
In orthodox first-order logic, variables and expressions are only allowed to take one value at a time; a variable 
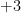
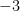
However, the ability to allow expressions to become only partially specified is undeniably convenient, and also rather intuitive. A classic example here is that of the quadratic formula:

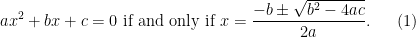
Strictly speaking, the expression 

or

or

in order to strictly adhere to this grammar. But none of these three reformulations are as compact or as conceptually clear as the original one. In a similar spirit, a mathematical English sentence such as
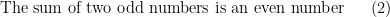
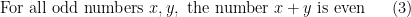
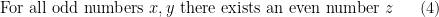
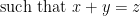
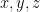 which are used once and then discarded.
which are used once and then discarded.
Another example of partially specified notation is the innocuous 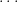
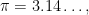
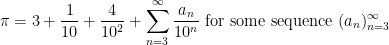
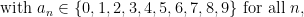
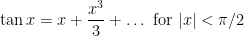

Below the fold I’ll try to assign a formal meaning to partially specified expressions such as (1), for instance allowing one to condense (2), (3), (4) to just
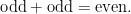
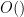 or the little-o notation
or the little-o notation 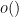 . We will explain how to do this at the end of this post.
. We will explain how to do this at the end of this post.
— 1. Partially specified objects —
Let’s try to assign a formal meaning to partially specified mathematical expressions. We now allow expressions 




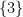
For reasons that will become clearer later, we will use the symbol 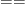




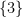
Any finite sequence 
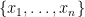




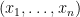






One can mimic set builder notation and denote a partially specified instance of a class 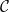



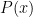
 as
as 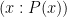 or simply
or simply  , if the domain of is implicitly understood from context. For instance, under this convention,
, if the domain of is implicitly understood from context. For instance, under this convention, 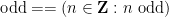
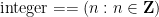
 refers to a partially specified odd perfect number, which is conjectured to not exist. As it turns out, our notation can handle instances of empty classes without difficulty (basically thanks to the concept of a vacuous truth), but we will avoid dwelling on this edge case much here since this concept is not intuitive for beginners. (But if one does want to confront this possibility, one can use a symbol such as
refers to a partially specified odd perfect number, which is conjectured to not exist. As it turns out, our notation can handle instances of empty classes without difficulty (basically thanks to the concept of a vacuous truth), but we will avoid dwelling on this edge case much here since this concept is not intuitive for beginners. (But if one does want to confront this possibility, one can use a symbol such as 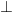 to denote an instance of the empty class, i.e., an object that has no specifications whatsoever.
to denote an instance of the empty class, i.e., an object that has no specifications whatsoever.
The symbol



One can then define other logical operations on partially specified objects if one wishes. For instance, we could define an “and” operator 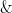



 and the “and” operator will suffice for our purposes.
and the “and” operator will suffice for our purposes.
Any operation on completely specified mathematical objects 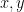
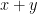


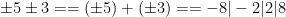
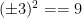



One can have an unbounded number of partially specified instances of a class, for instance 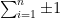


Remark 1 When working with signs, one sometimes wishes to keep all signs aligned, with
denoting the sign opposite to
whenever
. However, this notation is difficult to place in the framework used in this blog post without causing additional confusion, and as such we will not discuss it further here. (The syntax of regular expressions does have some tools for encoding this sort of alignment, but in first-order logic we also have the perfectly servicable tool of named variables and quantifiers (or plain old mathematical English) to do so also.)

One can also extend binary relations, such as 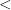
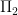


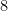

 is false. Similarly, the statement
is false. Similarly, the statement 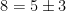 is true, because is an instance of :
is true, because is an instance of : 
 is also true, because every instance of is less than some instance of
is also true, because every instance of is less than some instance of  :
: 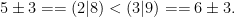 of a class can then be summarised as
of a class can then be summarised as 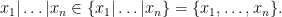
Note how this convention treats the left-hand side and right-hand side of a relation involving partially specified expressions asymmetrically. In particular, for partially specified expressions 
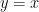



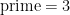

- (i) (Reflexivity)
.
- (ii) (Transitivity) If
and
, then
. Similarly, if
and
, then
, etc..
- (iii) (Substitution) If
for any function
. Similarly, if
, then
for any monotone function
These conventions for partially specified expressions align well with informal mathematical English. For instance, as discussed in the introduction, the assertion




 . Note also how the equality symbol for partially specified expressions corresponds well with the multiple meanings of the word “is” in English (consider for instance “two plus two is four”, “four is even”, and “the sum of two odd numbers is even”); the set-theoretic counterpart of this concept would be a sort of amalgam of the ordinary equality relation , the inclusion relation
. Note also how the equality symbol for partially specified expressions corresponds well with the multiple meanings of the word “is” in English (consider for instance “two plus two is four”, “four is even”, and “the sum of two odd numbers is even”); the set-theoretic counterpart of this concept would be a sort of amalgam of the ordinary equality relation , the inclusion relation  , and the subset relation
, and the subset relation 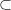 .
.
There are however a number of caveats one has to keep in mind, though, when dealing with formulas involving partially specified objects. The first, which has already been mentioned, is a lack of symmetry: 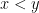


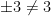
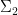
Another subtlety, already mentioned earlier, arises from our choice to allow different instantiations of the same class to refer to different instances, namely that the law of universal instantiation does not always work if the symbol being instantiated occurs more than once on the left-hand side. For instance, the identity
 , but if one naively substitutes in the partially specified expression
, but if one naively substitutes in the partially specified expression  for one obtains the claim
for one obtains the claim 
 do not have to match). However, there is no problem with repeated instantiations on the right-hand side, as long as there is at most a single instance on the left-hand side. For instance, starting with the identity
do not have to match). However, there is no problem with repeated instantiations on the right-hand side, as long as there is at most a single instance on the left-hand side. For instance, starting with the identity 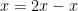 for to obtain
for to obtain 
A common practice that helps avoid these sorts of issues is to keep the partially specified quantities on the right-hand side of one’s relations, or if one is working with a chain of relations such as 



