
You are currently browsing the yearly archive for 2011.
One of the most fundamental principles in Fourier analysis is the uncertainty principle. It does not have a single canonical formulation, but one typical informal description of the principle is that if a function 
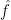
In this post I would like to highlight a useful instance of the uncertainty principle, due to Hugh Montgomery, which is useful in analytic number theory contexts. Specifically, suppose we are given a complex-valued function 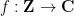

![{[M+1,M+N]}](https://s0.wp.com/latex.php?latex=%7B%5BM%2B1%2CM%2BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


where 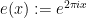
The classical uncertainty principle, in this context, asserts that if 


while from the Cauchy-Schwarz inequality we have

for each frequency 
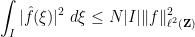
for any arc 
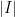

Another manifestation of the classical uncertainty principle is the large sieve inequality. A particularly nice formulation of this inequality is due independently to Montgomery and Vaughan and Selberg: if 
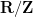



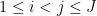

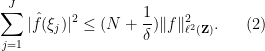
The reader is encouraged to see how this inequality is consistent with the Plancherel identity (1) and the intuition that 

![{[MK+K, MK+NK]}](https://s0.wp.com/latex.php?latex=%7B%5BMK%2BK%2C+MK%2BNK%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
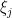
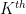
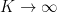
In the above instances of the uncertainty principle, the concept of narrow support in physical space was formalised in the Archimedean sense, using the standard Archimedean metric 



In this context, the uncertainty principle is this: the more residue classes modulo 
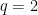
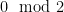
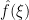
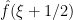
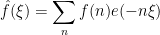
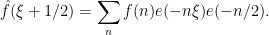
If 


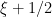

A little more generally, suppose now that 


From basic Fourier analysis, we know that the phases 


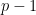


In particular, if 


Let us continue this analysis a bit further. Now suppose that 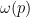
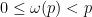

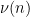


Using the periodic Fourier transform, we can write

for some coefficients 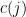
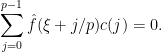
Some Fourier-analytic computations reveal that

and

and so after some routine algebra and the Cauchy-Schwarz inequality, we obtain a generalisation of (3):

Thus we see that the more residue classes mod 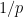
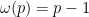
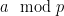

In 1968, Montgomery observed the following useful generalisation of the above calculation to arbitrary modulus:
Proposition 1 (Montgomery’s uncertainty principle) Let
be a finitely supported function which, for each prime
where
is the Möbius function.


We give a proof of this proposition below the fold.
Following the “adelic” philosophy, it is natural to combine this uncertainty principle with the large sieve inequality to take simultaneous advantage of localisation both in the Archimedean sense and in the
Corollary 2 (Arithmetic large sieve inequality) Let
, and let
be a finite set of natural numbers. Suppose that the frequencies
with
,
, and
are
where
was defined in (4).
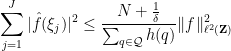
Indeed, from the large sieve inequality one has
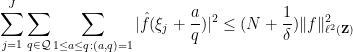
while from Proposition 1 one has

whence the claim.
There is a great deal of flexibility in the above inequality, due to the ability to select the set
Corollary 3 (Large sieve) Let
be a set of integers contained in
. Then
where


Proof: We apply Corollary 2 with 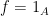
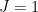
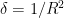
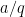


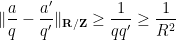
whenever 

If, for instance, 

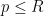
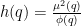


Using this fact and optimising in

where 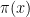

for any primitive residue class 



for any natural numbers 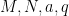

I recently realised that Corollary 2 also establishes a stronger version of the “restriction theorem for the Selberg sieve” that Ben Green and I proved some years ago (indeed, one can view Corollary 2 as a “restriction theorem for the large sieve”). I’m placing the details below the fold.
In 1964, Kemperman established the following result:
Theorem 1 Let
be a compact connected group, with a Haar probability measure
be compact subsets of
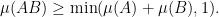
Remark 1 The estimate is sharp, as can be seen by considering the case when
are a non-trivial open subgroup of
replaced simply by
. The case when
By inner regularity, the hypothesis that
are compact can be replaced with Borel measurability, so long as one then adds the additional hypothesis that
is also Borel measurable.
A short proof of Kemperman’s theorem was given by Ruzsa. In this post I wanted to record how this argument can be used to establish the following more “robust” version of Kemperman’s theorem, which not only lower bounds 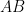
Theorem 2 Let
, one has
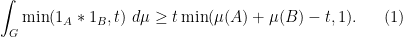
Indeed, Theorem 1 can be deduced from Theorem 2 by dividing (1) by 
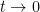
Let us now prove Theorem 2. It uses a submodularity argument related to one discussed in this previous post. We fix 

