
In a previous post, we discussed the Szemerédi regularity lemma, and how a given graph could be regularised by partitioning the vertex set into random neighbourhoods. More precisely, we gave a proof of
Lemma 1 (Regularity lemma via random neighbourhoods) Let
. Then there exists integers
with the following property: whenever
be a graph on finitely many vertices, if one selects one of the integers
at random from
uniformly from
at random, then the
vertex cells
(some of which can be empty) generated by the vertex neighbourhoods
for
, will obey the regularity property
with probability at least
, where the sum is over all pairs
for which
is not
-regular between
and
. [Recall that a pair
is
for any
and
with
, where
is the density of edges between
and
.]


The proof was a combinatorial one, based on the standard energy increment argument.
In this post I would like to discuss an alternate approach to the regularity lemma, which is an infinitary approach passing through a graph-theoretic version of the Furstenberg correspondence principle (mentioned briefly in this earlier post of mine). While this approach superficially looks quite different from the combinatorial approach, it in fact uses many of the same ingredients, most notably a reliance on random neighbourhoods to regularise the graph. This approach was introduced by myself back in 2006, and used by Austin and by Austin and myself to establish some property testing results for hypergraphs; more recently, a closely related infinitary hypergraph removal lemma developed in the 2006 paper was also used by Austin to give new proofs of the multidimensional Szemeredi theorem and of the density Hales-Jewett theorem (the latter being a spinoff of the polymath1 project).
For various technical reasons we will not be able to use the correspondence principle to recover Lemma 1 in its full strength; instead, we will establish the following slightly weaker variant.
Lemma 2 (Regularity lemma via random neighbourhoods, weak version) Let
with the following property: whenever
such that if one selects
vertices
uniformly from
vertex cells
generated by the vertex neighbourhoods
, will obey the regularity property (1) with probability at least
.
Roughly speaking, Lemma 1 asserts that one can regularise a large graph 
— 1. The graph correspondence principle —
The first key tool in this argument is the graph correspondence principle, which takes a sequence of (increasingly large) graphs and uses random sampling to extract an infinitary limit object, which will turn out to be an infinite but random (and, crucially, exchangeable) graph. This concept of a graph limit is related to (though slightly different from) the “graphons” used as graph limits in the work of Lovasz and Szegedy, or the ultraproducts used in the work of Elek and Szegedy. It also seems to be related to the concept of an elementary limit that I discussed in this post, though this connection is still rather tentative.
The correspondence works as follows. We start with a finite, deterministic graph 
- The vertex set of
will be the integers
.
- For every integer
, we randomly select a vertex
in
for which
, but these collisions will become asymptotically negligible in the limit
.)
- We then define the edge set
of
to be an edge on
is an edge in
(which in particular requires
).
More succinctly, 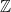
The random graph 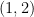


At first glance, it may seem a poor bargain to trade in a finite deterministic graph
- Exchangeability. The probability distribution of
and
, one obtains a new graph which is not equal to
, the pullback
of
has the same probability distribution as
, which places us in the general framework of ergodic theory.
- Limits. The space of probability measures on the space
of infinite graphs is sequentially compact; given any sequence
of infinite random graphs, one can find a subsequence
which converges in the vague topology to another infinite random graph. What this means is that given any event
- Factors. The underlying probability space for the random variable
, which is the
” for
. But this
of
, defined as the
. Thus for instance, the event that
, but not in
. One can also look at compound factors such as
, the factor generated by the union of
. For instance, the event that
is measurable in
, but the event that
The connection between the infinite random graph 




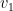



Combining the exchangeability and limit properties (and noting that the vague limit of exchangeable random graphs is still exchangeable), we obtain
Lemma 3 (Graph correspondence principle) Let
be a sequence of finite deterministic graphs, and let
such that
We can illustrate this principle with three main examples, two from opposing extremes of the “dichotomy between structure and randomness”, and one intermediate one.
Example 1 (Random example) Let
-regular graphs of edge density
, where
,
, and
as
. Then any graph limit
of this sequence will be an Erdös-Rényi graph
, where each edge
lies in
.
Example 2 (Structured example) Let
and
respectively, with
. Then any graph limit
of this sequence will be a random complete bipartite graph, constructed as follows: first, randomly colour each vertex
and blue with probability
, independently for each vertex. Then define
Example 3 (Random+structured example) Let
respectively, and the graph
is
One can use the graph correspondence principle to prove statements about finite deterministic graphs, by the usual compactness and contradiction approach: argue by contradiction, create a sequence of finite deterministic graph counterexamples, use the correspondence principle to pass to an infinite random exchangeable limit, and obtain the desired contradiction in the infinitary setting. (See this earlier blog post of mine for further discussion.) This will be how we shall approach the proof of Lemma 2.
— 2. The infinitary regularity lemma —
To prove the finitary regularity lemma via the correspondence principle, one must first develop an infinitary counterpart. We will present this infinitary regularity lemma (first introduced in this paper) shortly, but let us motivate it by a discussion based on the three model examples of infinite exchangeable graphs
First, consider the “random” graph 

