I’ve just uploaded to the arXiv my paper “Expanding polynomials over finite fields of large characteristic, and a regularity lemma for definable sets“, submitted to Contrib. Disc. Math. The motivation of this paper is to understand a certain polynomial variant of the sum-product phenomenon in finite fields. This phenomenon asserts that if  is a non-empty subset of a finite field
is a non-empty subset of a finite field  , then either the sumset
, then either the sumset 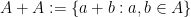 or product set
or product set  will be significantly larger than , unless is close to a subfield of (or to
will be significantly larger than , unless is close to a subfield of (or to  ). In particular, in the regime when is large, say
). In particular, in the regime when is large, say  , one expects an expansion bound of the form
, one expects an expansion bound of the form

for some absolute constants 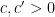 . Results of this type are known; for instance, Hart, Iosevich, and Solymosi obtained precisely this bound for
. Results of this type are known; for instance, Hart, Iosevich, and Solymosi obtained precisely this bound for 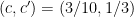 (in the case when
(in the case when  is prime), which was then improved by Garaev to
is prime), which was then improved by Garaev to  .
.
We have focused here on the case when is a large subset of , but sum-product estimates are also extremely interesting in the opposite regime in which is allowed to be small (see for instance the papers of Katz–Shen and Li and of Garaev for some recent work in this case, building on some older papers of Bourgain, Katz and myself and of Bourgain, Glibichuk, and Konyagin). However, the techniques used in these two regimes are rather different. For large subsets of , it is often profitable to use techniques such as the Fourier transform or the Cauchy-Schwarz inequality to “complete” a sum over a large set (such as ) into a set over the entire field , and then to use identities concerning complete sums (such as the Weil bound on complete exponential sums over a finite field). For small subsets of , such techniques are usually quite inefficient, and one has to proceed by somewhat different combinatorial methods which do not try to exploit the ambient field . But my paper focuses exclusively on the large regime, and unfortunately does not directly say much (except through reasoning by analogy) about the small case.
Note that it is necessary to have both 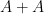 and
and 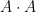 appear on the left-hand side of (1). Indeed, if one just has the sumset , then one can set to be a long arithmetic progression to give counterexamples to (1). Similarly, if one just has a product set , then one can set to be a long geometric progression. The sum-product phenomenon can then be viewed that it is not possible to simultaneously behave like a long arithmetic progression and a long geometric progression, unless one is already very close to behaving like a subfield.
appear on the left-hand side of (1). Indeed, if one just has the sumset , then one can set to be a long arithmetic progression to give counterexamples to (1). Similarly, if one just has a product set , then one can set to be a long geometric progression. The sum-product phenomenon can then be viewed that it is not possible to simultaneously behave like a long arithmetic progression and a long geometric progression, unless one is already very close to behaving like a subfield.
Now we consider a polynomial variant of the sum-product phenomenon, where we consider a polynomial image
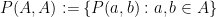
of a set 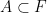 with respect to a polynomial
with respect to a polynomial 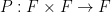 ; we can also consider the asymmetric setting of the image
; we can also consider the asymmetric setting of the image

of two subsets 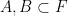 . The regime we will be interested is the one where the field is large, and the subsets
. The regime we will be interested is the one where the field is large, and the subsets  of are also large, but the polynomial
of are also large, but the polynomial  has bounded degree. Actually, for technical reasons it will not be enough for us to assume that has large cardinality; we will also need to assume that has large characteristic. (The two concepts are synonymous for fields of prime order, but not in general; for instance, the field with
has bounded degree. Actually, for technical reasons it will not be enough for us to assume that has large cardinality; we will also need to assume that has large characteristic. (The two concepts are synonymous for fields of prime order, but not in general; for instance, the field with  elements becomes large as
elements becomes large as  while the characteristic remains fixed at
while the characteristic remains fixed at  , and is thus not going to be covered by the results in this paper.)
, and is thus not going to be covered by the results in this paper.)
In this paper of Vu, it was shown that one could replace with 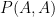 in (1), thus obtaining a bound of the form
in (1), thus obtaining a bound of the form
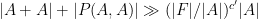
whenever  for some absolute constants , unless the polynomial had the degenerate form
for some absolute constants , unless the polynomial had the degenerate form 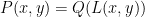 for some linear function
for some linear function 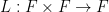 and polynomial
and polynomial 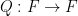 , in which behaves too much like to get reasonable expansion. In this paper, we focus instead on the question of bounding alone. In particular, one can ask to classify the polynomials for which one has the weak expansion property
, in which behaves too much like to get reasonable expansion. In this paper, we focus instead on the question of bounding alone. In particular, one can ask to classify the polynomials for which one has the weak expansion property
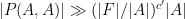
whenever for some absolute constants . One can also ask for stronger versions of this expander property, such as the moderate expansion property
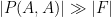
whenever , or the almost strong expansion property