One can of course translate any formula that involves partially specified objects into a more orthodox first-order logic sentence by inserting the relevant quantifiers in the appropriate places – but note that the variables used in quantifiers are always completely specified, rather than partially specified. For instance, if one expands “




One can combine partially specified notation with set builder notation, for instance the set 
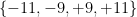

Our examples above of partially specified objects have been drawn from number systems, but one can use this notation for other classes of objects as well. For instance, within the class of functions 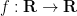

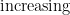 is the class of monotone increasing functions; similarly we have
is the class of monotone increasing functions; similarly we have 
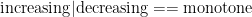






 denoting the Fourier transform) and so forth. Or, in the class of topological spaces, we have for instance
denoting the Fourier transform) and so forth. Or, in the class of topological spaces, we have for instance 



 from the symmetric equivalence relation .
from the symmetric equivalence relation .
As an example of how such notation might be integrated into an actual mathematical argument, we prove a simple and well known topological result in this notation:
Proposition 2 Letbe a continuous bijection from a compact space
. Then
Proof: We have

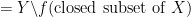 is a bijection)
is a bijection) 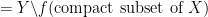 is compact)
is compact)  is continuous)
is continuous)  is Hausdorff)
is Hausdorff) 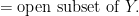 is open, hence
is open, hence 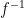 is continuous. Since was already continuous, is a homeomorphism.
is continuous. Since was already continuous, is a homeomorphism. 
— 2. Working with parameters —
In order to introduce asymptotic notation, we will need to combine the above conventions for partially specified objects with separate common adjustment to the grammar of mathematical logic, namely the ability to work with ambient parameters. This is a special case of the more general situation of interpreting logic over an elementary topos, but we will not develop the general theory of topoi here. As this adjustment is orthogonal to the adjustments in the preceding section, we shall for simplicity revert back temporarily to the traditional notational conventions for completely specified objects, and not refer to partially specified objects at all in this section.
In the formal language of first-order logic, variables such as 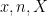
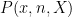

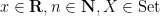



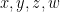
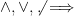

We now generalise this setup by working relative to some ambient set of parameters – some finite collection of variables that range in some specified sets (or classes) and may be subject to one or more constraints. For instance, one may be working with some natural number parameters 
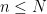

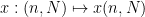

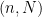

The specific ambient set of parameters, and the constraints on them, tends to vary as one progresses through various stages of a mathematical argument, with these changes being announced by various standard phrases in mathematical English. For instance, if at some point a proof contains a sentence such as “Let 
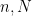
Any term that is well-defined for individual elements of a domain, is also well-defined for parameterised elements of the domain by pointwise evaluation. For instance, if 

 (obeying all ambient constraints), and false otherwise (i.e., if it fails for at least one choice of parameters). For instance, the relation
(obeying all ambient constraints), and false otherwise (i.e., if it fails for at least one choice of parameters). For instance, the relation 
 for all choice of parameters , and false otherwise.
for all choice of parameters , and false otherwise.
Remark 3 In the framework of nonstandard analysis, the interpretation of truth is slightly different; the above relation would be considered true if the set of parameters for which the relation holds lies in a given (non-principal) ultrafilter. The main reason for doing this is that it allows for a significantly more general transfer principle than the one available in this setup; however we will not discuss the nonstandard analysis framework further here. (Our setup here is closer in spirit to the “cheap” version of nonstandard analysis discussed in this previous post.)
With this convention an annoying subtlety emerges with regard to boolean connectives (conjunction 
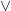
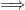

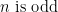 is odd. On the other hand, the internal negation
is odd. On the other hand, the internal negation 
 is even. To put it another way, the internal disjunction
is even. To put it another way, the internal disjunction 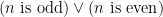
 and
and  are not (so the external disjunction of these statements is false). To maintain this distinction, I will reserve the boolean symbols (
are not (so the external disjunction of these statements is false). To maintain this distinction, I will reserve the boolean symbols ( ) for internal boolean connectives, and reserve the corresponding English connectives (“and”, “or”, “implies”, “not”) for external boolean connectives.
) for internal boolean connectives, and reserve the corresponding English connectives (“and”, “or”, “implies”, “not”) for external boolean connectives.
Because of this subtlety, orthodox dichotomies and trichotomies do not automatically transfer over to the parameterised setting. In the orthodox natural numbers, a natural number 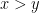
There is a similar distinction between internal quantification (quantifying over orthodox variables before quantifying over parameters), and external quantification (quantifying over parameterised variables after quantifying over parameters); we will again maintain this distinction by reserving the symbols 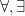
 and
and 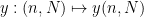 , the assertion
, the assertion  holds for all . In this case it is clear that this assertion is true and is in fact equivalent to the orthodox sentence
holds for all . In this case it is clear that this assertion is true and is in fact equivalent to the orthodox sentence  . More generally, we do have a restricted transfer principle in that any true sentence in orthodox logic that involves only quantifiers and no boolean connectives, will transfer over to parameterised logic (at least if one is willing to use the axiom of choice freely, which we will do in this post). We illustrate this (somewhat arbitrarily) with the Lagrange four square theorem
. More generally, we do have a restricted transfer principle in that any true sentence in orthodox logic that involves only quantifiers and no boolean connectives, will transfer over to parameterised logic (at least if one is willing to use the axiom of choice freely, which we will do in this post). We illustrate this (somewhat arbitrarily) with the Lagrange four square theorem 
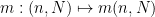 , there exist parameterised natural numbers
, there exist parameterised natural numbers  ,
,  ,
,  ,
,  , such that
, such that 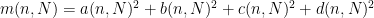 for all choice of parameters . To see this, we can Skolemise the four-square theorem (5) to obtain functions
for all choice of parameters . To see this, we can Skolemise the four-square theorem (5) to obtain functions  ,
, 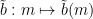 ,
,  ,
,  such that
such that 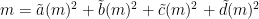
 . Then to obtain the parameterised claim, one simply sets
. Then to obtain the parameterised claim, one simply sets  ,
,  ,
, 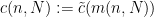 , and
, and  . Similarly for other sentences that avoid boolean connectives. (There are some further classes of sentences that use boolean connectives in a restricted fashion that can also be transferred, but we will not attempt to give a complete classification of such classes here; in general it is better to work out some examples of transfer by hand to see what can be safely transferred and which ones cannot.)
. Similarly for other sentences that avoid boolean connectives. (There are some further classes of sentences that use boolean connectives in a restricted fashion that can also be transferred, but we will not attempt to give a complete classification of such classes here; in general it is better to work out some examples of transfer by hand to see what can be safely transferred and which ones cannot.)
So far this setup is not significantly increasing the expressiveness of one’s language, because any statement constructed so far in parameterised logic can be quickly translated to an equivalent (and only slightly longer) statement in orthodox logic. However, one gains more expressive power when one allows one or more of the parameterised variables to have a specified type of dependence on the parameters, and in particular depending only on a subset of the parameters. For instance, one could introduce a real number 
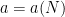
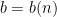
By quantifying over these restricted classes of parameterised functions, one can now efficiently write down a variety of statements in parameterised logic, of types that actually occur quite frequently in analysis. For instance, we can define a parameterised real 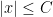
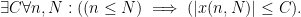 being -bounded, by which we mean
being -bounded, by which we mean  , or in orthodox logic
, or in orthodox logic  is bounded in magnitude by a quantity
is bounded in magnitude by a quantity  that depends on but not on ; in orthodox logic this becomes
that depends on but not on ; in orthodox logic this becomes 
As before, each of the example statements in parameterised logic can be easily translated into a statement in traditional logic. On the other hand, consider the assertion that a parameterised real 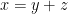
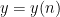