for any compact set 

We first verify the extreme cases. If 

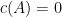

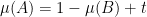
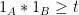
To handle the intermediate regime when 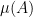
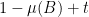
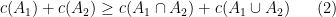
for arbitrary compact 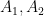
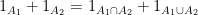
whence

and thus (noting that the quantities on the left are closer to each other than the quantities on the right)
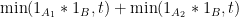

at which point (2) follows by integrating over
Now introduce the function

for 






for any 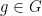

Note that 


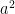


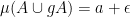

Taking infima in 

for all
We observe the following corollary:
Corollary 3 Let
be compact subsets of
. Then one has the pointwise estimate
if
, and
if
.


Once again, the bounds are completely sharp, as can be seen by computing 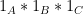

Proof: By cyclic permutation we may take 
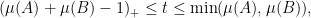
we can bound


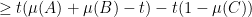

where we used Theorem 2 to obtain the third line. Optimising in
Emmanuel Breuillard, Ben Green and I have just uploaded to the arXiv the short paper “A nilpotent Freiman dimension lemma“, submitted to the special volume of the European Journal of Combinatorics in honour of Yahya Ould Hamidoune. This paper is a nonabelian (or more precisely, nilpotent) variant of the following additive combinatorics lemma of Freiman:
Freiman’s lemma. Let A be a finite subset of a Euclidean space with
. Then A is contained in an affine subspace of dimension at most
.
This can be viewed as a “cheap” version of the more well known theorem of Freiman that places sets of small doubling in a torsion-free abelian group inside a generalised arithmetic progression. The advantage here is that the bound on the dimension is extremely explicit.
Our main result is
Theorem. Let A be a finite subset of a simply-connected nilpotent Lie group G which is a K-approximate group (i.e. A is symmetric, contains the identity, and
can be covered by up to K left translates of A. Then A can be covered by at most
left-translates of a closed connected Lie subgroup of dimension at most
.
We remark that our previous paper established a similar result, in which the dimension bound was improved to 

To motivate the proof of this theorem, let us first show a simple case of an argument of Gleason, which is very much in the spirit of Freiman’s lemma:
Gleason Lemma (special case). Let
be a finite symmetric subset of a Euclidean space, and let
be a sequence of subspaces in this space, such that the sets
are strictly increasing in i for
. Then
, where
.
Proof. By hypothesis, for each 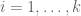
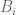





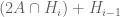




Note that by combining the contrapositive of this lemma with a greedy algorithm, one can show that any K-approximate group in a Euclidean space is contained in a subspace of dimension at most 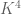
To extend the argument to the nilpotent setting we use the following idea. Observe that any non-trivial genuine subgroup H of a nilpotent group G will contain at least one non-trivial central element; indeed, by intersecting H with the lower central series 

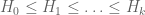

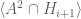


LLet 

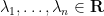

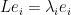

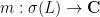
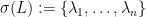

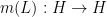

which then gives a functional calculus, in the sense that the map 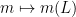
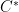
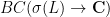
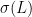


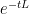
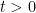


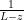

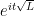
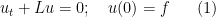
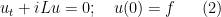
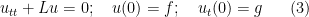
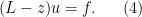
The functional calculus can also be associated to a spectral measure. Indeed, for any vectors 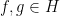
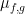

indeed, one can set
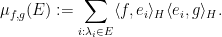
One can also view this complex measure as a coefficient
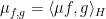
of a projection-valued measure
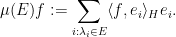
Finally, one can view 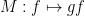
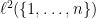


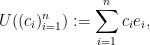
so that 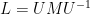
It is an important fact in analysis that many of these above assertions extend to operators on an infinite-dimensional Hilbert space 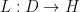

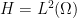


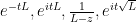
In order to do this, some necessary conditions on the densely defined operator
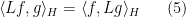
for all 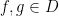
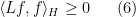
for all 




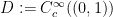
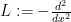
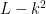

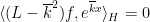
for all test functions 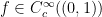
Another example occurs when 
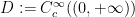
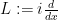
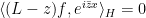
for all test functions 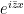