whenever . (One can consider even stronger expansion properties, such as the strong expansion property 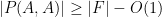 , but it was shown by Gyarmati and Sarkozy that this property cannot hold for polynomials of two variables of bounded degree when
, but it was shown by Gyarmati and Sarkozy that this property cannot hold for polynomials of two variables of bounded degree when 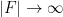 .) One can also consider asymmetric versions of these properties, in which one obtains lower bounds on
.) One can also consider asymmetric versions of these properties, in which one obtains lower bounds on 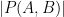 rather than
rather than 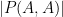 .
.
The example of a long arithmetic or geometric progression shows that the polynomials  or
or  cannot be expanders in any of the above senses, and a similar construction also shows that polynomials of the form
cannot be expanders in any of the above senses, and a similar construction also shows that polynomials of the form 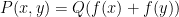 or
or  for some polynomials
for some polynomials  cannot be expanders. On the other hand, there are a number of results in the literature establishing expansion for various polynomials in two or more variables that are not of this degenerate form (in part because such results are related to incidence geometry questions in finite fields, such as the finite field version of the Erdos distinct distances problem). For instance, Solymosi established weak expansion for polynomials of the form
cannot be expanders. On the other hand, there are a number of results in the literature establishing expansion for various polynomials in two or more variables that are not of this degenerate form (in part because such results are related to incidence geometry questions in finite fields, such as the finite field version of the Erdos distinct distances problem). For instance, Solymosi established weak expansion for polynomials of the form 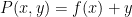 when
when  is a nonlinear polynomial, with generalisations by Hart, Li, and Shen for various polynomials of the form
is a nonlinear polynomial, with generalisations by Hart, Li, and Shen for various polynomials of the form 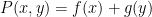 or
or 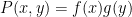 . Further examples of expanding polynomials appear in the work of Shkredov, Iosevich-Rudnev, and Bukh-Tsimerman, as well as the previously mentioned paper of Vu and of Hart-Li-Shen, and these papers in turn cite many further results which are in the spirit of the polynomial expansion bounds discussed here (for instance, dealing with the small regime, or working in other fields such as
. Further examples of expanding polynomials appear in the work of Shkredov, Iosevich-Rudnev, and Bukh-Tsimerman, as well as the previously mentioned paper of Vu and of Hart-Li-Shen, and these papers in turn cite many further results which are in the spirit of the polynomial expansion bounds discussed here (for instance, dealing with the small regime, or working in other fields such as  instead of in finite fields ). We will not summarise all these results here; they are summarised briefly in my paper, and in more detail in the papers of Hart-Li-Shen and of Bukh-Tsimerman. But we will single out one of the results of Bukh-Tsimerman, which is one of most recent and general of these results, and closest to the results of my own paper. Roughly speaking, in this paper it is shown that a polynomial
instead of in finite fields ). We will not summarise all these results here; they are summarised briefly in my paper, and in more detail in the papers of Hart-Li-Shen and of Bukh-Tsimerman. But we will single out one of the results of Bukh-Tsimerman, which is one of most recent and general of these results, and closest to the results of my own paper. Roughly speaking, in this paper it is shown that a polynomial 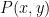 of two variables and bounded degree will be a moderate expander if it is non-composite (in the sense that it does not take the form
of two variables and bounded degree will be a moderate expander if it is non-composite (in the sense that it does not take the form 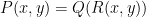 for some non-linear polynomial
for some non-linear polynomial  and some polynomial
and some polynomial  , possibly having coefficients in the algebraic completion of ) and is monic on both
, possibly having coefficients in the algebraic completion of ) and is monic on both  and
and  , thus it takes the form
, thus it takes the form  for some
for some 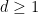 and some polynomial
and some polynomial  of degree at most
of degree at most  in , and similarly with the roles of and reversed, unless is of the form or (in which case the expansion theory is covered to a large extent by the previous work of Hart, Li, and Shen).
in , and similarly with the roles of and reversed, unless is of the form or (in which case the expansion theory is covered to a large extent by the previous work of Hart, Li, and Shen).
Our first main result improves upon the Bukh-Tsimerman result by strengthening the notion of expansion and removing the non-composite and monic hypotheses, but imposes a condition of large characteristic. I’ll state the result here slightly informally as follows:
Theorem 1 (Criterion for moderate expansion) Let be a polynomial of bounded degree over a finite field of sufficiently large characteristic, and suppose that is not of the form 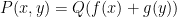 or
or 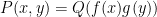 for some polynomials
for some polynomials  . Then one has the (asymmetric) moderate expansion property
. Then one has the (asymmetric) moderate expansion property