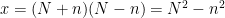

Another subtle distinction that arises once one has parameters is the distinction between “internal” or `parameterised” sets (sets depending on the choice of parameters), and external sets (sets of parameterised objects). For instance, the interval ![{[n,N]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2CN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)





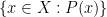
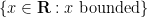

— 3. Asymptotic notation —
We now simultaneously introduce the two extensions to orthodox first order logic discussed in previous sections. In other words,
- We permit the use of partially specified mathematical objects in one’s mathematical statements (and in particular, on either side of an equation or inequality).
- We allow all quantities to depend on one or more of the ambient parameters.
In particular, we allow for the use of partially specified mathematical quantities that also depend on one or more of the ambient parameters. This allows us now formally introduce asymptotic notation. There are many variants of this notation, but here is one set of asymptotic conventions that I for one like to use:
Definition 4 (Asymptotic notation) LetSometimes (by explicitly declaring one will do so) one suppresses the dependence on one or more of the additional parameters
- We use
to denote a partially specified quantity in the class of quantities
for some absolute constant
. More generally, given some ambient parameters
, we use
to denote a partially specified quantity in the class of quantities
for some constant
- We also use
or
as a synonym for
, and
as a synonym for
. (In some fields of analysis,
,
, and
are used instead of
, and
- If
is a limiting value of that parameter (i.e., the parameter space for
to denote a partially specified quantity in the class of quantities
for all
depending only on
as
. More generally, given some further ambient parameters
to denote a partially specified quantity in the class of quantities
for all
depends on
and goes to zero as
(This is the “non-asymptotic” form of the
Thus, for instance, 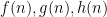

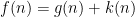
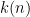

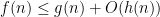

For a slightly more sophisticated example, consider the statement
 is a free variable taking values in the natural numbers. Using the conventions for multi-valued expressions, we can translate this expression into first-order logic as the assertion that whenever
is a free variable taking values in the natural numbers. Using the conventions for multi-valued expressions, we can translate this expression into first-order logic as the assertion that whenever 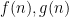 are quantities depending on such that there exists a constant
are quantities depending on such that there exists a constant 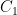 such that
such that  for all natural numbers , and there exists a constant
for all natural numbers , and there exists a constant 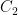 such that
such that  for all natural numbers , then we have
for all natural numbers , then we have 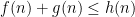 for all , where
for all , where  is a quantity depending on natural numbers with the property that there exists a constant
is a quantity depending on natural numbers with the property that there exists a constant 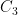 such that
such that  . Note that the first-order translation of (6) is substantially longer than (6) itself; and once one gains familiarity with the big-O notation, (6) can be deciphered much more quickly than its formal first-order translation.
. Note that the first-order translation of (6) is substantially longer than (6) itself; and once one gains familiarity with the big-O notation, (6) can be deciphered much more quickly than its formal first-order translation.
It can be instructive to rewrite some basic notions in analysis in this sort of notation, just to get a slightly different perspective. For instance, if
-
for all
.
-
for all
- A sequence
of functions is equicontinuous if one has
for all
(note that the implied constant depends on the family
, but not on the specific function
or on the index
- A sequence
for all
-
for all
- Similarly for uniformly differentiable, equidifferentiable, etc..
Remark 5 One can define additional variants of asymptotic notation such as,
, or
; see this wikipedia page for some examples. See also the related notion of “sufficiently large” or “sufficiently small”. However, one can usually reformulate such notations in terms of the above-mentioned asymptotic notations with a little bit of rearranging. For instance, the assertion
can be rephrased as an alternative:
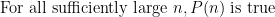

When used correctly, asymptotic notation can suppress a lot of distracting quantifiers (“there exists a
On the other hand, the notation can be somewhat confusing to use at first, as expressions involving asymptotic notation do not always obey the familiar laws of mathematical deduction if applied blindly; but the failures can be explained by the changes to orthodox first order logic indicated above. For instance, if 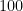

