f(1/x) = 123145302310813
x = 17, f(1/x) = 239903274153332
x = 18, f(1/x) = 449878870554525
x = 19, f(1/x) = 815431812287434
x = 20, f(1/x) = 1433599999999901
x = 21, f(1/x) = 2451942503795448
x = 22, f(1/x) = 4090228109879197
x = 23, f(1/x) = 6669668305397390
x = 24, f(1/x) = 10651768002183069
x = 25, f(1/x) = 16689300537109276
x = 26, f(1/x) = 25692411408914333
x = 27, f(1/x) = 38913423965888562
x = 28, f(1/x) = 58054566272303005
x = 29, f(1/x) = 85403568359940704
x = 30, f(1/x) = 124002899999999901
x = 31, f(1/x) = 177859338274833718
x = 32, f(1/x) = 252201579132747677
x = 33, f(1/x) = 353794745596087620
x = 34, f(1/x) = 491321905466226589
x = 35, f(1/x) = 675844101611328026
x = 36, f(1/x) = 921351926895869853
x = 37, f(1/x) = 1245423352456222792
x = 38, f(1/x) = 1670004351564867485
x = 39, f(1/x) = 2222330861257306974
x = 40, f(1/x) = 2936012799999999901
14 May, 2024 at 12:28 pm
Anonymous
yabba dabba do