whenever 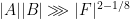 .
.
This is basically a sharp necessary and sufficient condition for asymmetric expansion moderate for polynomials of two variables. In the paper, analogous sufficient conditions for weak or almost strong expansion are also given, although these are not quite as satisfactory (particularly the conditions for almost strong expansion, which include a somewhat complicated algebraic condition which is not easy to check, and which I would like to simplify further, but was unable to).
The argument here resembles the Bukh-Tsimerman argument in many ways. One can view the result as an assertion about the expansion properties of the graph 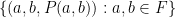 , which can essentially be thought of as a somewhat sparse three-uniform hypergraph on . Being sparse, it is difficult to directly apply techniques from dense graph or hypergraph theory for this situation; however, after a few applications of the Cauchy-Schwarz inequality, it turns out (as observed by Bukh and Tsimerman) that one can essentially convert the problem to one about the expansion properties of the set
, which can essentially be thought of as a somewhat sparse three-uniform hypergraph on . Being sparse, it is difficult to directly apply techniques from dense graph or hypergraph theory for this situation; however, after a few applications of the Cauchy-Schwarz inequality, it turns out (as observed by Bukh and Tsimerman) that one can essentially convert the problem to one about the expansion properties of the set

(actually, one should view this as a multiset, but let us ignore this technicality) which one expects to be a dense set in  , except in the case when the associated algebraic variety
, except in the case when the associated algebraic variety

fails to be Zariski dense, but it turns out that in this case one can use some differential geometry and Riemann surface arguments (after first invoking the Lefschetz principle and the high characteristic hypothesis to work over the complex numbers instead over a finite field) to show that is of the form  or
or  . This reduction is related to the classical fact that the only one-dimensional algebraic groups over the complex numbers are the additive group
. This reduction is related to the classical fact that the only one-dimensional algebraic groups over the complex numbers are the additive group 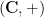 , the multiplicative group
, the multiplicative group 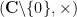 , or the elliptic curves (but the latter have a group law given by rational functions rather than polynomials, and so ultimately end up being eliminated from consideration, though they would play an important role if one wanted to study the expansion properties of rational functions).
, or the elliptic curves (but the latter have a group law given by rational functions rather than polynomials, and so ultimately end up being eliminated from consideration, though they would play an important role if one wanted to study the expansion properties of rational functions).
It remains to understand the structure of the set (2) is. To understand dense graphs or hypergraphs, one of the standard tools of choice is the Szemerédi regularity lemma, which carves up such graphs into a bounded number of cells, with the graph behaving pseudorandomly on most pairs of cells. However, the bounds in this lemma are notoriously poor (the regularity obtained is an inverse tower exponential function of the number of cells), and this makes this lemma unsuitable for the type of expansion properties we seek (in which we want to deal with sets which have a polynomial sparsity, e.g.  ). Fortunately, in the case of sets such as (2) which are definable over the language of rings, it turns out that a much stronger regularity lemma is available, which I call the “algebraic regularity lemma”. I’ll state it (again, slightly informally) in the context of graphs as follows:
). Fortunately, in the case of sets such as (2) which are definable over the language of rings, it turns out that a much stronger regularity lemma is available, which I call the “algebraic regularity lemma”. I’ll state it (again, slightly informally) in the context of graphs as follows:
Lemma 2 (Algebraic regularity lemma) Let be a finite field of large characteristic, and let 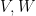 be definable sets over of bounded complexity (i.e. are subsets of
be definable sets over of bounded complexity (i.e. are subsets of 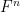 ,
,  for some bounded
for some bounded 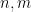 that can be described by some first-order predicate in the language of rings of bounded length and involving boundedly many constants). Let
that can be described by some first-order predicate in the language of rings of bounded length and involving boundedly many constants). Let  be a definable subset of
be a definable subset of  , again of bounded complexity (one can view as a bipartite graph connecting
, again of bounded complexity (one can view as a bipartite graph connecting  and
and  ). Then one can partition into a bounded number of cells
). Then one can partition into a bounded number of cells  ,
,  , still definable with bounded complexity, such that for all pairs
, still definable with bounded complexity, such that for all pairs  ,
,  , one has the regularity property
, one has the regularity property

