
You are currently browsing the tag archive for the ‘matrices’ tag.
While talking mathematics with a postdoc here at UCLA (March Boedihardjo) we came across the following matrix problem which we managed to solve, but the proof was cute and the process of discovering it was fun, so I thought I would present the problem here as a puzzle without revealing the solution for now.
The problem involves word maps on a matrix group, which for sake of discussion we will take to be the special orthogonal group 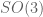



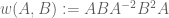
for 
Anyway, here is the problem:
Problem. Does there exist a sequence
of non-trivial word maps
that converge uniformly to the identity map?
To put it another way, given any 
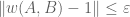


As I said, I don’t want to spoil the fun of working out this problem, so I will leave it as a challenge. Readers are welcome to share their thoughts, partial solutions, or full solutions in the comments below.
The determinant 

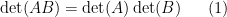
whenever 

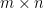





This identity, which converts an 
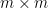


Another identity generated from (1) arises when trying to compute the determinant of a 
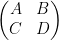
where 

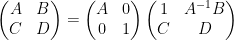

and on taking determinants using (1) we obtain the Schur determinant identity
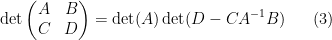
relating the determinant of a block-diagonal matrix with the determinant of the Schur complement 

It is also possible to use determinant identities to deduce other matrix identities that do not involve the determinant, by the technique of matrix differentiation (or equivalently, matrix linearisation). The key observation is that near the identity, the determinant behaves like the trace, or more precisely one has
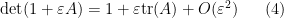
for any bounded square matrix 

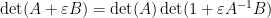
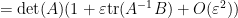
for infinitesimal 

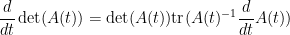
whenever
Let us see some examples of this differentiation method. If we take the Weinstein-Aronszajn identity (2) and multiply one of the rectangular matrices
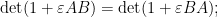
applying (4) and extracting the linear term in 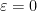
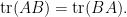
To manipulate derivatives and inverses, we begin with the Neumann series approximation
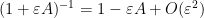
for bounded square
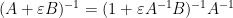
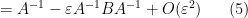
for square matrices 

whenever
We can then differentiate (or linearise) the Schur identity (3) in a number of ways. For instance, if we replace the lower block 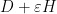


while the right-hand side becomes

extracting the linear term in
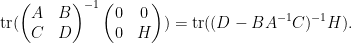
As 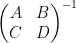
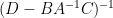

One can also compute the other components of this inverse in terms of the Schur complement 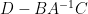
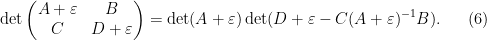
By (4), the left-hand side is
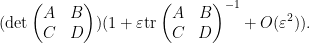
From (5), we have

and so from (4) the right-hand side of (6) is
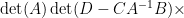
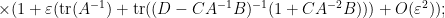
extracting the linear component in
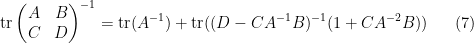
which relates the trace of the inverse of a block matrix, with the trace of the inverse of one of its blocks. This particular identity turns out to be useful in random matrix theory; I hope to elaborate on this in a later post.
As a final example of this method, we can analyse low rank perturbations 
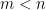
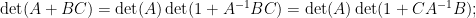
if one then perturbs 

Extracting the linear component in

assuming that
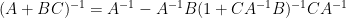
for the inverse of a low rank perturbation
Exercise 1 Use the “determinant first” approach to derive the Woodbury matrix identity (also known as the binomial inverse theorem)
where
are all invertible.

Exercise 2 Let
and differentiate this in
(assuming that all inverses exist) and thence
Rotating
then gives
which is useful for inverting a matrix
that has been split into a self-adjoint component
.


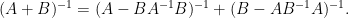
My colleague Ricardo Pérez-Marco showed me a very cute proof of Pythagoras’ theorem, which I thought I would share here; it’s not particularly earth-shattering, but it is perhaps the most intuitive proof of the theorem that I have seen yet.

In the above diagram, a, b, c are the lengths BC, CA, and AB of the right-angled triangle ACB, while x and y are the areas of the right-angled triangles CDB and ADC respectively. Thus the whole triangle ACB has area x+y.
Now observe that the right-angled triangles CDB, ADC, and ACB are all similar (because of all the common angles), and thus their areas are proportional to the square of their respective hypotenuses. In other words, (x,y,x+y) is proportional to 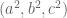
This problem lies in the highly interconnected interface between algebraic combinatorics (esp. the combinatorics of Young tableaux and related objects, including honeycombs and puzzles), algebraic geometry (particularly classical and quantum intersection theory and geometric invariant theory), linear algebra (additive and multiplicative, real and tropical), and the representation theory (classical, quantum, crystal, etc.) of classical groups. (Another open problem in this subject is to find a succinct and descriptive name for the field.) I myself haven’t actively worked in this area for several years, but I still find it a fascinating and beautiful subject. (With respect to the dichotomy between structure and randomness, this subject lies deep within the “structure” end of the spectrum.)
As mentioned above, the problems in this area can be approached from a variety of quite diverse perspectives, but here I will focus on the linear algebra perspective, which is perhaps the most accessible. About nine years ago, Allen Knutson and I introduced a combinatorial gadget, called a honeycomb, which among other things controlled the relationship between the eigenvalues of two arbitrary Hermitian matrices A, B, and the eigenvalues of their sum A+B; this was not the first such gadget that achieved this purpose, but it was a particularly convenient one for studying this problem, in particular it was used to resolve two conjectures in the subject, the saturation conjecture and the Horn conjecture. (These conjectures have since been proven by a variety of other methods.) There is a natural multiplicative version of these problems, which now relates the eigenvalues of two arbitrary unitary matrices U, V and the eigenvalues of their product UV; this led to the “quantum saturation” and “quantum Horn” conjectures, which were proven a couple years ago. However, the quantum analogue of a “honeycomb” remains a mystery; this is the main topic of the current post.

Recent Comments