(Originally written, Apr 8, 2012.)
Anonymity on the internet is a very fragile thing; every anonymous online identity on this planet is only about 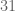 bits of information away from being completely exposed. This is because the total number of internet users on this planet is about
bits of information away from being completely exposed. This is because the total number of internet users on this planet is about 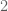 billion, or approximately
billion, or approximately  . Initially, all one knows about an anonymous internet user is that he or she is a member of this large population, which has a Shannon entropy of about bits. But each piece of new information about this identity will reduce this entropy. For instance, knowing the gender of the user will cut down the size of the population of possible candidates for the user’s identity by a factor of approximately two, thus stripping away one bit of entropy. (Actually, one loses a little less than a whole bit here, because the gender distribution of internet users is not perfectly balanced.) Similarly, any tidbit of information about the nationality, profession, marital status, location (e.g. timezone or IP address), hobbies, age, ethnicity, education level, socio-economic status, languages known, birthplace, appearance, political leaning, etc. of the user will reduce the entropy further. (Note though that entropy loss is not always additive; if knowing
. Initially, all one knows about an anonymous internet user is that he or she is a member of this large population, which has a Shannon entropy of about bits. But each piece of new information about this identity will reduce this entropy. For instance, knowing the gender of the user will cut down the size of the population of possible candidates for the user’s identity by a factor of approximately two, thus stripping away one bit of entropy. (Actually, one loses a little less than a whole bit here, because the gender distribution of internet users is not perfectly balanced.) Similarly, any tidbit of information about the nationality, profession, marital status, location (e.g. timezone or IP address), hobbies, age, ethnicity, education level, socio-economic status, languages known, birthplace, appearance, political leaning, etc. of the user will reduce the entropy further. (Note though that entropy loss is not always additive; if knowing  removes bits of entropy and knowing
removes bits of entropy and knowing  removes
removes  bits, then knowing both and does not necessarily remove
bits, then knowing both and does not necessarily remove  bits of entropy, because and may be correlated instead of independent, and so much of the information gained from may already have been present in ).
bits of entropy, because and may be correlated instead of independent, and so much of the information gained from may already have been present in ).
One can reveal quite a few bits of information about oneself without any serious loss to one’s anonymity; for instance, if one has revealed a net of  independent bits of information over the lifetime of one’s online identity, this still leaves one in a crowd of about
independent bits of information over the lifetime of one’s online identity, this still leaves one in a crowd of about  other people, enough to still enjoy some reasonable level of anonymity. But as one approaches the threshold of bits, the level of anonymity drops exponentially fast. Once one has revealed more than bits, it becomes theoretically possible to deduce one’s identity, given a sufficiently comprehensive set of databases about the population of internet users and their characteristics. Of course, such an ideal set of databases does not actually exist; but one can imagine that government intelligence agencies may have enough of these databases to deduce one’s identity from, say,
other people, enough to still enjoy some reasonable level of anonymity. But as one approaches the threshold of bits, the level of anonymity drops exponentially fast. Once one has revealed more than bits, it becomes theoretically possible to deduce one’s identity, given a sufficiently comprehensive set of databases about the population of internet users and their characteristics. Of course, such an ideal set of databases does not actually exist; but one can imagine that government intelligence agencies may have enough of these databases to deduce one’s identity from, say, 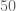 or
or 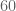 bits of information, and even publicly available databases (such as what one can access from popular search engines) are probably enough to do the job given, say,
bits of information, and even publicly available databases (such as what one can access from popular search engines) are probably enough to do the job given, say, 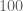 bits of information, assuming sufficient patience and determination. Thus, in today’s online world, a crowd of billions of other people is considerably less protection for one’s anonymity than one may initially think, and just because the first or
bits of information, assuming sufficient patience and determination. Thus, in today’s online world, a crowd of billions of other people is considerably less protection for one’s anonymity than one may initially think, and just because the first or  bits of information you reveal about yourself leads to no apparent loss of anonymity, this does not mean that the next or bits revealed will do so also.
bits of information you reveal about yourself leads to no apparent loss of anonymity, this does not mean that the next or bits revealed will do so also.
Restricting access to online databases may recover a handful of bits of anonymity, but one will not return to anything close to pre-internet levels of anonymity without extremely draconian information controls. Completely discarding a previous online identity and starting afresh can reset one’s level of anonymity to near-maximum levels, but one has to be careful never to link the new identity to the old one, or else the protection gained by switching will be lost, and the information revealed by the two online identities, when combined together, may cumulatively be enough to destroy the anonymity of both.
But one additional way to gain more anonymity is through deliberate disinformation. For instance, suppose that one reveals independent bits of information about oneself. Ordinarily, this would cost bits of anonymity (assuming that each bit was a priori equally likely to be true or false), by cutting the number of possibilities down by a factor of 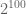 ; but if of these bits (chosen randomly and not revealed in advance) are deliberately falsified, then the number of possibilities increases again by a factor of
; but if of these bits (chosen randomly and not revealed in advance) are deliberately falsified, then the number of possibilities increases again by a factor of  , recovering about
, recovering about 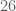 bits of anonymity. In practice one gains even more anonymity than this, because to dispel the disinformation one needs to solve a satisfiability problem, which can be notoriously intractible computationally, although this additional protection may dissipate with time as algorithms improve (e.g. by incorporating ideas from compressed sensing).
bits of anonymity. In practice one gains even more anonymity than this, because to dispel the disinformation one needs to solve a satisfiability problem, which can be notoriously intractible computationally, although this additional protection may dissipate with time as algorithms improve (e.g. by incorporating ideas from compressed sensing).
It is perhaps worth pointing out that disinformation is only a partial defence at best, and to protect anonymity it is better not to emit any information in the first place. For instance, in the above example, even with disinformation, one has still given away about  bits of information, which already is more than enough (in principle, at least) to identify the identity.
bits of information, which already is more than enough (in principle, at least) to identify the identity.


Recent Comments