The key property that lets one avoid this bad behaviour is that of essential self-adjointness. Once
Unfortunately, the concept of essential self-adjointness is defined rather abstractly, and is difficult to verify directly; unlike the symmetry condition (5) or the positive condition (6), it is not a “local” condition that can be easily verified just by testing
- Existence of resolvents
- Existence of a contractive heat propagator semigroup
(in the positive case);
- Existence of a unitary Schrödinger propagator group
- Existence of a unitary wave propagator group
- Existence of a “reasonable” functional calculus.
- Unitary equivalence with a multiplication operator.
Thus, to actually verify essential self-adjointness of a differential operator, one typically has to first solve a PDE (such as the wave, Schrödinger, heat, or Helmholtz equation) by some non-spectral method (e.g. by a contraction mapping argument, or a perturbation argument based on an operator already known to be essentially self-adjoint). Once one can solve one of the PDEs, then one can apply one of the known converse spectral theorems to obtain essential self-adjointness, and then by the forward spectral theorem one can then solve all the other PDEs as well. But there is no getting out of that first step, which requires some input (typically of an ODE, PDE, or geometric nature) that is external to what abstract spectral theory can provide. For instance, if one wants to establish essential self-adjointness of the Laplace-Beltrami operator 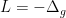
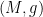
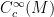

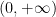
In these notes, I wanted to record (mostly for my own benefit) the forward and converse spectral theorems, and to verify essential self-adjointness of the Laplace-Beltrami operator on geodesically complete manifolds. This is extremely standard analysis (covered, for instance, in the texts of Reed and Simon), but I wanted to write it down myself to make sure that I really understood this foundational material properly.
In the previous set of notes we saw how a representation-theoretic property of groups, namely Kazhdan’s property (T), could be used to demonstrate expansion in Cayley graphs. In this set of notes we discuss a different representation-theoretic property of groups, namely quasirandomness, which is also useful for demonstrating expansion in Cayley graphs, though in a somewhat different way to property (T). For instance, whereas property (T), being qualitative in nature, is only interesting for infinite groups such as 
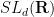
The definition of quasirandomness is easy enough to state:
Definition 1 (Quasirandom groups) Let
. We say that
of
is the identity for all
Exercise 1 Let
and
Remark 1 The terminology “quasirandom group” was introduced explicitly (though with slightly different notational conventions) by Gowers in 2008 in his detailed study of the concept; the name arises because dense Cayley graphs in quasirandom groups are quasirandom graphs in the sense of Chung, Graham, and Wilson, as we shall see below. This property had already been used implicitly to construct expander graphs by Sarnak and Xue in 1991, and more recently by Gamburd in 2002 and by Bourgain and Gamburd in 2008. One can of course define quasirandomness for more general locally compact groups than the finite ones, but we will only need this concept in the finite case. (A paper of Kunze and Stein from 1960, for instance, exploits the quasirandomness properties of the locally compact group
to obtain mixing estimates in that group.)
Quasirandomness behaves fairly well with respect to quotients and short exact sequences:
Exercise 2 Let
be a short exact sequence of finite groups
.
- (i) If
is
- (ii) Conversely, if
Informally, we will call 

The way we have set things up, the trivial group 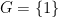
Exercise 3 Let
- (i) Show that if
. (Hint: use the mean zero component
of the regular representation
.) In particular, non-trivial finite groups cannot be infinitely quasirandom.
- (ii) Show that any proper subgroup
. (Hint: use the mean zero component of the quasiregular representation.)
The following exercise shows that quasirandom groups have to be quite non-abelian, and in particular perfect:
Exercise 4 (Quasirandomness, abelianness, and perfection) Let
- (i) If
-quasirandom. (Hint: use Fourier analysis or the classification of finite abelian groups.)
- (ii) Show that
is equal to
Later on we shall see that there is a converse to the above two exercises; any non-trivial perfect finite group with no large subgroups will be quasirandom.
Exercise 5 Let
of
-quasirandom, where
is the index of
Now we give an example of a more quasirandom group.
Lemma 2 (Frobenius lemma) If
is a field of some prime order
is
-quasirandom.
This should be compared with the cardinality 
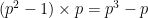
Proof: We may of course take 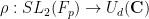

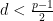
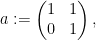
and suppose first that 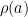