- (i) (Asymmetry of equality) We have
, but it is not true that
. In the same spirit,
is a true statement, but
is a false statement. Similarly for the
- (ii) (Intransitivity of equality) We have
, and
, but
. This is again stemming from the asymmetry of the equality relation.
- (iii) (Incompatibility with functional notation)
generally refers to a function of
usually does not refer to a function of
). This is a slightly unfortunate consequence of the overloaded nature of the parentheses symbols in mathematics, but as long as one keeps in mind that
and
are not function symbols, one can avoid ambiguity.
- (iv) (Incompatibility with mathematical induction) We have
, and more generally
for any
, but one cannot blindly apply induction and conclude that
for all
(with
viewed as an additional parameter). This is because to induct on an internal parameter such as
if
- (v) (Failure of the law of generalisation) Every specific (or “fixed”) positive integer, such as
, is of the form
- (vi) (Failure of the axiom schema of specification) Given a set
of bounded nonstandard reals becomes a proper subring of the ring of nonstandard reals.) This failure is again related to the distinction between internal and external predicates.
- (vii) (Failure of trichotomy) For non-asymptotic real numbers
, exactly one of the statements
,
,
hold. As discussed in the previous section, this is not the case for asymptotic quantities: none of the three statements
,
, or
are true, while all three of the statements
,
, and
are true. (This trichotomy can however be restored by using the nonstandard analysis formalism, or (in some cases) by restricting
- (viii) (Unintuitive interaction with
) Asymptotic notation interacts in strange ways with the
is a true statement, because for any expression
of order
, one can find another expression
of order
such that
for all
in which one of
“. And even then, I would generally only use negation of asymptotic statements in order to demonstrate the incorrectness of some particular argument involving asymptotic notation, and not as part of any positive argument involving such notations. These issues are of course related to (vii).
- (ix) (Failure of cancellation law) We have
, but one cannot cancel one of the
. Indeed,
is not equal to
in general. (For instance,
and
, but
.) More generally,
is not in general equal to
or even to
(although there is an important exception when one of
- (x) (
and
. However, these laws do not work if
and
do not even make sense. Thus for instance
cannot be written as
. (However, one does have
and
when
- (xi) (
, and
, but it is not the case that
. This example seems to indicate that the assertion
is not true, but that is because we have conflated an external (fixed) quantity
). The more precise statements (with
, and that the assertion
is not true, but the assertion
- (xii) (
, then for each fixed
; however,
. Thus an expression of the form
can in fact grow extremely fast in
or even
). Of course, one could replace
can fail, but if one has uniformity in the - (xiii) (
summands were not uniformly bounded. If one imposes uniform boundedness, then one now recovers the
, then
is now uniformly bounded in magnitude by
. Thus, viewing
is bounded by
. (However, one can write
since by our conventions the implied decay rates in the
summands are uniform in
- (xiv) (
are non-negative quantities, and one has a summation of the form
(noting here that the decay rate is not allowed to depend on
term to write this summation as
. However this is far from being true if the sum
exhibits significant cancellation. This is most vivid in the case when the sum
is equal to
, despite the fact that
uniformly in
. For oscillating
Similarly for the
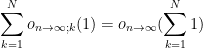
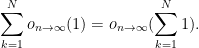
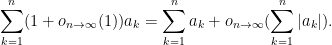
Perhaps the quickest way to develop some basic safeguards is to be aware of certain “red flags” that indicate incorrect, or at least dubious, uses of asymptotic notation, as well as complementary “safety indicators” that give more reassurance that the usage of asymptotic notation is valid. From the above examples, we can construct a small table of such red flags and safety indicators for any expression or argument involving asymptotic notation:
| Red flag | Safety indicator |
| Signed quantities in RHS | Absolute values in RHS |
| Casually using iteration/induction | Explicitly allowing bounds to depend on length of iteration/induction |
| Casually summing an unbounded number of terms | Keeping number of terms bounded and/or ensuring uniform bounds on each term |
| Casually changing a “fixed” quantity to a “variable” or “bound” one | Keeping track of what parameters implied constants depend on |
| Casually establishing lower bounds or asymptotics | Establishing upper bounds and/or being careful with signs and absolute values |
| Signed algebraic manipulations (e.g., cancellation law) | Unsigned algebraic manipulations |
| | Negation of ; or, better still, avoiding negation altogether |
| Swapping LHS and RHS | Not swapping LHS and RHS |
| Using trichotomy of order | Not using trichotomy of order |
| Set-builder notation | Not using set-builder notation (or, in non-standard analysis, distinguishing internal sets from external sets) |
When I say here that some mathematical step is performed “casually”, I mean that it is done without any of the additional care that is necessary when this step involves asymptotic notation (that is to say, the step is performed by blindly applying some mathematical law that may be valid for manipulation of non-asymptotic quantities, but can be dangerous when applied to asymptotic ones). It should also be noted that many of these red flags can be disregarded if the portion of the argument containing the red flag is free of asymptotic notation. For instance, one could have an argument that uses asymptotic notation in most places, except at one stage where mathematical induction is used, at which point the argument switches to more traditional notation (using explicit constants rather than implied ones, etc.). This is in fact the opposite of a red flag, as it shows that the author is aware of the potential dangers of combining induction and asymptotic notation. Similarly for the other red flags listed above; for instance, the use of set-builder notation that conspicuously avoids using the asymptotic notation that appears elsewhere in an argument is reassuring rather than suspicious.
If one finds oneself trying to use asymptotic notation in a way that raises one or more of these red flags, I would strongly recommend working out that step as carefully as possible, ideally by writing out both the hypotheses and conclusions of that step in non-asymptotic language (with all quantifiers present and in the correct order), and seeing if one can actually derive the conclusion from the hypothesis by traditional means (i.e., without explicit use of asymptotic notation ). Conversely, if one is reading a paper that uses asymptotic notation in a manner that casually raises several red flags without any apparent attempt to counteract them, one should be particularly skeptical of these portions of the paper.
As a simple example of asymptotic notation in action, we give a proof that convergent sequences also converge in the Césaro sense:
Proposition 6 Ifis a sequence of real numbers converging to a limit
, then the averages
also converge to
.
Proof: Since 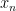

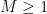 we have
we have 
 . For
. For 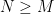 , we thus have
, we thus have 

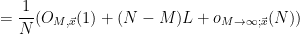

 . Setting
. Setting  to grow sufficiently slowly to infinity as (for fixed
to grow sufficiently slowly to infinity as (for fixed  ), we may simplify this to
), we may simplify this to 
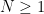 , and the claim follows.
, and the claim follows.