for all  , where
, where  is the density of in
is the density of in 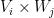 .
.
This lemma resembles the Szemerédi regularity lemma, but regularises all pairs of cells (not just most pairs), and the regularity is of polynomial strength in , rather than inverse tower exponential in the number of cells. Also, the cells are not arbitrary subsets of  , but are themselves definable with bounded complexity, which turns out to be crucial for applications. I am optimistic that this lemma will be useful not just for studying expanding polynomials, but for many other combinatorial questions involving dense subsets of definable sets over finite fields.
, but are themselves definable with bounded complexity, which turns out to be crucial for applications. I am optimistic that this lemma will be useful not just for studying expanding polynomials, but for many other combinatorial questions involving dense subsets of definable sets over finite fields.
The above lemma is stated for graphs 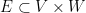 , but one can iterate it to obtain an analogous regularisation of hypergraphs
, but one can iterate it to obtain an analogous regularisation of hypergraphs 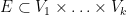 for any bounded
for any bounded  (for application to (2), we need
(for application to (2), we need  ). This hypergraph regularity lemma, by the way, is not analogous to the strong hypergraph regularity lemmas of Rodl et al. and Gowers developed in the last six or so years, but closer in spirit to the older (but weaker) hypergraph regularity lemma of Chung which gives the same “order
). This hypergraph regularity lemma, by the way, is not analogous to the strong hypergraph regularity lemmas of Rodl et al. and Gowers developed in the last six or so years, but closer in spirit to the older (but weaker) hypergraph regularity lemma of Chung which gives the same “order  ” regularity that the graph regularity lemma gives, rather than higher order regularity.
” regularity that the graph regularity lemma gives, rather than higher order regularity.
One feature of the proof of Lemma 2 which I found striking was the need to use some fairly high powered technology from algebraic geometry, and in particular the Lang-Weil bound on counting points in varieties over a finite field (discussed in this previous blog post), and also the theory of the etale fundamental group. Let me try to briefly explain why this is the case. A model example of a definable set of bounded complexity is a set 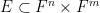 of the form
of the form

for some polynomial  . (Actually, it turns out that one can essentially write all definable sets as an intersection of sets of this form; see this previous blog post for more discussion.) To regularise the set , it is convenient to square the adjacency matrix, which soon leads to the study of counting functions such as
. (Actually, it turns out that one can essentially write all definable sets as an intersection of sets of this form; see this previous blog post for more discussion.) To regularise the set , it is convenient to square the adjacency matrix, which soon leads to the study of counting functions such as