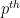

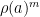

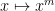


Exercise 6 Show that for any prime
for

Exercise 7 Let
of
Exercise 8 Show that
is
and any prime
, which follows from the results of Landazuri and Seitz.)
As a corollary of the above results and Exercise 2, we see that the projective special linear group 
Remark 2 One can ask whether the bound
, we see that it also acts projectively on the projective line
, which has
elements. Thus
, and also on the
; this latter representation (known as the Steinberg representation) is irreducible. This shows that the
,
of functions
that obey the twisted dilation invariance
for all
and
; these are known as the principal series representations. When
is the trivial character, this is the quasiregular representation discussed earlier. For most other characters, this is an irreducible representation, but it turns out that when
while being non-trivial), the principal series representation splits into the direct sum of two
-dimensional representations, which comes very close to matching the bound in Lemma 2. There is a parallel series of representations to the principal series (known as the discrete series) which is more complicated to describe (roughly speaking, one has to embed
and then use a rotated version of the above construction, to change a split torus into a non-split torus), but can generate irreducible representations of dimension
Exercise 9 Let
, the alternating group
is
); in particular, a cycle is conjugate to its
power for all
. Also, as
,
Remark 3 By using more precise information on the representations of the alternating group (using the theory of Specht modules and Young tableaux), one can show the slightly sharper statement that
-quasirandom for
(but is only
-quasirandom for
due to icosahedral symmetry, and
due to lack of perfectness). Using Exercise 3 with the index
, we see that the bound
If one replaces the alternating group
, is not perfect); indeed,
Remark 4 Thanks to the monumental achievement of the classification of finite simple groups, we know that apart from a finite number (26, to be precise) of sporadic exceptions, all finite simple groups (up to isomorphism) are either a cyclic group
, an alternating group
in characteristic
, it is known from the work of Landazuri and Seitz that such groups are
-quasirandom for some
-quasirandom for some
is sufficiently large depending on
, then
. It would be of interest to see if there was an alternate way to establish this fact that did not rely on the classification, as it may lead to an alternate approach to proving the classification (or perhaps a weakened version thereof).
A key reason why quasirandomness is desirable for the purposes of demonstrating expansion is that quasirandom groups happen to be rapidly mixing at large scales, as we shall see below the fold. As such, quasirandomness is an important tool for demonstrating expansion in Cayley graphs, though because expansion is a phenomenon that must hold at all scales, one needs to supplement quasirandomness with some additional input that creates mixing at small or medium scales also before one can deduce expansion. As an example of this technique of combining quasirandomness with mixing at small and medium scales, we present a proof (due to Sarnak-Xue, and simplified by Gamburd) of a weak version of the famous “3/16 theorem” of Selberg on the least non-trivial eigenvalue of the Laplacian on a modular curve, which among other things can be used to construct a family of expander Cayley graphs in 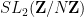
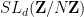
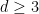
Van Vu and I have just uploaded to the arXiv our short survey article, “Random matrices: The Four Moment Theorem for Wigner ensembles“, submitted to the MSRI book series, as part of the proceedings on the MSRI semester program on random matrix theory from last year. This is a highly condensed version (at 17 pages) of a much longer survey (currently at about 48 pages, though not completely finished) that we are currently working on, devoted to the recent advances in understanding the universality phenomenon for spectral statistics of Wigner matrices. In this abridged version of the survey, we focus on a key tool in the subject, namely the Four Moment Theorem which roughly speaking asserts that the statistics of a Wigner matrix depend only on the first four moments of the entries. We give a sketch of proof of this theorem, and two sample applications: a central limit theorem for individual eigenvalues of a Wigner matrix (extending a result of Gustavsson in the case of GUE), and the verification of a conjecture of Wigner, Dyson, and Mehta on the universality of the asymptotic k-point correlation functions even for discrete ensembles (provided that we interpret convergence in the vague topology sense).
For reasons of space, this paper is very far from an exhaustive survey even of the narrow topic of universality for Wigner matrices, but should hopefully be an accessible entry point into the subject nevertheless.
In the previous set of notes we introduced the notion of expansion in arbitrary
Definition 1 (Cayley graph) Let
be a group, and let
be a finite subset of
whenever
) and does not contain the identity
is defined to be the graph with vertex set
, thus each vertex
is connected to the
elements
for
Example 2 The graph in Exercise 3 of Notes 1 is the Cayley graph on
with generators
.
Remark 3 We call the above Cayley graphs right-invariant because every right translation
on
is connected to
rather than
, so we may without loss of generality restrict our attention throughout to left Cayley graphs.
Remark 4 For minor technical reasons, it will be convenient later on to allow
For the purposes of building expander families, we would of course want the underlying group
We will also sometimes consider a generalisation of a Cayley graph, known as a Schreier graph:
Definition 5 (Schreier graph) Let
, thus there is a map
from
to
and
for all
and
. Let
for all
for all distinct
and
is defined to be the graph with vertex set
.
Example 6 Every Cayley graph
, using the obvious left-action of
permutations
that were studied in the previous set of notes is also a Schreier graph provided that
for all distinct
, with the underlying group being the permutation group
in the obvious manner), and
.
Exercise 7 If
. (Hint: you may assume without proof Petersen’s 2-factor theorem, which asserts that every
We return now to Cayley graphs. It is easy to characterise qualitative expansion properties of Cayley graphs:
Exercise 8 (Qualitative expansion) Let
- (i) Show that
-expander for
if and only if
- (ii) Show that
We will however be interested in more quantitative expansion properties, in which the expansion constant 
One can analyse the expansion of Cayley graphs in a number of ways. For instance, by taking the edge expansion viewpoint, one can study Cayley graphs combinatorially, using the product set operation
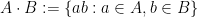
of subsets of
Exercise 9 (Combinatorial description of expansion) Let
for all sufficiently large
of
with
.
One can also give a combinatorial description of two-sided expansion, but it is more complicated and we will not use it here.
Exercise 10 (Abelian groups do not expand) Let
). (Hint: assume for contradiction that
, and show by two different arguments that
grows at least exponentially in
The left-invariant nature of Cayley graphs also suggests that such graphs can be profitably analysed using some sort of Fourier analysis; as the underlying symmetry group is not necessarily abelian, one should use the Fourier analysis of non-abelian groups, which is better known as (unitary) representation theory. The Fourier-analytic nature of Cayley graphs can be highlighted by recalling the operation of convolution of two functions 