41 comments
Comments feed for this article
10 May, 2022 at 5:32 pm
Partially specified mathematical objects, ambient parameters, and asymptotic notation – Marxist Statistics
[…] Partially specified mathematical objects, ambient parameters, and asymptotic notation […]
10 May, 2022 at 6:20 pm
Jas, the Physicist
x = -b/2a, I was just teaching a student that you can find the axis of symmetry by studying the quadratic formula (for standard parabolas of course, not ones that are rotated [x=y^2]). What a nice coincidence.
10 May, 2022 at 6:26 pm
waltonmath
I think Remark 1’s “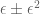 ” should read “
” should read “ “.
“.
[Corrected, thanks – T.]
11 May, 2022 at 4:04 am
allenknutson
I’m curious what sent you down this rabbit hole, of needing to know “what’s really going on” with statements in common usage by mathematicians.
The failure of symmetry of statements like “n+1 = O(n)” reminds me of the following needle-scratch moment in probability.
“Let X be so-and-so random variable.
“What’s the probability that X=2?” GOOD
“What’s the probability that 2=X?” DOUBLE PLUS UNGOOD but why?
11 May, 2022 at 9:36 am
Terence Tao
Actually this is a post that has been developing for a couple years; I worked on it a little each time one of my graduate students struggled with the accepted practices for writing asymptotic notation in research papers, being a little frustrated that there does not appear to be much explicit guidance on these topics in the literature. In spoken English there are many grammatical rules (e.g., regarding the preferred order of adjectives) that native speakers often just pick up without being explicitly taught, and the same occurs in mathematical English as well. It might be an interesting linguistic exercise to try to make explicit more of the analogous rules of mathematical English. [Sample puzzle in this vein: why is it that looks “correct”, but the other five permutations
looks “correct”, but the other five permutations  ,
,  ,
,  ,
,  ,
,  look “incorrect” despite formally describing the exact same quantity? Similarly for
look “incorrect” despite formally describing the exact same quantity? Similarly for 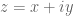 versus
versus  ,
, 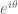 versus
versus  , etc.. -T.]
, etc.. -T.]
With regards to your example, it is an implicit standard (in the more analytic areas of mathematics, at least) when writing equations or inequalities to put the “primary” (and usually more complicated) quantity on the left and the “secondary” (less complicated) quantity on the right (or, alternatively, to upper and lower bound the primary quantity by two secondary quantities by placing it in the middle of a chain of inequalities). Perhaps this convention was influenced by the subject-verb-object ordering of English.
13 May, 2022 at 11:28 pm
antoniojpan
In addition, I would say that there have been times in history of mathematics when a proper notation has been a greater advance than a new theorem. One never knows…
18 May, 2022 at 2:15 pm
Aurel
11 May, 2022 at 6:41 am
Jonathan Kirby
I am also curious as to your motivation for this post. Mathematical notation and conventions exist in various degrees of formalism. Formalism is important for clear communication and recognising (and preventing) imprecision, but beyond that it quickly becomes confusing.
It might be easier to clarify asymptotic notation by writing