More generally, we see that the factors 

whenever 

Next, we consider the “structured” graph 


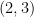


However, one can recover a conditional independence by introducing some new factors. Specifically, let 



Indeed, once one fixes (conditions) the information in 





A similar phenomenon holds for the “random+structured” graph 
These examples suggest, more generally, that we should be able to regularise the graph
Now, in Examples 2, 3 we were able to obtain this regularisation because the vertices of the graph were conveniently coloured for us (red or blue). But for general infinite exchangeable graphs
The key trick – which is the infinitary analogue of using random neighbourhoods to regularise a finitary graph – is to sequester half of the infinite vertices in 


We then have
Lemma 4 (Infinitary regularity lemma) Let
for natural numbers
, and
is a
-measurable event for all
, then

Proof: By induction on 



By relabeling we may take 



and

have the same distribution; in particular, they have the same 




As a special case of the above observation, we see that

In particular, this implies that 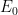


We remark that the same argument also allows one to easily regularise infinite exchangeable hypergraphs; see my paper for details. In fact one can go further and obtain a structural theorem for these hypergraphs generalising de Finetti’s theorem, and also closely related to the graphons of Lovasz and Szegedy; see this paper of Austin for details.
— 3. Proof of finitary regularity lemma —
Having proven the infinitary regularity lemma, we now use the correspondence principle and the compactness and contradiction argument to recover the finitary regularity lemma, Lemma 2.
Suppose this lemma failed. Carefully negating all the quantifiers, this means that there exists 


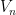
We convert each of the finite deterministic graphs 
Now for any distinct natural numbers 



where

and

The exchangeability of 


By the infinitary regularity lemma, the 

Meanwhile, the random variable 





We can also impose the symmetry condition 






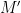

Again we can impose the symmetry condition 


for all distinct natural numbers

and by a separate application of the triangle inequality

The bounds (2), (3) apply to the limiting infinite random graph
Now we unwind the definitions to move back to the finite graphs 

where ![{F_{U,n}: V_n \times V_n \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7BF_%7BU%2Cn%7D%3A+V_n+%5Ctimes+V_n+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


for some symmetric function ![{F_{U,n}: V_n \times V_n \rightarrow [-1,1]}](https://s0.wp.com/latex.php?latex=%7BF_%7BU%2Cn%7D%3A+V_n+%5Ctimes+V_n+%5Crightarrow+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


while the estimate (3) can be similarly converted to

If one then repeats the arguments in the preceding blog post, we conclude (if 



3 comments
Comments feed for this article
3 December, 2012 at 5:35 pm
The spectral proof of the Szemeredi regularity lemma « What’s new
[…] are many proofs of this lemma, which is actually not that difficult to establish; see for instance these previous blog posts for some examples. In this post I would like to record one further proof, based […]
21 October, 2015 at 7:00 am
Michael
Hi Terry. When you say,
“One can also look at compound factors such as {{\mathcal B}_I \wedge {\mathcal B}_J}, the factor generated by the union of {{\mathcal B}_I} and {{\mathcal B}_J}.”
Did you mean to say
“One can also look at compound factors such as {{\mathcal B}_I \vee {\mathcal B}_J}, the factor generated by the union of {{\mathcal B}_I} and {{\mathcal B}_J}.”
Where I have replaced the \wedge with the \vee?
[Corrected, thanks – T.]
5 March, 2017 at 10:38 am
Furstenberg limits of the Liouville function | What's new
[…] correspondence principle is discussed in these previous blog posts. One way to establish the principle is by introducing a Banach limit that extends the usual […]