This convolution operation is bilinear and associative (at least when one imposes a suitable decay condition on the functions, such as compact support), but is not commutative unless 
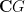

where

where 

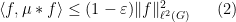
whenever 

whenever
We remark that the above spectral definition of expansion can be easily extended to symmetric sets 

obeys either (2) or (3).
We saw in the last set of notes that expansion can be characterised in terms of random walks. One can of course specialise this characterisation to the Cayley graph case:
Exercise 11 (Random walk description of expansion) Let
be the associated probability density functions. Let
be a constant.
- Show that the
such that for all sufficiently large
for some
, where
denotes the convolution of
- Show that the
for some
In this set of notes, we will connect expansion of Cayley graphs to an important property of certain infinite groups, known as Kazhdan’s property (T) (or property (T) for short). In 1973, Margulis exploited this property to create the first known explicit and deterministic examples of expanding Cayley graphs. As it turns out, property (T) is somewhat overpowered for this purpose; in particular, we now know that there are many families of Cayley graphs for which the associated infinite group does not obey property (T) (or weaker variants of this property, such as property 
The material here is based in part on this recent text on property (T) by Bekka, de la Harpe, and Valette (available online here).
Read the rest of this entry »
The objective of this course is to present a number of recent constructions of expander graphs, which are a type of sparse but “pseudorandom” graph of importance in computer science, the theory of random walks, geometric group theory, and in number theory. The subject of expander graphs and their applications is an immense one, and we will not possibly be able to cover it in full in this course. In particular, we will say almost nothing about the important applications of expander graphs to computer science, for instance in constructing good pseudorandom number generators, derandomising a probabilistic algorithm, constructing error correcting codes, or in building probabilistically checkable proofs. For such topics, I recommend the survey of Hoory-Linial-Wigderson. We will also only pass very lightly over the other applications of expander graphs, though if time permits I may discuss at the end of the course the application of expander graphs in finite groups such as
Instead of focusing on applications, this course will concern itself much more with the task of constructing expander graphs. This is a surprisingly non-trivial problem. On one hand, an easy application of the probabilistic method shows that a randomly chosen (large, regular, bounded-degree) graph will be an expander graph with very high probability, so expander graphs are extremely abundant. On the other hand, in many applications, one wants an expander graph that is more deterministic in nature (requiring either no or very few random choices to build), and of a more specialised form. For the applications to number theory or geometric group theory, it is of particular interest to determine the expansion properties of a very symmetric type of graph, namely a Cayley graph; we will also occasionally work with the more general concept of a Schreier graph. It turns out that such questions are related to deep properties of various groups 
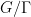
(There are also other important constructions of expander graphs that are not related to Cayley or Schreier graphs, such as those graphs constructed by the zigzag product construction, but we will not discuss those types of graphs in this course, again referring the reader to the survey of Hoory, Linial, and Wigderson.)
Van Vu and I have just uploaded to the arXiv our paper A central limit theorem for the determinant of a Wigner matrix, submitted to Adv. Math.. It studies the asymptotic distribution of the determinant 
Before we get to these results, let us first discuss the simpler problem of studying the determinant 
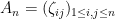