rather than giving a lot of new rules for manipulating the equals sign in this context.
11 May, 2022 at 9:45 am
Terence Tao
See my reply to Allen for my primary motivation for this post.
The symbol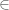 only is a viable solution in a portion of the use cases. For instance, an assertion such as
only is a viable solution in a portion of the use cases. For instance, an assertion such as  would not be correctly describable as
would not be correctly describable as 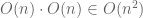 . Perhaps
. Perhaps  would be defensible, but now one has to devote a non-trivial amount of thought into deciding which of the connectives
would be defensible, but now one has to devote a non-trivial amount of thought into deciding which of the connectives  to use in a given context. For instance the assertion “Since
to use in a given context. For instance the assertion “Since 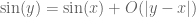 , we have
, we have  ” would now become “Since
” would now become “Since  , we have
, we have  “. Using the equality sign for all of these use cases instead is more intuitive and corresponds more closely to how the verb “is” (“to be”) is actually used in mathematical English.
“. Using the equality sign for all of these use cases instead is more intuitive and corresponds more closely to how the verb “is” (“to be”) is actually used in mathematical English.
[Also, the use of set notation such as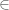 or
or 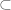 gets particularly confusing when the objects one is manipulating are themselves sets. For instance, the fact that a continuous function
gets particularly confusing when the objects one is manipulating are themselves sets. For instance, the fact that a continuous function  maps bounded sets to bounded sets can be described in my notation as
maps bounded sets to bounded sets can be described in my notation as  , or equivalently that
, or equivalently that 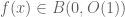 whenever
whenever  . These relationships become significantly more difficult to describe if one is already using
. These relationships become significantly more difficult to describe if one is already using  as connectives, as described above.]
as connectives, as described above.]
12 May, 2022 at 1:29 am
Jonathan Kirby
It’s great that you are trying to explain these usually unspoken conventions. I do think maybe you are overloading notation a bit much to the extent that it obscures clarity, but maybe that’s just because I am not used to it.
14 May, 2022 at 8:31 am
Terence Tao
It’s a question of mereology. The orthodox foundations of mathematics are based on set theory and first-order logic, and so mereological assertions such as “3 is a prime” and “primes larger than 2 are odd” are translated either into set-theoretic assertions such as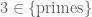 and
and  or into first-order logic sentences such as
or into first-order logic sentences such as 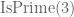 and
and  . With years of training, we all get used to these translations, and even internalize them to the point where we don’t notice anymore that a translation has actually occurred (except when we have to teach confused undergraduates who have not yet had experience with such translation). Nevertheless most of us still often think in mereological terms rather than set-theoretic or first-order terms (unless when actually dealing with sets as geometric or other structured spaces, or when focusing on logical, computational, or game-theoretic aspects of one’s assertions, in which case the set-theoretic or first-order formalism becomes advantageous). One mathematician can say to another, “By Heine-Borel, compactness in a Euclidean space is the same as being closed and bounded” and understand and use it immediately without requiring translation to set theory or first order logic; indeed, such a translation would only serve to slow that mathematician down as he or she would usually have translate it back into mereological form in order to wield it effectively. Because of this, I think it is worth adjusting our notational conventions to more closely align with our actual thought processes, especially if it can be done without sacrificing any precision or rigour. For instance, the two statements discussed above would now be translated as “
. With years of training, we all get used to these translations, and even internalize them to the point where we don’t notice anymore that a translation has actually occurred (except when we have to teach confused undergraduates who have not yet had experience with such translation). Nevertheless most of us still often think in mereological terms rather than set-theoretic or first-order terms (unless when actually dealing with sets as geometric or other structured spaces, or when focusing on logical, computational, or game-theoretic aspects of one’s assertions, in which case the set-theoretic or first-order formalism becomes advantageous). One mathematician can say to another, “By Heine-Borel, compactness in a Euclidean space is the same as being closed and bounded” and understand and use it immediately without requiring translation to set theory or first order logic; indeed, such a translation would only serve to slow that mathematician down as he or she would usually have translate it back into mereological form in order to wield it effectively. Because of this, I think it is worth adjusting our notational conventions to more closely align with our actual thought processes, especially if it can be done without sacrificing any precision or rigour. For instance, the two statements discussed above would now be translated as “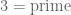 ” and “
” and “ “, thus having almost identical grammatical structure to mathematical English.
“, thus having almost identical grammatical structure to mathematical English.
The approach of viewing asymptotic orders as ideals is certainly a useful one, particularly when one wants to apply algebraic modes of reasoning to one’s problem (e.g., one may want to “mod out” lower order terms). This approach combines particularly well with the nonstandard analysis formalism for asymptotic notation, in which for instance the space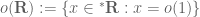 of infinitesimal nonstandard reals is indeed an ideal of the ring
of infinitesimal nonstandard reals is indeed an ideal of the ring 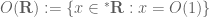 of bounded nonstandard reals, with a useful short exact sequence
of bounded nonstandard reals, with a useful short exact sequence  . It is particularly suitable for situations in which asymptotic notation is used exclusively to describe additive errors, e.g.,
. It is particularly suitable for situations in which asymptotic notation is used exclusively to describe additive errors, e.g.,  (which one can rewrite suggestively as
(which one can rewrite suggestively as 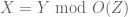 ). However, there are other use-cases of asymptotic notation (particularly those involving nonlinear functions such as the exponential) in which the ideal-theoretic approach is less helpful. For instance, I don’t see much advantage in interpreting each instance of the
). However, there are other use-cases of asymptotic notation (particularly those involving nonlinear functions such as the exponential) in which the ideal-theoretic approach is less helpful. For instance, I don’t see much advantage in interpreting each instance of the 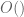 notation in the exponential type bound
notation in the exponential type bound 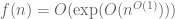 or the calculation
or the calculation  (for
(for  sufficiently large), in terms of ideals.
sufficiently large), in terms of ideals.
14 May, 2022 at 10:12 am
Anonymous
It should be remarked that Leibniz envisioned a universal symbolic language for the representation and analysis of mathematical, scientific and metaphysical concepts, see
https://en.wikipedia.org/wiki/Alphabet_of_human_thought
https://en.wikipedia.org/wiki/Characteristica_universalis
15 May, 2022 at 10:45 am
Jonathan Kirby
That makes a lot of sense. I think the standard formalisation of mathematical language (if such a thing exists) is second-order logic rather than first-order but I agree that the equivalence between intensional properties and extensional sets is not obvious until you are used to it.
For me the sticking point with asymptotic notation was always the overloading of the = symbol to mean something which is obviously not symmetric. In similar contexts I try to use something else (e.g. the word “is”). Maybe if the ideas in your blogpost become widely propagated and accepted then other people will not have the same problem when they are learning about it.
11 May, 2022 at 11:07 am
Anonymous
It seems that an object is completely specified by a property iff the set of object satisfying the property is a singleton (whose only element is the completely specified object)
11 May, 2022 at 12:26 pm
J
In the Wikipedia page (https://en.wikipedia.org/wiki/Big_O_notation#Formal_definition), means
means  *eventually* (instead of for the whole domain) for some constant
*eventually* (instead of for the whole domain) for some constant  , assuming
, assuming 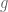 is positive. How would one write this in terms those in Definition 4?
is positive. How would one write this in terms those in Definition 4?
14 May, 2022 at 8:15 am
Terence Tao
I would introduce a different notation for this type of “asymptotic” type of bound, for instance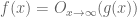 . But one can express it also in terms of the notation provided, namely as
. But one can express it also in terms of the notation provided, namely as 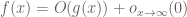 . (I now realize by the way that my previous definition of
. (I now realize by the way that my previous definition of  notation contained a slight inaccuracy, in that one should only require the bound
notation contained a slight inaccuracy, in that one should only require the bound  to hold on a neighbourhood of
to hold on a neighbourhood of 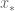 , rather than globally; this is now fixed.)
, rather than globally; this is now fixed.)
18 May, 2022 at 3:32 pm
J
I’m a bit confused with the remark under Definition 4:
(This is the “non-asymptotic” form of the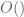 and