If one can show that this function  is “approximately finite rank” in the sense that (modulo lower order errors, of size
is “approximately finite rank” in the sense that (modulo lower order errors, of size  smaller than the main term), this quantity depends only on a bounded number of bits of information about and a bounded number of bits of information about
smaller than the main term), this quantity depends only on a bounded number of bits of information about and a bounded number of bits of information about  , then a little bit of linear algebra will then give the required regularity result.
, then a little bit of linear algebra will then give the required regularity result.
One can recognise  as counting -points of a certain algebraic variety
as counting -points of a certain algebraic variety
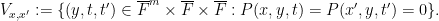
The Lang-Weil bound (discussed in this previous post) provides a formula for this count, in terms of the number 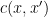 of geometrically irreducible components of
of geometrically irreducible components of 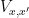 that are defined over (or equivalently, are invariant with respect to the Frobenius endomorphism associated to ). So the problem boils down to ensuring that this quantity is “generically bounded rank”, in the sense that for generic
that are defined over (or equivalently, are invariant with respect to the Frobenius endomorphism associated to ). So the problem boils down to ensuring that this quantity is “generically bounded rank”, in the sense that for generic 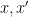 , its value depends only on a bounded number of bits of and a bounded number of bits of .
, its value depends only on a bounded number of bits of and a bounded number of bits of .
Here is where the étale fundamental group comes in. One can view as a fibre product 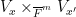 of the varieties
of the varieties
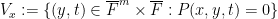
and
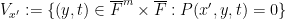
over  . If one is in sufficiently high characteristic (or even better, in zero characteristic, which one can reduce to by an ultraproduct (or nonstandard analysis) construction, similar to that discussed in this previous post), the varieties
. If one is in sufficiently high characteristic (or even better, in zero characteristic, which one can reduce to by an ultraproduct (or nonstandard analysis) construction, similar to that discussed in this previous post), the varieties 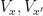 are generically finite étale covers of , and the fibre product is then also generically a finite étale cover. One can count the components of a finite étale cover of a connected variety by counting the number of orbits of the étale fundamental group acting on a fibre of that variety (much as the number of components of a cover of a connected manifold is the number of orbits of the topological fundamental group acting on that fibre). So if one understands the étale fundamental group of a certain generic subset of (formed by intersecting together an -dependent generic subset of with an -dependent generic subset), this in principle controls . It turns out that one can decouple the and dependence of this fundamental group by using an étale version of the van Kampen theorem for the fundamental group, which I discussed in this previous blog post. With this fact (and another deep fact about the étale fundamental group in zero characteristic, namely that it is topologically finitely generated), one can obtain the desired generic bounded rank property of , which gives the regularity lemma.
are generically finite étale covers of , and the fibre product is then also generically a finite étale cover. One can count the components of a finite étale cover of a connected variety by counting the number of orbits of the étale fundamental group acting on a fibre of that variety (much as the number of components of a cover of a connected manifold is the number of orbits of the topological fundamental group acting on that fibre). So if one understands the étale fundamental group of a certain generic subset of (formed by intersecting together an -dependent generic subset of with an -dependent generic subset), this in principle controls . It turns out that one can decouple the and dependence of this fundamental group by using an étale version of the van Kampen theorem for the fundamental group, which I discussed in this previous blog post. With this fact (and another deep fact about the étale fundamental group in zero characteristic, namely that it is topologically finitely generated), one can obtain the desired generic bounded rank property of , which gives the regularity lemma.
In order to expedite the deployment of all this algebraic geometry (as well as some Riemann surface theory), it is convenient to use the formalism of nonstandard analysis (or the ultraproduct construction), which among other things can convert quantitative, finitary problems in large characteristic into equivalent qualitative, infinitary problems in zero characteristic (in the spirit of this blog post). This allows one to use several tools from those fields as “black boxes”; not just the theory of étale fundamental groups (which are considerably simpler and more favorable in characteristic zero than they are in positive characteristic), but also some results limiting the morphisms between compact Riemann surfaces of high genus (such as the de Franchis theorem, the Riemann-Hurwitz formula, or the fact that all morphisms between elliptic curves are essentially group homomorphisms), which would be quite unwieldy to utilise if one did not first pass to the zero characteristic case (and thence to the complex case) via the ultraproduct construction (followed by the Lefschetz principle).
I found this project to be particularly educational for me, as it forced me to wander outside of my usual range by quite a bit in order to pick up the tools from algebraic geometry and Riemann surfaces that I needed (in particular, I read through several chapters of EGA and SGA for the first time). This did however put me in the slightly unnerving position of having to use results (such as the Riemann existence theorem) whose proofs I have not fully verified for myself, but which are easy to find in the literature, and widely accepted in the field. I suppose this type of dependence on results in the literature is more common in the more structured fields of mathematics than it is in analysis, which by its nature has fewer reusable black boxes, and so key tools often need to be rederived and modified for each new application. (This distinction is discussed further in this article of Gowers.)






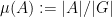


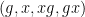




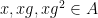
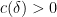

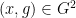


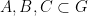




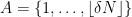
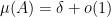




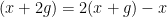



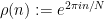






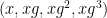

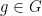
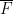
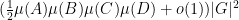


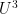

Recent Comments