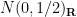

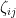
We can expand
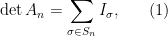
where 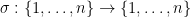
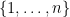
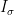

From the iid nature of the 


It turns out, though, that this is not quite best possible. This is easiest to explain in the real gaussian case, by performing a computation first made by Goodman. In this case, 
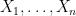



where 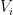
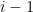
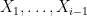

Now, we take advantage of a fundamental symmetry property of the Gaussian vector distribution, namely its invariance with respect to the orthogonal group 
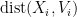

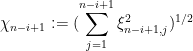
where 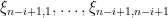


A standard computation shows that each 

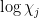


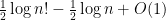
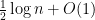

where 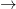

when 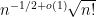
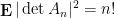
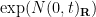

It turns out that the central limit theorem (3) is valid for any real iid matrix with mean zero, variance one, and an exponential decay condition on the entries; this was first claimed by Girko, though the arguments in that paper appear to be incomplete. Another proof of this result, with more quantitative bounds on the convergence rate has been recently obtained by Hoi Nguyen and Van Vu. The basic idea in these arguments is to express the sum in (2) in terms of a martingale and apply the martingale central limit theorem.
If one works with complex gaussian random matrices instead of real gaussian random matrices, the above computations change slightly (one has to replace the real 
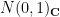
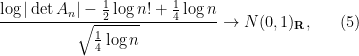

(but note that this new asymptotic is still consistent with Turán’s second moment calculation).
We can now turn to the results of our paper. Here, we replace the iid matrices 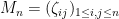


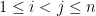

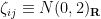
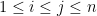
The determinants 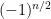


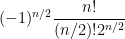
(the fraction here simply being the number of perfect matchings on 




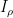

Our main results are then as follows.
Theorem 1 Let
be a Wigner matrix.
- If
- If
- The previous two results also hold for more general Wigner matrices, assuming that the real and imaginary parts are independent, a finite moment condition is satisfied, and the entries match moments with those of GOE or GUE to fourth order. (See the paper for a more precise formulation of the result.)


Thus, we informally have
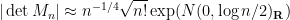
when
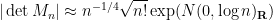
when
The extension from the GUE or GOE case to more general Wigner ensembles is a fairly routine application of the four moment theorem for Wigner matrices, although for various technical reasons we do not quite use the existing four moment theorems in the literature, but adapt them to the log determinant. The main idea is to express the log-determinant as an integral

of the Stieltjes transform
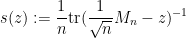
of
Somewhat surprisingly (to us, at least), it turned out that it was the first part of the theorem (namely, the verification of the limiting law for the invariant ensembles GUE and GOE) that was more difficult than the extension to the Wigner case. Even in an ensemble as highly symmetric as GUE, the rows are no longer independent, and the formula (2) is basically useless for getting any non-trivial control on the log determinant. There is an explicit formula for the joint distribution of the eigenvalues of GUE (or GOE), which does eventually give the distribution of the cumulants of the log determinant, which then gives the required central limit theorem; but this is a lengthy computation, first performed by Delannay and Le Caer.
Following a suggestion of my colleague, Rowan Killip, we give an alternate proof of this central limit theorem in the GUE and GOE cases, by using a beautiful observation of Trotter, namely that the GUE or GOE ensemble can be conjugated into a tractable tridiagonal form. Let me state it just for GUE:
Proposition 2 (Tridiagonal form of GUE) Let
be the random tridiagonal real symmetric matrix
where the
are jointly independent real random variables, with
being standard real Gaussians, and each
having a
where
are iid complex gaussians. Let


Proof: Let
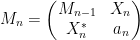
where 

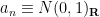

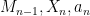
We now apply the tridiagonal matrix algorithm. Let 





where 
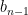
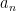
We continue this process, expanding 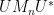
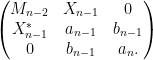
Applying a further unitary conjugation that fixes 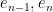

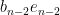


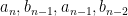
The determinant of a tridiagonal matrix is not quite as simple as the determinant of a triangular matrix (in which it is simply the product of the diagonal entries), but it is pretty close: the determinant 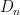

with 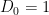

In the Winter quarter (starting on January 9), I will be teaching a graduate course on expansion in groups of Lie type. This course will focus on constructions of expanding Cayley graphs on finite groups of Lie type (such as the special linear groups 
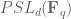

Recent Comments