and  notation, in which the bounds are assumed to hold for all values of parameters. There is also an “asymptotic” variant of these notation that is commonly used in some fields, in which the bounds in question are only assumed to hold in some neighbourhood of an asymptotic value
notation, in which the bounds are assumed to hold for all values of parameters. There is also an “asymptotic” variant of these notation that is commonly used in some fields, in which the bounds in question are only assumed to hold in some neighbourhood of an asymptotic value  , but we will not focus on that variant here.)
, but we will not focus on that variant here.)
It seems that the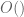 notation is non-asymptotic but
notation is non-asymptotic but  notation is actually asymptotic already in Definition 4, as it is written that “… for all
notation is actually asymptotic already in Definition 4, as it is written that “… for all  in some neighborhood of
in some neighborhood of  “.
“.
[Oops, this referred to an older version of the blog post in which was also defined non-asymptotically. The remark has now been updated – T.]
was also defined non-asymptotically. The remark has now been updated – T.]
11 May, 2022 at 2:18 pm
Anonymous
This post feels like an entry application to Grothendieck society:) Amazing amount of formalism.
11 May, 2022 at 2:41 pm
Anonymous
Dr. Tao: while the standard equivalence relation is
while the standard equivalence relation is  ? By being an equivalence relation, it is automatically symmetric. Isn’t
? By being an equivalence relation, it is automatically symmetric. Isn’t  unnecessary?
unnecessary?
Why do you introduce a “symmetric equivalence relation”
12 May, 2022 at 6:05 am
S
Thanks for this formalization: many people who have only occasional encounters with asymptotic notation get bothered by it and propose using set notation everywhere instead of “abusing” the equals sign; this post finally is something to point to about how to use and interpret asymptotic notation in its usual form.
Donald Knuth once mentioned an unfulfilled dream (in a letter to AMS, available e.g. here) of writing a book called “O Calculus”, doing everything with O notation: for example, he wrote, a function is continuous at a point
is continuous at a point  if
if 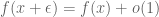 . In the language of this post, I guess that the more precise version would be:
. In the language of this post, I guess that the more precise version would be:  for all
for all  . Anyway, looking at this post, it seems that writing such a text would be both a bit more nontrivial than expected, but also actually possible and likely instructive. Interesting to think about!
. Anyway, looking at this post, it seems that writing such a text would be both a bit more nontrivial than expected, but also actually possible and likely instructive. Interesting to think about!
12 May, 2022 at 3:28 pm
Anonymous
Is my interpretation of the asymptotic notation correct for continuity? I am not sure about converting the parameter of the little o notation to the usual notation for continuity. Please check:
notation for continuity. Please check: is continuous in asymptotic notion:
is continuous in asymptotic notion:
To write
According to Definition 4, it means
for some such that
such that 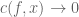 as
as  .
.
We can choose , then it follows that
, then it follows that
which goes to 0 as , which is the definition of continuity.
, which is the definition of continuity.
14 May, 2022 at 9:17 am
Terence Tao
The function is one choice for
is one choice for  , but it is not the only possible choice. This choice confirms that
, but it is not the only possible choice. This choice confirms that  -Lipschitz functions are continuous, but the converse is certainly not true; there exist continuous functions that are not Lipschitz.
-Lipschitz functions are continuous, but the converse is certainly not true; there exist continuous functions that are not Lipschitz.
14 May, 2022 at 6:50 am
Babayoga
But can you make M theory rigorous?
15 May, 2022 at 7:54 am
chorasimilarity
Your LHS = RHS notation seems to me like the statement “each instance of LHS is obtained after a (finite? uniform?) sequence of rewrites of an instance of RHS” so in a sense LHS = RHS may say either that LHS is an interesting consequence of RHS or that RHS is an interesting cause of LHS. But also: LHS is reachable in a constrained (inteligent? human?) evolution from RHS, or RHS is a range of an unconstrained evolution of LHS.
To me it looks that all this is not about multiple values, but about strategies of control of multiple possible rewrites.
Both strategies (constrain the path of rewrites, let the rewrites explode to cover a territory) are useful to the skilled human.
17 May, 2022 at 2:48 am
Adrian Fellhauer
an partially specified instance => a partially specified instance
[Corrected, thanks – T.]
17 May, 2022 at 3:18 pm
Anonymous
Do we always use “contractible” instead of “contractable” in math? Google the two words, they mean the same thing, and “contractible” is not even regarded as a word. So is “contractibility” unique in math language?
21 May, 2022 at 1:05 pm
Terence Tao
My understanding is that an object is contractible if it can be (intransitively) contracted, whereas an object is contractable if it can be (transitively) contracted to something else. For instance, a disease can be contractable (to a recipient), but not contractible (the disease vector cannot be contracted into a smaller shape), whereas for topological spaces the situation is reversed.
18 May, 2022 at 1:53 am
Tom
In teaching math to undergraduates – both math majors and engineers – I have for many years incorporated asymptotic notation from the very start (following a suggestion of D. Knuth), thus e.g. defining the derivative of a function not via the usual difference quotient but as the unique solution of the asymptotic equation f(x+h) = f(x) + f'(x)h + o(h). In my experience, this has had major pedagogical advantages, e.g. the proof of the product rule becomes much clearer and the transition to multivariable calculus becomes much smoother. However, in my first few attempts students have always been struggling with the fact that = is no longer a symmetric relation. Once I replaced the equality sign by the element and subset symbols, these problems went away, and the exam results of the students improved quite drastically. Later on, it was no problem to convert the notation to the one you are suggesting, but from a pedagogical point of view I believe that it is useful to insist, at least initially, that o(h) stands for a class of functions.
26 May, 2022 at 11:32 am
Martin Mertens
“in my first few attempts students have always been struggling with the fact that = is no longer a symmetric relation”
My solution is to write something along the lines of
f(x+h) = f(x) + f'(x)h + ϕ(h) for some ϕ ∈ o(h)
After we’ve proved the product rule, chain rule, etc. I’ll introduce the standard notation f(x+h) = f(x) + f'(x)h + o(h) as a shortcut. But I’m not a math teacher so I haven’t tested this with students.
18 May, 2022 at 2:26 pm
Aurel
In definition 4, shouldn’t be
be  ?
?
[Corrected, thanks – T.]
18 May, 2022 at 4:01 pm
Anonymous
No. It is correctly stated.
18 May, 2022 at 4:05 pm
Anonymous
Does anyone know the latex comment for integral average? i.e. the integral sign , but with a horizontal bar across the centre. Couldn’t find it anywhere.
, but with a horizontal bar across the centre. Couldn’t find it anywhere.
28 May, 2022 at 6:24 am
Michael Ruxton
Look for Scott Pakin’s Comprehensive LATEX Symbol List
20 May, 2022 at 12:46 pm
Liewyee
I can clearly find out the association between the underlying logic (logic)and the elegant-number-sequences(language of mathmetic/set theory and etc.)which behind them through this blog,thank U Tao.
and have a nice day of 520.
I love U.
A poem for U in mine,hope U like it~^____^
2 June, 2022 at 7:30 pm
Anonymous
l wish you all the peace at Dragon Boat Festival.
8 June, 2022 at 9:44 pm
Anonymous
Is this related to plural logic?
9 June, 2022 at 8:30 am
m
“”A bit more subtly, parameters can disappear at the conclusion of a portion of an argument….
The axioms of topology and many (most?) consequences of compactness/uniformity can be expressed as rules of inference
stating that “parameters can disappear” in many particular situations, see examples below.
Of course, it is precisely the intuition (e.g., explained to a student) of compactness/uniformity
but what formalism for topology would make this explicit? Is there a formalism for parametrised logic allowing
to add and remove parameters explicitly ?
For example, axiom “the intersection of open subsets is open” we first reformulate as
 , if there is an parametrised open neighbourhood
, if there is an parametrised open neighbourhood 
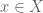 ,
, for each
for each 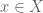 .
. ).
).
“a set is open if it contains an open neighbourhood of each point”, and then express it as follows.
Given a subset
for each parameter
then
there is an absolute (i.e. non-parametrised, constant) open neighbourhood
(necessarily
Similarly, axiom “the intersection of finitely many open subsets is open” we first reformulate as
“if a point can be separated by a neighbourhood from each of the finitely many subsets, then it
can be separated by a neighbourhood from all of them at the same time”.
Now we reformulate this using parametrised variables and see that
it claims that a parameter can disappear in a particular situation:
“if a point
from a parametrised subset
(i.e. there is an parametrised open neighbourhood
then
from the parametrised subset
(i.e. there is an non-parametrised open neighbourhood
In fact, this remains true if we let parameter
that a Hausdorff compact is normal.
“” For instance, we can define a parameterised real
constant
Yet another example is the consequence of compactness stating that on a compact domain continuously parametrised over a compact domain $t\in K$ is bounded
continuously parametrised over a compact domain $t\in K$ is bounded
each function is bounded, i.e. in your terminology, that
each real
by an absolute constant $C$ such that $|x|\leq C$.
This can be expressed literally as a rule making parameter disappear in a specific situation, as follows.
From the (trivially true) hypothesis that for parameter varying over a compact domain
varying over a compact domain  ,
, there is a parametrised real variable
there is a parametrised real variable 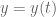 such that
such that 
 varying over a compact domain
varying over a compact domain  ,
,

 .
.
for each parametrised continuous real variable
it follows that
for parameter
for each parametrised continuous real variable
there is an absolute (i.e. non-parametrised) real variable
such that
In what formalism this would be the definition of compactness ? Could any of the examples above can be understood
in terms of elementary topos you mention ? Is there a formalism (proof system) for parametrised logic ?
Let me finish by mentioning a few other examples of topological statements and definitions
which can be reformulated in this way, as rules of inference stating that parameters can disappear:
the image of a closed set is closed; Lebesgue number Lemma; paracompactness.
11 June, 2022 at 3:44 pm
Terence Tao
I believe that the formalism of dependent type theory can be used to capture this sort of parameterised reasoning formally. Probably one can also formalize things in topos-theoretic terms, but I have not looked into this carefully.
6 July, 2022 at 5:02 am
robertkhan397
Math can be pretty amazing, as I learned from this blog post. I never knew there were so many cool details and facts about math! This website is a great resource for learning more about math, with plenty of information and tutorials. I also found some other sites , blogs and and online courses that are worth checking out for anyone who wants to learn more about mathematics. Thanks for sharing this information!
28 April, 2023 at 6:26 am
Arnie Bebita-Dris
I enjoyed reading this blog post, Professor Tao, though admittedly some of it were beyond me.
If I may just ask, are you trying to develop mathematical notation/syntax for formalizing sigma/factor chain proofs, which are currently automated using high-speed computers?
Seeing that you mentioned odd perfect numbers early on when you introduced the concept of partially specified mathematical expressions, and having dived into this blog post and having digested what I could understand and “read”, I feel and believe that your discussion here lends itself well to such an approach.
30 September, 2023 at 3:21 pm
Bounding sums or integrals of non-negative quantities | What's new
[…] where is a quantity that goes to zero as the parameters of the problem go to infinity (or some other limit). (For a deeper dive into asymptotic notation in general, see this previous blog post.) […]